Amazon Web Services ブログ
Fivetran の Managed Data Lake Service の CDC で実現する業務システムから Apache Iceberg へのリアルタイムデータ連携
本記事は アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト 疋田、畠 と、Fivetran による共著です。
はじめに
本記事では、Fivetran の Managed Data Lake Service 及び CDC 機能を活用して業務システムの RDBMS から Amazon S3 上の Apache Iceberg テーブルへリアルタイムにデータ連携が必要となるユースケースや構成イメージ、実装例を記載します。
本記事では、業務システムの RDBMS からリアルタイムにデータを連携するユースケースを紹介します。また、 Fivetran の Fivetran Managed Data Lake Service 及び CDC 機能を用いて Amazon S3 上の Apache Iceberg テーブルを活用する構成と実装例をご紹介します。
お客様の業務システムには、受注・在庫・会計といった大量のトランザクションデータが蓄積されています。これらのデータを分析やビジネス上の意思決定に活用したいというニーズは年々高まっており、近年では生成 AI の学習データ基盤としてもオープンテーブルフォーマットを活用したデータ基盤へのデータ集約が注目されています。
しかし、業務システムの RDBMS 上で直接分析クエリを実行すると、本来のトランザクション処理に影響を及ぼすリスクがあります。受発注や在庫更新のような日常的なデータの読み書きトランザクション処理は OLTP(Online Transaction Processing)、大量データの集計や傾向分析などの分析処理は OLAP(Online Analytical Processing)と呼ばれ、それぞれ求められる処理特性が異なります。高スペックな RDBMS を用いて OLTP および OLAP を単一のデータベース基盤で処理する方式の場合、最新のデータを扱えますが、ハードウェアやライセンス等のコストが増大します。夜間バッチで OLAP 基盤へデータを連携する方法では、コストを抑えられますが、データの鮮度がバッチの実行間隔に依存するといったトレードオフが生じます。
こうした課題を解決する手段の一つが、Change Data Capture(CDC)を用いた業務システムとデータ基盤の連携です。CDC はデータベースの変更をリアルタイムに検知・取得する技術で、業務システムへの負荷を最小限に抑えながらデータを連携できます。
本ブログでは、AWS Data and Analytics コンピテンシーパートナーである Fivetran の Managed Data Lake Service (MDLS) 機能を活用し、業務システムの RDBMS から Amazon S3 上の Apache Iceberg テーブルへデータを連携する方法をご紹介します。Apache Iceberg は大規模な分析データセットを管理するためのオープンテーブルフォーマットで、ACID トランザクションやスキーマ進化、タイムトラベルといった機能を提供します。連携されたデータは AWS Glue データカタログに登録され、Amazon Redshift 、 Amazon Athena 等からすぐにクエリ・分析が可能です。
