May 2025: This post was reviewed and the CloudFormation template was updated for accuracy
Amazon Managed Streaming for Apache Kafka (Amazon MSK) runs Apache Kafka clusters for you in the cloud. Although using cloud services means you don’t have to manage racks of servers any more, we take advantage of rack aware features in Apache Kafka to spread risk across AWS Availability Zones and increase availability of Amazon MSK services. Apache Kafka brokers have been rack aware since version 0.10. As the name implies, rack awareness provides a mechanism by which brokers can be configured to be aware of where they are physically located. We can use the broker.rack configuration variable to assign each broker a rack ID.
Why would a broker want to know where it’s physically located? Let’s explore two primary reasons. The first original reason revolves around designing for high availability (HA) and resiliency in Apache Kafka. The next reason, starting in Apache Kafka 2.4, can be utilized for cutting costs of your cross-Availability Zone traffic from consumer applications.
In this post, we review the HA and resiliency reason in Apache Kafka and Amazon MSK, then we dive deeper into how to reduce the costs of cross-Availability Zone traffic with rack aware consumers.
Rack awareness overview
The design decision for implementing rack awareness is actually quite simple, so let’s start with the key concepts. Because Apache Kafka is a distributed system, resiliency is a foundational construct that must be addressed. In other words, in a distributed system, one or more broker nodes going offline is a given and must be accounted for when running in production.
In Apache Kafka, one way to plan for this inevitability is through data replication. You can configure Apache Kafka with the topic replication factor. This setting indicates how many copies of the topic’s partition data should be maintained across brokers. A replication factor of 3 indicates the topic’s partitions should be stored on at least three brokers, as illustrated in the following diagram.
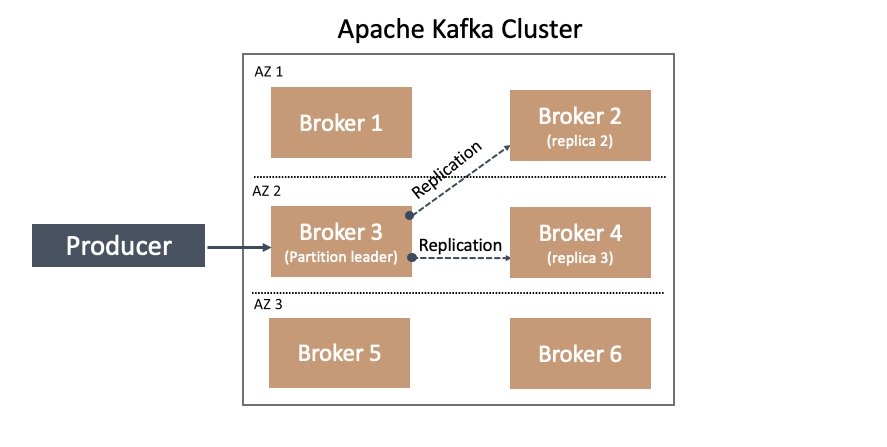
For more information on replication in Apache Kafka, including relevant terminology such as leader, replica, and followers, see Replication.
Now let’s take this a step further.
With rack awareness, Apache Kafka can choose to balance the replication of partitions on brokers across different racks according to the replication factor value. For example, in a cluster with six brokers configured with three racks (two brokers in each rack), and a topic replication factor of 3, replication is attempted across all three racks—a leader partition is on a broker in one rack, with replication to the other two brokers in each of the other two racks.
This feature becomes especially interesting when disaster planning for an Availability Zone going offline. How do we plan for HA in this case? Again, the answer is found in rack awareness. If we configure our broker’s broker.rack config setting based on the Availability Zone (or data center location) in which it resides for example, we can be resilient to Availability Zone failures. How does this work? We can build upon the previous example—in a six-node Kafka cluster deployed across three Availability Zones, two nodes are in each Availability Zone and configured with a broker.rack according to their respective Availability Zone. Therefore, a replication factor of 3 is attempted to store a copy of partition data in each Availability Zone. This means a copy of your topic’s data resides in each Availability Zone, as illustrated in the following diagram.

