분산 시스템의 도전 과제
아키텍처 | 레벨 200
소개
두 번째 서버를 추가하면서 분산 시스템은 Amazon에서 기본 양식이 되었습니다. 제가 1999년 Amazon에 입사했을 때는 서버가 많지 않아서 "fishy"나 "online-01"과 같은 알기 쉬운 이름을 서버에 붙여주기도 합니다. 하지만 1999년에도 분산 컴퓨팅은 쉽지 않았습니다. 그리고 현재, 분산 시스템은 지연 시간, 확장, 네트워킹 API의 이해, 데이터 마샬링 및 마샬링 해제, Paxos와 같은 복잡한 알고리즘과 같은 도전 과제를 안고 있습니다. 시스템이 더 커지고 더 분산되면서, 이론상의 엣지 사례가 일반화되고 있습니다.
안정적인 장거리 전화 네트워크나 Amazon Web Services(AWS) 서비스와 같은 분산 유틸리티 컴퓨팅 서비스 개발도 어려운 일이 되었습니다. 분산 컴퓨팅은 두 가지 연관된 문제 때문에 다른 양식의 컴퓨팅보다 더 특이하고 직관성도 떨어집니다. 바로 독립된 실패와 비결정성이라는 문제는 분산 시스템에서 가장 영향력이 큰 문제를 일으킵니다. 대부분의 엔지니어에게 익숙한 일반적인 컴퓨팅 실패 외에도, 분산 시스템에서의 실패는 여러 방식으로 발생할 수 있습니다. 더 최악은 실패했는지 여부도 항상 파악하지는 못한다는 점입니다.
Amazon Builders 라이브러리에서 저희는 AWS가 분산 시스템에서 발생하는 복잡한 개발 및 운영 문제를 처리하는 방법을 설명합니다. 다른 글에서 이러한 기술을 자세히 설명하기 전에, 분산 컴퓨팅이 조금 특이한 이유를 설명해주는 개념들을 검토해보려고 합니다. 먼저, 분산 시스템의 유형부터 살펴보겠습니다.
분산 시스템 유형
분산 시스템은 실제로 구현의 난이도가 매우 다양합니다. 그 다양성 범위의 한 끝에는 오프라인 분산 시스템이 있습니다. 여기에는 배치 처리 시스템, 빅 데이터 분석 클러스터, 동영상 화면 렌더링 팜, 프로틴 폴딩 클러스터 등이 포함됩니다. 오프라인 분산 시스템은 구현하기는 어려워도 분산 컴퓨팅의 모든 장점(확장성 및 내결함성)을 갖고 있으며, 단점(복잡한 실패 모드 및 비결정성)은 거의 없습니다.
그리고 다양성의 한가운데에는 소프트 실시간 분산 시스템이 있습니다. 이는 지속적으로 결과를 생성하거나 업데이트해야 하는 중요한 시스템이지만, 비교적 작업 수행 기간이 관대한 편입니다. 이러한 시스템의 예로는, 일부 검색 인덱스 빌더, 손상된 서버를 검색하는 시스템, Amazon Elastic Compute Cloud(Amazon EC2)에 대한 역할 등이 있습니다. 검색 인덱스는 과도한 고객 영향 없이도 10분에서 여러 시간에 걸쳐 애플리케이션에 따라 오프라인 상태가 될 수 있습니다. Amazon EC2에 대한 역할은 모든 EC2 인스턴스에 업데이트된 자격 증명을 푸시해야 하지만, 오래된 자격 증명은 일정 시간 만료되지 않으므로 작업 시간에 몇 시간 정도 여유가 있습니다.
그리고 다양성 범위에서 가장 끝에 있는 가장 까다로운 시스템으로는 하드 실시간 분산 시스템이 있습니다. 종종 요청/회신 서비스라고도 합니다. Amazon에서 저희가 분산 시스템 구축을 고려할 때 하드 실시간 시스템을 제일 먼저 떠올렸습니다. 하지만 하드 실시간 분산 시스템은 올바르게 구현하기 가장 어렵습니다. 어려운 이유는, 예를 들어 고객이 응답을 바로 기다리는 경우처럼 요청이 예상치 않게 도착하고 응답을 빨리 제공해야 하기 때문입니다. 프런트 엔드 웹 서버, 주문 파이프라인, 신용카드 거래, 모든 AWS API, 전화 통신 등이 이에 해당합니다. 그리고 이 글에서는 하드 실시간 분산 시스템을 중점적으로 다루려고 합니다.
하드 실시간 시스템의 특이성
슈퍼맨 줄거리 중에 슈퍼맨이 모든 것이 반대인 한 행성(비자로 월드)에 사는 자신의 복제인 비자로를 만나는 이야기가 있습니다. 비자로는 슈퍼맨과 비슷해 보이지만, 실제로는 악당입니다. 하드 실시간 분산 시스템도 마찬가지입니다. 일반 컴퓨팅 종류처럼 보이지만, 실제로는 너무 어렵고 솔직히 악랄한 부분도 있습니다.
