Сложности, связанные с распределенными системами
АРХИТЕКТУРА | УРОВЕНЬ 200
Введение
Как только мы добавили второй сервер, распределенные системы стали повседневной реальностью в компании Amazon. Когда я начал работать в компании Amazon в 1999 году, у нас было так мало серверов, что мы могли давать некоторым из них узнаваемые имена, например fishy или online-01. Однако даже в 1999 году реализовать распределенные вычисления было непросто. Как и сейчас, в распределенных системах существовали проблемы с задержкой, масштабированием, пониманием сетевых API, сериализацией и десериализацией данных, а также сложностью таких алгоритмов, как Paxos. По мере того как системы стремительно росли и становились все более распределенными, теоретические экстремальные случаи становились регулярными явлениями.
Распределенные системы коммунальных вычислений, например магистральные телефонные сети или Amazon Web Services (AWS), очень сложны в разработке. Распределенные вычисления также запутаннее и менее интуитивно понятны, чем другие виды вычислений, по причине двух взаимосвязанных проблем. Независимые отказы и недетерминированность создают наиболее значимые проблемы в распределенных системах. Помимо типичных отказов вычислений, привычных для большинства инженеров, в распределенных системах может возникать множество других отказов. Что еще хуже, не всегда можно определить наличие сбоя.
В «Библиотеке разработчиков Amazon» рассказывается, как сервисы AWS справляются со сложностями разработки и эксплуатационными проблемами, возникающими в распределенных системах. Прежде чем подробно рассматривать эти методики в других статьях, стоит получить представление о том, что же делает распределенные вычисления такими запутанными. Для начала рассмотрим типы распределенных систем.
Типы распределенных систем
На самом деле распределенные системы различаются по сложности реализации. С одного края спектра находятся автономные распределенные системы. К ним относятся системы пакетной обработки, кластеры анализа больших данных, фермы рендеринга сцен кино, кластеры сворачивания белка и т. п. Хотя их реализация совсем непроста, автономные распределенные системы обладают почти всеми преимуществами распределенных вычислений (масштабируемостью и отказоустойчивостью) и практически лишены присущих им недостатков (сложных режимов отказа и недетерминированности).
В середине спектра находятся распределенные системы мягкого реального времени. Это критически важные системы, которые должны непрерывно создавать или обновлять результаты. Однако для этого у них есть много времени. К примерам таких систем относятся некоторые построители поисковых индексов, системы поиска неисправных серверов, роли для Amazon Elastic Compute Cloud (Amazon EC2) и т. д. Индексатор поиска может работать в автономном режиме от 10 минут до нескольких часов (в зависимости от приложения), не оказывая отрицательного влияния на работе пользователей. По сути, роли для Amazon EC2 должны передавать обновленные данные для доступа каждому инстансу EC2, но на это у них есть несколько часов, пока не истечет срок действия старых данных для доступа.
С другого края спектра (и наиболее проблематичного) находятся распределенные системы жесткого реального времени. Их часто называют сервисами типа «запрос-отклик». В компании Amazon при создании распределенных систем в первую очередь рассматривают системы жесткого реального времени. К сожалению, распределенные системы жесткого реального времени сложнее всего реализовать правильно. Это связано с тем, что запросы поступают неожиданно, а отклики необходимо отправлять быстро (например, пользователь целенаправленно ожидает отклика). К их примерам относятся интерфейсные веб-серверы, конвейер заказов, транзакции по кредитным картам, каждый API AWS, системы телефонии и т. д. Основное внимание в этой статье уделяется распределенным системам жесткого реального времени.
Странности систем жесткого реального времени
В одной из сюжетных линий комиксов про Супермена он встречается со своим альтер-эго по имени Бизарро, который живет на планете (в Мире Бизарро), где все наоборот. Бизарро внешне напоминает Супермена, но на самом деле он злодей. Примерно так же дела обстоят и с распределенными системами жесткого реального времени. Они напоминают обычные вычислительные системы, но на самом деле сильно отличаются и, если честно, склоняются на сторону зла.
Главная причина странности таких систем – сети типа «запрос-отклик». Мы не имеем ввиду мельчайшие подробности TCP/IP, DNS, сокетов и других протоколов. Эти темы могут быть сложны для понимания, но они подобны другим сложным проблемам, связанным с вычислениями.
