Блог Amazon Web Services
Используем AWS Lambda: антипаттерны в событийно-управляемой архитектуре – Часть 3
Оригинал статьи: ссылка (James Beswick, Principal Developer Advocate)
В серии «Используем AWS Lambda» я затрону несколько тем, важных для разработчиков, архитекторов и системных администраторов, которые работают с приложениями, использующими AWS Lambda. Эта серия из трёх статей познакомит вас с событийно-управляемой архитектурой и покажет, как она связана с бессерверными приложениями.
Часть 1 рассказывает про преимущества событийно-ориентированной архитектуры, и то, как она может повысить пропускную способность, масштабируемость и расширяемость. В части 2 описываются некоторые принципы проектирования и лучшие практики, которые помогут разработчикам использовать преимущества Lambda при разработке приложений. В этой части рассматриваются типовые антипаттерны в архитектуре, управляемой событиями.
Lambda не устанавливает жёстких правил, этот сервис предоставляет широкие возможности для создания приложений так, как вам удобно. Хотя эта гибкость полезна, в некоторых случаях созданная архитектура может оказаться неоптимальной.
Монолитная функция
При миграции приложений из традиционных сервисов вроде Amazon EC2 или AWS Elastic Beanstalk разработчики переносят существующий код. Часто это приводит к созданию одной лямбда-функции, реализующей всю логику работы приложения и вызываемой по любому событию. Например, для простейшего веб-приложения такая монолитная функция будет обрабатывать все возможные вызовы, поступающие через Amazon API Gateway и интегрироваться со всеми используемыми сервисами:

Такой подход имеет несколько недостатков:
- Размер: функция получается большой, поскольку включает код для обработки всех возможных событий, что замедляет загрузку и запуск.
- Сложнее ограничивать права: IAM-роль, используемая функцией, должна открывать доступ ко всем используемым ресурсам. Ей приходится предоставлять широкие права, хотя не все они требуются при каждом вызове.
- Сложнее обновлять: внесение изменений в рабочее приложение, состоящее из единственной функции, связано с риском вызвать сбой всего приложения. Изменение логики обработки одного события – это изменение всей функции.
- Сложнее сопровождать: сложнее обеспечить совместную работу нескольких разработчиков, так как весь код находится в монолитном хранилище. Разработчикам потребуется тщательнее продумывать изменения. Придумывать тесты также сложнее.
- Сложнее переиспользовать код: как правило, из монолитного кода сложнее выделить функции, которые можно переиспользовать. По мере того, как растет количество разрабатываемых и сопровождаемых проектов, поддерживать их становится сложнее, и скорость работы команд начинает снижаться.
- Сложнее тестировать: по мере увеличения размеров функции становится сложнее разрабатывать тесты, которые бы покрывали все сочетания вариантов входных данных и обрабатываемых событий. Тестировать небольшие сервисы, содержащие небольшой объем кода, проще.
Другим подходом будет разбиение монолитной лямбда-функции на отдельные микросервисы, решающие единственную чётко определённую задачу. В приведённом выше примере веб-приложения, предоставляющем несколько вариантов вызова API, функцию можно разбить на сервисы, каждый из которых обрабатывает отдельный вид вызова.
 Подход к разбиению монолитной функции зависит от сложности приложения. Одним из подходов является замещение (strangler pattern). Микросервисы имеют ряд преимуществ:
Подход к разбиению монолитной функции зависит от сложности приложения. Одним из подходов является замещение (strangler pattern). Микросервисы имеют ряд преимуществ:
- Размер: функции, обрабатывающие только отдельные события, меньше и могут выполняться быстрее, что позволит сократить расходы.
- IAM-роль может быть ограничена минимально необходимыми правами, что помогает придерживаться принципа минимальных привилегий. Такой подход позволяет ограничить возможный радиус поражения и повысить безопасность.
- Проще обновлять: код отдельного микросервиса можно обновлять, не затрагивая всё приложение. Изменения производятся в отдельных функциях, а не во всем приложении, и можно использовать подход «канарейки в шахте» (canary releases) для контроля за развёртыванием.
- Проще сопровождать: новые функции обычно проще добавлять в небольшой сервис, чем в монолитный код с сильной связанностью. Зачастую, сервис можно расширить, добавляя новые лямбда-функции, не меняя существующие.