業務システムから Iceberg テーブルへの CDC データ連携のユースケース
業務システムで用いられるデータベース基盤から Apache Iceberg テーブルへ CDC でデータを連携するユースケースとして、以下のようなものが挙げられます。
OLTP と OLAP の分離によるデータベース基盤のダウンサイジング
オンプレミスの高性能なデータベース基盤では、 OLTP と OLAP の両方を単一の基盤上で実行しているケースが少なくありません。OLAP ワークロードに対応するために基盤のスペックが引き上げられ、結果としてライセンスコストやハードウェアコストが増大しているという状況は、多くのお客様に共通する課題です。
これに対して、CDC を用いて業務データを Apache Iceberg テーブルに連携することで、OLAP ワークロードを Amazon Athena にオフロードできます。Fivetram Managed Data Lake Service が連携したデータは AWS Glue データカタログに自動的に登録されるため、Athena からすぐにクエリを開始できます。これにより、既存のデータベース基盤は本来の OLTP 処理に専念でき、スペックの適正化やダウンサイジングが可能になります。Amazon Athena はサーバーレスサービスであるため、インフラストラクチャの管理が不要で、クエリのデータスキャン量に応じた従量課金で利用できます。
バッチ処理のオフロード
多くの企業では、業務システムのデータを分析用データベースに連携するために、夜間バッチによる定期的なデータ抽出を行っています。この方式では、データの鮮度がバッチの実行間隔に依存するため、日中に発生した変更が分析に反映されるのは翌日以降になる場合も少なくありません。また、バッチ処理自体がデータベースに大きな負荷をかけるため、業務時間外に実行せざるを得ないという制約もあります。
CDC を活用すれば、データベースのトランザクションログから変更データをリアルタイムに取得可能です。これにより、業務システムへの負荷を最小限に抑えながら、データの鮮度を大幅に向上でき、夜間バッチの廃止や実行頻度の削減等を狙えます。また、Fivetran のようなサーバーレスなマネージドサービスを用いることで運用負荷の軽減や、後述の Fivetran Managed Data Lake Service のような多くの機能を素早く利用可能です。
履歴データの保持と分析
業務システムでは、データは常に最新の状態に更新されるため、過去のある時点の状態を参照することが困難です。たとえば、「ある顧客の住所が変更される前の情報」や「商品の価格改定前の単価」といった履歴情報は、通常の RDBMS 上では保持されません。
Fivetran の CDC は データウェアハウスにおける履歴管理手法である Slowly Changing Dimension Type 2(SCD Type 2)に対応しています。SCD Type 2 により、レコードの変更履歴を保持する形式でデータを連携できます。これにより、Apache Iceberg テーブル上に変更の履歴が蓄積され、「いつ、どのように変更されたか」を後から分析することが可能になります。Iceberg のタイムトラベル機能と組み合わせることで、任意の時点のデータスナップショットを参照することもできます。
Fivetranとは? エンタープライズグレードのCDCとデータ統合の自動化