Распределенные системы жесткого реального времени делает такими сложными тот факт, что сеть позволяет отправлять сообщения из одного домена с отказом в другой. Отправка сообщения кажется безобидной задачей. Но на самом деле именно при отправке сообщения все становится сложнее, чем обычно.
В качестве простого примера рассмотрим приведенный ниже фрагмент кода из реализации игры Pac-Man. Он предназначен для работы на одном компьютере, поэтому не отправляет сообщений по сети.
board.move(pacman, user.joystickDirection())
ghosts = board.findAll(":ghost")
for (ghost in ghosts)
if board.overlaps(pacman, ghost)
user.slayBy(":ghost")
board.remove(pacman)
return
А теперь давайте представим сетевую версию этого кода, где состояние объекта board хранится на отдельном сервере. Каждое обращение к объекту board, например findAll(), приводит к отправке и получению сообщений между двумя серверами.
Когда с одного сервера на другой отправляется сообщение типа «запрос-отклик», всегда должна выполняться минимальная последовательность из восьми действий. Чтобы понять, как работает сетевой код Pac-Man, рассмотрим основы передачи сообщений типа «запрос-отклик».
Передача сообщений по сети
Передача сообщений типа «запрос-отклик» по сети
Один цикл «запрос-отклик» всегда состоит из одних и тех же этапов. Как показано на приведенной ниже схеме, компьютер клиента CLIENT отправляет MESSAGE по сети NETWORK на серверный компьютер SERVER, который отправляет в ответ сообщение REPLY, также по сети NETWORK
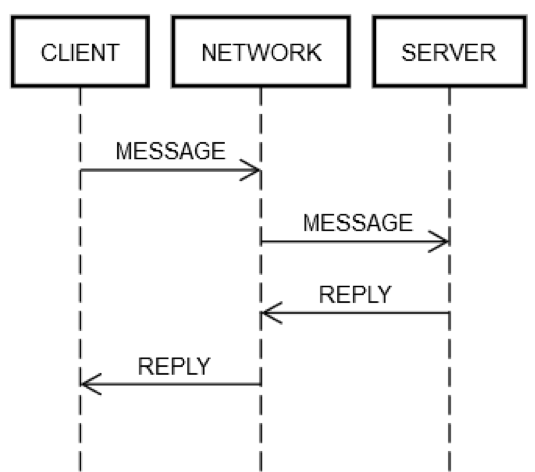
При благоприятных условиях, когда все работает правильно, выполняются следующие действия:
-
ОТПРАВКА ЗАПРОСА: CLIENT отправляет запрос MESSAGE в сеть NETWORK.
-
ДОСТАВКА ЗАПРОСА: сеть NETWORK доставляет MESSAGE на компьютер SERVER.
-
ПРОВЕРКА ЗАПРОСА: SERVER проверяет MESSAGE.
-
ОБНОВЛЕНИЕ СОСТОЯНИЯ СЕРВЕРА: при необходимости SERVER обновляет свое состояние в соответствии с MESSAGE.
-
ОТПРАВКА ОТВЕТА: SERVER отправляет сообщение REPLY в сеть NETWORK.
-
ДОСТАВКА ОТВЕТА: сеть NETWORK доставляет REPLY на компьютер CLIENT.
-
ПРОВЕРКА ОТВЕТА: CLIENT проверяет REPLY.
-
ОБНОВЛЕНИЕ СОСТОЯНИЯ КЛИЕНТА: при необходимости CLIENT обновляет свое состояние в соответствии с REPLY.
Многовато действий для одного простого цикла! Однако эти этапы образуют определение связи типа «запрос-отклик» по сети, поэтому их невозможно пропустить. Например, невозможно пропустить этап 1. Клиент должен как-нибудь передать MESSAGE в сеть NETWORK. С физической точки зрения это означает отправку пакетов через сетевой адаптер, в результате чего электрические сигналы передаются через серию маршрутизаторов, образующих сеть между компьютерами CLIENT и SERVER. Это действие указано отдельно от действий этапа 2, так как он может завершиться неудачей по независимым причинам, таким как неожиданная потеря питания компьютера SERVER и невозможность принять входящие пакеты. Такая же логика применима и к остальным этапам.
