Como evitar o fallback em sistemas distribuídos
ARQUITETURA | NÍVEL 300
Introdução
Falhas críticas impedem que um serviço produza resultados úteis. Por exemplo, em um site de comércio eletrônico, se ocorrer a falha em uma busca por informações de produto em um banco de dados, o site não poderá exibir a página do produto com êxito. Os serviços da Amazon têm que solucionar a maioria das falhas críticas para serem confiáveis. Há quatro categorias amplas de estratégias para lidar com falhas críticas:
- Repetição: executar novamente a atividade que falhou, imediatamente ou após algum tempo.
- Repetição proativa: executar a atividade várias vezes em paralelo e usar a primeira que terminar.
- Failover: executar a tarefa com uma cópia diferente do endpoint ou, preferivelmente, executar várias cópias paralelas da atividade para aumentar as chances de uma delas ter êxito.
- Fallback: usar um mecanismo diferente para alcançar o mesmo resultado.
Este artigo aborda as estratégias de fallback e os motivos pelos quais quase nunca as utilizamos na Amazon. Você poderá se surpreender. Afinal de contas, os engenheiros em geral usam o mundo real como ponto de partida para seus projetos. E no mundo real, as estratégias de fallback devem ser planejadas antecipadamente e usadas quando forem necessárias. Digamos que os painéis do aeroporto se apaguem. Um plano de contingência (por exemplo, informações de voo anotadas manualmente em quadros brancos) precisa ser elaborado para solucionar essa situação, já que os passageiros precisam saber a qual portão se dirigir. Porém, veja como é horrível o plano de contingência: a dificuldade de ler nos quadros brancos, a dificuldade de manter as informações atualizadas e o risco de pessoas cometerem erros ao inserirem as informações manualmente. A estratégia de fallback do quadro branco é necessária, embora repleta de problemas.
No universo dos sistemas distribuídos, as estratégias de fallback estão entre os desafios mais difíceis, principalmente para serviços com restrição de tempo. Para agravar essa dificuldade, as estratégias de fallback podem levar muito tempo (até mesmo anos) para causar repercussão. Além disso, a diferença entre uma boa e uma má estratégia é sutil. Neste artigo, o foco será mostrar como as estratégias de fallback podem causar mais problemas do que solucioná-los. Incluiremos exemplos de onde as estratégias de fallback causaram problemas na Amazon. Por fim, abordaremos alternativas para o fallback utilizadas na Amazon.
A análise das estratégias de fallback dos serviços não é intuitiva e os efeitos cascata são difíceis de prever em sistemas distribuídos. Vamos então começar verificando as estratégias de fallback para uma aplicação em uma única máquina.
Fallback em uma única máquina
Considere o seguinte snippet de código C que ilustra um padrão comum de lidar com falhas de alocação de memória em vários aplicativos. Esse código aloca memória com o uso da função malloc() e depois copia um buffer de imagem para a memória, enquanto executa algum tipo de transformação:
pixel_ranges = malloc(image_size); // allocates memory
if (pixel_ranges == NULL) {
// On error, malloc returns NULL
exit(1);
}
for (i = 0; i < image_size; i++) {
pixel_ranges[i] = xform(original_image[i]);
}
O código não se recupera bem quando ocorrem falhas de malloc. Na prática, as chamadas de malloc raramente falham. Os desenvolvedores então, em geral, ignoram as falhas do código. Por que essa estratégia é tão utilizada? O motivo é que, em uma única máquina, se o malloc falhar, provavelmente será por memória insuficiente. Há problemas maiores do que a falha de uma chamada do malloc: pane do computador. Na maioria das vezes, em uma única máquina. Esse é um bom motivo. Muitos aplicativos não são essenciais a ponto de valerem o esforço de solucionar um problema tão complexo. Mas e se você quisesse solucionar o erro? Tentar fazer algo útil nessa situação é complicado. Vamos supor que implementamos um segundo método chamado malloc2 que aloca a memória de outra maneira e que chamamos malloc2 em caso de falha na implementação do malloc padrão:
pixel_ranges = malloc(image_size);
if (pixel_ranges == NULL) {
pixel_ranges = malloc2(image_size);
}
À primeira vista, esse código parece funcionar. Contudo, há problemas com ele, alguns menos óbvios que outros. Para começar, a lógica de fallback é difícil de testar. Poderíamos interceptar a chamada de malloc e injetar uma falha. No entanto, isso talvez não simule corretamente o que aconteceria no ambiente de produção. Na produção, em caso de falha de malloc, a máquina muito provavelmente está sem memória ou a memória é insuficiente. Como você simula esses problemas genéricos de memória? Mesmo que você pudesse gerar um ambiente com pouca memória para executar o teste (digamos, em um contêiner Docker), como você sincronizaria a condição de memória insuficiente com a execução do código de fallback malloc2?