- Проще переиспользовать код: функцию, которая специализируется на выполнении единственной задачи проще переносить в другие проекты. Создание библиотеки универсальных специализированных функций может ускорить разработку будущих проектов.
- Проще тестировать: организовать модульное тестирование небольшого кода с небольшим количеством вариантов входных данных проще.
- Проще разработка: каждая команда может сосредоточиться только на части приложения. Адаптация новых разработчиков будет проходить быстрее.
Чтобы узнать больше, прочитайте «Decomposing the Monolith with Event Storming».
Оркестрация в лямбда-функции
Многие бизнес-процессы требуют создания сервиса, реализующего сложную логику работы, зависящую от множества факторов. Если взять для примера приложение для электронной торговли, таким будет процесс оплаты заказа:
- Оплата может быть произведена наличными, чеком или кредитной картой. Каждый способ потребует отдельной реализации.
- Оплата кредитной картой может привести ко множеству результатов от успешного платежа до отказа.
- Сервису может потребоваться произвести возврат средств или кредитов на часть или всю сумму покупки.
- Сторонний сервис обработки платежей по кредитным картам может оказаться недоступным из-за сбоя.
- Обработка некоторых платежей может занять несколько дней.
Реализация этой логики в лямбда-функции может привести к запутанному коду («спагетти-коду»), который нелегко читать, понимать и поддерживать. Этот код может стать слабым звеном в рабочей системе. Сложность возрастает, если необходимо реализовать обработку ошибок, выполнять повторные попытки и обрабатывать входные и выходные данные. Использовать лямбда-функцию для реализации подобной логики – плохая практика.
Для этого лучше воспользоваться сервисом AWS Step Functions, который позволит описать алгоритм в виде набора состояний в формате JSON. Такое описание можно сохранять в системе контроля версий. Сервис позволяет реализовывать сложную логику, реакцию на ошибки и механизмы повтора. Продолжительность выполнения процесса в сервисе может составлять до 1 года, при этом сервис умеет работать с различными версиями процесса, а значит вы сможете производить обновления версий не прерывая работу приложения. Использование этого сервиса также сокращает количество кода, который необходимо писать, что облегчает тестирование и сопровождение.
AWS Step Functions подходит для описания логики одного процесса или микросервиса, для координации взаимодействия нескольких сервисов лучше использовать Amazon EventBridge. Это бессерверная шина событий, которая маршрутизирует события на основе правил и упрощает взаимодействие между микросервисами.
Шаблоны, вызывающие зацикливание
Сервисы AWS порождают события, которые вызывают лямбда-функции, а лямбда-функции могут обращаться к сервисам AWS. Как правило, сервис или ресурс, вызывающий лямбда-функцию, должен отличаться от сервиса или ресурса, к которому обращается функция. Несоблюдение этого правила может вызвать зацикливание.
Например, лямбда-функция сохраняет объект в Amazon S3, что, в свою очередь, приводит к вызову той же самой лямбда-функции с помощью события Put. Вызов приведет к созданию нового объекта в корзине, что опять приведет к вызову той же лямбда-функции:

Хотя создать зацикливание можно во множестве языков программирования, в бессерверных приложениях оно приведет к большому расходу ресурсов. Lambda и S3 автоматически масштабируются пропорционально количеству вызовов, поэтому зацикливание может привести к масштабированию Lambda до максимально установленного количества параллельных вызовов, S3 будет продолжать сохранять новые объекты и порождать новые события, вызывающие Lambda. Прекратить масштабирование можно кнопкой «Throttle» в консоли Lambda, опустив максимальное количество параллельных вызовов до нуля, что прервет зацикливание.
В примере используется S3, но возможность зацикливания существует и в Amazon SNS, Amazon SQS, Amazon DynamoDB и других службах. В большинстве случаев безопаснее разделять ресурсы, которые вызывают лямбда-функцию и ресурсы, которые используются лямбда-функцией. Однако, если лямбда-функция все же должна обращаться к сервису, который ее вызвал, убедитесь, что:
- Используется отличающийся триггер: например, триггер объекта S3 может использовать специальное имя или мета-тег, который позволит обрабатывать только первоначальный вызов. Это позволит избежать повторного вызова той же самой функции, объектом, который она же и создала. Ознакомьтесь с подобным подходом на примере приложения S3-to-Lambda Translation.
