AWS Big Data Blog
Retain more for less with tiered storage for Amazon MSK
Organizations are adopting Apache Kafka and Amazon Managed Streaming for Apache Kafka (Amazon MSK) to capture and analyze data in real-time. Amazon MSK allows you to build and run production applications on Apache Kafka without needing Kafka infrastructure management expertise or having to deal with the complex overheads associated with running Apache Kafka on your own. With increasing maturity, customers seek to build sophisticated use cases that combine aspects of real time and batch processing. For instance, you may want to train machine learning (ML) models based on historic data and then use these models to do real time inferencing. Or you may want to be able to recompute previous results when the application logic changed, e.g., when a new KPI is added to a streaming analytics application or when a bug was fixed that caused incorrect output. These use cases often require storing data for several weeks, months, or even years.
Apache Kafka is well positioned to support these kind of use cases. Data is retained in the Kafka cluster as long as required by configuring the retention policy. In this way, the most recent data can be processed in real time for low-latency use cases while historic data remains accessible in the cluster and can be processed in a batch fashion.
However, retaining data in a Kafka cluster can become expensive because storage and compute are tightly coupled in a cluster. To scale storage, you need to add more brokers. But adding more brokers with the sole purpose of increasing the storage squanders the rest of the compute resources like CPU and memory. Also, a large cluster with more nodes adds operational complexity with a longer time to recover and rebalance when a broker fails. To avoid that operational complexity and higher cost, you can move your data to Amazon Simple Storage Service (Amazon S3) for long-term access and with cost-effective storage classes in Amazon S3 you can optimize your overall storage cost. This solves cost challenges, but now you have to build and maintain that part of the architecture for data movement to a different data store. You also need to build different data processing logic using different APIs for consuming data (Kafka API for streaming, Amazon S3 API for historic reads).
Today, we’re announcing Amazon MSK tiered storage, which brings a virtually unlimited and low-cost storage tier for Amazon MSK, making it simpler and cost-effective for developers to build streaming data applications. Since the launch of Amazon MSK in 2019, we have enabled capabilities such as vertical scaling and automatic scaling of broker storage so you can operate your Kafka workloads in a cost-effective way. Earlier this year, we launched provisioned throughput which enables seamlessly scaling I/O without having to provision additional brokers. Tiered storage makes it even more cost-effective for you to run Kafka workloads. You can now store data in Apache Kafka without worrying about limits. You can effectively balance your performance and costs by using the performance-optimized primary storage for real-time data and the new low-cost tier for the historical data. With a few clicks, you can move streaming data into a lower-cost tier to store data and only pay for what you use.
Tiered storage frees you from making hard trade-offs between supporting the data retention needs of your application teams and the operational complexity that comes with it. This enables you to use the same code to process both real-time and historical data to minimize redundant workflows and simplify architectures. With Amazon MSK tiered storage, you can implement a Kappa architecture – a streaming-first software architecture deployment pattern – to use the same data processing pipeline for correctness and completeness of data over a much longer time horizon for business analysis.
How Amazon MSK tiered storage works
Let’s look at how tiered storage works for Amazon MSK. Apache Kafka stores data in files called log segments. As each segment completes, based on the segment size configured at cluster or topic level, it’s copied to the low-cost storage tier. Data is held in performance-optimized storage for a specified retention time, or up to a specified size, and then deleted. There is a separate time and size limit setting for the low-cost storage, which must be longer than the performance-optimized storage tier. If clients request data from segments stored in the low-cost tier, the broker reads the data from it and serves the data in the same way as if it were being served from the performance-optimized storage. The APIs and existing clients work with minimal changes. When your application starts reading data from the low-cost tier, you can expect an increase in read latency for the first few bytes. As you start reading the remaining data sequentially from the low-cost tier, you can expect latencies that are similar to the primary storage tier. With tiered storage, you pay for the amount of data you store and the amount of data you retrieve.
For a pricing example, let’s consider a workload where your ingestion rate is 15 MB/s, with a replication factor of 3, and you want to retain data in your Kafka cluster for 7 days. For such a workload, it requires 6x m5.large brokers, with 32.4 TB EBS storage, which costs $4,755. But if you use tiered storage for the same workload with local retention of 4 hours and overall data retention of 7 days, it requires 3x m5.large brokers, with 0.8 TB EBS storage and 9 TB of tiered storage, which costs $1,584. If you want to read all the historic data at once, it costs $13 ($0.0015 per GB retrieval cost). In this example with tiered storage, you save around 66% of your overall cost.
Get started using Amazon MSK tiered storage
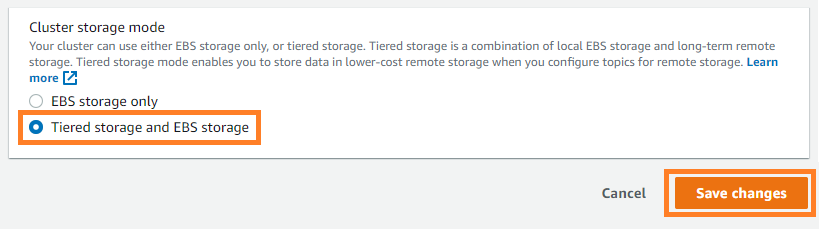
To enable tiered storage on your existing cluster, upgrade your MSK cluster to Kafka version 2.8.2.tiered and then choose Tiered storage and EBS storage as your cluster storage mode on the Amazon MSK console.

After tiered storage is enabled on the cluster level, run the following command to enable tiered storage on an existing topic. In this example, you’re enabling tiered storage on a topic called msk-ts-topic with 7 days’ retention (local.retention.ms=604800000) for a local high-performance storage tier, setting 180 days’ retention (retention.ms=15550000000) to retain the data in the low-cost storage tier, and updating the log segment size to 48 MB:
Availability and pricing
Amazon MSK tiered storage is available in all AWS regions where Amazon MSK is available excluding the AWS China, AWS GovCloud regions. This low-cost storage tier scales to virtually unlimited storage and requires no upfront provisioning. You pay only for the volume of data retained and retrieved in the low-cost tier.
For more information about this feature and its pricing, see the Amazon MSK developer guide and Amazon MSK pricing page. For finding the right sizing for your cluster, see the best practices page.
Summary
With Amazon MSK tiered storage you don’t need to provision storage for the low-cost tier or manage the infrastructure. Tiered storage enables you to scale to virtually unlimited storage. You can access data in the low-cost tier using the same clients you currently use to read data from the high-performance primary storage tier. Apache Kafka’s consumer API, streams API, and connectors consume data from both tiers without changes. You can modify the retention limits on the low-cost storage tier similarly as to how you can modify the retention limits on the high-performance storage.
Enable tiered storage on your MSK clusters today to retain data longer at a lower cost.
About the Author
 Masudur Rahaman Sayem is a Streaming Architect at AWS. He works with AWS customers globally to design and build data streaming architecture to solve real-world business problems. He is passionate about distributed systems. He also likes to read, especially classic comic books.
Masudur Rahaman Sayem is a Streaming Architect at AWS. He works with AWS customers globally to design and build data streaming architecture to solve real-world business problems. He is passionate about distributed systems. He also likes to read, especially classic comic books.