시작하기 리소스 센터 / 10분 자습서 / ...
고도로 정확한 교육 데이터 세트 구축
Amazon SageMaker Ground Truth 사용
이 자습서에서는 Amazon SageMaker Ground Truth를 사용하여 이미지 분류 사용 사례에 대한 매우 정확한 교육 데이터 세트를 구축하는 방법에 대해 알아봅니다. Amazon SageMaker Ground Truth를 사용하면 레이블 지정 작업에 대해 이미지 분류, 객체 탐지, 의미 체계 세분화 등으로 구성된 매우 정확한 교육 데이터 세트를 구축할 수 있습니다. Amazon SageMaker Ground Truth를 사용하면 레이블링 작업자에게 간편하게 액세스할 수 있고 내장형 또는 맞춤 구성 워크플로와 통상적인 레이블 지정 작업의 인터페이스를 사용할 수 있습니다.
Amazon SageMaker Ground Truth는 기계 학습을 사용하여 레이블을 데이터에 자동 적용함으로써 데이터 세트를 생성하는 시간 및 노력을 줄이는 데 도움이 될 수 있습니다. 이는 레이블링 작업자가 생성한 레이블에서 상시적으로 학습함으로써 가능합니다.
이 자습서 중에는 자동차, 트럭, 리무진, 밴 및 오토바이(자전거) 등의 차량 이미지로 데이터 세트를 레이블 지정할 수 있습니다.
Amazon SageMaker Ground Truth는 다양한 인력 옵션에 액세스할 수 있습니다.
- Amazon Mechanical Turk - 전 세계 500,000명을 상회하는 독립 계약자의 인력에 온디맨드 24/7의 방식으로 액세스할 수 있습니다. 이 옵션은 민감하지 않은 데이터에 권장합니다.
- 사설 인력 – 자체 직원 또는 계약자로 구성된 팀에 액세스할 수 있습니다. 이 옵션은 민감한 데이터인 경우 또는 레이블 지정 작업에 도메인 전문성이 필요한 경우에 권장합니다.
- 공급업체 인력 – Amazon이 승인하고 AWS Marketplace를 통해 전문적인 데이터 레이블 지정 서비스를 제공하는 제 3자 공급업체 목록에 액세스할 수 있습니다.
이 자습서에서는 Amazon Mechanical Turk를 사용합니다.
Amazon SageMaker Ground Truth로 레이블 지정 작업을 생성하려면 다음 단계를 수행하십시오.
- 레이블 지정해야 할 이미지를 준비하여 Amazon Simple Storage Service(Amazon S3)에 업로드합니다.
- 가능한 레이블 카테고리를 지정합니다.
- 레이블링 작업자의 지침을 생성합니다.
- 레이블링 작업 사양을 작성합니다.
- 작업을 Amazon Mechanical Turk에 제출합니다.
| 자습서 소개 | |
|---|---|
| 시간 | 10분 이상 |
| 사용 사례 | Machine Learning |
| 제품 | Amazon SageMaker Ground Truth, Amazon Mechanical Turk, Amazon Simple Storage Service |
| 최종 업데이트 날짜 | 2019년 8월 23일 |
시작하기 전에
이 자습서를 시작하려면 먼저 AWS 계정이 있어야 합니다. 아직 계정이 없으면 AWS에 가입을 클릭하여 새 계정을 만드십시오.
계정이 있습니까?
계정에 로그인합니다.
1단계 - Amazon SageMaker 콘솔에 로그인
1.
AWS Management Console을 새 창으로 열어서 이 자습서를 계속 열어둘 수 있습니다.
2.
AWS Console 검색 창에 SageMaker를 입력하고 Amazon SageMaker를 선택하여 서비스 콘솔을 엽니다.

Amazon SageMaker 노트북 인스턴스를 생성하여 데이터 준비하기
이 단계에서는 레이블 지정해야 하는 샘플 데이터 세트를 다운로드하여 생성한 Amazon Simple Storage Service (Amazon S3) 버킷에 업로드합니다. 서비스에서는 Amazon S3로부터 데이터 세트를 취득할 것으로 예상하기 때문에 이 단계를 완료한 후에 Amazon SageMaker Ground Truth의 레이블 지정 작업을 시작해야 합니다.
샘플 데이터 세트를 다운로드하여 Amazon S3에 업로드하려면 Amazon SageMaker 노트북 인스턴스를 사용합니다. 데이터 세트를 업로드하려면 Amazon SageMaker 노트북 인스턴스가 Amazon S3에 안전하게 액세스해야 합니다. 이 권한을 제공하기 위해 Amazon SageMaker는 새 AWS Identity and Access Management(IAM) 역할을 필요한 권한과 함께 생성하여 고객의 인스턴스에 지정할 수 있습니다.
참고 – 이 단계는 Amazon S3 버킷에 액세스할 수 있는 권한을 가진 어떤 클라이언트를 사용하더라도 수행할 수 있습니다. 이 자습서에서는 단순성 및 편의성을 위해 Amazon SageMaker 노트북 인스턴스를 사용합니다. AWS Command Line Interface(AWS CLI), Python 및 Boto3를 설치한 로컬 클라이언트를 사용하려면 3-3단계로 진행하면 됩니다.