Um outro problema é que o próprio fallback pode falhar. O código de fallback anterior não lida com falhas de malloc2. Portanto, o programa não oferece tantos benefícios quanto se poderia imaginar. A estratégia de fallback torna improvável haver uma falha completa, porém não é impossível. Na Amazon, percebemos que empenhar recursos de engenharia para tornar um código primário (não fallback) mais confiável geralmente aumenta nossas chances de êxito. É melhor do que investir em uma estratégia de fallback pouco utilizada.
Além do mais, se disponibilidade for nossa maior prioridade, a estratégia de fallback pode não valer o risco. Por que se preocupar com malloc se malloc2 tem mais chances de êxito? Em termos lógicos, malloc2 pode ser uma vantagem na troca por sua maior disponibilidade. Talvez ele aloque memória com latência mais alta, porém com armazenamento SSD maior. E aí, surge uma dúvida. Por que essa troca seria válida para malloc2? Vamos considerar uma possível sequência de eventos com essa estratégia de fallback. Primeiramente, o cliente está usando o aplicativo. De repente (após falha de malloc), malloc2 entra em cena e a performance do aplicativo diminui. Isso é ruim. É bom ficar mais lento? Os problemas não param por aí. Considere que a máquina está muito provavelmente sem memória, ou a memória é insuficiente. Agora, o cliente tem dois problemas (aplicativo mais lento e máquina mais lenta), em vez de um. Os efeitos colaterais de mudar para malloc2 podem até piorar o problema geral. Por exemplo, outros subsistemas também podem brigar pelo mesmo armazenamento SSD.
A lógica de fallback também pode gerar uma carga imprevisível para o sistema. Até mesmo uma simples lógica comum, como gravar uma mensagem de erro em um log com um rastreamento de pilha é aparentemente inofensiva. No entanto, se algo mudar repentinamente e causar esse erro em uma taxa alta, um aplicativo vinculado à CPU poderá inesperadamente se tornar um aplicativo vinculado a E/S. E se o disco não estiver provisionado para lidar com gravação nessa taxa ou armazenar tal volume de dados, sua performance poderá diminuir ou a aplicação poderá travar.
A estratégia de fallback pode não só agravar o problema, mas transformar o erro em um bug latente. É fácil desenvolver estratégias de fallback que raramente entram em produção. Pode levar anos até que uma única máquina do cliente fique realmente sem memória no exato momento de acionar a linha de código específica com o fallback em malloc2 demonstrado anteriormente. Se houver algum erro na lógica de fallback ou algum tipo de efeito colateral que agrave o problema geral, os engenheiros que desenvolveram o código provavelmente terão esquecido como ele funcionava originalmente, e será difícil corrigir o código. Para um aplicativo em uma única máquina, isso pode ser uma troca comercial aceitável. Entretanto, nos sistemas distribuídos, as consequências são muito mais complexas, conforme explicaremos posteriormente.
Todos esses problemas são difíceis. Mas, de acordo com a nossa experiência, eles geralmente podem ser ignorados, com segurança, em aplicativos em uma única máquina. A solução mais comum é a que mencionamos anteriormente: basta deixar que os erros de alocação de memória travem o aplicativo. O código que aloca memória divide o mesmo destino com o resto da máquina. É muito provável que o resto da máquina esteja prestes a falhar nesse caso. Mesmo sem o mesmo destino, agora o estado do aplicativo seria um que não havia sido previsto. Causar a falha rapidamente é uma boa estratégia. A vantagem comercial é razoável.
