AWS Partner Network (APN) Blog
Optimize the Cost of Running DataRobot Models by Deploying and Monitoring on AWS Serverless
By Meenakshisundaram Thandavarayan, Sr. Partner Solutions Architect – AWS
By John Forrest, VP Product Architecture – DataRobot
 |
| DataRobot |
 |
Value realization from machine learning (ML) is achieved by generating predictions from the model in a production environment. Integration of the candidate model into production depends on the inference requirements, such as Batch inference, real-time inference, or edge inference.
Operationalizing ML models continues to be a challenge, however, due to lack of established ML architecture and its integration with the existing landscape. In addition, operationalizing ML models expands beyond just deploying them in a production environment to the management, monitoring, and retraining of the models.
DataRobot integrates with Amazon Web Services (AWS) and provides the flexibility for a model trained in DataRobot to be deployed on AWS services with centralized model governance, management, and monitoring.
In this post, we share how the models developed in DataRobot are deployed on AWS services (both server-based and serverless) and centrally monitored within DataRobot MLOps Server.
The DataRobot AutoML platform orchestrates the complete model development and training lifecycle, including auto feature engineering, auto model selection, and model ranking based on target metrics. Meanwhile, AWS has created a suite of compute capabilities that provide the ability to deploy ML models quickly.
Together, DataRobot and AWS allow machine learning engineers to:
- Deploy models for Batch transformation and real-time artificial intelligence (AI).
- Use server and serverless deployments for ML models.
- Build custom functionality on top of the ML model.
- Use CPUs/GPUs based on model and data requirements.
- Auto scale inference infrastructure on demand.
- Centralize model monitoring, governance, and operations.
- Reduce cost of inference; low-latency scoring without the overhead of API calls.
DataRobot is an AWS Machine Learning Competency Partner that helps data scientists and ML practitioners quickly and effortlessly prepare their data for building, training, and tuning models through an interactive, visual, and intelligent data preparation experience at scale.
DataRobot was named a Visionary in both the Gartner 2021 Magic Quadrant for Data Science and Machine Learning Platforms and the Forrester New Wave.
Solution Architecture
The diagram in Figure 1 below illustrates how DataRobot works with AWS, while the following list describes the different components of the solution. For this post, we’ll consider this a single account deployment architecture.
- DataRobot Platform components:
- Application server providing the AutoML user interface.
- Modeling workers and auto scaling Amazon Elastic Compute Cloud (Amazon EC2) instances for model training.
- AI Catalog, a metadata repository for data and models.
- MLOps server for model governance and monitoring models in production.
- AWS Glue as a metastore and Amazon Athena for SQL queries, against an Amazon Simple Storage Service (Amazon S3) data lake.
- Serverless services for ML model deployments that include AWS Lambda and AWS Fargate on Amazon Elastic Container Service (Amazon ECS) and Amazon Elastic Kubernetes Service (Amazon EKS).
- Server-based services for ML model deployments including Amazon EC2 and Amazon SageMaker.
- Batch AI deployment capabilities including Amazon Redshift and Amazon EMR.
- Amazon Elastic Container Registry (Amazon ECR) for storing portable prediction server images.
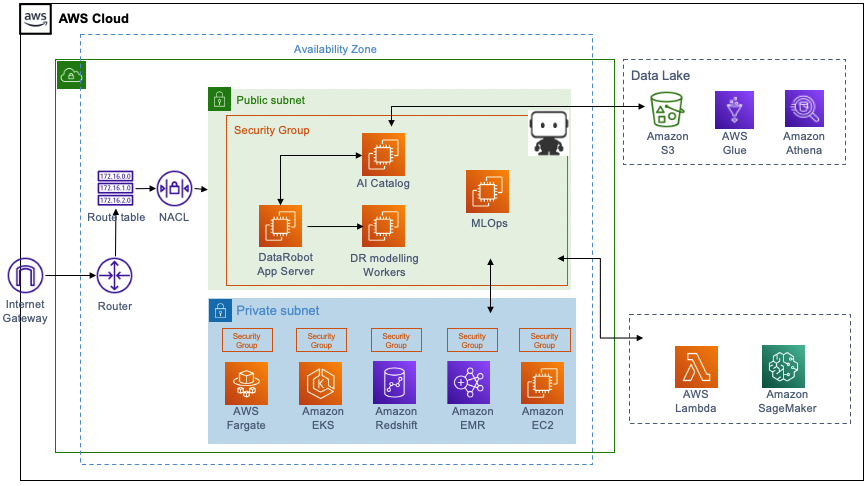
Figure 1 – DataRobot on AWS.