1.
Amazon SageMaker > 노트북 인스턴스 페이지에서 노트북 인스턴스 생성을 선택합니다.

2.
노트북 인스턴스 생성 섹션의 노트북 인스턴스 이름 텍스트 상자에 노트북 인스턴스 이름을 입력합니다.
예를 들어, 이 자습서에서는 GroundTruthDatasetInstance를 인스턴스 이름으로 지정했습니다.

3.
IAM 역할을 생성하려면 IAM 역할 드롭다운 목록에서 새 역할 생성을 선택합니다.
4.
[IAM 역할 생성] 대화 상자에서 모든 S3 버킷을 선택합니다.
그러면 Amazon SageMaker 인스턴스가 계정에 있는 모든 S3 버킷에 액세스할 수 있습니다.
그러나 사용하려는 버킷이 있는 경우에는 특정 S3 버킷을 선택하고 버킷 이름을 지정하십시오.
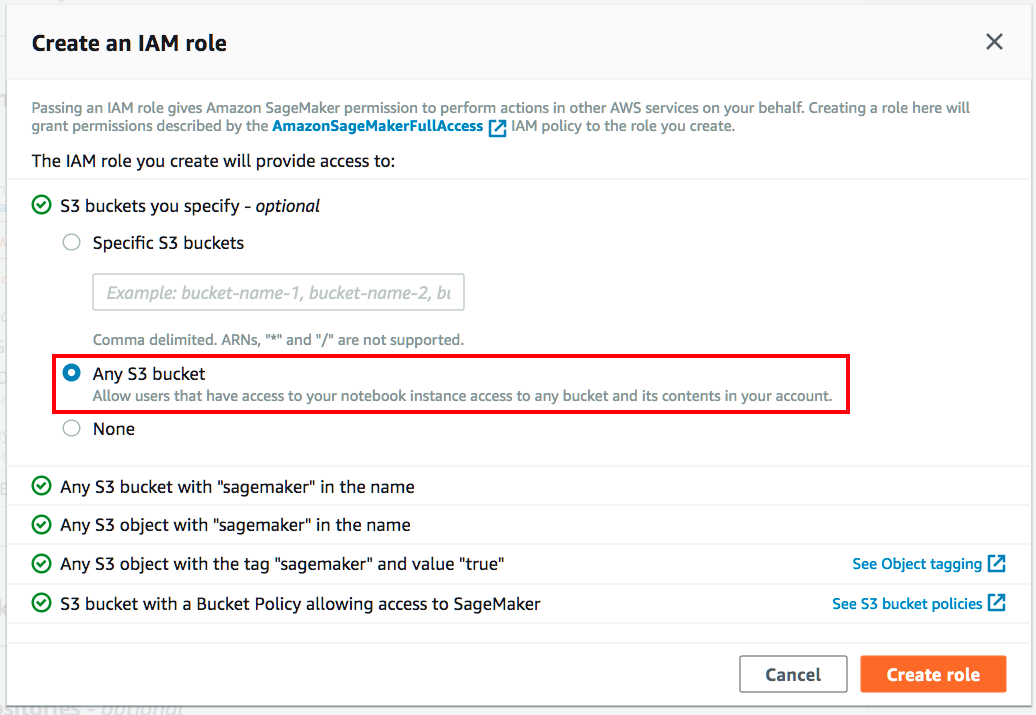
5.
[역할 생성]을 선택합니다.
Amazon SageMaker가 AmazonSageMaker-ExecutionRole-*** 역할을 생성합니다.
6.
다른 옵션은 기본 설정을 그대로 유지하고 노트북 인스턴스 생성을 클릭합니다.
노트북 인스턴스 섹션에서 새 GroundTruthDatasetInstance 항목이 대기 중 상태와 함께 표시됩니다.

3단계 – 데이터 세트를 준비하여 Amazon S3에 업로드
이 단계에서는 2단계에서 생성한 Amazon SageMaker 노트북 인스턴스를 사용하여 Amazon SageMaker Ground Truth 레이블 지정 작업을 위한 데이터 세트를 준비한 후에 이를 Amazon S3에 업로드합니다. 레이블 지정 작업을 위해 Amazon S3에 업로드하는 이미지는 여러 이미지 카테고리로 구성된 공개 Google Open Image Dataset 1 데이터 세트에서 구할 수 있습니다. 이 자습서에서는 트럭, 리무진, 밴, 자동차 및 오토바이(자전거) 이미지만 다운로드합니다. Google Open Images Dataset의 이미지는 이미 레이블 지정되어 있기 때문에 이 정보를 사용하여 결과를 취득한 후에 레이블 지정 작업의 품질을 검증할 수 있습니다.
1.
노트북 인스턴스 섹션에서 작업 열의 GroundTruthDatasetInstance 상태가 대기 중에서 InService로 변경된 후에 Jupyter 열기를 선택합니다.