하드 실시간 분산 시스템 개발은 요청/회신 네트워킹, 이 한 가지 이유로 매우 특이합니다. TCP/IP, DNS, 소켓 또는 이러한 다른 프로토콜의 핵심적인 부분을 말하는 것은 아닙니다. 이 주제는 이해하긴 어려워도, 컴퓨팅의 다른 난제들과 비슷합니다.
하드 실시간 분산 시스템이 어려운 이유는, 하나의 결함 도메인에서 다른 도메인으로 네트워크가 메시지를 전송할 수 있다는 점에 기인합니다. 메시지 전송 자체는 무해할 수 있습니다. 하지만 실제로 메시지가 전송되면 모든 작업이 보통 때보다 더 복잡해지기 시작합니다.
간단한 예로, 팩맨 구현 중 다음 코드 조각을 살펴보겠습니다. 단일 머신에서 실행하려고 하므로, 네트워크에서 메시지를 전송하지 않습니다.
board.move(pacman, user.joystickDirection())
ghosts = board.findAll(":ghost")
for (ghost in ghosts)
if board.overlaps(pacman, ghost)
user.slayBy(":ghost")
board.remove(pacman)
return
이제 네트워크로 연결된 이 코드 버전을 개발한다고 가정합니다. 그러면 보드 객체 상태가 별도의 서버에서 관리됩니다. findAll()과 같이 보드 객체를 호출할 때마다 두 서버 간에 메시지를 주고 받습니다.
두 서버 간에 요청/회신 메시지가 전송될 때마다 최소 8단계 이상의 동일한 세트가 항상 수행되어야 합니다. 네트워크로 연결된 팩맨 코드를 이해하기 위해 요청/회신 메시징의 기초를 검토해보겠습니다.
네트워크를 통한 메시징
네트워크에서 요청/회신 메시징
1회 왕복의 요청/회신 작업은 항상 동일한 단계를 포함합니다. 다음 그림과 같이, 클라이언트 머신 CLIENT는 네트워크 NETWORK를 통해 요청 MESSAGE를 서버 머신 SERVER로 전송하고, 이 서버에서는 메시지 REPLY로 역시나 네트워크 NETWORK를 통해 회신합니다.
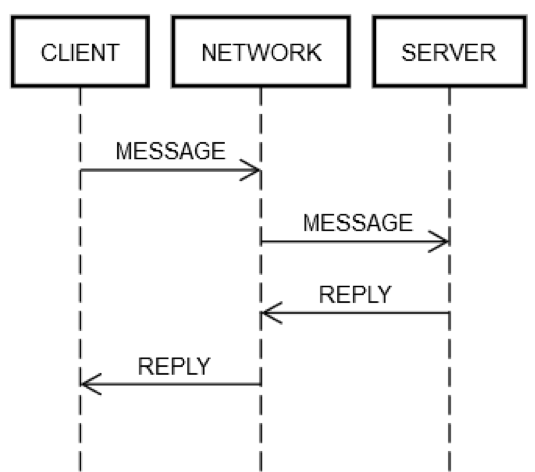
모두 잘 작동하는 경우에 다음 단계가 수행됩니다.
-
요청 게시: CLIENT가 NETWORK에 요청 MESSAGE를 넣습니다.
-
요청 전송: NETWORK가 MESSAGE를 SERVER로 전송합니다.
-
요청 검증: SERVER가 MESSAGE를 검증합니다.
-
서버 상태 업데이트: SERVER가 필요한 경우 MESSAGE에 따라 서버 상태를 업데이트합니다.
-
회신 게시: SERVER가 회신 REPLY를 NETWORK에 넣습니다.
-
회신 전송: NETWORK가 REPLY를 CLIENT로 전송합니다.
-
회신 검증: CLIENT가 REPLY를 검증합니다.
-
클라이언트 상태 업데이트: CLIENT가 필요한 경우 REPLY에 따라 클라이언트 상태를 업데이트합니다.
이 짧은 한 번 왕복에도 꽤 많은 단계가 포함됩니다! 하지만 이 단계는 네트워크에서 요청/회신 통신의 정의에 해당하며, 이중 한 단계도 건너뛸 수 없습니다. 예를 들어, 1단계는 건너뛸 수 없습니다. 클라이언트는 어떻게든 MESSAGE를 네트워크 NETWORK에 넣어야 합니다. 실제로, 네트워크 어댑터를 통해 패킷 전송을 의미하므로 전기 신호가 CLIENT와 SERVER 사이에서 네트워크를 구성하는 일련의 라우터를 통해 와이어로 전송됩니다. 이는 2단계와는 별개입니다. 2단계는 독립된 이유로 실패할 수 있습니다. 예를 들어, SERVER에서 갑자기 전원이 끊어져 수신 패킷을 수락하지 못할 수 있기 때문입니다. 동일한 논리가 나머지 단계에도 적용될 수 있습니다.