One of the many benefits of choosing to run your Apache Kafka workloads in Amazon MSK is the broker.rack variable on each broker is set automatically according to the Availability Zone in which it is deployed. For example, when you deploy a three-node MSK cluster across three Availability Zones, each node has a different broker.rack setting. Or, when you deploy a six-node MSK cluster across three Availability Zones, you have a total of three unique broker.rack values.
Additionally, a noteworthy benefit of choosing Amazon MSK is that replication traffic across Availability Zones is included with service. You’re not charged for broker replication traffic that crosses Availability Zone boundaries!
In this section, we covered the first reason for being Availability Zone aware: data produced is spread across all the Availability Zones for the cluster, improving durability and availability when there are issues at the Availability Zone level.
Next, let’s explore a second use of rack awareness—how to use it to cut network traffic costs of Kafka consumers.
Starting in Apache Kafka 2.4, KIP-392 was implemented to allow consumers to fetch from the closest replica.
Before closest replica fetching was allowed, all consumer traffic went to the leader of a partition, which could be in a different rack, or Availability Zone, than the client consuming data. But with capability from KIP-392 starting in Apache Kafka 2.4, we can configure our Kafka consumers to read from the closest replica brokers rather than the partition leader. This opens up the potential to avoid cross-Availability Zone traffic costs if a replica follower resides in the same Availability Zone as the consuming application. How does this happen? It’s built on the previously described rack awareness functionality in Apache Kafka brokers and extended to consumers.
Let’s cover a specific example of how to implement this in Amazon MSK and Kafka consumers.
Implement fetch from closest replica in Amazon MSK
In addition to needing to deploy Apache Kafka 2.4 or above (Amazon MSK 2.4.1.1 or above), we need to set two configurations.
In this example, I’ve deployed a three-broker MSK Express cluster across three Availability Zones, which means one broker resides in each Availability Zone. In addition, I’ve deployed an Amazon Elastic Compute Cloud (Amazon EC2) instance in one of these Availability Zones. On this EC2 instance, I’ve downloaded and extracted Apache Kafka, so I can use the command line tools available such as kafka-configs.sh and kafka-topics.sh in the bin/ directory. It’s important to keep this in mind as we progress through the following sections of configuring Amazon MSK, and configuring and verifying the Kafka consumer.
For your convenience, I’ve provided an AWS CloudFormation template for this setup in the Resources section at the end of this post.
Amazon MSK configuration
There is one broker configuration and one consumer configuration that we need to modify in order to allow consumers to fetch from the closest replica. These are client.rack on the consumers and replica.selector.class on the brokers.
As previously mentioned, Amazon MSK automatically sets a broker’s broker.rack setting according to Availability Zone. Because we’re using Amazon MSK in this example, this means the broker.rack configuration on each broker is already configured for us, but let’s verify that.
We can confirm the broker.rack setting in a few different ways. As one example, we can use the kafka-configs.sh script from my previously mentioned EC2 instance:
bin/kafka-configs.sh —-broker 1 —-all —-describe —-bootstrap-server $BOOTSTRAP | grep rack
Depending on our environment, we should receive something similar to the following result:
broker.rack=use1-az4 sensitive=false synonyms={STATIC_BROKER_CONFIG:broker.rack=use1-az4}
Note that BOOTSTRAP is just an environment variable set to my cluster’s bootstrap server connection string. I set it previously with export BOOTSTRAP=<cluster specific>;
For example: export BOOTSTRAP=”boot-xyo.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092,boot-9yg.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092,boot-eot.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092”
For more information on bootstrap servers, refer to Getting the bootstrap brokers for an Amazon MSK cluster.