2.
신규 드롭다운 목록에서 GroundTruthDatasetInstance가 Jupyter 파일 탭에 표시된 후에 conda_python3을 선택합니다.

3.
이미지를 Amazon S3에 업로드하려면 다음 코드를 인스턴스의 코드 셀에 복사합니다.
이 자습서의 기본 버킷 이름은 sm-gt-dataset입니다.
다른 버킷 이름을 지정하려면 다음 Python 스크립트의 BUCKET 변수를 변경하고 자습서 나머지 부분의 sm-gt-dataset를 변경한 버킷 이름으로 바꿉니다.
참고 – 코드 블록을 단축하려면 코드를 다중 셀로 분할하면 됩니다.
새 셀을 생성하려면 파일 > +를 선택합니다.
또는 삽입 > 아래 셀 삽입을 선택합니다.
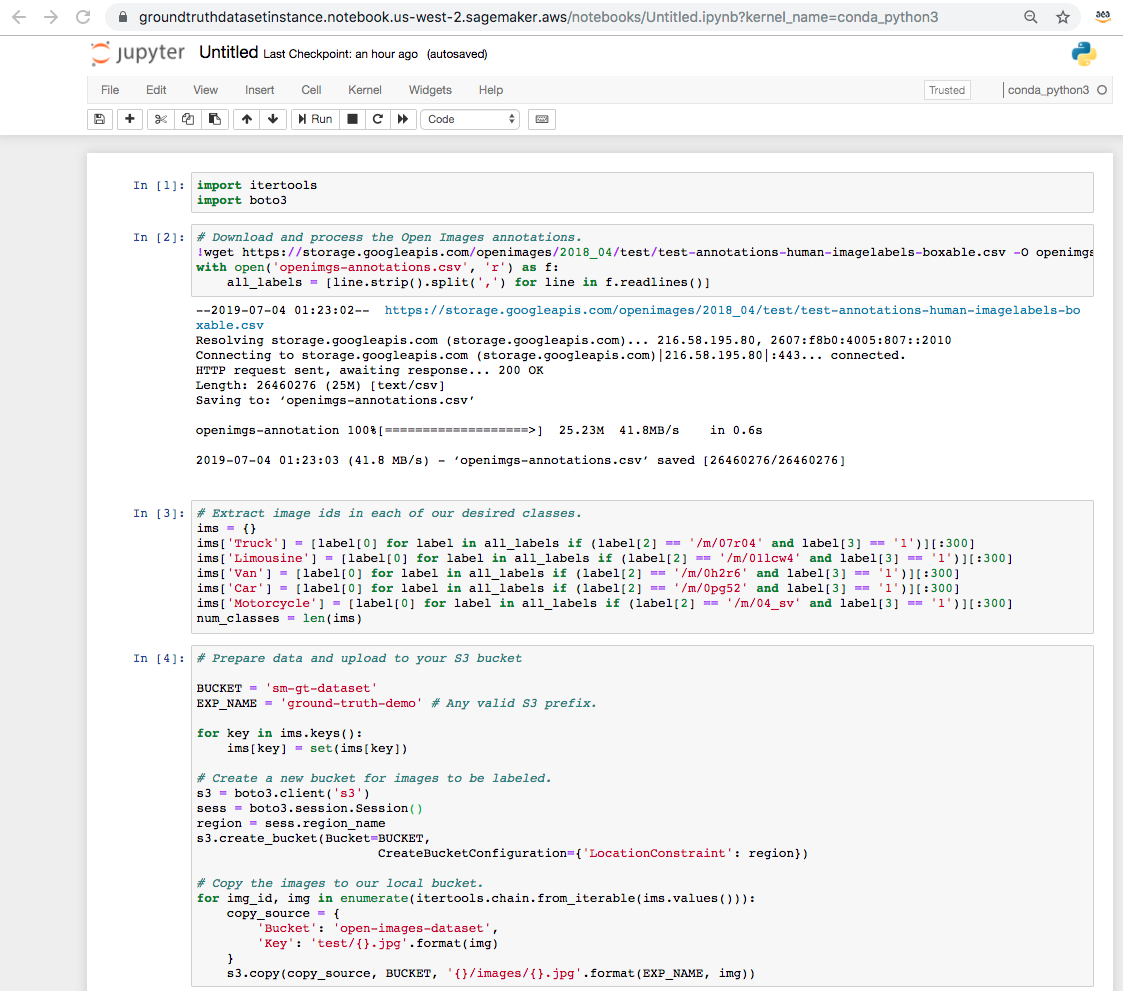
import itertools
import boto3
# Download and process the Open Images annotations
!wget https://storage.googleapis.com/openimages/2018_04/test/test-annotations-human-imagelabels-boxable.csv -O openimgs-annotations.csv
with open('openimgs-annotations.csv', 'r') as f:
all_labels = [line.strip().split(',') for line in f.readlines()]
# Extract image ids in each of our desired classes
ims = {}
ims['Truck'] = [label[0] for label in all_labels if (label[2] == '/m/07r04' and label[3] == '1')][:300]
ims['Limousine'] = [label[0] for label in all_labels if (label[2] == '/m/01lcw4' and label[3] == '1')][:300]
ims['Van'] = [label[0] for label in all_labels if (label[2] == '/m/0h2r6' and label[3] == '1')][:300]
ims['Car'] = [label[0] for label in all_labels if (label[2] == '/m/0pg52' and label[3] == '1')][:300]
ims['Motorcycle'] = [label[0] for label in all_labels if (label[2] == '/m/04_sv' and label[3] == '1')][:300]
num_classes = len(ims)
# Prepare data and upload to your S3 bucket
BUCKET = 'sm-gt-dataset'
EXP_NAME = 'ground-truth-demo' # Any valid S3 prefix.
for key in ims.keys():
ims[key] = set(ims[key])
# Create a new bucket for images to be labeled
s3 = boto3.client('s3')
sess = boto3.session.Session()
region = sess.region_name
s3.create_bucket(Bucket=BUCKET,
CreateBucketConfiguration={'LocationConstraint': region})
# Copy the images to your local bucket
for img_id, img in enumerate(itertools.chain.from_iterable(ims.values())):
copy_source = {
'Bucket': 'open-images-dataset',
'Key': 'test/{}.jpg'.format(img)
}
s3.copy(copy_source, BUCKET, '{}/images/{}.jpg'.format(EXP_NAME, img))4.
코드를 실행하려면 셀 > 모두 실행을 선택합니다.
코드를 실행한 후에 데이터 세트는 다음의 기본 위치에서 볼 수 있습니다.
Amazon S3 > sm-gt-dataset > ground-truth-demo > images.
이 폴더에는 현재 자동차, 트럭, 리무진, 밴 및 오토바이(자전거)를 포함하여 1,014개의 차량 이미지가 있어야 합니다.
참고 – 다른 버킷 이름을 지정한 경우에 데이터 세트는 생성한 버킷의 폴더에서 볼 수 있습니다.
Amazon S3 > your_bucket_name > ground-truth-demo > images.