따라서 네트워크에서 수행되는 하나의 요청/회신은 하나의 작업(메서드 호출)을 8단계로 분해합니다. 위에서 언급한 대로, 더 안 좋은 점은 CLIENT, SERVER 및 NETWORK가 서로 독립적으로 실패할 수 있다는 점입니다. 엔지니어의 코드는 이전 실패를 설명하는 모든 단계를 처리해야 합니다. 일반적인 엔지니어링에서는 매우 드문 일입니다. 그 이유를 알아내려면 코드의 단일 머신 버전에서 다음 식을 검토합니다.
board.find("pacman")
엄밀히 말하면, board.find 구현 자체에서는 버그가 발생할 수 없어도 특이한 방식으로 런타임에 이 코드가 실패할 수 있습니다. 예를 들어, CPU는 런타임에 자연스럽게 과열될 수 있습니다. 머신의 전원 공급 장치에서 장애가 발생하는 일도 자연스러운 일입니다. 커널에서도 문제가 발생할 수 있습니다. 메모리도 가득 찰 수 있으며, board.find에서 생성하려는 일부 객체를 생성하지 못할 수도 있습니다. 아니면 머신이 실행 중인 디스크가 가득 찰 수 있으며, 그럴 일은 없겠지만 board.find가 일부 통계 파일을 업데이트하지 못하고 오류를 반환할 수 있습니다. 서버가 감마선에 노출되고 RAM에서 비트가 반전될 수도 있습니다. 하지만 대부분의 경우 엔지니어는 이런 일들을 걱정하지 않습니다. 예를 들어, 단위 테스트에서는 "CPU 장애가 발생하는 경우"와 같은 가상 시나리오를 다루지 않으며, 오직 드물게 메모리 부족 시나리오만 검토합니다.
일반적인 엔지니어링에서 이러한 종류의 장애는 단일 머신에서 발생합니다. 즉, 단일 결함 도메인에 해당합니다. 예를 들어, CPU에서 자연스럽게 과열되어 board.find 메서드에서 실패한 경우 전체 머신이 중단된다고 가정하는 것이 안전합니다. 이론적으로 이러한 오류를 처리할 수 없는 경우도 마찬가지입니다. 앞서 언급한 다른 오류 유형에 대해서도 비슷한 가정을 할 수 있습니다. 이러한 사례에 대한 테스트를 작성할 수도 있지만, 일반적인 엔지니어링에서는 큰 의미가 없습니다. 이러한 실패가 발생하면 다른 모든 것도 실패한다고 가정하는 편이 안전합니다. 이를 가리켜 모두가 운명 공동체라고 합니다. 운명 공동체에서는 엔지니어가 처리해야 하는 다른 실패 모드를 크게 줄일 수 있습니다.
장애 처리
하드 실시간 분산 시스템에서 실패 모드 처리
하드 실시간 분산 시스템을 작업하는 엔지니어는 서버와 네트워크가 운명 공동체가 아니므로 네트워크 장애의 모든 측면을 테스트해야 합니다. 단일 머신 사례와 달리, 네트워크에서 장애가 발생해도 클라이언트 머신은 계속 작동합니다. 원격 머신에서 장애가 발생해도 클라이언트 머신은 계속 작동하는 식입니다.
앞서 설명한 요청/회신 단계의 실패 사례를 세밀하게 테스트하려면 엔지니어는 각 단계가 실패할 수 있다고 가정해야 합니다. 그리고 클라이언트와 서버 모두에서 코드가 이러한 실패를 고려하여 올바르게 동작하도록 보장해야 합니다.
제대로 작동하지 않는 왕복 요청/회신 작업을 살펴보겠습니다.
-
게시 요청 실패: NETWORK에서 메시지를 전송하지 못하거나(예를 들어, 잘못된 순간에 중간 라우터에서 크래시 발생) SERVER에서 명시적으로 메시지를 거부했습니다.
-
요청 전송 실패: NETWORK는 MESSAGE를 SERVER로 전송하지만, SERVER는 MESSAGE 수신 후 크래시가 발생합니다.
-
요청 검증 실패: SERVER에서 MESSAGE가 올바르지 않다고 판단합니다. 거의 모든 것이 원인일 수 있습니다. 예를 들어, 손상된 패킷, 호환되지 않는 소프트웨어 버전 또는 클라이언트나 서버에서의 버그 때문일 수 있습니다.
-
서버 상태 업데이트 실패: SERVER에서 서버 상태를 업데이트하려고 하지만, 작동하지 않습니다.
-
회신 게시 실패: 성공 또는 실패로 회신하는지에 상관없이 SERVER에서 회신 게시에 실패할 수 있습니다. 예를 들어, 네트워크 카드가 잘못된 순간에 과열될 수 있습니다.
-
회신 전송 실패: NETWORK가 이전 단계에서 작동했어도 NETWORK에서 앞서 설명한 대로 CLIENT에 REPLY를 전송할 수 없습니다.
-
회신 검증 실패: CLIENT가 REPLY가 올바르지 않다고 판단합니다.
-
클라이언트 상태 업데이트 실패: CLIENT가 메시지 REPLY를 수신할 수 있지만 클라이언트 상태를 업데이트하지 못하거나 메시지를 이해하지 못하거나(비호환성 때문에) 다른 이유로 실패할 수 있습니다.