現代のデータアーキテクチャは、Amazon S3 を核として、オープンで柔軟な基盤へと進化しています。組織がレイクハウス型の分析へと移行するにつれ、Apache Iceberg のようなオープンテーブル形式でデータを取得することが、データのポータビリティと将来への対応を確保する上で不可欠になっています。
エンタープライズグレードのデータ移動: High-Volume Agent(HVA)と Binary Log Reader
データエンジニアリングにおける最大の課題は、データの取り込みだけでなく、ミッションクリティカルなワークロードの長期的な信頼性と拡張性を維持することです。Fivetran は 700 を超えるフルマネージドコネクタを提供し、多様なデータソースからの連携をノーコードで実現します。特に Oracle(Oracle Exadata を含む)のような要求の厳しい環境向けには、高度な Binary Log Reader 技術を活用した低レイテンシのログベース CDC に対応しています。Oracle Database 19c 以降に最適化されたこの仕組みは、REDO ログを直接分析することで LogMiner などの従来型ツールのオーバーヘッドを回避します。多くの場合、ソースに近い環境に配置した High-Volume Agent(HVA)を介して REDO ログを読み取ることで、テラバイト規模のデータであっても本番環境への影響を最小限に抑えながらリアルタイムに移動できます。これにより、コアビジネスシステムの安定性を損なうことなく、シームレスな OLAP オフロードが可能になります。
自動化されたガバナンスと将来を見据えたテーブル
Fivetran MDLS は、スキーマの変更を自動的に検知・反映することで、スキーマドリフトに自動的に対応します。また、レコードの変更履歴が保持される SCD Type 2 のサポートにより、Iceberg テーブル管理の運用負担を軽減します。これにより、ソーススキーマが変化しても、下流の分析の一貫性と「将来への対応」が確保されます。
検出を効率化するため、Fivetran は AWS Glue データカタログとネイティブに統合されています。Amazon S3 で Icebergテーブルが更新されると共に、メタデータが自動的に同期されます。これにより、Amazon Athena 経由でデータセットを即座に検出及びクエリできるようになります。Fivetran の自動データ移動と AWS のスケーラブルなインフラストラクチャを組み合わせることで、チームはエンタープライズ規模の AI と分析に対応できる、ガバナンスが効いた高性能なデータ基盤を構築できます。
さらに、Fivetran MDLS はデータのロード・更新にとどまらず、Icebergテーブルのパフォーマンスを継続的に維持するための自動管理機能をバックグラウンドで実行します。具体的には、クエリ性能を最適化するための小さなファイルの統合(コンパクション)、不要な孤立ファイルの削除、古いスナップショットの自動期限切れ処理などが含まれます。これらの運用タスクが自動化されることで、チームはインフラ管理ではなくデータ活用に集中できます。
また、Fivetran MDLS を活用することで、各ツールやシステムがデータのコピーを個別に持つ必要がなくなります。データは Amazon S3 上の Iceberg テーブルとして一元管理されるため、ストレージコストを抑えながら「単一の真実のバージョン(Single Source of Truth)」を実現し、組織全体のデータサイロを防ぐことができます。