1 A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, S. Kamali, S. Popov, M. Malloci, T. Duerig 및 V. Ferrari. The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. arXiv:1811.00982, 2018. (https://arxiv.org/abs/1811.00982)
고지사항 – 이 자습서를 위한 용도로 Google Inc.이 생성하고 https://storage.googleapis.com/openimages/web/download.html에서 구할 수 있는 Open Images Dataset V5를 수정하지 않았습니다. 주석은 CC BY 4.0 라이선스에 따라 Google Inc.의 허가를 취득했습니다. 이미지는 CC BY 2.0 라이선스를 취득한 것으로 명시했습니다. 데이터에 대한 자세한 통계와 데이터에 대해 교육한 모델의 평가는 위에 인용된 논문을 참조하십시오.
4단계 - Amazon SageMaker Ground Truth 레이블링 지정 작업을 생성
이 단계에서는 3단계에서 준비한 데이터의 SageMaker Ground Truth 레이블 지정 작업을 생성합니다. 목표는 레이블을 이 이미지에 적용하여 5개 카테고리, 즉 자동차, 트럭, 리무진, 밴 및 오토바이(자전거)로 분류하는 것입니다.
1.
Amazon SageMaker 대시보드에서 레이블 지정 작업 > 레이블 지정 작업 생성을 선택합니다.

2.
작업 개요 섹션에서 작업 이름 텍스트 상자에 vehicle-labeling-demo를 입력합니다.

3.
입력 데이터 세트의 위치를 지정합니다. Amazon SageMaker Ground Truth는 각 줄의 이미지를 참조하여 입력 매니페스트 파일을 예상합니다.
예를 들어, 각 이미지는 매니페스트 파일에 다음 형식으로 입력해야 합니다.
{"source-ref": "s3://sm-gt-dataset/ground-truth-demo/images/2563c7e7e3432a6e.jpg"}
4.
Amazon SageMaker Ground Truth가 이 매니페스트를 자동 생성하게 하려면 입력 데이터 세트 위치 섹션에서 매니페스트 파일 생성을 클릭합니다.
5.
입력 데이터 세트 위치 텍스트 상자에 이미지의 위치를 입력하고 생성을 클릭합니다.
예를 들어, s3://sm-gt-dataset/ground-truth-demo/images/
3-3단계에서 지정한 버킷 및 폴더 이름을 정확하게 입력해야 합니다.