- Количество параллельных вызовов ограничено: установив количество одновременно разрешенных вызовов в минимально возможное значение, вы ограничите возможность автоматического масштабирования функции. Это не предотвратит зацикливание, но сократит возможный расход ресурсов. Такой подход можно использовать на этапе разработки и тестирования.
- Используйте Amazon CloudWatch для мониторинга и оповещения: настроив оповещение при внезапном увеличении количества параллельно выполняемых вызовов, вы сможете предпринять необходимые действия.
Лямбда-функции, вызывающие лямбда-функции
Функции обеспечивают инкапсуляцию и повторное использование кода. Большинство языков программирования применяют синхронный вызов функций. В этом случае вызывающая функция ждет окончания выполнения вызываемой функции. Эта модель плохо вписывается в большинство вариантов бессерверных приложений.
Например, рассмотрим простое приложение электронной коммерции, состоящее из трех лямбда-функций, которые обрабатывают заказ:
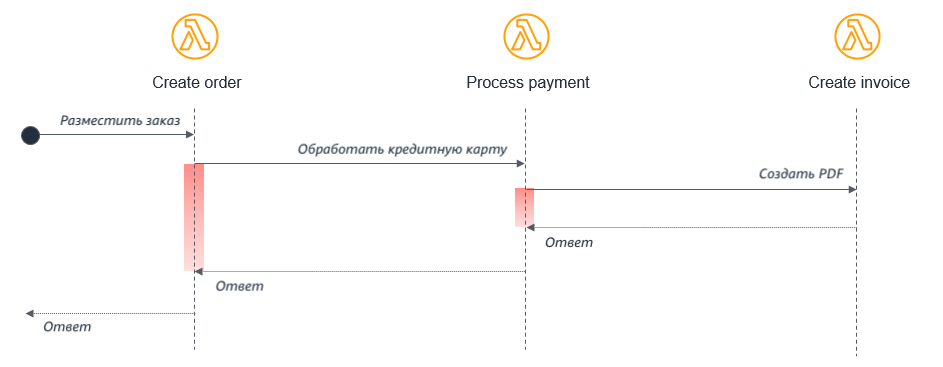
В этом случае функция Create order (Создать заказ) вызывает функцию Process payment (Обработка платежа), которая, в свою очередь, вызывает функцию Create invoice (Создать счёт). Даже если эти функции являются частью одного приложения, выполняющегося на одном и том же сервере, в бессерверной архитектуре, они вызовут несколько проблем, которых можно было бы избежать:
- Затраты: при использовании Lambda вы платите за время выполнения функции. В этом примере пока будет выполняться функция Create invoice, две других функции так же будут тарифицироваться, как выполняющиеся, как это отражено красным цветом на диаграмме.
- Обработка ошибок: Вложенный вызов функций затрудняет обработку. Либо ошибки будут возвращаться в вызывающую функцию для обработки на более высоком уровне, либо потребуется реализовать какую-то нестандартную обработку таких ситуации. Например, если ошибка возникла в функции Create invoice, функция Process payment может попробовать отменить платеж или вызвать Create invoice повторно.
- Сильная связность: Обработка платежа обычно занимает больше времени, чем создание счета. В этой модели скорость работы всего процесса будет определяться медленной функцией.
- Масштабирование: Все три функции придётся масштабировать одинаково. В нагруженной системе такое масштабирование будет избыточным.
В бессерверных приложениях существует два распространенных подхода, позволяющих избавиться от вложенных вызовов. Первый – вставить очередь SQS между вызовами лямбда-функций. Если вызываемая функция медленнее, чем вызывающая, очередь надёжно сохраняет сообщения и развяжет функции. В приведённом примере функция Create order отправляет сообщение в очередь SQS, а функция Process payment получает его из очереди.
Второй подход – использовать AWS Step Functions. Для сложных процессов, требующих реализации сложной логики обработки ошибок и повторения попыток, AWS Step Functions поможет уменьшить количество кода, необходимого для описания процесса. В результате Step Functions будет управлять логикой работы процесса, обеспечит надёжную обработку ошибок и выполнение повторных попыток, а лямбда-функции будут содержать только бизнес-логику.
