AWS Big Data Blog
Category: Amazon Managed Streaming for Apache Kafka (Amazon MSK)

How SOCAR built a streaming data pipeline to process IoT data for real-time analytics and control
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. SOCAR is the leading Korean mobility company with strong competitiveness in car-sharing. SOCAR has become a comprehensive mobility platform in collaboration with Nine2One, an e-bike sharing service, […]

Retain more for less with tiered storage for Amazon MSK
Organizations are adopting Apache Kafka and Amazon Managed Streaming for Apache Kafka (Amazon MSK) to capture and analyze data in real-time. Amazon MSK allows you to build and run production applications on Apache Kafka without needing Kafka infrastructure management expertise or having to deal with the complex overheads associated with running Apache Kafka on your […]

Use MSK Connect for managed MirrorMaker 2 deployment with IAM authentication
March 2025: This post was reviewed and updated for accuracy. MSK Replicator now makes it easier to set up cross-Region and same-Region replication without running MirrorMaker 2. Read AWS News Blog to learn more. In this post, we show how to use MSK Connect for MirrorMaker 2 deployment with AWS Identity and Access Management (IAM) authentication. We create […]

Split your monolithic Apache Kafka clusters using Amazon MSK Serverless
Today, many companies are building real-time applications to improve their customer experience and get immediate insights from their data before it loses its value. As the result, companies have been facing increasing demand to provide data streaming services such as Apache Kafka for developers. To meet this demand, companies typically start with a small- or […]

Reduce network traffic costs of your Amazon MSK consumers with rack awareness
May 2025: This post was reviewed and the CloudFormation template was updated for accuracy Amazon Managed Streaming for Apache Kafka (Amazon MSK) runs Apache Kafka clusters for you in the cloud. Although using cloud services means you don’t have to manage racks of servers any more, we take advantage of rack aware features in Apache […]

Best practices to optimize cost and performance for AWS Glue streaming ETL jobs
AWS Glue streaming extract, transform, and load (ETL) jobs allow you to process and enrich vast amounts of incoming data from systems such as Amazon Kinesis Data Streams, Amazon Managed Streaming for Apache Kafka (Amazon MSK), or any other Apache Kafka cluster. It uses the Spark Structured Streaming framework to perform data processing in near-real […]

How Epos Now modernized their data platform by building an end-to-end data lake with the AWS Data Lab
Epos Now provides point of sale and payment solutions to over 40,000 hospitality and retailers across 71 countries. Their mission is to help businesses of all sizes reach their full potential through the power of cloud technology, with solutions that are affordable, efficient, and accessible. Their solutions allow businesses to leverage actionable insights, manage their […]

Introducing Protocol buffers (protobuf) schema support in AWS Glue Schema Registry
AWS Glue Schema Registry now supports Protocol buffers (protobuf) schemas in addition to JSON and Avro schemas. This allows application teams to use protobuf schemas to govern the evolution of streaming data and centrally control data quality from data streams to data lake. AWS Glue Schema Registry provides an open-source library that includes Apache-licensed serializers […]

Back up and restore Kafka topic data using Amazon MSK Connect
This blog is only meant to be used as a reference for backing up and restoring data for an Amazon MSK cluster. AWS does not offer any support for it. You can use Apache Kafka to run your streaming workloads. Kafka provides resiliency to failures and protects your data out of the box by replicating […]
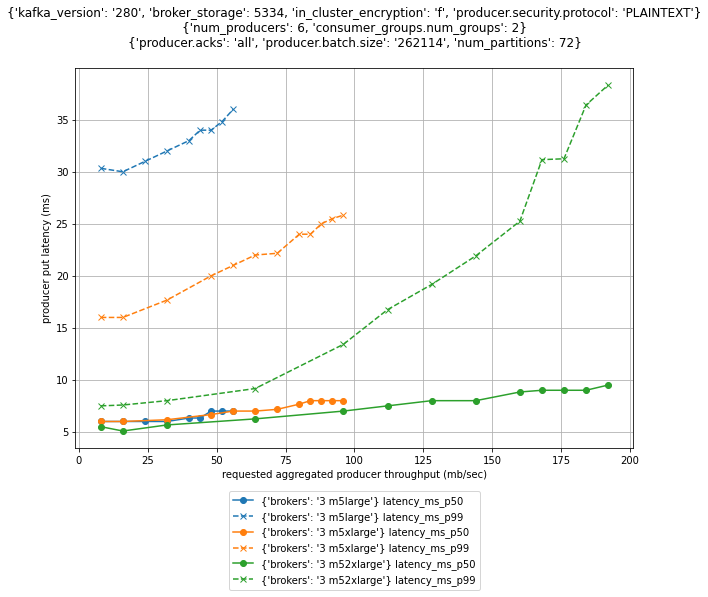
Best practices for right-sizing your Apache Kafka clusters to optimize performance and cost
Apache Kafka is well known for its performance and tunability to optimize for various use cases. But sometimes it can be challenging to find the right infrastructure configuration that meets your specific performance requirements while minimizing the infrastructure cost. This post explains how the underlying infrastructure affects Apache Kafka performance. We discuss strategies on how […]