이러한 실패 모드 때문에 분산 컴퓨팅이 어려워집니다. 저는 이러한 실패 모드를 8가지 세계 종말의 실패 모드라고 부릅니다. 이러한 실패 모드와 관련하여 팩맨 코드의 다음 식을 다시 검토해보겠습니다.
board.find("pacman")
이 식은 다음과 같은 클라이언트 측 활동으로 확장됩니다.
-
보드 머신으로 주소 지정된 네트워크에 {action: "find", name: "pacman", userId: "8765309"}와 같은 메시지를 게시합니다.
-
네트워크를 사용할 수 없거나 보드 머신에 대한 연결이 명시적으로 거부되는 경우 오류가 발생합니다. 이 사례는 다소 특별합니다. 클라이언트가 서버 머신에서 요청을 수신할 수 없다는 점을 확실히 알기 때문입니다.
-
회신을 기다립니다.
-
회신이 수신되지 않으면 제한 시간이 초과됩니다. 이 단계에서 제한 시간의 초과는 요청 결과가 UNKNOWN 상태임을 의미합니다. 이러한 상황은 발생할 수도 있고, 발생하지 않을 수도 있습니다. 클라이언트는 UNKNOWN을 올바르게 처리해야 합니다.
-
회신이 수신되면 성공한 회신, 오류 회신 또는 이해할 수 없거나 손상된 회신인지를 판별합니다.
-
오류가 아니면 응답을 마샬링 해제하고 코드가 이해할 수 있는 객체로 전환합니다.
-
오류나 이해할 수 없는 회신인 경우 예외를 발생시킵니다.
-
어디서 예외를 처리하든 예외는 요청을 재시도해야 하는지, 아니면 포기하고 처리를 중지해야 하는지를 결정해야 합니다.
또한 식은 다음과 같은 서버 측 활동을 시작합니다.
-
요청을 수신합니다(이 상황이 발생하지 않을 수도 있음).
-
요청을 검증합니다.
-
사용자를 검색하여 사용자가 아직 활성 상태인지 확인합니다. (너무 오래 메시지를 수신하지 못했기 대문에 서버가 사용자를 포기했을 수도 있습니다.)
-
서버가 사용자가 아직 있는지 알 수 있도록 사용자에 대한 연결 유지 테이블을 업데이트합니다.
-
사용자 위치를 검색합니다.
-
{xPos: 23, yPos: 92, clock: 23481984134}와 같은 내용을 포함하는 응답을 게시합니다.
-
추가 서버 논리로 클라이언트의 향후 효과를 올바르게 처리해야 합니다. 예를 들어, 메시지를 수신하지 못하거나, 수신했지만 이해하지 못하거나, 수신하고 크래시가 발생했거나 성공적으로 처리할 수 있습니다.
요약하면, 정상 코드의 식 하나는 하드 실시간 분산 시스템 코드에서 15개의 추가 단계로 전환됩니다. 이렇게 확장되는 이유는 8개의 서로 다른 지점 때문이고, 이러한 지점에서 클라이언트와 서버 간의 개별 왕복 통신이 실패할 수 있습니다. board.find("pacman")와 같이 네트워크에서 왕복을 나타내는 식 때문에 다음과 같은 특성이 나타납니다.
(error, reply) = network.send(remote, actionData)
switch error
case POST_FAILED:
// handle case where you know server didn't get it
case RETRYABLE:
// handle case where server got it but reported transient failure
case FATAL:
// handle case where server got it and definitely doesn't like it
case UNKNOWN: // i.e., time out
// handle case where the only thing you know is that the server received
// the message; it may have been trying to report SUCCESS, FATAL, or RETRYABLE
case SUCCESS:
if validate(reply)
// do something with reply object
else
// handle case where reply is corrupt/incompatible
이 복잡성은 불가피합니다. 코드가 모든 사례를 올바르게 처리하지 못하면 서비스는 실제로 이상한 방식으로 실패하게 됩니다. 팩맨 예제와 같이 클라이언트/서버 시스템에 가능한 모든 실패 모드에 대한 테스트를 작성한다고 상상해 보십시오!
테스트
하드 실시간 분산 시스템 테스트
팩맨 코드 조각의 단일 머신 버전 테스트는 비교적 직관적입니다. 몇 개의 다른 보드 객체를 생성하고, 다른 상태에 배치한 후, 몇 개 사용자 객체를 다른 상태에 작성하는 식입니다. 엔지니어는 엣지 조건을 가장 많이 고민하고, 생성 테스트나 퍼저를 사용해볼 수도 있습니다.
팩맨 코드에는 보드 객체를 사용하는 네 개의 위치가 있습니다. 분산된 팩맨의 경우 앞서 설명한 대로, 코드에는 다섯 가지 가능한 결과(POST_FAILED, RETRYABLE, FATAL, UNKNOWN 또는 SUCCESS)를 포함하는 네 개의 지점이 있습니다. 이것으로 테스트의 상태 공간이 몇 배로 늘어납니다. 예를 들어, 하드 실시간 분산 시스템의 엔지니어는 많은 순열을 처리해야 합니다. board.find()에 대한 호출은 POST_FAILED로 실패합니다. RETRYABLE로 실패하는 경우에 발생하는 상황을 테스트한 다음, FATAL로 실패하는 경우에 벌어지는 상황을 테스트하면서 이렇게 계속되는 식입니다.