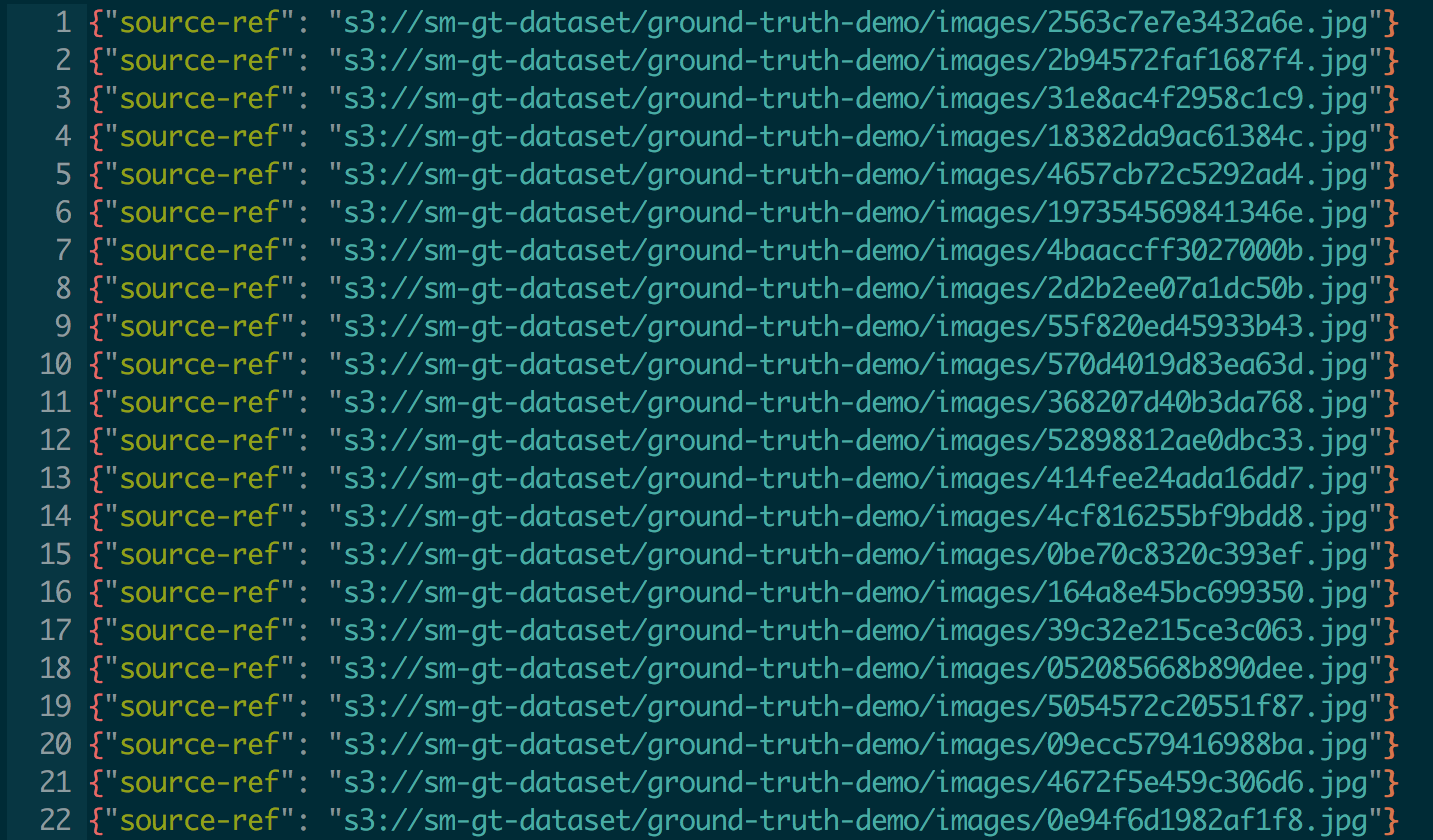
6.
매니페스트를 생성했으면 이 매니페스트 사용을 클릭합니다.
7.
레이블 지정된 데이터 세트를 저장할 Amazon S3 버킷의 경로를 지정합니다.
예: s3://sm-gt-dataset/ground-truth-demo/labeled_data/
8.
3단계에서 생성한 IAM 역할을 선택합니다.
또는 드롭다운 목록의 지침에 따라 새 IAM 역할을 생성합니다.
9.
추가 구성 섹션에서 데이터 세트의 하위 집합을 레이블 지정하고 암호화 설정을 지정할 수 있는 옵션을 선택할 수 있습니다.
이 예제에서는 옵션을 선택하지 마십시오.
10.
작업 유형 창의 작업 카테고리 드롭다운 목록에서 이미지를 선택합니다.