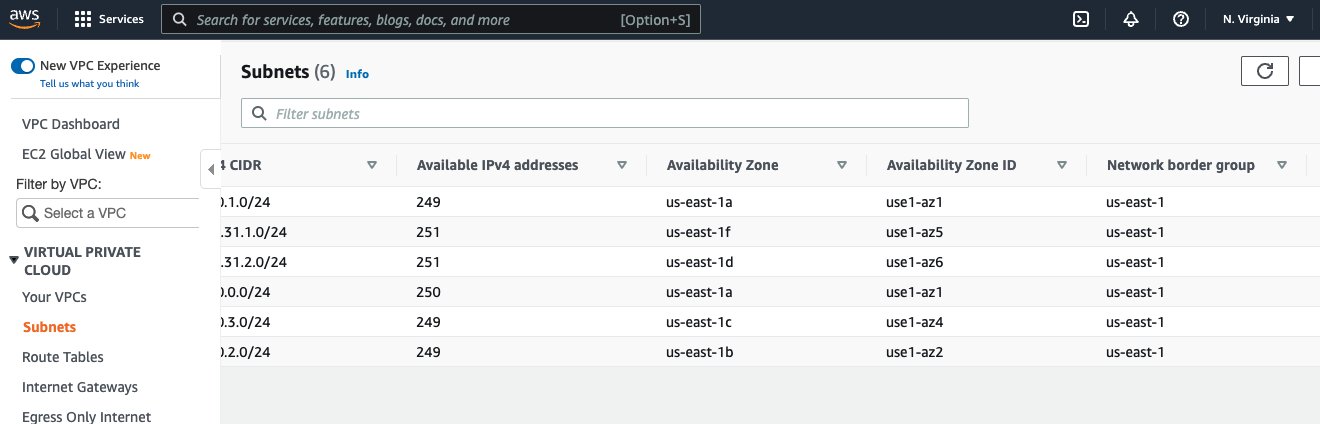
From the command results, we can see broker.rack is set to use1-az4 for broker 1. The value use1-az4 is determined from Availability Zone to Availability Zone ID mapping. You can view this mapping on the Amazon Virtual Private Cloud (Amazon VPC) console on the Subnets page, as shown in the following screenshot.

In the preceding screenshot, we can see the Availability Zone ID use1-az4. We note this value for later use in our consumer configuration changes.
The broker setting we need to set is replica.selector.class. In this case, the default value for the configuration in Amazon MSK is null. See the following code:
bin/kafka-configs.sh —broker 1 —all —describe —bootstrap-server $BOOTSTRAP | grep replica.selector
This results in the following:
replica.selector.class=null sensitive=false synonyms={}
That’s ok, because Amazon MSK allows replica.selector.class to be overridden. For more information, refer to Custom MSK configurations.
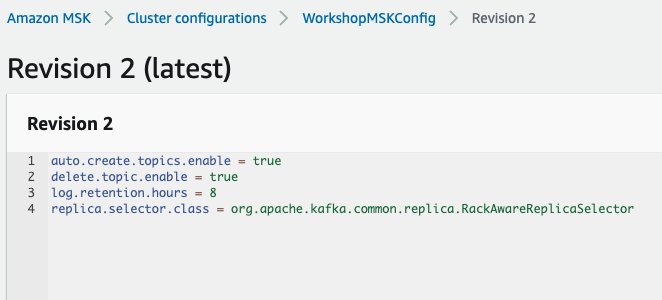
To override this setting, we need to associate a cluster configuration with this key set to org.apache.kafka.common.replica.RackAwareReplicaSelector. For example, I’ve updated and applied the configuration of the MSK cluster used in this post with the following:
auto.create.topics.enable = true
delete.topic.enable = true
log.retention.hours = 8
replica.selector.class = org.apache.kafka.common.replica.RackAwareReplicaSelector
The following screenshot shows the configuration.

To learn more about applying cluster configurations, see Amazon MSK configuration.
After updating the cluster’s configuration with this configuration, we can verify it’s active in the brokers with the following code:
bin/kafka-configs.sh —broker 1 —all —describe —bootstrap-server $BOOTSTRAP | grep replica.selector
We get the following results:
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector sensitive=false synonyms={STATIC_BROKER_CONFIG:replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector}
With these two broker settings in place, we’re ready to move on to the consumer configuration.
Kafka consumer configuration and verification
In this section, we cover an example of running a consumer that is rack aware vs. one that is not. We verify by examining log files in order to compare the results of different configuration settings.
To perform this comparison, let’s create a topic with six partitions and replication factor of 3:
bin/kafka-topics.sh --create --topic order --partitions 6 --replication-factor 3 --bootstrap-server $BOOTSTRAPbin/
A replication factor of 3 means the leader partition is in one Availability Zone, while the two replicas are distributed across each remaining Availability Zone. This provides a convenient setup to test and verify our consumer because the consumer is deployed in one of these Availability Zones. This allows us to test and confirm that the consumer never crosses Availability Zone boundaries to fetch because either the leader partition or replica copy is always available from the broker in the same Availability Zone as the consumer.