Para aplicativos críticos em uma única máquina que precisam funcionar se ocorrerem falhas de alocação de memória, uma solução é alocar previamente toda a memória de heap durante a inicialização e nunca reutilizar o malloc, mesmo em condições de erro. A Amazon implementou essa estratégia várias vezes. Por exemplo, em daemons de monitoramento que são executados em servidores de produção e daemons do Amazon Elastic Compute Cloud (Amazon EC2) que monitoram picos na CPU dos clientes.
Fallback distribuído
Na Amazon, não permitimos que os sistemas distribuídos, principalmente os que precisam responder em tempo real, façam as mesmas trocas que os aplicativos em uma única máquina. Um dos nossos motivos é a ausência de um destino compartilhado com o cliente. Podemos pressupor que os aplicativos estejam em execução na máquina que fica em frente ao cliente. Se o aplicativo ficar sem memória, provavelmente o cliente não espera que ele continue a funcionar. Os serviços não são executados na máquina que o cliente está usando diretamente. Por isso, expectativa é outra. Além disso, normalmente os clientes usam os serviços exatamente porque eles estão mais disponíveis do que um aplicativo executado em um único servidor. Teoricamente, isso nos faria implementar o fallback como meio de tornar o serviço mais confiável. Infelizmente, o fallback distribuído tem os mesmos problemas, e ainda piores quando ocorrem falhas críticas do sistema.
Estratégias de fallback distribuído são mais difíceis de testar. O fallback de serviço é mais complicado que o da aplicação em uma única máquina, porque várias máquinas e serviços downstream participam de certa forma das falhas. Os modos de falha, como as situações de sobrecarga, são difíceis de replicar em um teste, mesmo que a orquestração do teste esteja prontamente disponível em várias máquinas. A combinatória também aumenta o número absoluto de casos a serem testados. Ou seja, você precisa de mais testes, e eles são mais difíceis de configurar.
As próprias estratégias de fallback distribuído podem falhar. Embora possa parecer que as estratégias de fallback são exitosas, nossa experiência demonstra que geralmente elas apenas melhoram as chances de êxito.
As estratégias de fallback distribuído, com frequência, pioram as interrupções. Segundo nossa experiência, as estratégias de fallback aumentam a abrangência do impacto das falhas e também os tempos de recuperação.
As estratégias de fallback distribuído quase sempre não valem o risco. Assim como com o malloc2, a estratégia de fallback cria normalmente algum tipo de troca. Se não fosse isso, nós a usaríamos o tempo todo. Por que usar um fallback que é pior, quando algo já não está indo bem?
As estratégias de fallback distribuído geralmente têm bugs latentes que surgem somente quando um conjunto improvável de coincidências ocorre, possivelmente meses ou anos após sua introdução.
Uma grande interrupção no mundo real acionada por um mecanismo de fallback no site de varejo da Amazon ilustra todos esses problemas. A interrupção ocorrida por volta de 2001 foi causada por um recurso novo que oferecia prazos de envio atualizados para todos os produtos exibidos no site. O novo recurso seria algo assim:

Naquela ocasião, a arquitetura do site tinha somente duas camadas. Como esses dados eram armazenados em um banco de dados da cadeia de suprimentos, os servidores web precisavam consultar o banco de dados diretamente. Contudo, o banco de dados não dava conta do volume de solicitações enviadas pelo site. O site tinha um volume alto de tráfego, e algumas páginas exibiam 25 ou mais produtos, com prazos de envio de cada produto exibidos em linha. Adicionamos uma camada de cache executada como um processo separado em cada servidor web (algo como Memcached):
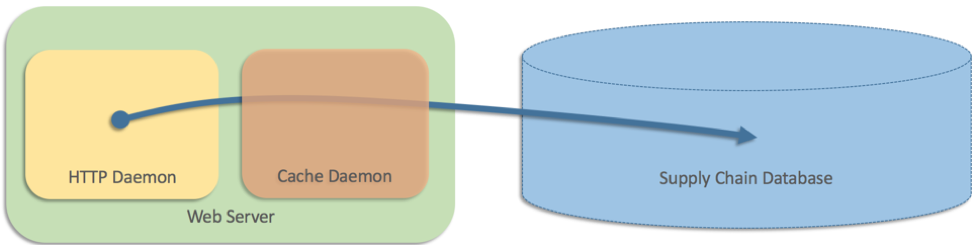
Funcionou bem, mas a equipe também tentou solucionar quando o cache (processo separado) falhou pelo mesmo motivo. Nesse cenário, os servidores web voltaram a consultar o banco de dados diretamente. Em um pseudocódigo, desenvolvemos algo como:
if (cache_healthy) {
shipping_speed = get_speed_via_cache(sku);
} else {
shipping_speed = get_speed_from_database(sku);
}
O fallback para consultas diretas ao banco de dados era uma solução intuitiva e funcionou por alguns meses. Entretanto, em algum momento, todos os caches falharam mais ou menos ao mesmo tempo, o que fez com que cada servidor web acessasse o banco de dados diretamente. Essa situação gerou carga suficiente para bloquear completamente o banco de dados. O site inteiro ficou inativo porque todos os processos do servidor web ficaram bloqueados no banco de dados. O banco de dados da cadeia de suprimentos também era essencial para os centros de atendimento, o que fez com que a interrupção se espalhasse ainda mais: todos os centros de atendimento do mundo inteiro ficaram paralisados até o problema ser corrigido.