Таким образом, один цикл «запрос-отклик» по сети разбивает одно действие (называемое методом) на восемь этапов. Что еще хуже, как упоминалось выше, CLIENT, SERVER и NETWORK могут отказывать независимо друг от друга. В коде должна быть предусмотрена обработка отказов на каждом из этапов. При обычном проектировании это требуется редко. Чтобы понять причину этого, рассмотрим приведенное ниже выражение из версии этого кода для одного компьютера.
board.find("pacman")
С технической точки зрения возможны неожиданные сбои кода во время выполнения, даже если метод board.find реализован без ошибок. Например, ЦП может спонтанно перегреться. Может случиться спонтанный перебой питания. Может появиться ошибка kernel panic. Память может переполниться, из-за чего методу board.find не удастся создать нужный объект. Или заполнится диск на компьютере, и метод board.find не сможет обновить файл статистики, а затем вернет сообщение об ошибке, хотя в этом нет необходимости. В результате воздействия гамма-излучения на сервер может измениться бит в ОЗУ. Но большую часть времени инженеры не беспокоятся о таких вещах. Например, при модульном тестировании возможность сбоя ЦП никогда не учитывается, а сценарии нехватки памяти рассматриваются лишь в редких случаях.
При типичном проектировании такие сбои происходят на одном компьютере, то есть в одной области сбоя. Например, если метод board.find даст сбой из-за спонтанного перегрева ЦП, можно с уверенностью сказать, что отказал весь компьютер. С этой ошибкой невозможно справиться даже теоретически. Такие же предположения можно сделать и о других ошибках, перечисленных выше. Вы можете попробовать написать тесты для некоторых из этих случаев, но при типичном проектировании в этом мало смысла. Если такие сбои произойдут, можно с уверенностью сказать, что откажет и все остальное. В технике этот принцип называется разделением судьбы (fate-sharing). Разделение судьбы избавляет инженера от необходимости обработки множества различных режимов отказа.
Обработка отказа
Обработка режимов отказа в распределенных системах жесткого реального времени
Инженерам, работающим над распределенными системами жесткого реального времени, необходимо тестировать все аспекты сбоев сети, поскольку серверы и сеть не разделяют одну судьбу. В отличие от случая с одним компьютером, если произойдет сбой сети, клиентская машина продолжит работать. Если произойдет сбой удаленного компьютера, клиентская машина продолжит работать, ну и так далее.
Для тщательного тестирования сбоев на каждом из вышеописанных этапов цикла «запрос-ответ» инженерам необходимо предполагать, что сбой может произойти на любом этапе. Кроме того, им необходимо обеспечить корректную работу кода (как на клиентском компьютере, так и на сервере) в случае таких сбоев.
Рассмотрим действие цикла «запрос-ответ», где что-либо не работает:
-
Отказ при ОТПРАВКЕ ЗАПРОСА: либо сети NETWORK не удалось доставить сообщение (например, в неподходящий момент отказал промежуточный маршрутизатор), либо сам SERVER отклонил его.
-
Отказ при ДОСТАВКЕ ЗАПРОСА: сеть NETWORK успешно доставляет сообщение MESSAGE на SERVER, но SERVER отказывает сразу после получения сообщения MESSAGE.
-
Отказ при ПРОВЕРКЕ ЗАПРОСА: SERVER определяет сообщение MESSAGE как неверное. Причина может быть практически любой. Например, это могут быть поврежденные пакеты, несовместимые версии программного обеспечения либо ошибки на стороне клиента или сервера.
-
Отказ при ОБНОВЛЕНИИ СОСТОЯНИЯ СЕРВЕРА: SERVER безуспешно пытается обновить свое состояние.
-
Отказ при ОТПРАВКЕ ОТВЕТА: SERVER может не отправить ответ об успешном или исполнении или отказе. Например, его сетевая карта может сгореть в самый неподходящий момент.
-
Отказ при ДОСТАВКЕ ОТВЕТА: сеть NETWORK может не доставить ответ REPLY на компьютер CLIENT, как описано выше, даже если это удавалось на предыдущем этапе.
-
Отказ при ПРОВЕРКЕ ОТВЕТА: CLIENT считает ответ REPLY неверным.