Let’s load sample data into the order topic using the MSK Data Generator with the following configuration:
{
"connector.class": "com.amazonaws.mskdatagen.GeneratorSourceConnector",
"tasks.max": "2",
"genv.order.product_id.with": "#{number.number_between '101','109'}",
"genv.order.quantity.with": "#{number.number_between '1','5'}",
"genkp.order.with": "#{Code.isbn10}",
"genv.order.customer_id.matching": "customer.key"
}
How to use the MSK Data Generator is beyond the scope of this post, but we generate sample data to the order topic with a random key (Internet.uuid) and key pair values of product_id, quantity, and customer_id. For our purposes, it’s important the generated key is random enough to ensure the data is evenly distributed across partitions.
To verify our consumer is reading from the closest replica, we need to turn up the logging. Because we’re using the bin/kafka-console-consumer.sh script included with Apache Kafka distribution, we can update the config/tools-log4j.properties file to influence the logging of scripts run in the bin/ directory, including kafka-console-consumer.sh. We just need to add one line:
log4j.logger.org.apache.kafka.clients.consumer.internals.AbstractFetch=DEBUG
Note: Kafka changed its logging structure with version 3.5.0, see KAFKA-14365, so with MSK clusters running version 3.4.0 or earlier, you’ll need to replace mentions of AbstractFetch with the Fetcher class.
So, for example: log4j.logger.org.apache.kafka.clients.consumer.internals.Fetcher=DEBUG
For MSK clusters running version 3.5.1 or newer, use the AbstractFetch class. The following code is the relevant portion from config/tools-log4j.properties file:
log4j.rootLogger=WARN, stderr
log4j.logger.org.apache.kafka.clients.consumer.internals.AbstractFetch=DEBUG
log4j.appender.stderr=org.apache.log4j.ConsoleAppender
log4j.appender.stderr.layout=org.apache.log4j.PatternLayout
log4j.appender.stderr.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.stderr.Target=System.err
Now we’re ready to test and verify from a consumer.
Let’s consume without rack awareness first:
bin/kafka-console-consumer.sh —topic order —bootstrap-server $BOOTSTRAP
We get results such as the following:
2025-03-24 19:46:13,988] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-75702] Added READ_UNCOMMITTED fetch request for partition order-5 at position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 3 rack: use1-az2)], epoch=0}} to node b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 3 rack: use1-az2) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 19:46:13,988] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-75702] Added READ_UNCOMMITTED fetch request for partition order-2 at position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 3 rack: use1-az2)], epoch=0}} to node b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 3 rack: use1-az2) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 19:46:13,988] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-75702] Sending READ_UNCOMMITTED IncrementalFetchRequest(toSend=(), toForget=(), toReplace=(),implied=(order-5, order-2), canUseTopicIds=True) to broker b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 3 rack: use1-az2) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 19:46:13,989] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-75702] Adding pending request for node b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 3 rack: use1-az2) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 19:46:14,480] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-75702] Removing pending request for node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 19:46:14,481] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-75702] Added READ_UNCOMMITTED fetch request for partition order-4 at position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6)], epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 19:46:14,482] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-75702] Added READ_UNCOMMITTED fetch request for partition order-1 at position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6)], epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 19:46:14,482] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-75702] Sending READ_UNCOMMITTED IncrementalFetchRequest(toSend=(), toForget=(), toReplace=(),implied=(order-4, order-1), canUseTopicIds=True) to broker b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 19:46:14,482] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-75702] Adding pending request for node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 19:46:14,488] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-75702] Removing pending request for node b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 1 rack: use1-az4) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 19:46:14,488] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-75702] Added READ_UNCOMMITTED fetch request for partition order-3 at position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 1 rack: use1-az4)], epoch=0}} to node b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 1 rack: use1-az4) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 19:46:14,489] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-75702] Added READ_UNCOMMITTED fetch request for partition order-0 at position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 1 rack: use1-az4)], epoch=0}} to node b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 1 rack: use1-az4) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
We get use1-az2, use1-az4, and use1-az1. This will vary for each cluster. This is expected because we’re generating data evenly across the order topic partitions and haven’t configured kafka-console-consumer.sh to fetch from followers yet.