構成の概要とシナリオ
ここでは、PostgreSQL で稼働する業務システムのデータを分析基盤に連携するシナリオを例に、具体的な手順をご紹介します。業務データベースに対して分析用途の集計クエリを直接実行すると本番ワークロードへの負荷が懸念されます。加えて、一部のテーブルについては各レコードの変更履歴を追跡できる形でデータを蓄積する必要があります。
そこで、Fivetran を業務データベースに接続し、Amazon S3 上に Iceberg 形式でデータを蓄積するパイプラインを構築します。これにより、業務システムの OLTP ワークロードと分析の OLAP ワークロードを分離しつつ、両者を継続的に連携できます。S3 に書き込まれた Iceberg テーブルのメタデータは AWS Glue Data Catalog に登録されるため、Amazon Athena から即座にクエリが可能です。
今回の構成は以下の通りです。
- ソース: PostgreSQL データベース
- CDC 処理・データレイク管理: Fivetran MDLS
- ターゲット: Amazon S3 + AWS Glue Data Catalog(Apache Iceberg 形式)
- クエリエンジン: Amazon Athena

Iceberg 形式のデータは、Amazon Athena 以外にも Amazon Redshift や Apache Spark、Trino など Iceberg をサポートする様々なクエリエンジンからデータをコピーすることなく参照できます。要件の変化に応じて最適なツールを使い分けることが可能です。
サンプルデータ
今回のウォークスルーでは、業務システムを模した以下の 2 つのテーブルを使用します。
orders テーブル(受注データ)は、日々の受注を記録するトランザクションテーブルです。Fivetran MDLS による通常の CDC で連携し、INSERT/UPDATE/DELETE がそのまま Iceberg テーブルに反映される様子を確認します。
| カラム名 | 型 | 説明 |
|---|---|---|
| id | SERIAL (PK) | 受注ID |
| product_id | INTEGER | 商品ID |
| quantity | INTEGER | 数量 |
| total_price | NUMERIC(10,2) | 合計金額 |
| status | VARCHAR(20) | ステータス(pending / confirmed / shipped / cancelled) |
| ordered_at | TIMESTAMP | 受注日時 |
初期データとして、以下の 5 件の受注が登録されています。
| id | product_id | quantity | total_price | status |
|---|---|---|---|---|
| 1 | 1 | 1 | 128,000 | confirmed |
| 2 | 2 | 2 | 90,000 | shipped |
| 3 | 3 | 1 | 18,000 | pending |
| 4 | 5 | 3 | 10,500 | confirmed |
| 5 | 4 | 2 | 17,800 | pending |
products テーブル(商品マスタ)は、商品の基本情報を管理するマスタテーブルです。Fivetran MDLS の SCD Type 2 を使った連携方式を使用し、価格改定などの更新が行われた際に変更前のレコードが履歴として保持される様子を確認します。