-
Отказ при ОБНОВЛЕНИИ СОСТОЯНИЯ КЛИЕНТА: CLIENT получает ответ REPLY, но не может обновить свое состояние, неправильно интерпретирует сообщение (в связи с несовместимостью), или отказ возникает по какой-либо другой причине.
Именно эти режимы отказа делают распределенные вычисления такими сложными. Я называю их восемью режимами апокалипсиса. Давайте снова рассмотрим выражение из кода Pac-Man в контексте этих режимов отказа.
board.find("pacman")
Это выражение относится к следующим действиям на стороне клиента:
-
Отправка через сеть сообщения, например {action: "find", name: "pacman", userId: "8765309"}, адресованного компьютеру Board.
-
Если сеть недоступна или подключение к компьютеру Board было явно отклонено, выводится ошибка. Этот случай в некоторой степени уникален, ведь клиент знает с детерминированностью, что запрос не мог быть получен серверным компьютером.
-
Ожидание ответа.
-
Если ответ не получен, ожидание прерывается. На этом этапе под прерыванием ожидания подразумевается, что запрос возвращает результат UNKNOWN. Это может не произойти. Клиент должен корректно обрабатывать результат UNKNOWN.
-
Если ответ получен, необходимо определить, какой он: успешный, ошибочный или непонятный/поврежденный.
-
Если это не ошибка, ответ десериализуется и преобразуется в объект, распознаваемый кодом.
-
Если это ошибка или непонятный ответ, создается исключение.
-
Сторона, которая создает исключение, должна определить, нужен ли повторный запрос.
Выражение также запускает следующие действия на стороне сервера:
-
Получение запроса (это может вообще не произойти).
-
Проверка запроса.
-
Проверка, на месте ли пользователь. (Сервер мог перестать обслуживать пользователя, так как слишком долго не получал от него сообщений.)
-
Обновление графика связи с пользователем, чтобы сервер знал, что пользователь (скорее всего) еще на месте.
-
Поиск расположения пользователя.
-
Отправка ответа, содержащего примерно такие данные: {xPos: 23, yPos: 92, clock: 23481984134}.
-
Вся дальнейшая серверная логика должна корректно обрабатывать будущие последствия для клиента. Возможно, клиент не может получить сообщение или интерпретировать его. Возможно, он успешно обработает сообщение или выдаст отказ после получения.
Подводя итог, одно выражение в обычном коде превращается в пятнадцать дополнительных этапов в коде распределенных систем жесткого реального времени. Это расширение вызвано наличием восьми различных точек, в которых каждое циклическое взаимодействие между клиентом и сервером может привести к отказу. Любое выражение, представляющее прием и передачу в сети, например board.find("pacman"), дает представленные ниже результаты.
(error, reply) = network.send(remote, actionData)
switch error
case POST_FAILED:
// handle case where you know server didn't get it
case RETRYABLE:
// handle case where server got it but reported transient failure
case FATAL:
// handle case where server got it and definitely doesn't like it
case UNKNOWN: // i.e., time out
// handle case where the only thing you know is that the server received
// the message; it may have been trying to report SUCCESS, FATAL, or RETRYABLE
case SUCCESS:
if validate(reply)
// do something with reply object
else
// handle case where reply is corrupt/incompatible
Этой сложности не избежать. Если код не обрабатывает все случаи корректно, сервис рано или поздно начнет отказывать при странных обстоятельствах. Представьте, сколько тестов придется писать для всех режимов отказа, с которыми может столкнуться система «клиент-сервер», такая как наш пример с Pac-Man!
Тестирование
Тестирование распределенных систем жесткого реального времени
Тестировать версию фрагмента кода Pac-Man для одного компьютера относительно просто. Создайте несколько разных объектов Board, переведите их в различные состояния, создайте объекты User в разных состояниях и т. д. Инженеры больше всего задумываются об экстремальных условиях и могут использовать генеративное тестирование или фаззинг.
В коде Pac-Man объект board используется в четырех местах. В коде распределенной версии Pac-Man есть четыре места с пятью возможными исходами, как показано выше (POST_FAILED, RETRYABLE, FATAL, UNKNOWN или SUCCESS). Они существенно умножают пространство состояний тестов. Например, инженеры распределенных систем жесткого реального времени должны обрабатывать множество сочетаний. Допустим, вызов метода board.find() завершается ошибкой POST_FAILED. В таком случае вам нужно проверить, что происходит при сбое с состоянием RETRYABLE, а затем – при сбое с состоянием FATAL и т. д.