Let’s stop this consumer and rerun it to fetch from the closest replica this time. The EC2 instance in this example is located in Availability Zone us-east-1a, which means the Availability Zone ID is use1-az1, as previously discussed. To set this in our consumer, we need to set the client.rack configuration property as shown when running the following command:
bin/kafka-console-consumer.sh --topic order --bootstrap-server $BOOTSTRAP --consumer-property client.rack=use1-az6
Now, the log results show a difference:
[2025-03-24 20:21:27,369] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-17382] Added READ_UNCOMMITTED fetch request for partition order-4 at position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6)], epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 20:21:27,369] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-17382] Added READ_UNCOMMITTED fetch request for partition order-5 at position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 3 rack: use1-az2)], epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 20:21:27,370] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-17382] Added READ_UNCOMMITTED fetch request for partition order-2 at position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 3 rack: use1-az2)], epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
[2025-03-24 20:21:27,370] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-17382] Added READ_UNCOMMITTED fetch request for partition order-3 at position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 1 rack: use1-az4)], epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
For each log line, we now have two rack: values. The first rack: value shows the current leader, the second rack: shows the rack that is being used to fetch messages.
For a specific example, consider the following line from the preceding example code:
[2025-03-24 20:21:27,370] DEBUG [Consumer clientId=console-consumer, groupId=console-consumer-17382] Added READ_UNCOMMITTED fetch request for partition order-3 at position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 1 rack: use1-az4)], epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
The leader is identified as rack: use1-az4, but the fetch request is sent to use1-az6 as indicated by to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9092 (id: 2 rack: use1-az6) (org.apache.kafka.clients.consumer.internals.AbstractFetch)
You’ll see something similar in all other log lines. The fetch is always to the broker in use1-az6.
And there we have it! We’re consuming from the closest replica.
Conclusion
With closest replica fetch, you can save as much as two-thirds of your cross-Availability Zone traffic charges when consuming from Kafka topics, because your consumers can read from replicas in the same Availability Zone instead of having to cross Availability Zone boundaries to read from the leader. In this post, we provided a background on Apache Kafka rack awareness and how Amazon MSK automatically sets brokers to be rack aware according to Availability Zone deployment. Then we demonstrated how to configure your MSK cluster and consumer clients to take advantage of rack awareness and avoid cross-Availability Zone network charges.
Resources
You can use the following CloudFormation template
to create the example MSK Express cluster and EC2 instance with Apache Kafka downloaded and extracted. Note that this template requires the described WorkshopMSKConfig custom MSK configuration to be pre-created before running the template.
About the author
 Todd McGrath is a data streaming specialist at Amazon Web Services where he advises customers on their streaming strategies, integration, architecture, and solutions. On the personal side, he enjoys watching and supporting his 3 teenagers in their preferred activities as well as following his own pursuits such as fishing, pickleball, ice hockey, and happy hour with friends and family on pontoon boats. Connect with him on LinkedIn.
Todd McGrath is a data streaming specialist at Amazon Web Services where he advises customers on their streaming strategies, integration, architecture, and solutions. On the personal side, he enjoys watching and supporting his 3 teenagers in their preferred activities as well as following his own pursuits such as fishing, pickleball, ice hockey, and happy hour with friends and family on pontoon boats. Connect with him on LinkedIn.
 Austin Groeneveld is a Streaming Specialist Solutions Architect at Amazon Web Services (AWS), based in the San Francisco Bay Area. In this role, Austin is passionate about helping customers accelerate insights from their data using the AWS platform. He is particularly fascinated by the growing role that data streaming plays in driving innovation in the data analytics space. Outside of his work at AWS, Austin enjoys watching and playing soccer, traveling, and spending quality time with his family.
Austin Groeneveld is a Streaming Specialist Solutions Architect at Amazon Web Services (AWS), based in the San Francisco Bay Area. In this role, Austin is passionate about helping customers accelerate insights from their data using the AWS platform. He is particularly fascinated by the growing role that data streaming plays in driving innovation in the data analytics space. Outside of his work at AWS, Austin enjoys watching and playing soccer, traveling, and spending quality time with his family.
Audit History
Last reviewed and updated in May 2025 by Austin Groeneveld| Streaming Specialist Solutions Architect