Amazon Web Services 한국 블로그
Amazon EC2 Inf2 인스턴스 정식 출시 – 저비용 고성능 생성 AI 추론 가능
딥 러닝(Deep Learning, DL)의 혁신, 특히 대규모 언어 모델(Large Langage Model, LLM)의 급속한 성장이 업계를 강타했습니다. DL 모델은 수백만 ~ 수십억 개의 파라미터로부터 성장했으며 흥미롭고 새로운 기능을 보여주고 있습니다. DL 모델은 생성 AI (Generative AI) 또는 의료 및 생명과학 분야의 첨단 연구에 새롭게 적용되고 있습니다. AWS는 이러한 DL 워크로드를 대규모로 가속화하기 위해 칩, 서버, 데이터 센터 연결 및 소프트웨어 전반을 혁신해 왔습니다.
AWS re:Invent 2022에서 AWS에서 설계한 최신 ML 칩인 AWS Inferentia2로 구동되는 Amazon EC2 Inf2 인스턴스의 미리 보기를 발표한 바 있습니다. Inf2 인스턴스는 고성능 DL 추론 애플리케이션을 전역적으로 대규모로 실행하도록 설계되었습니다. Inf2 인스턴스는 Amazon EC2에서 GPT-J 또는 OPT(Open Pre-trained Transformer) 언어 모델과 같은 생성 AI의 최신 혁신 기술을 배포하기 위한 가장 비용 효율적이고 에너지 효율적인 방법입니다.
오늘 Amazon EC2 Inf2 인스턴스를 정식 출시합니다.
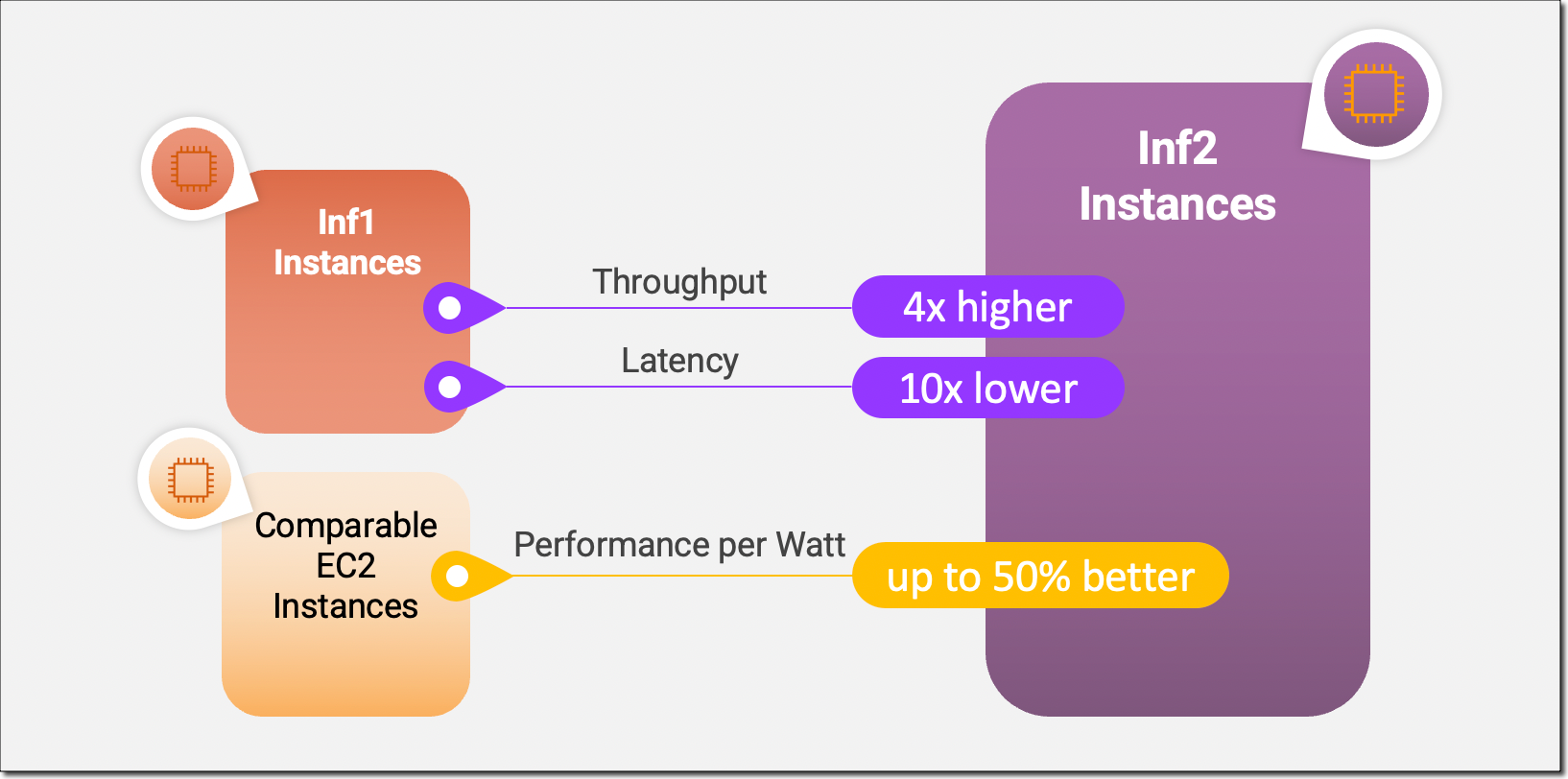
EC2 Inf2 인스턴스는 액셀러레이터 간 초고속 연결을 통해 확장형 분산 추론을 지원하는 Amazon EC2 최초의 추론 최적화 인스턴스입니다. 이제 Inf2 인스턴스의 여러 액셀러레이터에서 수천억 개의 파라미터가 포함된 모델을 효율적으로 배포할 수 있습니다. Amazon EC2 Inf1 인스턴스와 비교할 때 Inf2 인스턴스는 처리량이 최대 4배 더 많고 지연 시간은 최대 10배 더 짧습니다. 다음은 새 Inf2 인스턴스의 주요 성능 개선 사항을 강조하는 인포그래픽입니다.
새로운 Inf2 인스턴스 주요 특징