Но даже такого тестирования недостаточно. В типичном коде инженеры могут предположить, что если метод board.find() работает, то будет работать и следующий вызов объекта board с методом board.move(). При разработке распределенных систем жесткого реального времени такой гарантии нет. Серверный компьютер может в любой момент отказать по независимым причинам. В результате инженерам приходится писать тесты для всех пяти случаев при каждом вызове объекта board. Допустим, инженер придумал 10 сценариев тестирования версии Pac-Man для одного компьютера. Однако в версии для распределенных систем каждый из этих сценариев потребуется испытать 20 раз. Таким образом, тестовая матрица значительно увеличивается (200 вместо 10).
Но и это еще не все. Инженеру также может принадлежать серверный код. Какое бы ни возникло сочетание ошибок клиента, сети и сервера, необходимо протестировать его, чтобы клиент и сервер не оказались в поврежденном состоянии. Серверный код может выглядеть, как показано ниже.
handleFind(channel, message)
if !validate(message)
channel.send(INVALID_MESSAGE)
return
if !userThrottle.ok(message.user())
channel.send(RETRYABLE_ERROR)
return
location = database.lookup(message.user())
if location.error()
channel.send(USER_NOT_FOUND)
return
else
channel.send(SUCCESS, location)
handleMove(...)
...
handleFindAll(...)
...
handleRemove(...)
...
Необходимо протестировать четыре функции на стороне сервера. Предположим, что для каждой функции на одном компьютере предусмотрено по пять тестов. Уже получается 20 тестов. Так как клиенты отправляют множество сообщений на один сервер, в тестах должны моделироваться последовательности различных запросов, чтобы обеспечить надежную работу сервера. Примеры запросов: find, move, remove и findAll.
Допустим, одна конструкция содержит 10 разных сценариев, в среднем по три вызова на каждый сценарий. Вот и еще 30 тестов. Но в одном сценарии также необходимо тестировать случаи отказа. Для каждого из этих тестов необходимо моделировать, что произойдет, если у клиента возникла ошибка какого-либо из четырех типов (POST_FAILED, RETRYABLE, FATAL и UNKNOWN), а затем он снова вызвал сервер, отправив недопустимый запрос. Например, клиент может успешно вызвать метод find, но иногда получать результат UNKNOWN при вызове метода move. Затем он может по той или иной причине заново вызвать метод find. Обрабатывает ли сервер такой случай надлежащим образом? Скорее всего, но вы не узнаете наверняка, пока не испытаете его. Таким образом, как и в случае с кодом на стороне клиента, тестовая матрица на стороне сервера стремительно усложняется.
Обработка неизвестных ошибок
Обработка неизвестных ошибок
Уму непостижимо, сколько сочетаний ошибок может произойти в распределенной системе, особенно при обработке множества запросов. Один из подходов к проектированию распределенных систем – подвергать сомнению все. Каждая строка кода (кроме тех, которые никак не касаются связи по сети) может не справиться со своей задачей.
Наверное, сложнее всего обрабатывать ошибки типа UNKNOWN, описанные в предыдущем разделе. Клиенту не всегда известно, успешно ли выполнен запрос. Возможно, он переместил Pac-Man (или снял средства со счета пользователя, если речь о банковском сервисе), а может и нет. Как инженерам обрабатывать такие ситуации? Это сложно, ведь инженеры – всего лишь люди, а людям сложно справляться с настоящей неопределенностью. Люди привыкли видеть код так, как показано ниже.
bool isEven(number)
switch number % 2
case 0
return true
case 1
return false
Им понятен этот код, потому что он работает именно так, как выглядит. Людям сложнее разобраться в распределенной версии кода, которая передает часть задач сервису.
bool distributedIsEven(number)
switch mathServer.mod(number, 2)
case 0
return true
case 1
return false
case UNKNOWN
return WHAT_THE_FARG?