11.
작업 선택 옵션에서 이미지 분류를 선택합니다. 다음을 클릭합니다.
12.
작업자 선택 및 도구 구성 섹션의 작업자 유형에서 공개를 선택합니다.
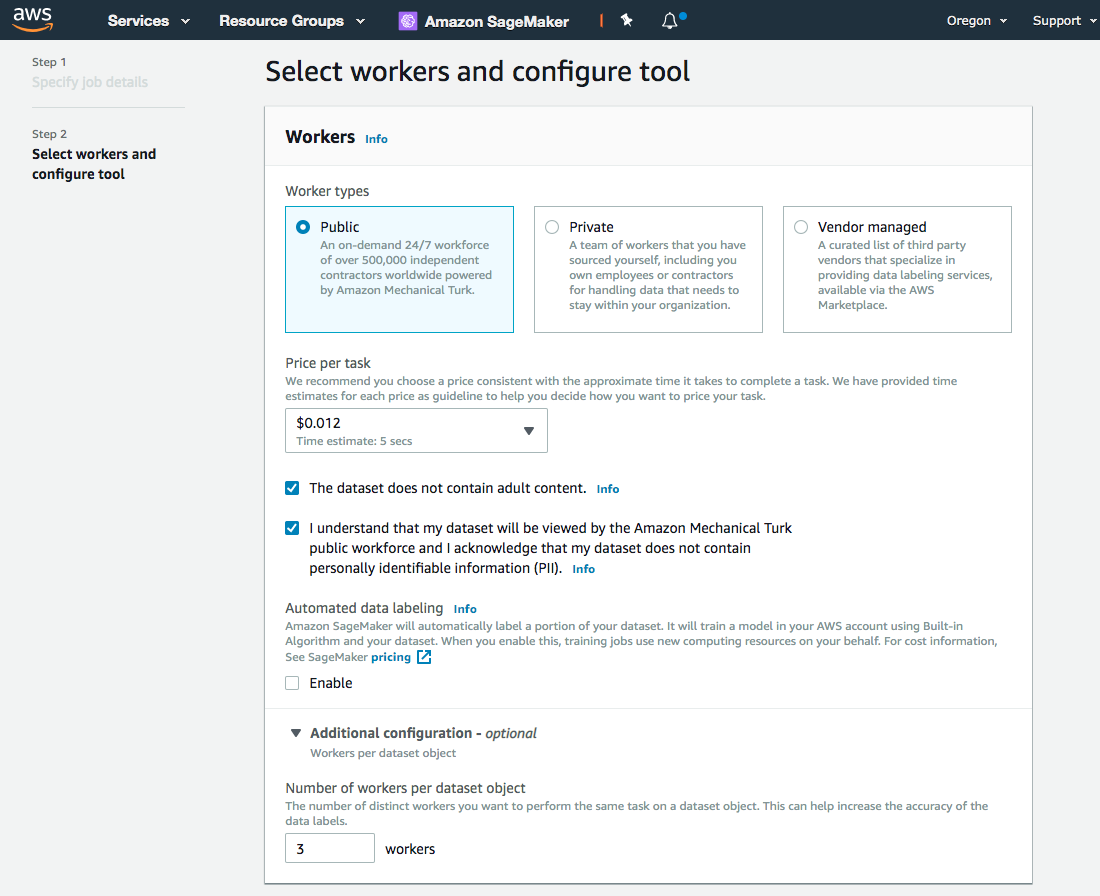
13.
작업당 가격 드롭다운 목록에서 기본 옵션을 그대로 유지합니다.
레이블링 작업자에게 5초 미만으로 소요되는 복잡성이 낮은 작업이므로 기본 옵션이 적절합니다.
객체 탐지 또는 의미 체계 세분화와 같이 작업이 더 복잡하면 더 높은 작업당 가격을 선택해야 합니다.
14.
다음 확인란을 선택합니다.
- 데이터에 성인 콘텐츠가 없습니다.
- Amazon Mechanical Turk 공개 인력이 내 데이터 세트를 열람하는 것을 이해하며, 데이터 세트에 개인 ID 정보(PII)가 포함되어 있지 않음을 인정합니다.
15.
자동 데이터 레이블 지정 확인란을 선택 해제했는지 확인합니다.
이미지 수가 능동 학습의 자동 레이블 지정에 필요한 임계값인 1,250개를 초과하는 경우에만 이 옵션을 선택합니다. 데이터 세트가 더 큰 경우에 자동 데이터 레이블 지정 기능을 사용하면 대형 데이터 세트의 레이블 지정에 소요되는 총비용을 낮출 수 있습니다.
자동 데이터 레이블 지정 기능을 선택해야 할 경우에 대한 자세한 내용은 Amazon SageMaker 개발자 안내서의 자동 데이터 레이블 지정 사용을 참조하십시오.
16.
추가 구성 섹션에서 데이터 세트 객체당 작업자 수 텍스트 상자는 작업자 3명의 기본 설정을 그대로 유지합니다.
17.
이미지 분류 레이블 지정 도구 섹션에서 두 템플릿 텍스트 상자에는 레이블링 작업자의 지침을 추가합니다. 제출을 클릭합니다.
이 이미지는 템플릿 지침의 예제이며, 레이블링 도구가 레이블링 작업자에 어떻게 표시되는지에 대한 미리보기입니다.