Todos os problemas que vimos no caso de uma única máquina estavam presentes no caso distribuído, com consequências ainda mais desastrosas. Era difícil testar o caso de fallback distribuído. Mesmo que tivéssemos simulado a falha de cache, não teríamos encontrado o problema, pois foi preciso que ocorressem falhas em várias máquinas para ele aparecer. Nesse caso, a estratégia de fallback amplificou o problema. Foi pior do que se não tivéssemos qualquer estratégia de fallback. O fallback transformou uma interrupção parcial do site (não conseguia exibir os prazos de envio) em uma interrupção total do site (nenhuma página era carregada) e desativou toda a rede de atendimento da Amazon no back-end.
A ideia por trás da nossa estratégia de fallback nesse caso era ilógica. Se acessar o banco de dados diretamente era mais confiável do que passar pelo cache, por que se preocupar com o cache? Tínhamos receio de que não usando o cache, o banco de dados ficaria sobrecarregado. Mas por que usar o código de fallback se ele tinha um potencial tão danoso? Podíamos ter percebido o erro no início, mas este era um bug latente, e a situação que causou a interrupção surgiu meses após o lançamento.
Como a Amazon evita o fallback
Devido a essas dificuldades do fallback distribuído, agora quase sempre preferimos alternativas ao fallback. Vamos especificar aqui.
Aumentar a confiabilidade dos casos de não fallback
Como dito anteriormente, as estratégias de fallback apenas reduzem a probabilidade de falhas totais. Um serviço pode estar muito mais disponível se o código principal (não fallback) for mais robusto. Por exemplo, em vez de implementar a lógica de fallback entre dois armazenamentos de dados distintos, uma equipe poderia investir em um banco de dados com maior disponibilidade inerente, como o Amazon DynamoDB. Essa estratégia é frequentemente usada com êxito em toda a Amazon. Por exemplo, esta conversa descreve como usar o DynamoDB para ativar o amazon.com no Prime Day 2017.
Deixe que o chamador lide com os erros
Uma solução para falhas críticas do sistema é não fazer fallback, e sim deixar que o sistema que faz a chamada lide com a falha (por exemplo, por meio de repetição). Essa é uma estratégia preferível para serviços da AWS, onde nossas CLIs e SDKs contam com lógica incorporada para as repetições. Quando possível, preferimos essa estratégia, principalmente nas situações em que já houve empenho suficiente de compartilhar o destino e reduzir a probabilidade de falha do caso principal (e a lógica de fallback teria pouquíssima probabilidade de aumentar a disponibilidade).
Enviar dados proativamente
Outra tática que adotamos para evitar o fallback é reduzir o número de partes móveis ao responder a solicitações. Se, por exemplo, um serviço precisar de dados para atender a uma solicitação, e os dados já estiverem presentes no local (eles não precisam ser extraídos), não haverá necessidade de failover. Um exemplo do êxito desse procedimento é a implementação dos perfis do AWS Identity and Access Management (IAM) para o Amazon EC2. O serviço do IAM precisa fornecer credenciais assinadas e rotativas para executar o código em instâncias do EC2. Para evitar o fallback, as credenciais são proativamente enviadas para cada instância e permanecem válidas por muitas horas. Isso significa que as solicitações relacionadas a funções do IAM continuam funcionando mesmo na improbabilidade de ocorrer uma interrupção no mecanismo de envio.