Inf2 인스턴스는 현재 네 가지 크기로 제공되며 최대 12개의 AWS Inferentia2 칩 및 192개의 vCPU로 구동됩니다. BF16 또는 FP16 데이터 형식에서 2.3 petaFLOPS의 통합 컴퓨팅 성능을 제공하며 칩 간 초고속 NeuronLink 상호 연결을 제공합니다. NeuronLink는 여러 Inferentia2 칩에서 대규모 모델을 확장하고 통신 병목 현상을 방지하며 고성능 추론 지원합니다.
Inf2 인스턴스는 최대 384GB의 공유 액셀러레이터 메모리와 모든 Inferentia2 칩에 32GB 고대역폭 메모리(HBM) 및 9.8TB/s의 총 메모리 대역폭을 제공합니다. 이러한 유형의 대역폭은 메모리에 바인딩되는 대규모 언어 모델에 대한 추론을 지원하는 데 특히 중요합니다.
기본 AWS Inferentia2 칩은 DL 워크로드용으로 특별히 제작되었으므로 Inf2 인스턴스는 다른 유사한 Amazon EC2 인스턴스보다 와트당 최대 50% 더 나은 성능을 제공합니다. AWS Inferentia2 실리콘 혁신에 대한 자세한 내용은 이 블로그 게시물 후반부에서 다루겠습니다.
다음 표에는 Inf2 인스턴스의 크기 및 사양이 자세히 나와 있습니다.
| 인스턴스 이름
|
vCPU | AWS Inferentia2 칩 | 액셀러레이터 메모리 | NeuronLink | 인스턴스 메모리 | 인스턴스 네트워킹 |
| inf2.xlarge | 4 | 1 | 32GB | N/A | 16GB | 최대 15Gbps |
| inf2.8xlarge | 32 | 1 | 32GB | N/A | 128GB | 최대 25Gbps |
| inf2.24xlarge | 96 | 6 | 192GB | 예 | 384GB | 50Gbps |
| inf2.48xlarge | 192 | 12 | 384GB | 예 | 768GB | 100Gbps |
AWS Inferentia2 혁신
AWS Trainium 칩과 마찬가지로, 각 AWS Inferentia2 칩에는 향상된 NeuronCore-v2 엔진 2개, HBM 스택 및 다중 액셀러레이터 추론을 수행할 때 계산 및 통신 작업을 병렬화하는 집합적인 전용 컴퓨팅 엔진이 있습니다.