하지만 이러한 테스트로도 충분하지 않습니다. 일반적인 코드에서 엔지니어는 board.find()가 문제 없이 작동하면 보드에 대한 다음 호출인 board.move()도 작동한다고 가정할 수 있습니다. 하드 실시간 분산 시스템 엔지니어링에서는 이렇게 보장하지 않습니다. 서버 머신은 언제라도 독립적으로 실패할 수 있습니다. 그 결과 엔지니어는 보드에 대한 모든 호출의 모든 다섯 가지 사례에 대한 테스트를 작성해야 합니다. 엔지니어가 팩맨의 단일 머신 버전에서 10개의 시나리오를 테스트한다고 가정합니다. 하지만 분산 시스템 버전에서 엔지니어는 이러한 각 시나리오를 20배 더 테스트해야 합니다. 다시 말해, 테스트 행렬은 10에서 200개로 불어난 것입니다!
하지만, 이것이 다가 아닙니다. 엔지니어는 서버 코드도 갖고 있을 수 있습니다. 클라이언트, 네트워크 및 서버 측 오류의 결합 방식과는 무관하게, 엔지니어는 클라이언트와 서버가 손상된 상태로 종료되지 않도록 테스트해야 합니다. 서버 코드는 다음과 같을 수 있습니다.
handleFind(channel, message)
if !validate(message)
channel.send(INVALID_MESSAGE)
return
if !userThrottle.ok(message.user())
channel.send(RETRYABLE_ERROR)
return
location = database.lookup(message.user())
if location.error()
channel.send(USER_NOT_FOUND)
return
else
channel.send(SUCCESS, location)
handleMove(...)
...
handleFindAll(...)
...
handleRemove(...)
...
그리고 테스트할 네 개의 서버 측 함수가 있습니다. 단일 머신에서 각 함수에 각각 다섯 개의 테스트가 있다고 가정합니다. 그러면 테스트는 20개입니다. 클라이언트는 동일한 서버에 여러 메시지를 전송하므로, 테스트는 서버가 여전히 강력한 성능을 유지할 수 있도록 여러 요청의 시퀀스를 시뮬레이션해야 합니다. 요청의 예로는, find, move, remove 및 findAll이 있습니다.
이제 하나의 생성자에 각 시나리오에서 평균적으로 3개 호출을 수행하는 10개의 다른 시나리오가 있다고 가정합니다. 그러면 30개의 테스트가 더 생깁니다. 하지만 하나의 시나리오는 실패 사례도 테스트해야 합니다. 이러한 각 테스트에서 클라이언트가 네 개의 실패 유형(POST_FAILED, RETRYABLE, FATAL 및 UNKNOWN)을 수신하고 올바르지 않은 요청으로 서버를 다시 호출하는 경우 벌어지는 상황을 시뮬레이션해야 합니다. 예를 들어, 클라이언트가 find를 성공적으로 호출하지만, move를 호출할 때 UNKNOWN 상태를 다시 받을 때가 있습니다. 그리고 다시 어떤 이유로 find를 다시 호출합니다. 그러면 서버는 이 사례를 올바르게 처리할까요? 그럴 수도 있지만, 테스트하기 전에는 알 수 없습니다. 그래서 클라이언트 측 코드와 마찬가지로, 서버 측 테스트 행렬도 매우 복잡해집니다.
알 수 없는 조건 처리
알 수 없는 조건 처리
특히 여러 요청에 대해 분산 시스템에서 발생할 수 있는 모든 실패 순열을 고려한다는 것은 정말로 상상도 할 수 없습니다. 분산 엔지니어링에 접근할 때 깨달은 한 가지는 모든 것을 믿지 말라는 것입니다. 네트워크 통신은 가능해도 모든 코드 행이 예상대로 작동하지 않을 수 있습니다.
가장 처리하기 어려운 점은 이전 섹션에서 설명한 UNKNOWN 오류 유형입니다. 클라이언트는 요청에 성공했는지 항상 아는 것은 아닙니다. 팩맨 이동을 완료했을 수도 있고(뱅킹 서비스의 경우 고객 은행 계좌에서 현금 인출), 완료하지 못했을 수도 있습니다. 엔지니어는 이런 문제를 어떻게 처리해야 할까요? 엔지니어도 사람이기 때문에 어렵습니다. 사람이 불확실성을 처리하느라 꽤 애를 먹습니다. 사람은 다음과 같이 코드를 바라보는 데 익숙합니다.
bool isEven(number)
switch number % 2
case 0
return true
case 1
return false
사람은 보이는 대로 작동하기 때문에 이 코드를 이해합니다. 사람은 이러한 작업 일부를 서비스로 분산시키는 코드의 분산된 버전에 어려움을 갖습니다.
bool distributedIsEven(number)
switch mathServer.mod(number, 2)
case 0
return true
case 1
return false
case UNKNOWN
return WHAT_THE_FARG?