Человеку практически невозможно разобраться, как правильно обрабатывать ошибки типа UNKNOWN. Что же на самом деле означает UNKNOWN? Стоит ли коду повторить попытку? Если да, то сколько раз? Каким должен быть интервал между попытками? Дела обстоят еще хуже, если у кода есть побочные эффекты. В приложении для составления бюджета, работающем на одном компьютере, можно легко снять средства со счета, как показано в приведенном ниже примере.
class Teller
bool doWithdraw(account, amount)
switch account.withdraw(amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
Однако распределенная версия этого приложения работает непредсказуемо из-за ошибок типа UNKNOWN.
class DistributedTeller
bool doWithdraw(account, amount)
switch this.accountService.withdraw(account, amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
case UNKNOWN
return WHAT_THE_FARG?
Необходимость в обработке ошибок типа UNKNOWN – это одна из причин, по которым при проектировании распределенных систем не все так, как кажется на первый взгляд.
Скопления
Скопления распределенных систем жесткого реального времени
Восемь режимов апокалипсиса могут возникать на любом уровне абстрагирования в распределенной системе. Приведенный выше пример был ограничен одной клиентской машиной, сетью и одним серверным компьютером. Даже в таком простом сценарии матрица состояний отказа стала очень сложной. Настоящие распределенные системы обладают более сложными матрицами состояний отказа, чем пример с одной клиентской машиной. Настоящие распределенные системы состоят из множества компьютеров, которые можно рассматривать на множестве уровней абстрагирования.
-
Отдельные компьютеры
-
Группы компьютеров
-
Группы групп компьютеров
-
И так далее (возможно)
Например, сервис на основе AWS может сгруппировать компьютеры, которые предназначены для обработки ресурсов, находящихся в определенной зоне доступности. Кроме того, может существовать еще две группы компьютеров, обслуживающих две другие зоны доступности. Затем эти группы можно собрать в группу региона AWS. А эта группа региона может взаимодействовать (логически) с группами других регионов. К сожалению, даже на этом высоком и более логичном уровне возникают все те же проблемы.
Предположим, что сервис собрал несколько серверов в одну логическую группу, GROUP1. Группа GROUP1 может иногда отправлять сообщения другой группе серверов – GROUP2. Это пример рекурсивного распределенного проектирования. В этом случае могут возникать все вышеописанные режимы отказа сети. Допустим, группе GROUP1 нужно отправить запрос группе GROUP2. Как показано на приведенной ниже схеме, взаимодействие типа «запрос-отклик» между двумя компьютерами аналогично вышеописанному случаю с одним компьютером.
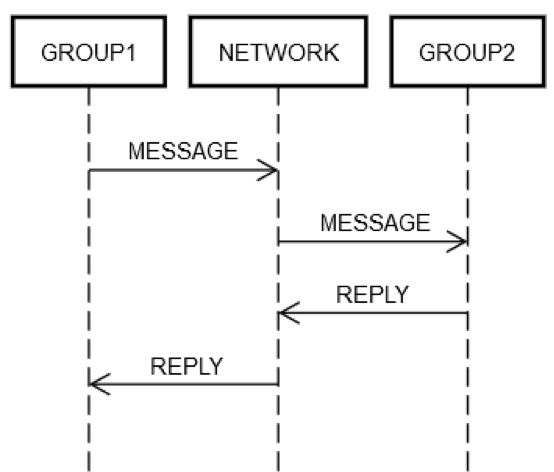
Так или иначе, какой-нибудь компьютер из группы GROUP1 должен отправить сообщение в сеть NETWORK, адресовав его (логически) группе GROUP2. Какой-то компьютер из группы GROUP2 должен обработать запрос, ну и так далее. Тот факт, что группы GROUP1 и GROUP2 состоят из групп компьютеров, не меняет фундаментальных фактов. GROUP1, GROUP2 и NETWORK по-прежнему могут отказывать независимо друг от друга.
Однако это лишь представление на уровне группы. В каждой группе также происходит взаимодействие между компьютерами. Например, структура группы GROUP2 может быть такой, как на приведенной ниже схеме.