각 NeuronCore-v2에는 DL 알고리즘용으로 특별히 구축된 전용 스칼라, 벡터 및 텐서 엔진이 있습니다. 텐서 엔진은 행렬 연산에 최적화되어 있습니다. 스칼라 엔진은 ReLU(Rectified Linear Unit) 함수와 같은 요소별 연산에 최적화되어 있습니다. 벡터 엔진은 배치 정규화 또는 풀링을 비롯한 비요소별 벡터 연산에 최적화되어 있습니다.
다음은 추가적인 AWS Inferentia2 칩 및 서버 하드웨어 혁신에 대한 간략한 요약입니다.
- 데이터 형식 – AWS Inferentia2는 FP32, TF32, BF16, FP16, UINT8 등 다양한 데이터 형식을 지원하므로 워크로드에 가장 적합한 데이터 형식을 선택할 수 있습니다. 또한 새로운 구성 가능한 FP8(cFP8) 데이터 형식을 지원하는데, 이 형식은 모델의 메모리 공간과 I/O 요구 사항을 줄여 주므로 대형 모델에 특히 적합합니다. 다음 이미지는 지원되는 데이터 형식을 비교합니다.

- 동적 실행, 동적 입력 셰이프 — AWS Inferentia2에는 동적 실행을 지원하는 범용 디지털 신호 프로세서(DSP) 가 내장되어 있으므로 제어 흐름 연산자를 호스트에서 언롤링하거나 실행할 필요가 없습니다. AWS Inferentia2는 또한 텍스트를 처리하는 모델과 같이 입력 텐서 크기를 알 수 없는 모델의 핵심인 동적 입력 셰이프를 지원합니다.
- 사용자 지정 연산자 — AWS Inferentia2는 C++로 작성된 사용자 지정 연산자를 지원합니다. Neuron 사용자 지정 C++ 연산자를 사용하면 NeuronCore에서 기본적으로 실행되는 C++ 사용자 지정 연산자를 작성할 수 있습니다. 표준 PyTorch 사용자 지정 연산자 프로그래밍 인터페이스를 사용하여 NeuronCore 하드웨어에 대한 자세한 지식 없이도 CPU 사용자 지정 연산자를 Neuron으로 마이그레이션하고 새로운 실험 연산자를 구현할 수 있습니다.
- NeuronLink v2 — Inf2 인스턴스는 칩 간의 직접적인 초고속 연결(NeuronLink v2)을 통해 분산 추론을 지원하는 Amazon EC2 최초의 추론 최적화 인스턴스입니다. NeuronLink v2는 all-reduce와 같은 집합 통신(CC) 연산자를 사용하여 모든 칩에서 고성능 추론 파이프라인을 실행합니다.
다음 Inf2 분산 추론 벤치마크는 유사한 추론 최적화 Amazon EC2 인스턴스에 비해 OPT-30B 및 OPT-66B 모델의 처리량 및 비용 개선을 보여줍니다.

이제 Amazon EC2 Inf2 인스턴스를 시작하는 방법을 보여 드리겠습니다.
Inf2 인스턴스 시작하기
AWS Neuron SDK는 AWS Inferentia2를 PyTorch와 같은 인기 있는 기계 학습(ML) 프레임워크에 통합합니다. Neuron SDK에는 컴파일러, 런타임 및 프로파일링 도구가 포함되어 있으며, 새 기능과 성능 최적화로 지속적으로 업데이트되고 있습니다.
이 예제에서는 사용 가능한 PyTorch Neuron 패키지를 사용하여 Hugging Face의 사전 훈련된 BERT 모델을 컴파일하고 EC2 Inf2 인스턴스에 배포해 보겠습니다. PyTorch Neuron은 PyTorch XLA 소프트웨어 패키지를 기반으로 하며 PyTorch 작업을 AWS Inferentia2 명령으로 변환할 수 있습니다.
SSH를 Inf2 인스턴스에 연결하고 PyTorch Neuron 패키지가 포함된 Python 가상 환경을 활성화합니다. Neuron 제공 AMI를 사용하는 경우 다음 명령을 실행하여 사전 설치된 환경을 활성화할 수 있습니다.
source aws_neuron_venv_pytorch_p37/bin/activate이제 코드를 몇 가지 변경하기만 하면 PyTorch 모델을 AWS Neuron에 최적화된 TorchScript로 컴파일할 수 있습니다. 먼저 torch, PyTorch Neuron 패키지 torch_neuronx, Hugging Face transformers 라이브러리를 가져오겠습니다.