사람이 UNKNOWN을 올바르게 처리하는 방법을 알아내기란 불가능에 가깝습니다. UNKNOWN이란 실제로 무엇을 의미할까요? 코드를 재시도해야 하는 상황인가요? 그렇다면 몇 번을 시도해야 할까요? 재시도 간에 얼마를 기다려야 할까요? 코드에 부작용이 있으면 상황은 더 악화됩니다. 단일 머신에서 실행되는 예산 애플리케이션 내부에서는 다음 예제와 같이 계좌에서 현금 인출 작업은 간단합니다.
class Teller
bool doWithdraw(account, amount)
switch account.withdraw(amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
그러나 이 애플리케이션의 분산 버전은 UNKNOWN 때문에 조금 특이합니다.
class DistributedTeller
bool doWithdraw(account, amount)
switch this.accountService.withdraw(account, amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
case UNKNOWN
return WHAT_THE_FARG?
UNKNOWN 오류 유형을 처리하는 방법을 알아내는 것은 분산 엔지니어링에서 항상 보이는 대로가 아니기 때문입니다.
무리
일단의 하드 실시간 분산 시스템
8가지 세계 종말의 실패 모드는 분산 시스템에서 어떤 추상 수준에서든 발생할 수 있습니다. 이전 예제는 단일 클라이언트 머신, 네트워크 및 단일 서버 머신으로 제한되었습니다. 단순 시나리오에서도 실패 상태 행렬은 정말 많이 복잡해집니다. 실제 분산 시스템은 단일 클라이언트 머신 예제보다 더 복잡한 실패 상태 행렬을 보여줍니다. 실제 분산 시스템은 여러 추상 레벨에서 볼 수 있는 여러 시스템으로 구성되어 있습니다.
-
개별 머신
-
머신 그룹
-
머신 그룹의 그룹
-
이런 식의 가능한 그룹
예를 들어, AWS에 빌드된 서비스는 특정 가용 영역 내 리소스를 처리하는 전용 머신을 그룹화할 수 있습니다. 그리고 다른 두 가용 영역을 처리하는 머신 그룹이 2개 더 있을 수 있습니다. 그런 다음, 이 그룹을 AWS 리전 그룹으로 그룹화할 수 있습니다. 이 리전 그룹은 다른 리전 그룹과 논리적으로 통신할 수 있습니다. 하지만, 더 높은 논리적 레벨에서도 모든 같은 문제가 적용됩니다.
한 서비스가 일부 서버를 단일 논리 그룹, GROUP1로 그룹화한다고 가정합니다. 그룹 GROUP1은 때때로 다른 서버 그룹, GROUP2로 메시지를 전송할 수 있습니다. 다음은 반복적 분산 엔지니어링의 예제입니다. 앞서 설명한 모든 같은 네트워킹 실패 모드가 여기에도 적용 가능합니다. GROUP1에서 GROUP2로 요청을 전송하려고 한다고 가정합니다. 다음 다이어그램에서와 같이, 두 머신의 요청/회신 상호작용은 이전에 설명한 단일 머신의 상호작용과 같습니다.
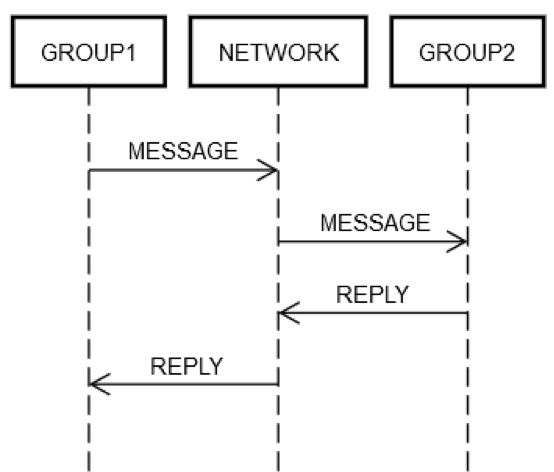
어떻게 해서든, GROUP1은 논리적으로 GROUP2로 주소 지정된 네트워크, NETWORK에 메시지를 넣어야 합니다. GROUP2의 일부 머신이 요청을 처리해야 하며, 계속 이런 식으로 진행됩니다. GROUP1 및 GROUP2가 머신 그룹으로 구성되었다는 사실 때문에 기본적인 내용이 바뀌지는 않습니다. GROUP1, GROUP2 및 NETWORK는 서로 독립적으로 계속 실패할 수 있습니다.
그러나 이건 그룹 수준의 보기에 불과합니다. 각 그룹에는 머신 대 머신 수준의 상호작용도 존재합니다. 예를 들어, GROUP2는 다음 다이어그램과 같이 구조화될 수 있습니다.