Use Case: Predict Survival on the Titanic
Let’s look at an example to see how you can use AWS and DataRobot to empower your data science and ML engineering teams.
We’ll use an iconic Titanic survival use case where the business goal is to predict which people were more likely to survive. The purpose of taking a simple use case is to focus on model deployment and monitoring and less on feature engineering and model development.

Figure 2 – Machine learning life cycle.
In this example, we’ll use DataRobot’s platform to prepare the dataset, train the model, and evaluate the model. However, the primary focus of the discussion is how to deploy the model on AWS services for different business needs.
To follow along with this example and try out DataRobot and Amazon SageMaker capabilities foryourself, we invite you to download the dataset.
Model Development
In this example, we limit data collection and integration steps to loading the dataset to an Amazon S3 bucket within your AWS account. The dataset needs to be registered with DataRobot’s AI Catalog, which is a metadata repository for use in data preparation and model training.
Use DataRobot’s Data Preparation tool to perform the data engineering tasks of removing columns that add little to no value for ML, encoding categorical columns, and scaling data. After the data is engineered, export it back to the AI Catalog as a prepared dataset and save the data in an S3 bucket.
Model engineering includes feature engineering, model selection, model tuning, and model training. DataRobot analyzes the characteristics of the training data and selected prediction target, and then selects the appropriate ML algorithms to apply.
To initiate AutoML, select the prediction target (in this case, the “Survived” column), optimization metric, and modeling mode as “Quick” Autopilot. AutoML optimizes the input data and features automatically for each algorithm, performing operations like one-hot encoding, missing value imputation, text mining, and standardization to transform features for more efficient results.
The modelling stage of AutoML supports popular advanced machine learning techniques and open-source tools such as Apache Spark, H2O, Scala, Python, R, TensorFlow, Facebook Prophet, Keras, DeepAR, Eureqa, LightGBM, and XGBoost.
You can use DataRobot’s Explainable AI module to evaluate each model on Lift Chart, ROC Curve, and Confusion Matrix to select the candidate model. This includes visual insights and automated model documentation with blueprints describing the modeling process and the algorithms used.
The output of the modelling stage is a leaderboard of models ranked based on the optimization metric. Review the leaderboard and select the model to deploy for inference prediction.
Model Deployment and Model Monitoring
DataRobot integration with AWS provides DataRobot models for deployment to multiple AWS services:
- Serverless deployments on AWS Lambda.
- Container-based deployments on Amazon EKS.
- Deployment on Spark clusters and Amazon EMR.
- Deployment on Amazon SageMaker.
- Batch AI deployments on Amazon Redshift.
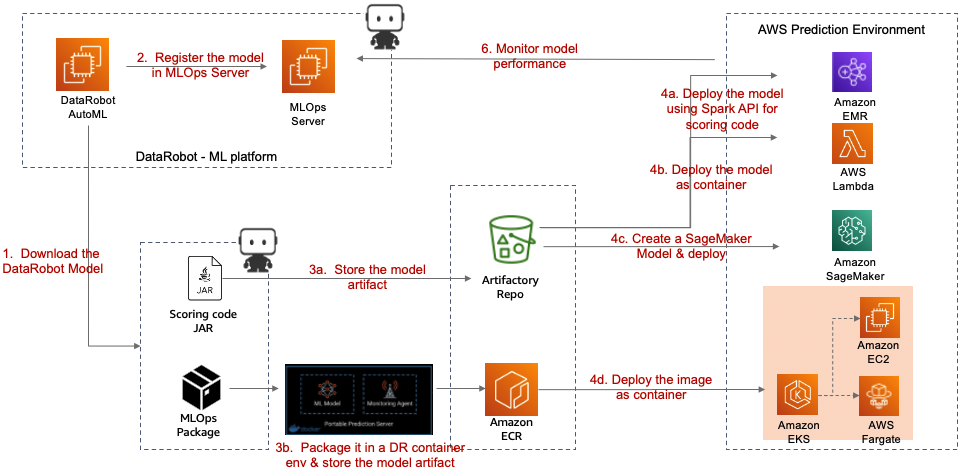
Figure 3 – Model deployment patterns.