import torch
import torch_neuronx from transformers import AutoTokenizer, AutoModelForSequenceClassification
import transformers
...다음으로 토크나이저와 모델을 만들어 보겠습니다.
name = "bert-base-cased-finetuned-mrpc"
tokenizer = AutoTokenizer.from_pretrained(name)
model = AutoModelForSequenceClassification.from_pretrained(name, torchscript=True)예제 입력으로 모델을 테스트할 수 있습니다. 모델은 입력으로 두 문장을 예상하며, 출력은 해당 문장이 서로 패러프레이즈이거나 아니거나입니다.
def encode(tokenizer, *inputs, max_length=128, batch_size=1):
tokens = tokenizer.encode_plus(
*inputs,
max_length=max_length,
padding='max_length',
truncation=True,
return_tensors="pt"
)
return (
torch.repeat_interleave(tokens['input_ids'], batch_size, 0),
torch.repeat_interleave(tokens['attention_mask'], batch_size, 0),
torch.repeat_interleave(tokens['token_type_ids'], batch_size, 0),
)
# Example inputs
sequence_0 = "The company Hugging Face is based in New York City"
sequence_1 = "Apples are especially bad for your health"
sequence_2 = "Hugging Face's headquarters are situated in Manhattan"
paraphrase = encode(tokenizer, sequence_0, sequence_2)
not_paraphrase = encode(tokenizer, sequence_0, sequence_1)
# Run the original PyTorch model on examples
paraphrase_reference_logits = model(*paraphrase)[0]
not_paraphrase_reference_logits = model(*not_paraphrase)[0]
print('Paraphrase Reference Logits: ', paraphrase_reference_logits.detach().numpy())
print('Not-Paraphrase Reference Logits:', not_paraphrase_reference_logits.detach().numpy())다음과 같은 출력을 얻을 수 있습니다.
Paraphrase Reference Logits: [[-0.34945598 1.9003887 ]]
Not-Paraphrase Reference Logits: [[ 0.5386365 -2.2197142]]이제 torch_neuronx.trace () 메서드는 컴파일을 위해 Neuron Compiler(neuron-cc)로 작업을 전송하고 컴파일된 아티팩트를 TorchScript 그래프에 포함합니다. 메서드는 인수로서 예제 입력의 튜플과 모델을 예상합니다.
neuron_model = torch_neuronx.trace(model, paraphrase)예제 입력으로 Neuron 컴파일 모델을 테스트해 보겠습니다.
paraphrase_neuron_logits = neuron_model(*paraphrase)[0]
not_paraphrase_neuron_logits = neuron_model(*not_paraphrase)[0]
print('Paraphrase Neuron Logits: ', paraphrase_neuron_logits.detach().numpy())
print('Not-Paraphrase Neuron Logits: ', not_paraphrase_neuron_logits.detach().numpy())다음과 같은 출력을 얻을 수 있습니다.
Paraphrase Neuron Logits: [[-0.34915772 1.8981738 ]]
Not-Paraphrase Neuron Logits: [[ 0.5374032 -2.2180378]]이것으로 완료되었습니다. 몇 줄의 코드 변경만으로 Amazon EC2 Inf2 인스턴스에서 PyTorch 모델을 컴파일하고 실행했습니다. AWS Inferentia2와 현재 모델 지원 매트릭스에 적합한 DL 모델 아키텍처에 대해 자세히 알아보려면 AWS Neuron 설명서를 참조하십시오.
지금 이용 가능
지금 AWS 미국 동부(오하이오) 및 미국 동부(버지니아 북부) 리전에서 온디맨드, 예약 및 스팟 인스턴스 또는 Savings Plan의 일부로 Inf2 인스턴스를 시작할 수 있습니다. Amazon EC2와 마찬가지로 사용한 만큼만 비용을 지불하면 됩니다. 자세한 내용은 Amazon EC2 요금을 참조하세요.
Inf2 인스턴스는 AWS Deep Learning AMI를 사용하여 배포할 수 있으며, 컨테이너 이미지는 Amazon SageMaker, Amazon Elastic Kubernetes Service(Amazon EKS), Amazon Elastic Container Service(Amazon ECS), AWS ParallelCluster 등의 관리형 서비스를 통해 사용할 수 있습니다.
자세한 내용을 알아보려면 Amazon EC2 Inf2 인스턴스 페이지를 참조하시고, 피드백을 보내시려면 AWS re:Post for EC2를 이용하시거나 평소 교류하는 AWS Support 담당자를 통해 전달해 주세요.
– Antje