| カラム名 | 型 | 説明 |
|---|---|---|
| id | SERIAL (PK) | 商品ID |
| name | VARCHAR(100) | 商品名 |
| category | VARCHAR(50) | カテゴリ |
| unit_price | NUMERIC(10,2) | 単価 |
| is_active | BOOLEAN | 販売中フラグ |
| updated_at | TIMESTAMP | 更新日時 |
初期データとして、以下の 5 商品が登録されています。
| id | name | category | unit_price |
|---|---|---|---|
| 1 | ノートPC 14インチ | PC | 128,000 |
| 2 | モニター 27インチ | 周辺機器 | 45,000 |
| 3 | メカニカルキーボード | 周辺機器 | 18,000 |
| 4 | ワイヤレスマウス | 周辺機器 | 8,900 |
| 5 | USBハブ 7ポート | アクセサリ | 3,500 |
セットアップ手順
ここからは、実際に環境を構築しながら手順を説明します。全体の流れは以下の通りです。
AWS 側の準備(S3 バケット、IAM ロール、Glue データカタログ)
Fivetran のデスティネーション(データレイク)設定
ソースデータベース(Aurora PostgreSQL)の準備
Fivetran のコネクター設定と CDC 連携の開始
AWS 側の準備
S3 バケットの作成
Iceberg テーブルのデータファイルとメタデータを格納する S3 バケットを作成します。詳細は Amazon S3 の開始方法を参照してください。
IAM ロールの作成
Fivetran が S3 バケットへの書き込みと Glue Data Catalog の操作を行うための IAM ロールを作成します。必要な IAM ポリシーや信頼ポリシーの設定手順は、Fivetran の Managed Data Lake Service セットアップガイドに記載されています。
Fivetran のデスティネーション設定
Fivetran のダッシュボードから、データの書き込み先となるデスティネーションを設定します。今回は S3 Data Lake を選択し、作成した S3 バケットと IAM ロールの情報を入力します。設定の詳細は Fivetran の Managed Data Lake Service セットアップガイドを参照してください。
設定の中で、Update AWS Glue Catalog を有効にすると、Fivetran が Iceberg テーブルのメタデータを Glue Data Catalog に自動登録するようになり、Amazon Athena などからすぐにクエリできる状態になります。
設定が完了すると、以下のようにデスティネーションが登録されます。
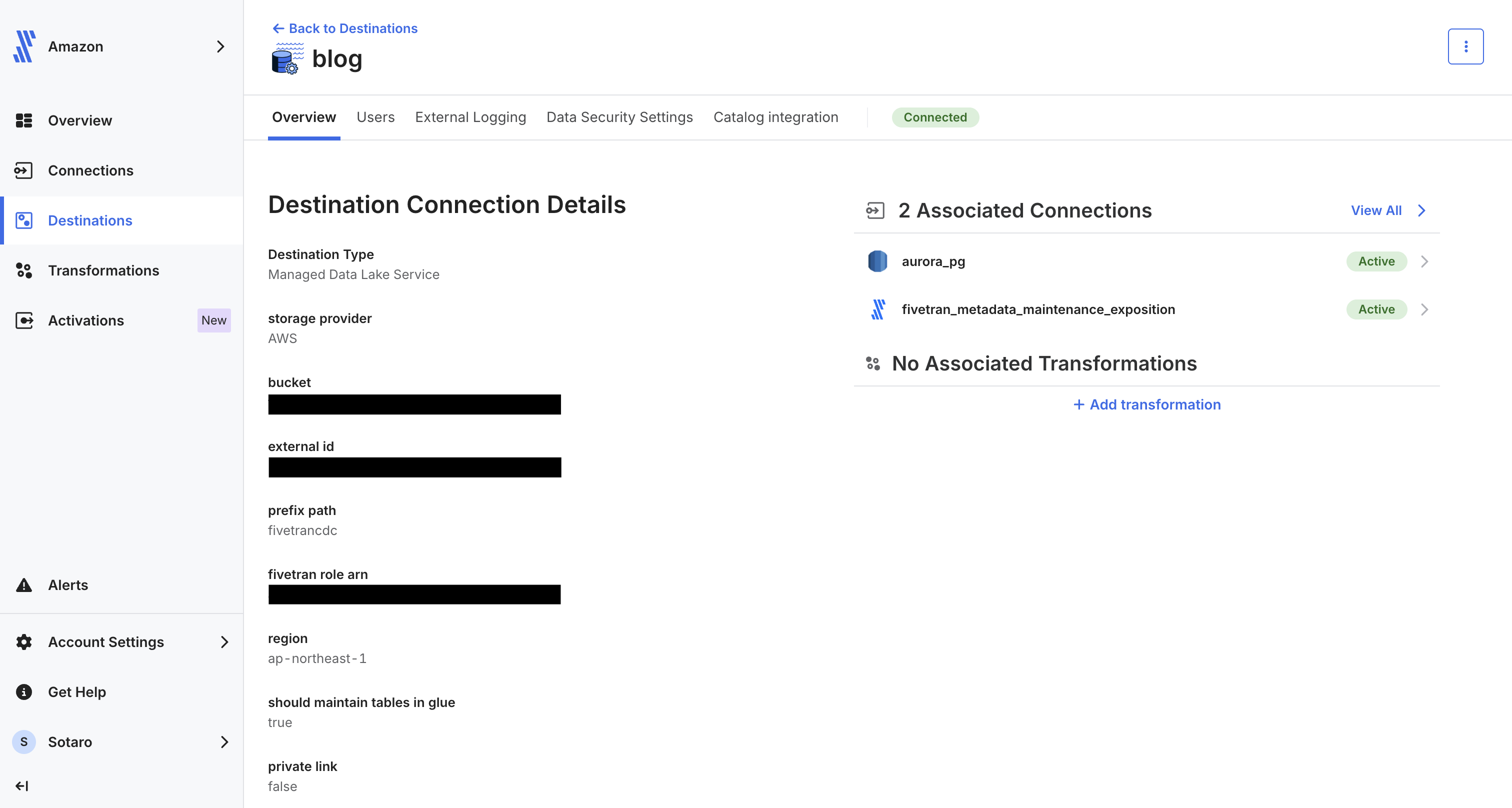
ソースデータベースの準備
今回は Amazon Aurora PostgreSQL をソースデータベースとして使用します。論理レプリケーションの有効化やユーザーの作成など、ソース側の設定は Fivetran の Aurora PostgreSQL セットアップガイドに従って進めます。