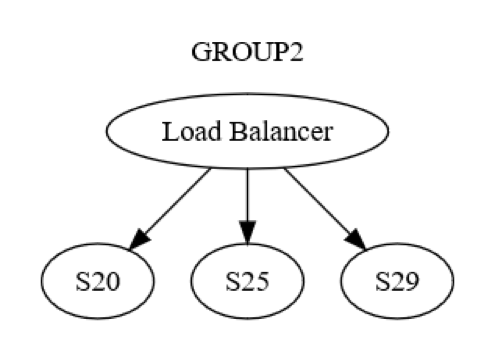
Сначала сообщение для группы GROUP2 отправляется через балансировщик нагрузки на один компьютер (возможно, S20) в группе. Разработчикам системы известно, что S20 может отказать на этапе ОБНОВЛЕНИЯ СОСТОЯНИЯ. В результате компьютеру S20 может потребоваться передать сообщение как минимум одному другому компьютеру (либо из той же, либо из другой группы). Как же компьютер S20 сделает это? Он отправит сообщение типа «запрос-отклик», скажем, компьютеру S25, как показано на приведенной ниже схеме.
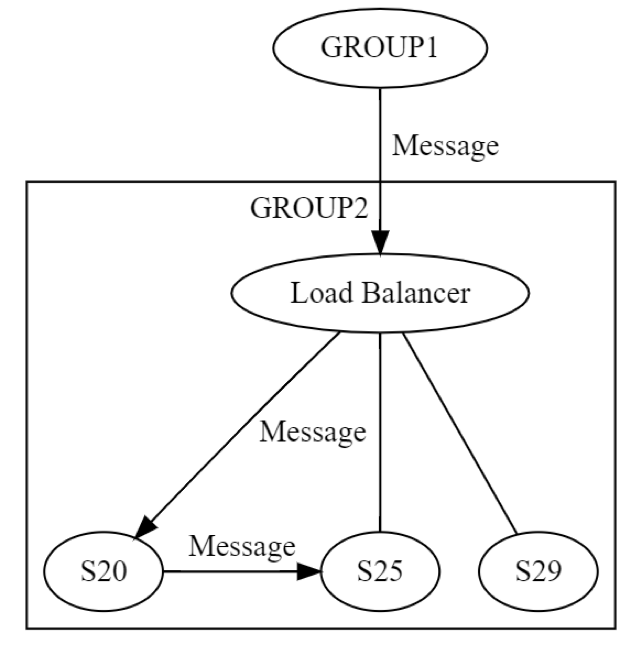
Следовательно, S20 работает в сети рекурсивно. Все восемь сбоев опять могут возникнуть независимо друг от друга. Распределенное проектирование осуществляется дважды, а не один раз. На логическом уровне сообщение от группы GROUP1, адресованное группе GROUP2, может быть не доставлено по восьми причинам. В результате отправляется еще одно сообщение, которое также может быть не доставлено из-за независимого сбоя по одной из восьми причин, рассматриваемых выше. Для тестирования этого сценария потребуется, как минимум, следующее:
-
тесты для всех восьми возможных ошибок при передаче сообщений из GROUP1 в GROUP2 на уровне групп,
-
тесты для всех восьми возможных ошибок при передаче сообщений от S20 к S25 на уровне сервера.
В этом примере передачи сообщений типа «запрос-отклик» показано, почему тестирование распределенных систем остается особенно трудной задачей даже спустя 20 лет работы с ними. Тестирование является сложной задачей, учитывая огромное количество экстремальных случаев, но оно особенно важно в таких системах. Ошибки могут обнаруживаться спустя продолжительное время после развертывания систем. Кроме того, они могут оказывать непредсказуемо широкое влияние на систему и смежные системы.
Распределенные ошибки
Ошибки в распределенных системах часто бывают скрытыми
Если существует риск возникновения отказа, считается, что чем раньше он произойдет, тем лучше. Например, лучше узнать о проблеме с масштабированием сервиса, на исправление которой уйдет шесть месяцев, не менее чем за шесть месяцев до того, как систему потребуется масштабировать. Аналогичным образом, ошибки лучше обнаруживать до того, как они возникнут в рабочей среде. Если же ошибки все-таки возникнут в рабочей среде, лучше обнаружить их как можно быстрее, прежде чем они повлияют на многих клиентов или окажут другое отрицательное влияние.
Распределенные ошибки (то есть вызванные неудачной попыткой обработать все сочетания восьми режимов отказа) часто приводят к серьезным последствиям. Множество примеров этого можно найти в крупных распределенных системах, начиная с телекоммуникационных и заканчивая базовыми интернет-системами. Такие отказы не только широко распространены и затратны, но и могут быть вызваны ошибками в коде, развернутом в рабочей среде за месяцы до этого. Затем потребуется много времени, чтобы определить сочетание сценариев, которые на самом деле приводят к этим ошибкам (и их распространению по всей системе).