A DataRobot model deployed on AWS services can be either a Docker container or a model exported as a scoring code JAR file. We will discuss in more detail the scoring code JAR file.
The flexibility to deploy models in an environment external to DataRobot can present challenges to monitoring model behavior, health, and performance for model decay and retraining. A DataRobot MLOps Agent deployed alongside the model helps address the model monitoring requirement.

Figure 4 – Externally deployed DataRobot model types.
In this case, we deploy the model selected as the candidate model in a serverless environment, AWS Lambda, as well as address model monitoring using Lambda.
Lambda is a serverless compute service that lets you run code without provisioning or managing servers, creating workload-aware cluster scaling logic, maintaining event integrations, or managing runtimes.
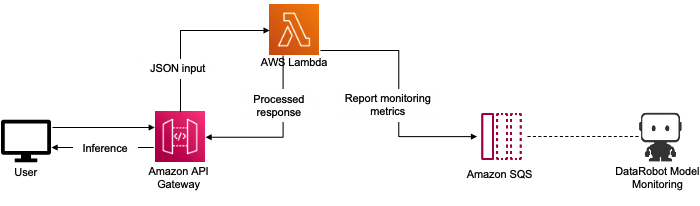
Figure 5 – DataRobot model deployed on AWS Lambda.
Using a serverless environment for model deployment and monitoring has multiple advantages:
- Adding custom functionality on top of the DataRobot model.
- Reducing cost, as inference end points are on demand.
- Using both Batch and real-time AI processing due to the ease of integration with AWS services.
To deploy the DataRobot model to the Lambda function, download the model and wrap it into a function deployable to Lambda. For detailed instructions on how to do this, see Using Scoring Code Models with AWS Lambda.
A brief summary of the instructions is as follows:
- Download the DataRobot model as a compiled Java executable. This dependency-free JAR file is now independent of the DataRobot application. Scoring Code JAR pre-packages the MLOps monitoring agent for model monitoring.
- Wrap the downloaded model for prediction. There are a few ways to create a wrapper. You can create your own project or use the example from DataRobot on GitHub. Compile the model using Maven to create a model JAR file, and then store the model JAR file in an S3 bucket.
The model is now ready to be deployed as a Lambda function. Create a Lambda function (Java 8 or Java 11), upload the compiled model JAR file, and specify the Lambda handler to be invoked in real time or batch mode.
Register the model in the DataRobot’s MLOps server to enable centralized monitoring of the health and performance of the model. The MLOps agent packaged with the Scoring Code JAR file captures information and sends it to a centralized MLOps server, making it easier to detect and diagnose issues occurring in the production model.
For detailed instructions on setting up Lambda for monitoring, see AWS Lambda Serverless Reporting Actuals to DataRobot MLOps.
Conclusion
In this post, you learned how to operationalize a DataRobot model on AWS Lambda and monitor the model for its performance. Deploying the model on AWS facilitates integration with the existing landscape, building collaboration across the data science and ML engineering communities in delivering cross-company AI projects and initiatives.
To learn more about deploying DataRobot models on other AWS compute services, see the following resources:
- Deploying DataRobot models on Containers services (Amazon EKS)
- Deploying DataRobot models on Spark Cluster (Amazon EMR)
- Deploying DataRobot models on Amazon SageMaker
To get started with DataRobot on AWS, use AWS Quick Starts or AWS Marketplace.
.

.
DataRobot – AWS Partner Spotlight
DataRobot is an AWS Machine Learning Competency Partner that helps data scientists and ML practitioners prepare their data for building, training, and tuning models through an interactive, visual, and intelligent data preparation experience at scale.
Contact DataRobot | Partner Overview | AWS Marketplace
*Already worked with DataRobot? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.