AWS Architecture Blog
Category: Database

Top Architecture Blog Posts of 2024
Well, it’s been another historic year! We’ve watched in awe as the use of real-world generative AI has changed the tech landscape, and while we at the Architecture Blog happily participated, we also made every effort to stay true to our channel’s original scope, and your readership this last year has proven that decision was […]

Let’s Architect! Serverless developer experience in AWS
Accelerate your serverless feedback loop with game-changing AWS developer tools: generate tests with AI, visualize DynamoDB schemas locally, optimize Lambda memory, and more—all within a streamlined local IDE experience.
Let’s Architect! Modern data architectures
Data is the fuel for AI; modern data is even more important for generative AI and advanced data analytics, producing more accurate, relevant, and impactful results. Modern data comes in various forms: real-time, unstructured, or user-generated. Each form requires a different solution. AWS’s data journey began with Amazon Simple Storage Service (Amazon S3) in 2006, […]

How Wesfarmers Health implemented upstream event buffering using Amazon SQS FIFO
Customers of all sizes and industries use Software-as-a-Service (SaaS) applications to host their workloads. Most SaaS solutions take care of maintenance and upgrades of the application for you, and get you up and running in a relatively short timeframe. Why spend time, money, and your precious resources to build and maintain applications when this could […]

Tenant portability: Move tenants across tiers in a SaaS application
In today’s fast-paced software as a service (SaaS) landscape, tenant portability is a critical capability for SaaS providers seeking to stay competitive. By enabling seamless movement between tiers, tenant portability allows businesses to adapt to changing needs. However, manual orchestration of portability requests can be a significant bottleneck, hindering scalability and requiring substantial resources. As […]
Let’s Architect! Migrating to the cloud with AWS
In today’s digital world, businesses are increasingly turning to the cloud for its scalability, agility, and cost-effectiveness. Migrating your data center to the cloud can be a daunting task, but with the right approach and tools, it can be a successful journey. This Let’s Architect! blog post will guide you through the process of migrating […]

London Stock Exchange Group uses chaos engineering on AWS to improve resilience
This post was co-written with Luke Sudgen, Lead DevOps Engineer Post Trade, and Padraig Murphy, Solutions Architect Post Trade, from London Stock Exchange Group. In this post, we’ll discuss some failure scenarios that were tested by London Stock Exchange Group (LSEG) Post Trade Technology teams during a chaos engineering event supported by AWS. Chaos engineering […]
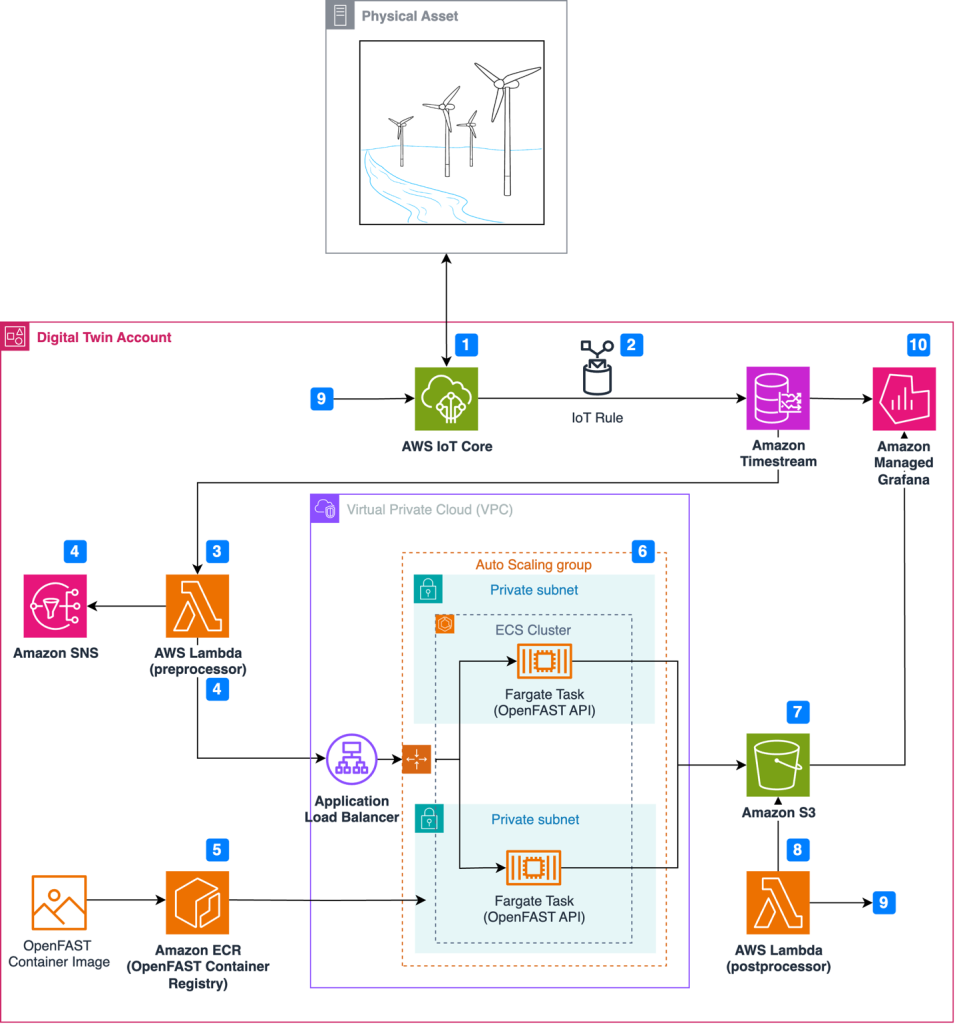
Physics on AWS: Optimizing wind turbine performance using OpenFAST in a digital twin
Wind energy plays a crucial role in global decarbonization efforts by generating emission-free power from an abundant resource. In 2022, wind energy produced 2100 terawatt-hours (TWh) globally, or over 7% of global electricity, with expectations to reach 7400 TWh by 2030. Despite its potential, several challenges must be addressed to help meet grid decarbonization targets. […]

Top Architecture Blog Posts of 2023
2023 was a rollercoaster year in tech, and we at the AWS Architecture Blog feel so fortunate to have shared in the excitement. As we move into 2024 and all of the new technologies we could see, we want to take a moment to highlight the brightest stars from 2023. As always, thanks to our […]

Converting stateful application to stateless using AWS services
Designing a system to be either stateful or stateless is an important choice with tradeoffs regarding its performance and scalability. In a stateful system, data from one session is carried over to the next. A stateless system doesn’t preserve data between sessions and depends on external entities such as databases or cache to manage state. […]