セットアップガイドに従い、Fivetran 専用のデータベースユーザーの作成と読み取り権限・レプリケーション権限の付与、Publication とレプリケーションスロットの作成を行います。
Fivetran のコネクション設定
Fivetran では、デスティネーションに対してデータソースごとのコネクションを作成することでデータパイプラインを構成します。先ほど作成したデスティネーションに対して、Amazon Aurora PostgreSQL へのコネクションを追加します。PostgreSQL を選択し、Aurora クラスターのエンドポイントや認証情報を入力します。
データベースへの接続方法は直接接続のほか SSH トンネルや AWS PrivateLink にも対応しています。また、増分同期の方式(Update Method)には Logical Replication と Query-Based の 2 種類があります。Logical Replication は WAL(Write-Ahead Log)から変更を検知する方式で、Aurora PostgreSQL バージョン 10 以降で利用できます。今回はこちらを選択し、先ほど作成した Replication Slot と Publication Name を指定します。
設定が完了すると、以下のようにコネクションが登録されます。
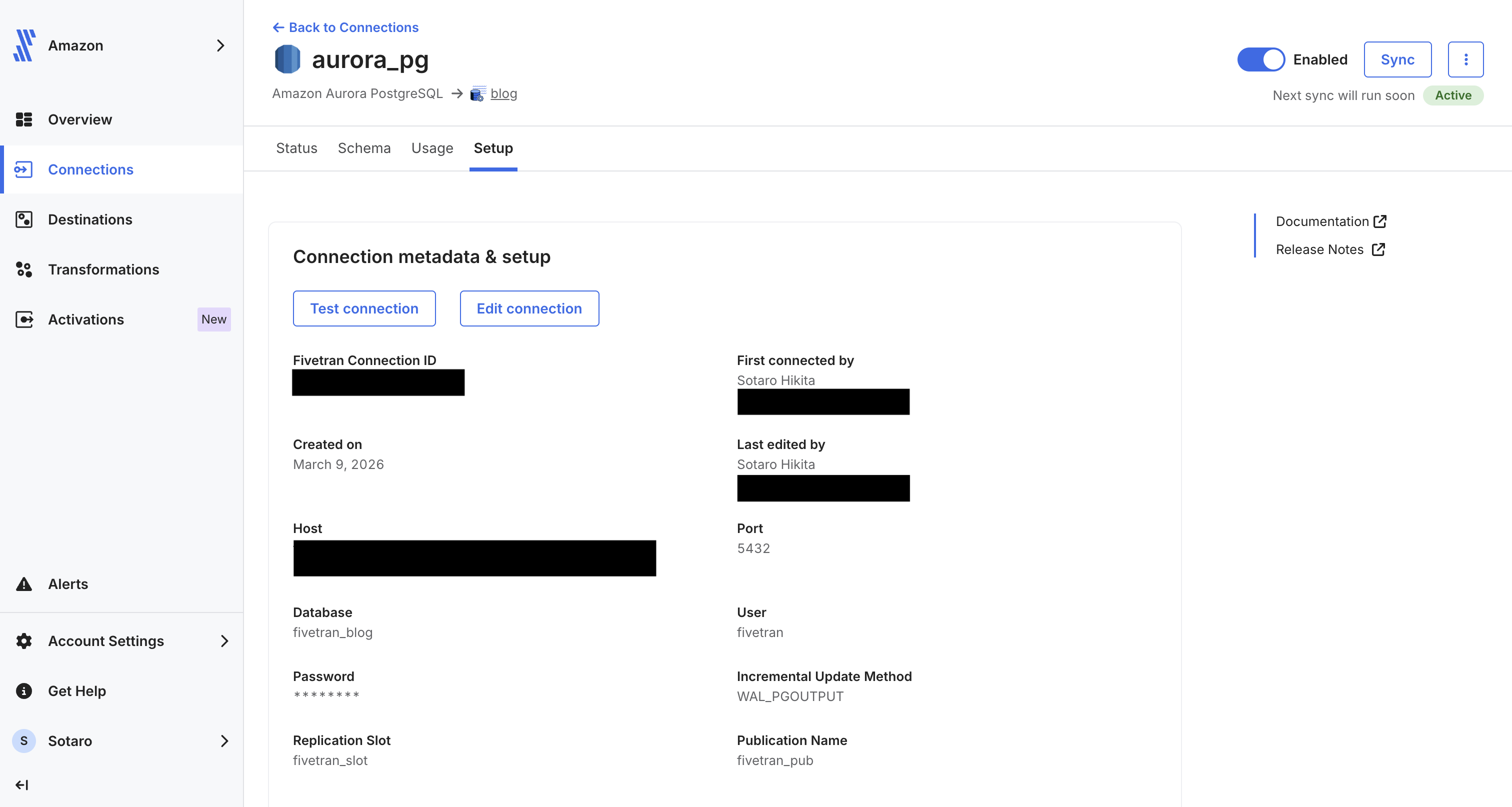
データ連携の設定と同期の開始
コネクションの設定画面では、同期対象のデータや連携方式に関する様々な設定を行うことができます。
コネクションの Schema タブでは、同期対象のテーブルやカラムを個別に選択できます。不要なテーブルを除外したり、機密性の高いカラムを連携対象から外すといった制御が可能です。
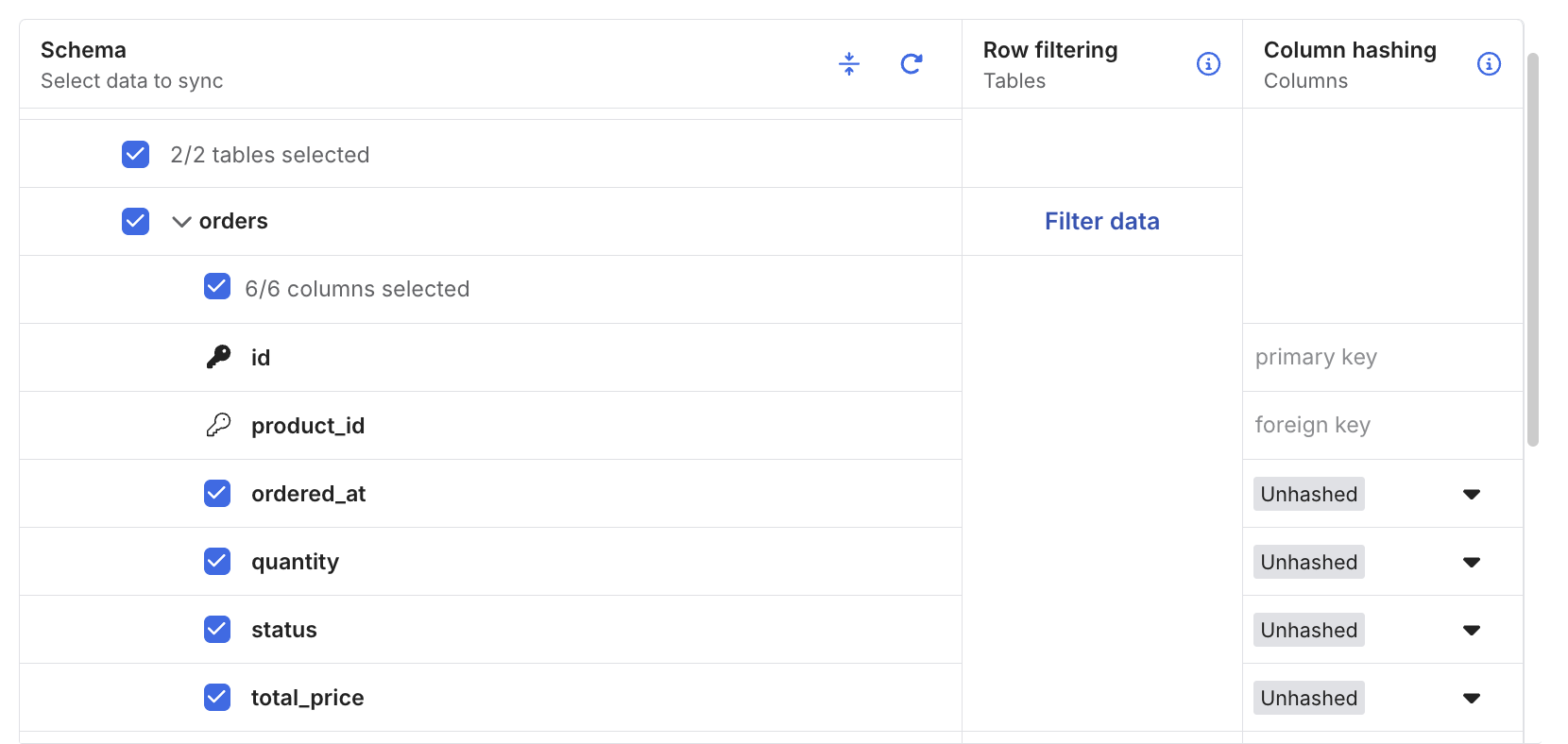
また、ソース側でテーブルやカラムが追加された場合の挙動を Schema Change Handling で制御できます。すべて自動で同期する(Allow all)、既存テーブルへのカラム追加のみ同期する(Allow columns)、すべてブロックする(Block all)の 3 つのオプションから選択できます。
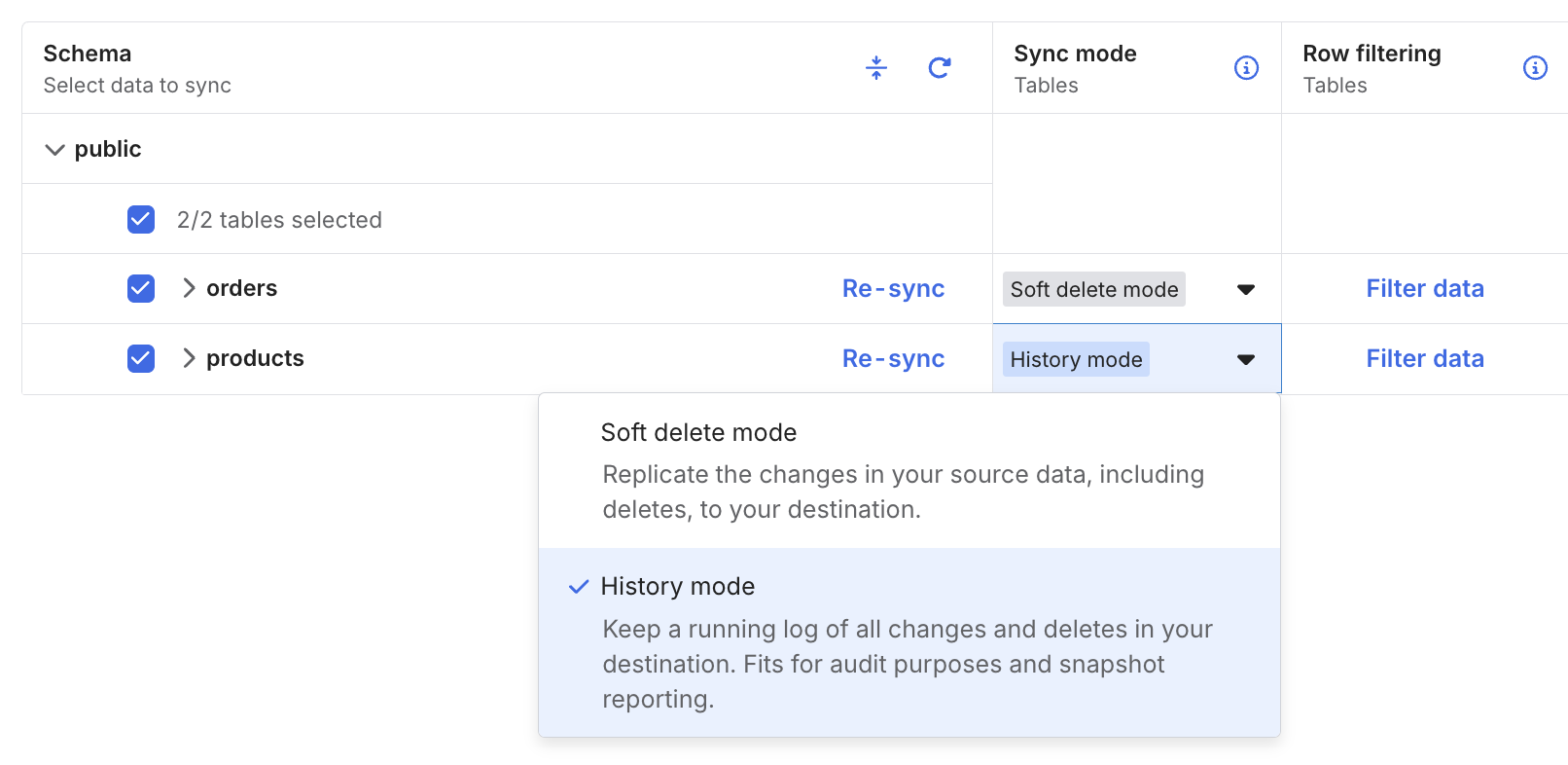
「Sync Mode」により、テーブルへの変更履歴の反映方法を設定できます。ソースの変更をそのまま反映したい場合は、「Soft delete mode」(デフォルト)を選択します。SCD Type 2 でデータを連携したい場合は、「History mode」を選択します。
今回はproducts テーブルの Sync Mode を History mode に変更し、SCD Type 2 での履歴管理を有効にしています。これにより、レコードの変更時に変更前の状態が履歴として保持されます。
同期の頻度は Sync frequency で設定します。プランに応じて最短 1 分間隔から選択できます。
これらの設定を行った上で Start Initial Sync をクリックすると、初回のフルロードが開始されます。ソーステーブルの既存データがすべて Iceberg テーブルに転送されます。
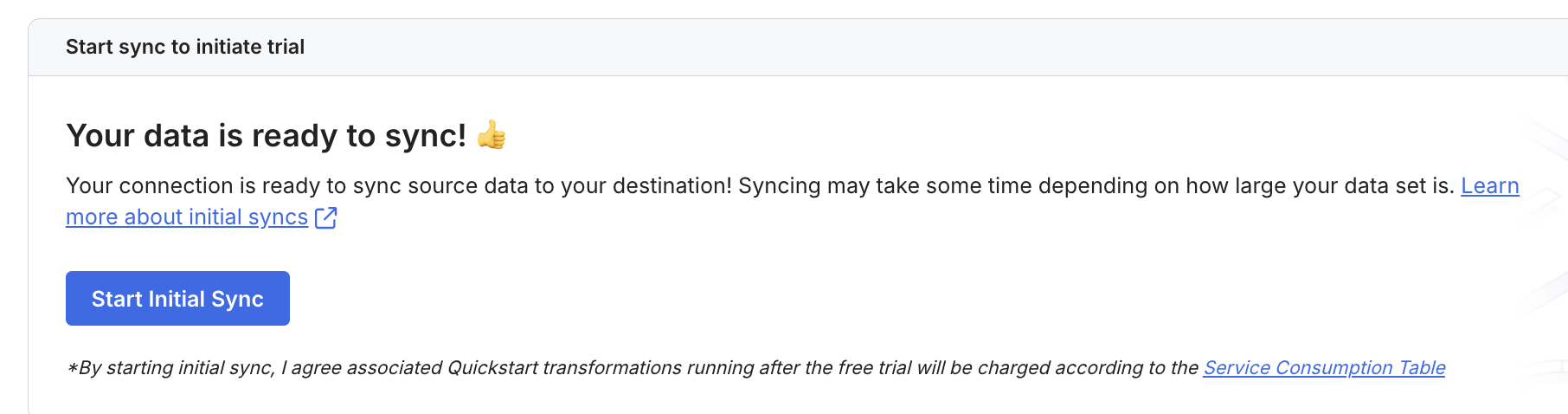
データ連携の確認
初回同期の確認
AWS マネージメントコンソールからGlue カタログを確認してみると、テーブルが連携されていることがわかります。
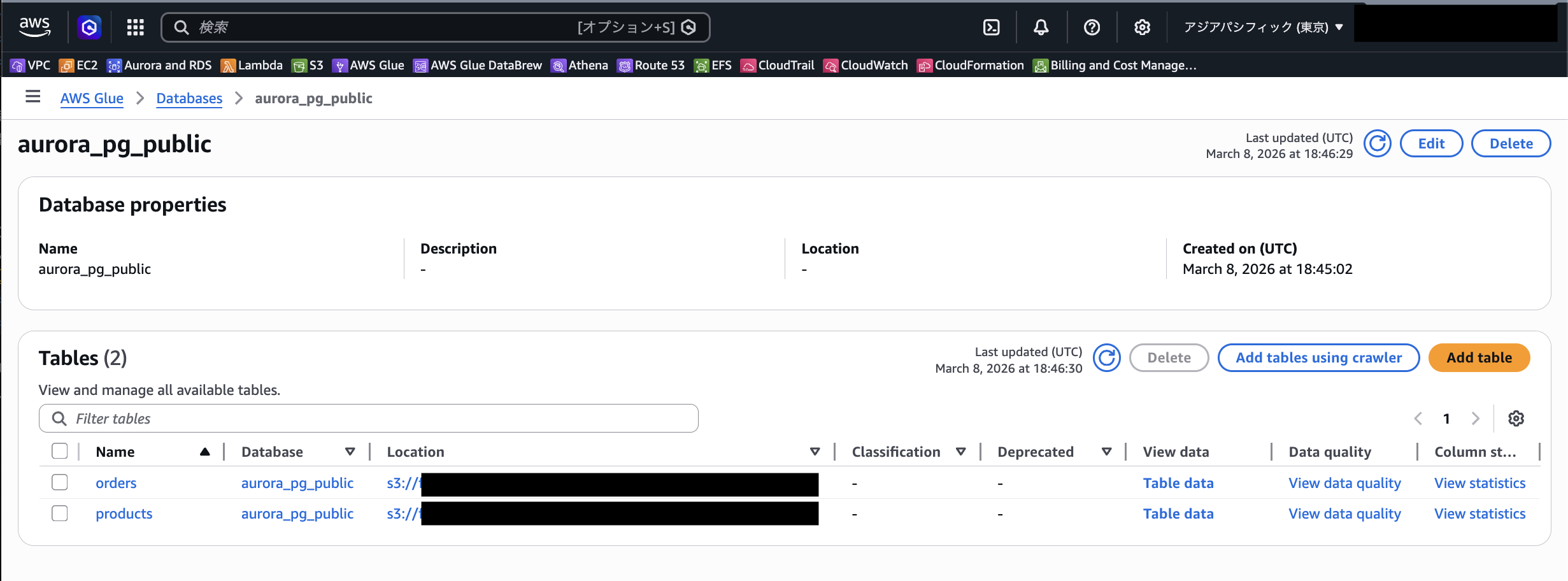