Синхронное ожидание в рамках одной лямбда-функции
Избегайте синхронной обработки событий, которые могут выполняться параллельно. Например, лямбда-функция выполняет запись в корзину S3, а затем добавляет запись в таблицу DynamoDB:
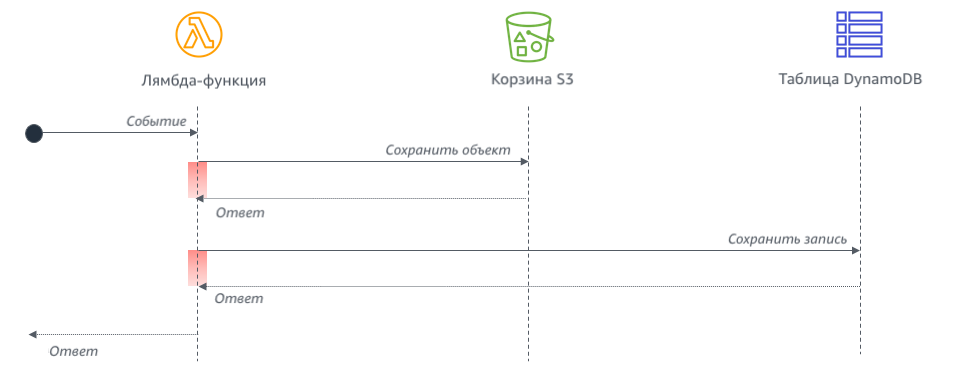
Общее время, которое функция проведёт, ожидая результатов (выделено красным) будет больше, потому что обращения выполняются последовательно. Если задачи независимы, они могут выполняться параллельно, что приведёт к тому, что общее время ожидания будет равно времени выполнения самой продолжительной задачи.

Если же функция зависит от результатов выполнения предыдущей, общее время ожидания и расходы на выполнение можно сократить, разделив лямбда-функции:
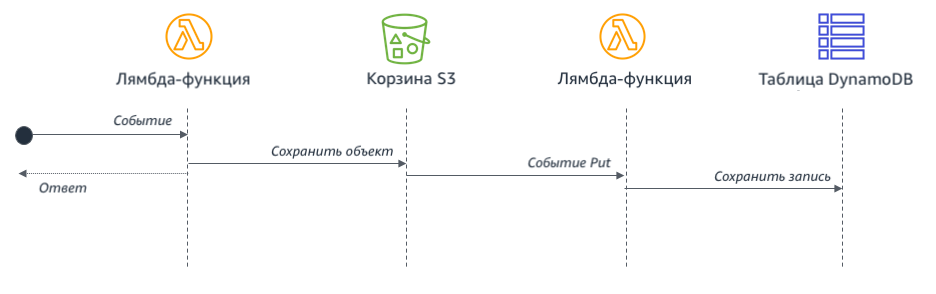 При таком подходе первая лямбда-функция завершается сразу после сохранения объекта в корзину S3. Сервис S3 вызывает вторую лямбда-функцию, которая записывает данные в таблицу DynamoDB. Такой подход сводит к минимуму общее время ожидания при выполнении лямбда-функции.
При таком подходе первая лямбда-функция завершается сразу после сохранения объекта в корзину S3. Сервис S3 вызывает вторую лямбда-функцию, которая записывает данные в таблицу DynamoDB. Такой подход сводит к минимуму общее время ожидания при выполнении лямбда-функции.
Чтобы узнать больше, ознакомьтесь с «Serverless Applications Lens» рекомендаций «AWS Well Architected».
Заключение
Этот пост описывает типовые антипаттерны в архитектуре, управляемой событиями, с использованием Lambda. Я описал некоторые проблемы при использовании монолитных лямбда-функций и использовании лямбда-функций для оркестрации. Я объяснил, как избежать рекурсивных архитектур, которые могут вызвать зацикливание, и почему следует избегать вызова лямбда-функций из лямбда-функций. Я также показал, как сократить время, которое функция проводит в ожидании, для сокращения затрат.
Больше учебных материалов по теме бессерверных вычислений можно найти на странице Serverless Land.