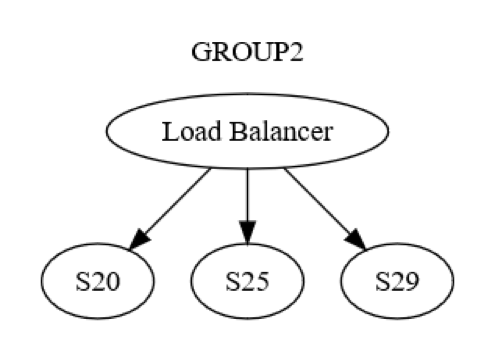
먼저, GROUP2에 대한 메시지를 로드 밸런서를 통해 그룹 내 하나의 머신(가능한 경우 S20)으로 전송합니다. 시스템의 설계자는 S20이 상태 업데이트 단계 중에 실패할 수 있다는 점을 알고 있습니다. 그 결과, S20은 하나 이상의 다른 머신(피어 중 하나이거나 다른 그룹의 머신)으로 메시지를 전달해야 할 수도 있습니다. 그렇다면 S20은 이 작업을 실제로 어떻게 수행할까요? 다음 다이어그램과 같이 요청/회신 메시지를 S25로 전송합니다.
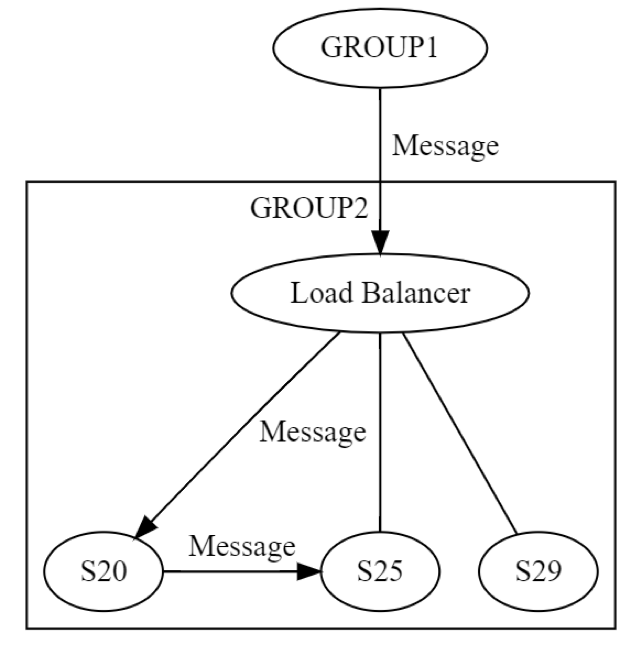
그러면 S20은 반복적으로 네트워킹을 수행합니다. 동일한 8개의 실패가 개별적으로 다시 발생할 수 있습니다. 분산 엔지니어링은 한 번이 아니라, 두 번 발생합니다. GROUP1에서 GROUP2로의 메시지는 논리적 수준에서 8가지 모든 방식으로 실패할 수 있습니다. 이 메시지로 다른 메시지가 생성되고, 이 메시지에서도 앞서 설명한 대로 8가지 모든 방식으로 독립적으로 실패할 수 있습니다. 이 시나리오에 대한 테스트는 다음을 포함합니다.
-
GROUP1에서 GROUP2로의 그룹 수준 메시징이 실패할 수 있는 8가지 모든 방식에 대한 테스트
-
S20에서 S25로의 서버 수준 메시징이 실패할 수 있는 8가지 모든 방식에 대한 테스트
이 요청/회신 메시징 예제는 지난 20년 동안의 경험을 통해 분산 시스템 테스트가 특별히 더 성가신 문제인 이유를 잘 보여줍니다. 엣지 사례는 매우 방대하기 때문에 테스트가 어렵고, 특히 분산 시스템은 더욱 그렇습니다. 시스템이 배포된 후에 버그가 표면으로 드러나는 데 오래 걸릴 수 있습니다. 그리고 버그가 시스템과 인접한 시스템에 예측할 수 없는 방대한 영향을 줄 수도 있습니다.
분산된 버그
종종 잠복해있는 분산 버그
실제로 실패한 경우 나중보다 더 빨리 발생하는 것이 더 낫다는 것이 일반적인 상식입니다. 예를 들어, 서비스에서 수정하는 데 6개월이 필요한 확장 문제는 서비스에서 이러한 확장을 수행하기 적어도 6개월 전에 찾아내는 것이 좋습니다. 마찬가지로 프로덕션으로 전환하기 전에 버그를 찾는 것이 더 좋습니다. 버그가 프로덕션에서 발생하는 경우 많은 고객에게 영향을 주거나 다른 부작용을 발생시키기 전에 빠르게 찾아내야 합니다.
분산 버그, 즉 8가지 세계 종말의 실패 모드에 대한 모든 순열을 처리하지 못해 발생한 버그는 종종 심각한 상황으로 이어집니다. 시간이 지남에 따라 전자 통신 시스템에서 핵심 인터넷 시스템에 이르기까지 대규모 분산 시스템에서 예제는 아주 많습니다. 이러한 가동 중단은 범위가 넓고 많은 비용이 들 뿐만 아니라 몇 개월 전에 프로덕션에 배포한 버그로 인해 발생할 수 있습니다. 그리고 실제로 이러한 버그를 발생시키고 전체 시스템으로 확산하는 여러 시나리오의 조합을 트리거하는 데에도 시간이 걸립니다.