連携先の Iceberg テーブルは Amazon Athena や AWS Glue、Amazon Redshift などさまざまなエンジンからクエリすることが可能です。Iceberg テーブルへのクエリに対応している 3rd party の製品からのクエリももちろん可能です。
今回は、Amazon SageMaker Unified Studio の AI エージェントが組み込まれたノートブックから Amazon Athena でクエリを行ってみました。以下の通り、連携された Iceberg テーブルを簡単にクエリすることができました。
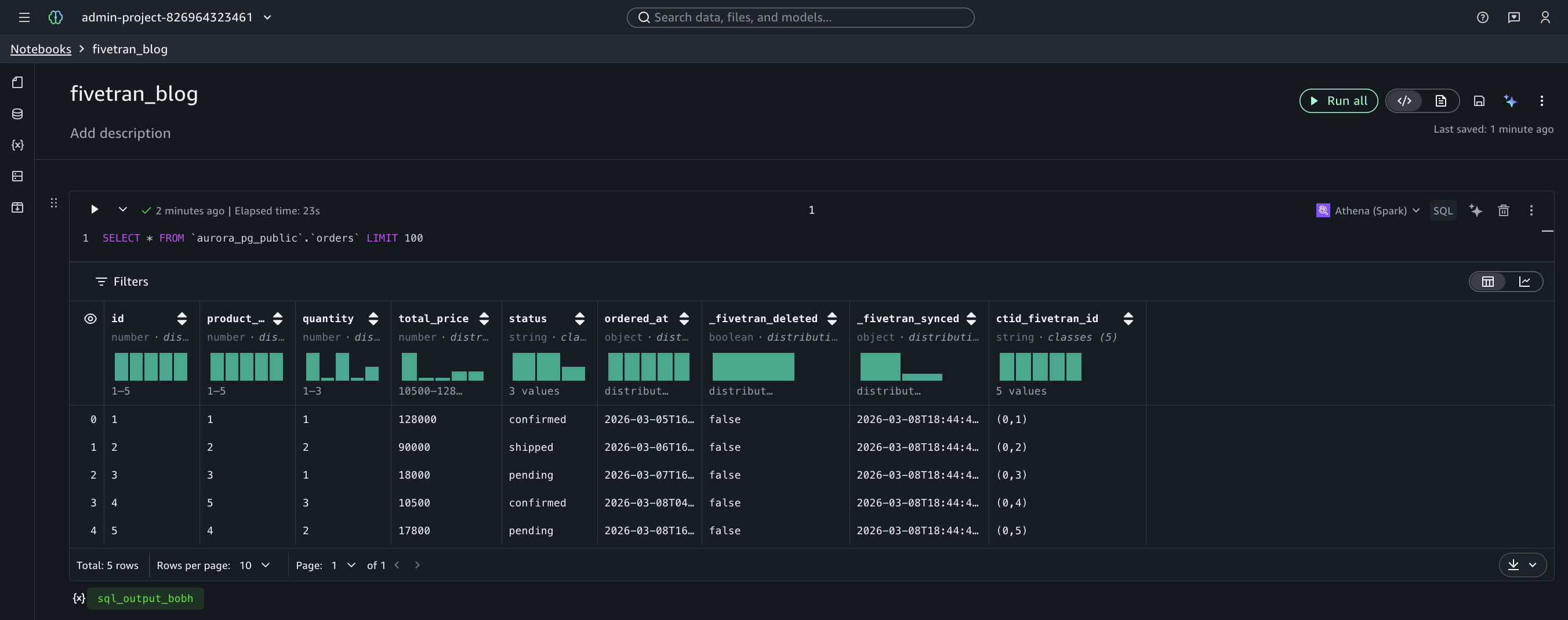
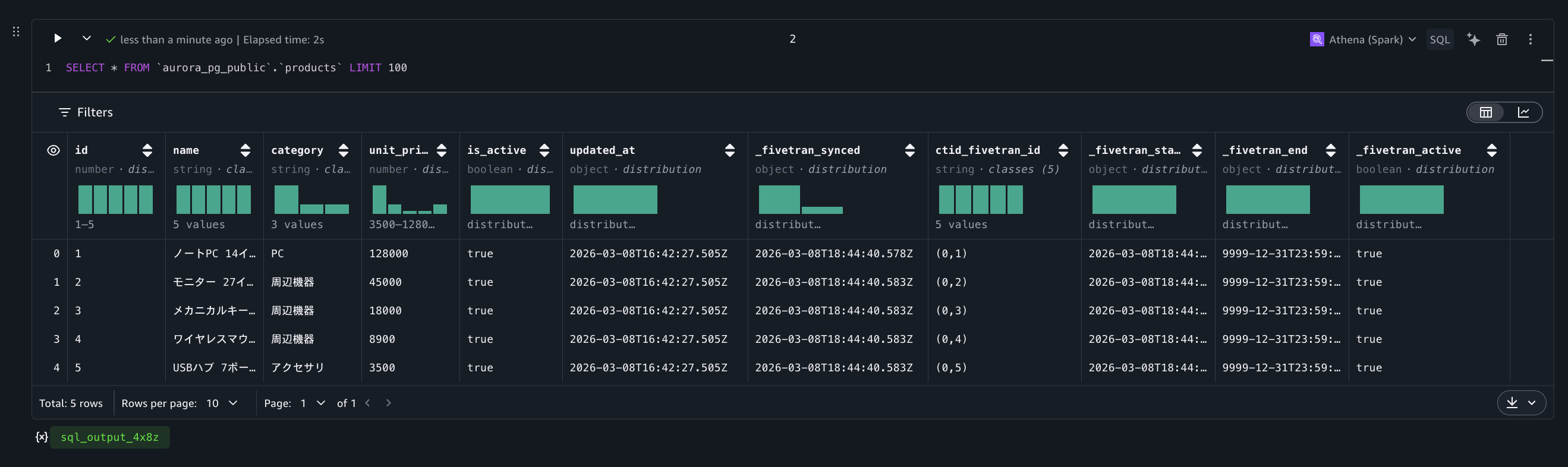
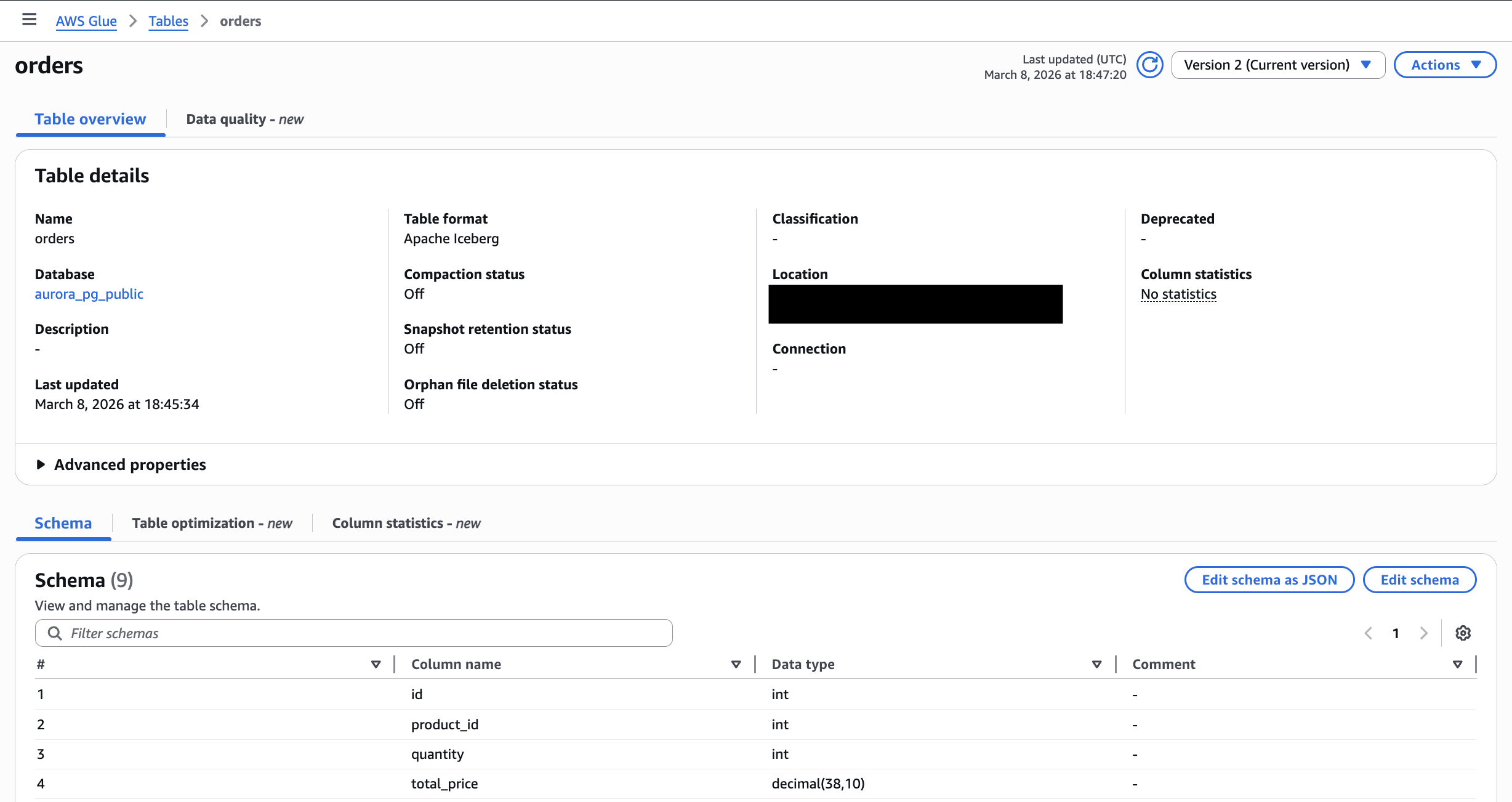
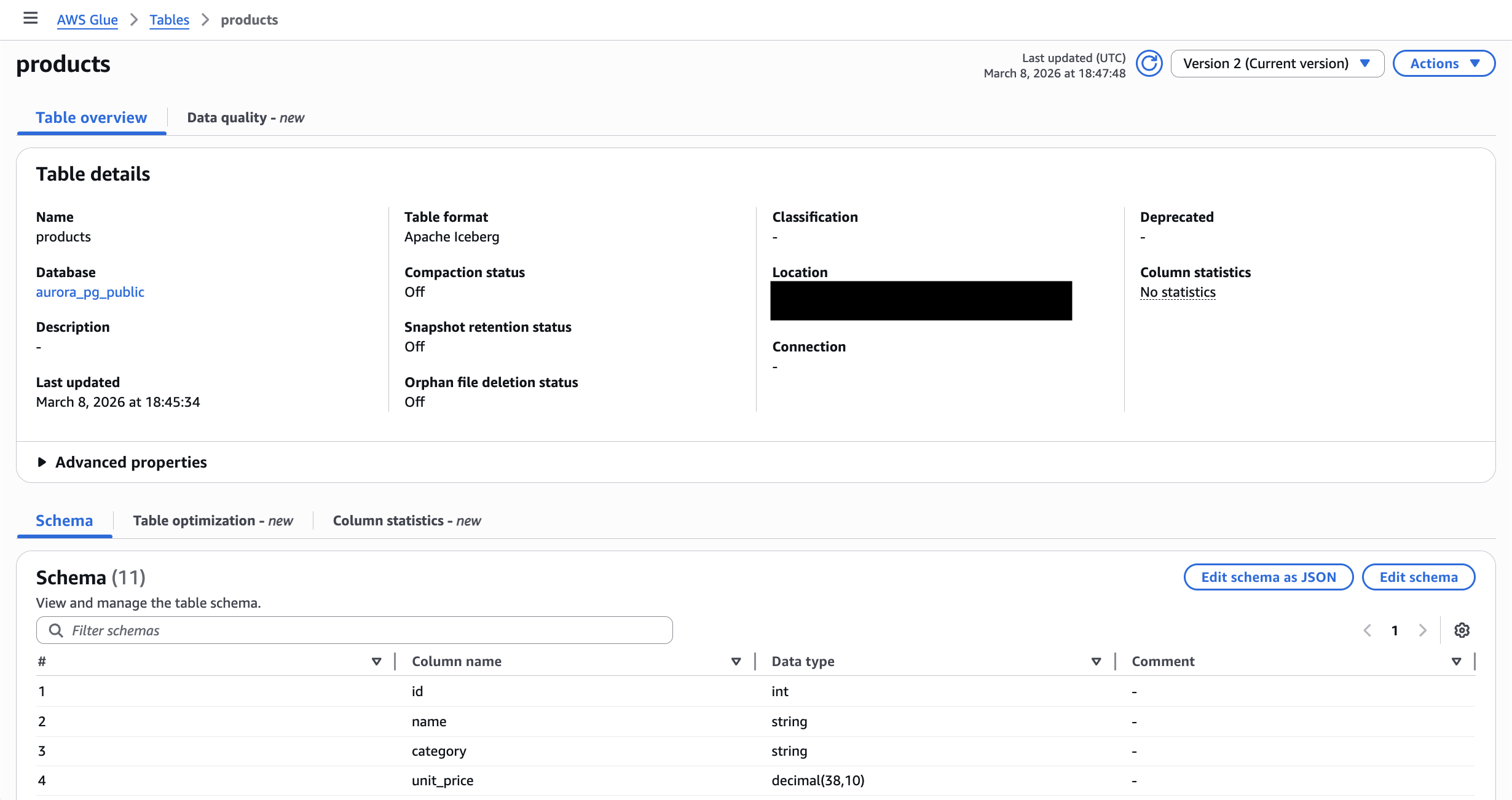
ソーステーブルのカラムに加えて、Fivetran が自動的に付与するメタデータカラムが確認できます。
orders テーブル(通常の CDC)では、以下のメタデータカラムが追加されています。
_fivetran_deleted: ソース側で削除されたレコードを示すフラグ。削除が検知されるとtrueになる_fivetran_synced: Fivetran がレコードを同期した日時
products テーブル(SCD Type 2)では、上記に加えて履歴管理のためのカラムが追加されています。
_fivetran_start: そのレコードが有効になった日時_fivetran_end: そのレコードが無効になった日時。現在有効なレコードは 9999-12-31T23:59:59.999Z_fivetran_active: 現在有効なレコードかどうかを示すフラグ
現時点ではすべてのレコードが _fivetran_active = true で、初回同期時点のスナップショットが格納されている状態です。ここからソースデータベースに変更を加え、CDC による差分連携と SCD Type 2 の履歴管理の動作を確認していきます。
CDC による差分連携の確認
初回同期の完了後、ソースデータベースに対して INSERT、UPDATE、DELETE を実行し、変更が Iceberg テーブルに反映されることを確認します。
-- 新しい受注の追加
INSERT INTO orders (product_id, quantity, total_price, status, ordered_at)
VALUES (1, 2, 256000, 'pending', NOW());
-- 受注ステータスの更新
UPDATE orders SET status = 'shipped' WHERE id = 3;
-- 受注のキャンセル(削除)
DELETE FROM orders WHERE id = 5;Fivetran の次回同期が実行された後、Athena で再度クエリを実行すると、これらの変更が反映されていることを確認できます。
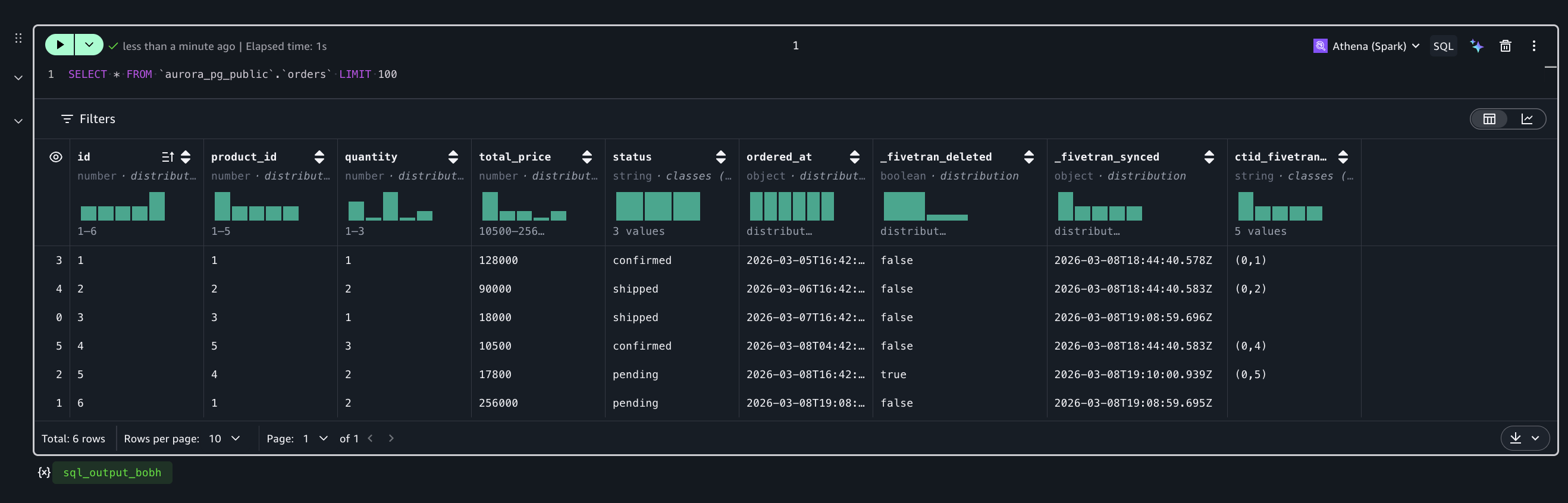
- id=6 として新しいレコードが追加されている(INSERT の反映)
- id=3 の status が
pendingからshippedに変更されている(UPDATE の反映) - id=5 の