18.
새 레이블 지정 작업이 추가되었는지 확인하려면 콘솔에서 Amazon SageMaker > 레이블 지정 작업을 선택합니다.
새 vehicle-labeling-demo 레이블 지정 작업이 진행 중의 상태 및 이미지 분류의 작업 유형과 함께 표시되어야 합니다.
참고 - 이 작업은 완료하는 데 몇 시간이 걸릴 수 있습니다.
Amazon Mechanical Turk 공개 인력이 데이터의 레이블을 지정하는 경우에는 상태가 완료로 변경됩니다.
19.
작업 진행 상황을 보려면 Amazon SageMaker > 레이블 지정 작업 > vehicle-labeling-demo를 선택합니다.
5단계 - 레이블 지정 작업 결과 검토
이 단계에서는 레이블 지정 작업을 완료한 후에 그 결과를 검토합니다.
1.
콘솔에서 Amazon SageMaker > 레이블 지정 작업 > vehicle-labeling-demo를 선택합니다.
레이블 지정된 데이터 세트 객체 섹션에서 데이터 세트의 이미지 썸네일이 아래에 해당 레이블이 부착된 상태로 표시됩니다.

2.
레이블 지정 작업의 전체 결과를 보려면 레이블 지정 작업 요약 섹션에서 출력 데이터 세트 위치 링크를 클릭합니다.
예를 들어, s3://sm-gt-dataset/ground-truth-demo/labeled_data/vehicle-labeling-demo/