전염되는 분산 버그
분산 버그의 핵심인 또 다른 문제에 대해 알아보겠습니다.
-
분산 버그는 네트워크 사용과 관련이 있습니다.
-
그래서 분산 버그는 다른 머신이나 머신 그룹으로 전파될 가능성이 큽니다. 머신을 함께 연결하는 유일한 특성임을 그 정의에서도 포함하고 있기 때문입니다.
Amazon도 이러한 분산 버그를 경험했습니다. 오래되었지만, 한 가지 관련 예로, www.amazon.com에서 발생한 사이트 전체 장애가 있습니다. 당시 장애는 디스크가 가득 찼을 때 원격 카탈로그 서비스 내 단일 서버 실패로 인해 발생했습니다.
이러한 오류 조건의 마샤링 해제로 인해 원격 카탈로그 서버는 수신하는 모든 요청에 대해 빈 응답을 반환하기 시작했습니다. 그리고 적어도 이 경우에는 무언가 있을 때보다 빈 응답의 반환이 훨씬 더 빠르기 때문에 매우 빠르게 반환하기 시작했습니다. 그동안 웹 사이트와 원격 카탈로그 서비스 사이의 로드 밸런서는 모든 응답 길이가 0임을 알아차리지 못했습니다. 하지만 다른 모든 원격 카탈로그 서버보다 너무 빠르다는 점은 인지했습니다. 그래서 www.amazon.com에서 디스크가 가득 찬 원격 카탈로그 서버 하나로 방대한 트래픽을 전송했습니다. 결국 하나의 원격 서버가 제품 정보를 표시할 수 없었기 때문에 전체 웹 사이트가 멈췄습니다.
저희가 잘못된 서버를 빨리 찾아 서비스에서 제거하고 웹 사이트를 복원했지요. 그리고 근본 원인을 확인하고 문제를 식별하여 같은 상황이 다시 발생하지 않도록 하는 일상적인 프로세스에 따라 후속 조치를 수행했습니다. 다른 시스템에서 같은 문제가 발생하지 않도록 Amazon과도 이번에 배운 내용을 공유했습니다. 이 실패 모드에 대한 특별한 교훈을 얻기도 했지만, 이번 사고는 실패 모드가 분산 시스템에서 예상치 못한 방식으로 빠르게 전파되는 것을 보여준 좋은 실례가 되었습니다.
요약
분산 시스템에서 문제 요약
요약하면, 분산 시스템에 대한 엔지니어링이 어려운 이유는 다음과 같습니다.
-
엔지니어가 오류 조건을 결합할 수 없습니다. 대신, 엔지니어는 장애에 대한 많은 순열을 고려해야 합니다. 대부분의 오류는 다른 오류 조건과는 독립적으로, 그리고 잠재적으로 함께 결합하여 언제라도 발생할 수 있습니다.
-
네트워트 작동 결과가 UNKNOWN 상태일 수 있으며, 이때 요청은 성공, 실패 또는 수신되었지만 처리되지 않은 상태일 수 있습니다.
-
분산 문제는 단순히 하위 수준의 실제 머신이 아니라, 분산 시스템의 모든 논리적 수준에서 발생합니다.
-
분산 시스템은 반복성 때문에 시스템의 상위 수준에서 더 악화됩니다.
-
분산 버그는 종종 시스템에 배포된 후 오랜 시간이 경과한 후 나타나기도 합니다.
-
분산 버그는 전체 시스템으로 퍼질 수 있습니다.
-
위의 많은 문제는 변경되지 않는 네트워킹의 물리 법칙에 따라 파생됩니다.
분산 컴퓨팅이 어렵고, 특이하다고 해서 이러한 문제를 해결할 방법이 없는 것은 아닙니다. Amazon Builders 라이브러리에서는 AWS가 분산 시스템을 관리하는 방법을 더 자세히 설명합니다. 여러분도 고객을 위해 빌드할 때 저희가 배웠던 소중한 교훈에서 솔루션을 찾기를 합니다.
작성자 소개
Jacob Gabrielson은 Amazon Web Services의 선임 수석 엔지니어입니다. 그는 Amazon에서 17년 동안 주로 내부 마이크로서비스 플랫폼과 관련된 작업을 해 왔습니다. 지난 8년 동안 소프트웨어 배포 시스템, 컨트롤 플레인 서비스, 스팟 시장, Lightsail, 그리고 최근에는 컨테이너를 포함하여 EC2 및 ECS에도 참여하고 있습니다. Jacob은 시스템 프로그래밍, 프로그래밍 언어 및 분산 컴퓨팅에 열정적으로 임하고 있습니다. 가장 싫어하는 것은 특히 실패 조건에서 이원화된 시스템 동작입니다. 그는 시애틀의 워싱턴 주립 대학에서 컴퓨터 공학 학사 학위를 갖고 있습니다.

관련 콘텐츠
오늘 원하는 내용을 찾으셨나요?
페이지의 콘텐츠 품질을 개선할 수 있도록 피드백을 보내주세요.