_fivetran_deletedがtrueになっている(DELETE の反映)
DELETE されたレコードはテーブルから物理的に削除されるのではなく、_fivetran_deleted = true のフラグで論理削除として管理されます。これにより、削除の履歴を保持しつつ、分析時には WHERE _fivetran_deleted = false でフィルタすることで最新の有効データのみを参照できます。
SCD Type 2 による履歴管理の確認
products テーブルで商品の価格改定と販売終了を行い、SCD Type 2 による履歴管理を確認します。
-- 商品の価格改定
UPDATE products SET unit_price = 138000, updated_at = NOW() WHERE id = 1;
-- 商品の販売終了
UPDATE products SET is_active = false, updated_at = NOW() WHERE id = 5;Fivetran の同期後、Amazon Athena で products テーブルをクエリすると、変更前と変更後の両方のレコードが保持されていることを確認できます。
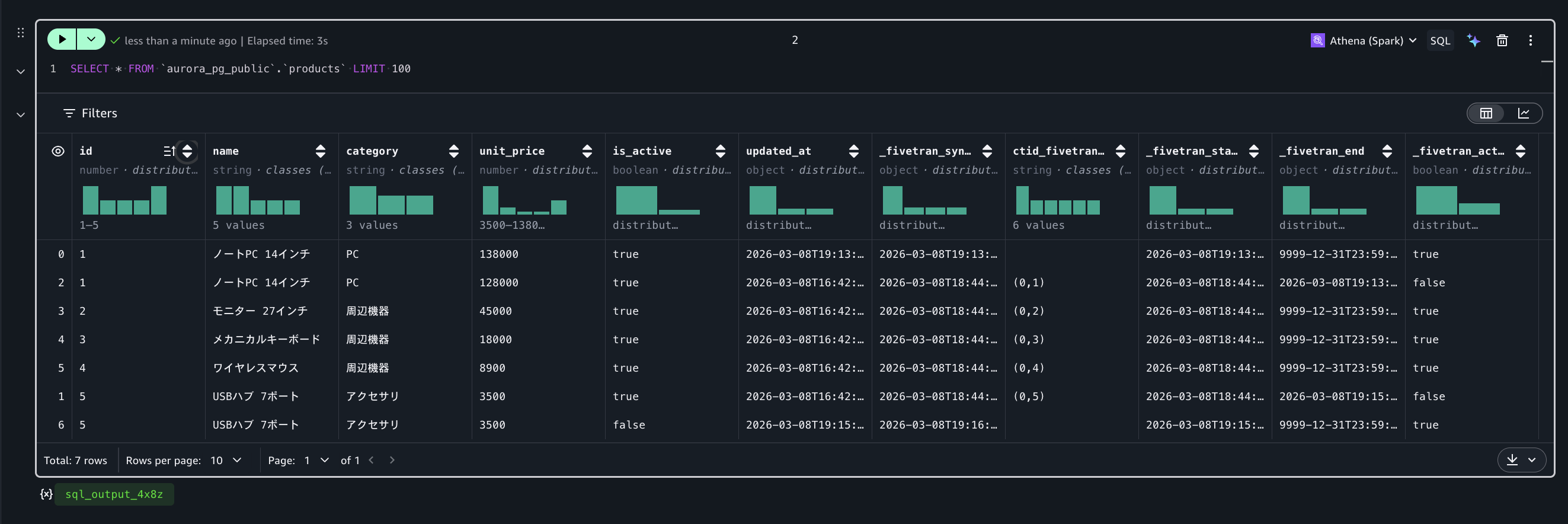
たとえば id=1(ノートPC 14インチ)では、価格改定前の unit_price=128,000 のレコードが _fivetran_active = false として残り、改定後の unit_price=138,000 のレコードが _fivetran_active = true として追加されます。同様に id=5(USBハブ 7ポート)では、is_active が true だった時点のレコードと false に変更された後のレコードがそれぞれ保持されます。
このように、ソース側では単純な UPDATE であっても、_fivetran_active = false のレコードも含めて参照することで「いつ、どのような値だったか」の履歴を分析できます。また、_fivetran_active = true のレコードのみを対象にクエリすることで、テーブルの最新の状態を参照することもできます。
以上のウォークスルーで確認した通り、Fivetran MDLS を使うことで Aurora PostgreSQL から Iceberg テーブルへの CDC パイプラインを、コードを書くことなく構築できました。通常の CDC による INSERT/UPDATE/DELETE の即時反映に加え、SCD Type 2 による変更履歴の自動蓄積、テーブル・カラム単位の同期制御やスキーマ変更への対応など、運用に必要な機能が設定画面上で完結しています。連携されたデータは Glue Data Catalog を通じて Athena からすぐにクエリでき、分析基盤としてすぐに活用を開始できる状態になります。
まとめ
本記事では、Fivetran Managed Data Lake Service 及び CDC 機能を活用し、業務システムの RDBMS から Amazon S3 上の Apache Iceberg テーブルへリアルタイムにデータを連携する構成を紹介しました。Fivetran の Binary Log Reader による低負荷な変更データ取得と、AWS Glue データカタログへの自動メタデータ同期により、OLTP/OLAP の分離やバッチ処理のオフロードといったユースケースをシンプルな構成で実現が可能となります。