Converter fallback em failover
Um dos piores aspectos do fallback é não poder ser praticado regularmente, e provavelmente falha ou aumenta a abrangência do impacto quando ocorre durante uma interrupção. As circunstâncias que acionam o fallback podem não ocorrer naturalmente por meses ou até mesmo anos! Para solucionar o problema de falhas latentes da estratégia de fallback, é importante exercitá-lo regularmente na produção. Um serviço deve executar a lógica de fallback e a lógica não fallback continuamente. Ele não deve apenas executar o caso de fallback, mas tratá-lo como uma fonte de dados igualmente válida. Por exemplo, um serviço pode escolher aleatoriamente entre respostas de fallback e não fallback (quando recebe ambas de volta) para ter certeza de que funcionam. Porém, a essa altura, a estratégia não pode mais ser considerada fallback e entra definitivamente na categoria de failover.
Assegurar que repetições e timeouts não se transformem em fallback
Repetições e timeouts são abordados no artigo Timeouts, Retries, and Backoff with Jitter. O artigo diz que as repetições são um mecanismo poderoso para garantir alta disponibilidade no caso de erros transitórios e aleatórios. Em outras palavras, repetições e timeouts são uma garantia contra falhas ocasionais causadas por problemas secundários, como perda de pacotes falsos, falha não correlacionada a uma única máquina e outros. Entretanto, é fácil haver erros nas repetições e nos timeouts. Os serviços geralmente levam meses ou mais tempo sem necessidade de muitas tentativas repetidas e isso pode acontecer em cenários que a equipe nunca testou. Por esse motivo, mantemos as métricas que monitoram as taxas gerais de repetições, e alarmes que alertam nossas equipes se a repetição estiver ocorrendo com frequência.
Outra maneira de evitar que repetições se transformem em fallback é executá-las sempre como uma repetição proativa (também conhecida como prevenção ou solicitações paralelas). Essa técnica é incorporada aos sistemas que executam leituras ou gravações de quórum, onde um sistema pode solicitar uma resposta de dois de três servidores para reagir. A repetição proativa segue o padrão de design do trabalho constante. Como solicitações redundantes estão sempre sendo feitas, as repetições não geram carga extra para o sistema quando a necessidade por solicitações redundantes aumenta.
Conclusão
Na Amazon, evitamos o fallback em nossos sistemas porque ele é difícil de comprovar e sua eficácia, difícil de testar. As estratégias de fallback introduzem um modo operacional em que o sistema entra em ação somente nos momentos mais caóticos quando os problemas começam a surgir, e alternar para esse modo apenas aumenta o caos. É frequente acontecerem longos atrasos entre o momento de implementação de uma estratégia de fallback e o momento em que ela está em um ambiente de produção.
Damos preferências aos caminhos de código que são exercitados continuamente na produção, e não raramente. Priorizamos o aumento da disponibilidade de nossos sistemas primários, com o uso de padrões, como o envio de dados para os sistemas que precisam, em vez de extrair os dados e correr o risco de uma chamada remota em um momento crítico. Por fim, observamos se ocorre algum comportamento sutil de nosso código, capaz de transformar-se em operação de fallback, como quando há repetições excessivas.
Se o fallback for essencial em um sistema, nós o exercitaremos com a máxima frequência possível na produção, de modo que ele se comporte com o mesmo nível de confiabilidade e previsão que o modo operacional primário.
Sobre o autor
Jacob Gabrielson é um engenheiro-chefe sênior na Amazon Web Services. Ele trabalha na Amazon há 17 anos, principalmente nas plataformas internas de microsserviços. Durante os último 8 anos, ele trabalhou no EC2 e no ECS, incluindo sistemas de implantação de software, serviços de plano de controle, Spot Market, Lightsail e, mais recentemente, contêineres. Jacob é apaixonado por programação de sistemas, linguagens de programação e computação distribuída. O comportamento bimodal do sistema, principalmente em condições de falha, é o que mais o desagrada. Ele é formado em Ciência da Computação pela Universidade de Washington em Seattle.

Conteúdo relacionado
Você encontrou o que estava procurando hoje?
Ajude-nos a melhorar a qualidade do conteúdo em nossas páginas