Распределенные ошибки распространяются как эпидемия
Рассмотрим еще одну фундаментальную проблему распределенных ошибок.
-
Распределенные ошибки всегда связаны с использованием сети.
-
Таким образом, распределенные ошибки с большей вероятностью распространятся на другие компьютеры (или группы компьютеров), так как по определению они затрагивают единственное, чем объединены эти компьютеры.
В компании Amazon тоже возникали распределенные ошибки. Старый, но уместный пример – полный отказ сайта www.amazon.com. Сбой был вызван отказом одного сервера в сервисе удаленного каталога при заполнении диска.
Из-за неправильной обработкой этой ошибки сервер удаленного каталога начал возвращать пустые отклики на каждый полученный запрос. Он также стал возвращать их очень быстро, ведь намного проще вернуть пустой отклик, чем какие-либо данные (по крайней мере, так было в нашем случае). При этом балансировщик нагрузки между веб-сайтом и сервисом удаленного каталога не замечал, что длина всех откликов была нулевой. Однако он заметил, что они работали намного быстрее, чем все остальные серверы удаленных каталогов. По этой причине он отправил огромное количество трафика с сайта www.amazon.com на тот сервер удаленного каталога, диск которого был заполнен. По сути, весь веб-сайт отказал из-за того, что один удаленный сервер не мог вывести никаких сведений о продуктах.
Мы быстро обнаружили неисправный сервер и удалили его из сервиса, чтобы восстановить веб-сайт. Затем мы прошли наш обычный процесс определения первопричин и выявления проблем, чтобы предотвратить повторение такой ситуации. Мы поделились опытом с другими отделами компании Amazon, чтобы помочь предотвратить возникновение такой же проблемы в других системах. Этот инцидент не только преподал нам важный урок об этом режиме отказа, но и послужил отличным примером того, как быстро и неожиданно распространяются отказы в распределенных системах.
Краткое описание
Краткое описание проблем в распределенных системах
Проектирование распределенных систем является трудной задачей по перечисленным ниже причинам.
-
Инженеры не могут совмещать условия ошибок. Вместо этого им приходится учитывать множество сочетаний сбоев. Большинство ошибок возможны в любое время и не зависят от других условий ошибок (а значит, могут возникнуть и в сочетании с ними).
-
Любая сетевая операция может возвращать результат UNKNOWN. При этом запрос может быть выполнен успешно, завершиться сбоем либо может быть получен, но не обработан.
-
Распределенные проблемы возникают на всех логических уровнях распределенной системы, а не только на физических компьютерах низкого уровня.
-
В связи с рекурсией распределенные проблемы усугубляются на верхних уровнях системы.
-
Распределенные ошибки часто появляются спустя продолжительное время после развертывания кода в системе.
-
Распределенные ошибки могут распространяться по всей системе.
-
Многие из вышеописанных проблем обусловлены законами физики сети, которые невозможно изменить.
Сложность (и непредсказуемость) распределенных вычислений еще не означает, что эти проблемы невозможно устранить. В «Библиотеке разработчиков Amazon» мы подробно рассматриваем, как сервисы AWS управляют распределенными системами. Надеемся, что полученная нами информация будет полезна при разработке систем для ваших клиентов.
Об авторе
Джейкоб Габриэльсон – главный инженер в Amazon Web Services. Он сотрудничает с Amazon уже 17 лет и занимается в основном разработкой внутренних платформ микросервисов. Последние 8 лет он работает над EC2 и ECS, в том числе отвечает за системы развертывания программного обеспечения, сервисы плоскости управления, спотовый рынок, платформу Lightsail и (в последнее время) контейнеры. Джейкоб увлекается программированием систем, языками программирования и распределенными вычислениями. Больше всего ему не нравится двухрежимное поведение системы, особенно при возникновении сбоев. Он закончил Вашингтонский университет (г. Сиэтл), получив диплом бакалавра по компьютерным наукам.

Похожие материалы
Нашли то, что искали сегодня?
Скажите, как улучшить качество контента на наших страницах