3.
매니페스트 디렉터리로 이동하여 output.manifest 파일을 엽니다.
예: s3://sm-gt-dataset/ground-truth-demo/labeled_data/vehicle-labeling-demo/manifests/output/output.manifest
output.manifest는 4단계에서 자동 생성된 input.manifest 파일과 유사한 JSON Lines 형식의 파일이지만 다음과 같은 필드가 추가로 포함되어 있습니다.
- vehicle-labeling-demo – 이 필드에서는 레이블에 해당하는 숫자값(0-4)을 지정합니다.
- vehicle-labeling-demo-metadata – 이 필드에서는 신뢰도 점수, 작업 이름, 레이블의 문자열 이름(자동차, 트럭 또는 밴), 인간 또는 기계 주석(능동 학습) 및 기타 정보와 같은 레이블링 메타데이터를 지정합니다.
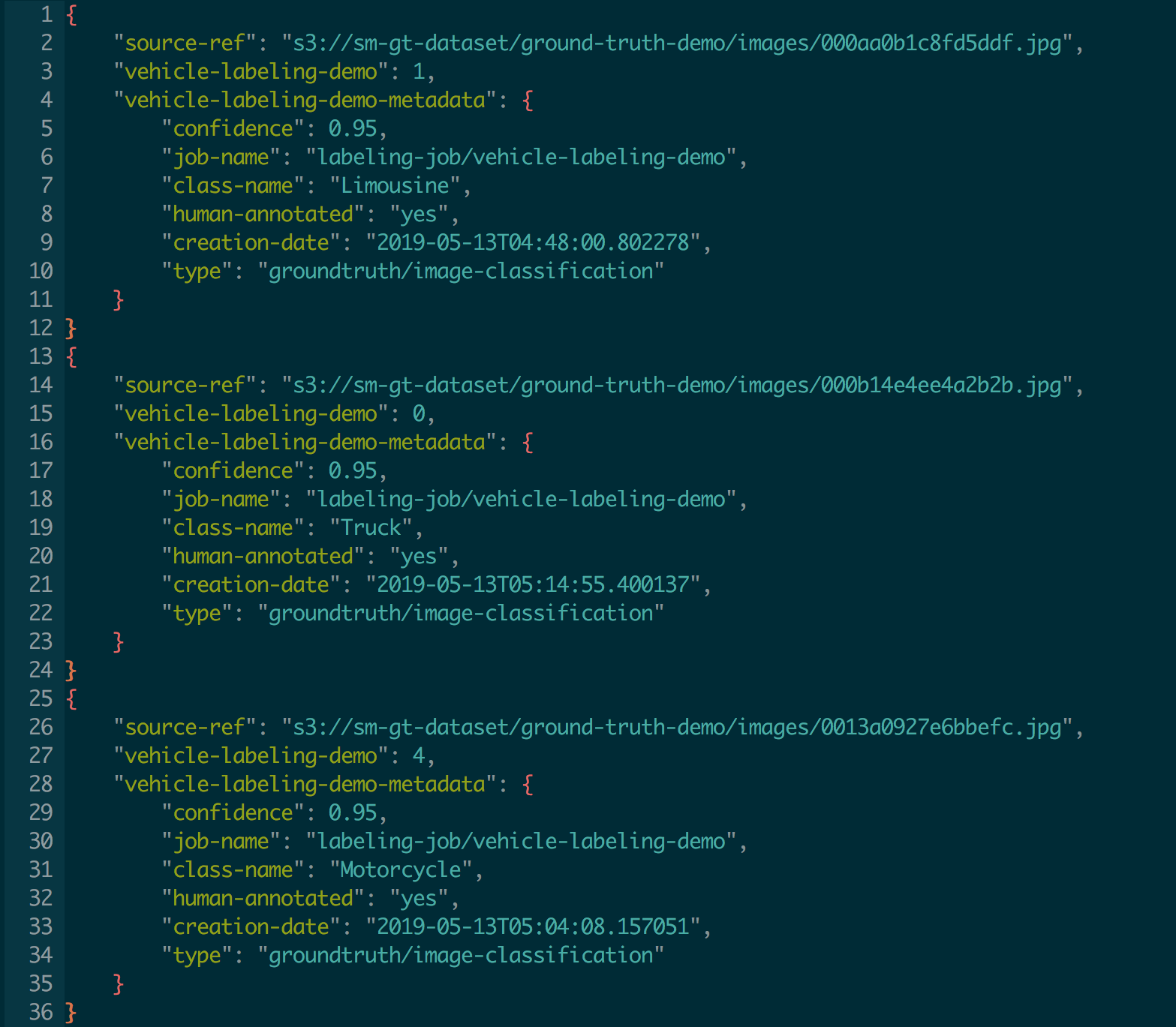
output.manifest 파일의 레이블 정보를 사용하여 차량의 이미지를 자동차, 트럭, 리무진, 밴 또는 오토바이(자전거)로 분류할 수 있는 이미지 분류기를 교육시킬 수 있습니다.
Amazon SageMaker에서 output.manifest 파일을 사용하여 모델을 교육할 수 있는 방법에 대한 자세한 내용은 Amazon SageMaker Ground Truth로 레이블 지정된 데이터 세트를 사용하여 모델을 쉽게 교육하기 블로그 게시물을 참조하십시오.
6단계 - 리소스 종료
자습서의 최종 단계는 Amazon SageMaker 관련 리소스를 종료하는 것입니다. 현재 사용되지 않는 리소스를 종료하면 비용이 절감되므로 권장됩니다. 리소스를 종료하지 않으면 계정에 비용이 청구됩니다.
1.
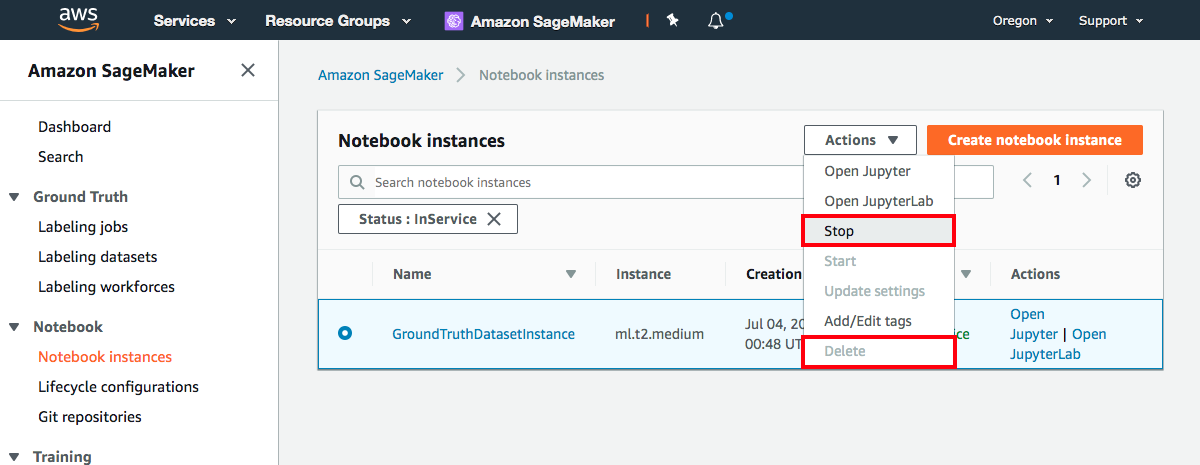
AWS Management Console에서 Amazon SageMaker > Notebook 인스턴스 > GroundTruthDatasetInstance를 선택합니다.
2.
작업 드롭다운 목록에서 중지를 선택합니다.
참고 – 인스턴스를 중지하면 비용이 발생하지 않습니다.
인스턴스를 중지한 후에 제거하려면 작업 드롭다운 목록에서 삭제를 선택합니다.
축하합니다!
지금까지 Amazon SageMaker Ground Truth를 사용하여 Amazon Mechanical Turk로 교육 데이터 세트를 구축하는 방법을 배웠습니다. 이제 이 레이블 지정 이미지를 사용하여 차량 이미지를 5개 레이블 지정 카테고리, 즉 자동차, 트럭, 밴, 리무진 및 오토바이로 분류할 수 있는 이미지 분류 모델을 교육할 수 있습니다.
Ground Truth 작업의 레이블 지정 이미지를 사용하여 모델을 쉽게 교육할 수 있는 방법에 대한 자세한 내용은 Amazon SageMaker Ground Truth로 레이블 지정된 데이터 세트를 사용하여 모델을 쉽게 교육하기 블로그 게시물을 참조하십시오.