AWS Big Data Blog
Category: Analytics
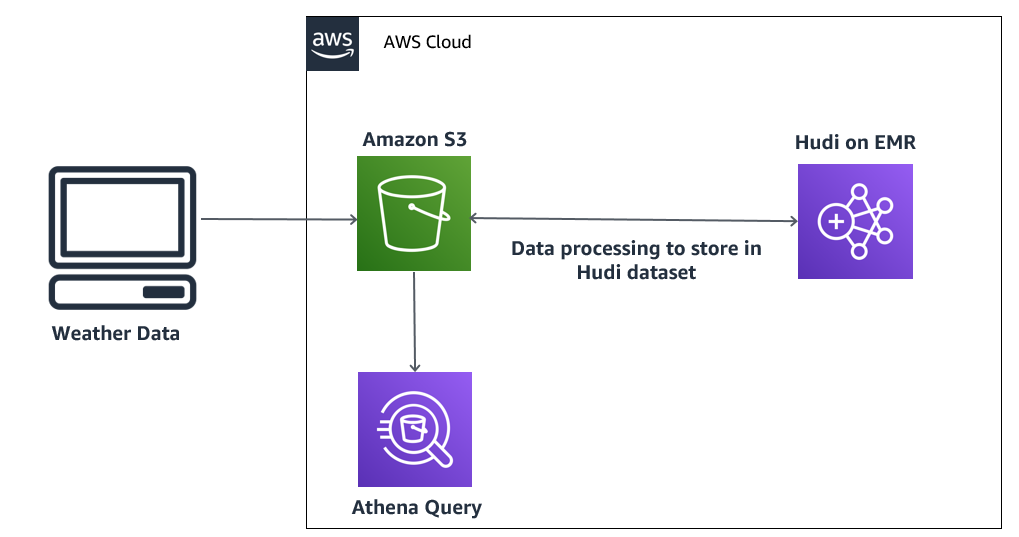
Query an Apache Hudi dataset in an Amazon S3 data lake with Amazon Athena part 1: Read-optimized queries
July 2023: This post was reviewed for accuracy. On July 16, 2021, Amazon Athena upgraded its Apache Hudi integration with new features and support for Hudi’s latest 0.8.0 release. Hudi is an open-source storage management framework that provides incremental data processing primitives for Hadoop-compatible data lakes. This upgraded integration adds the latest community improvements to […]
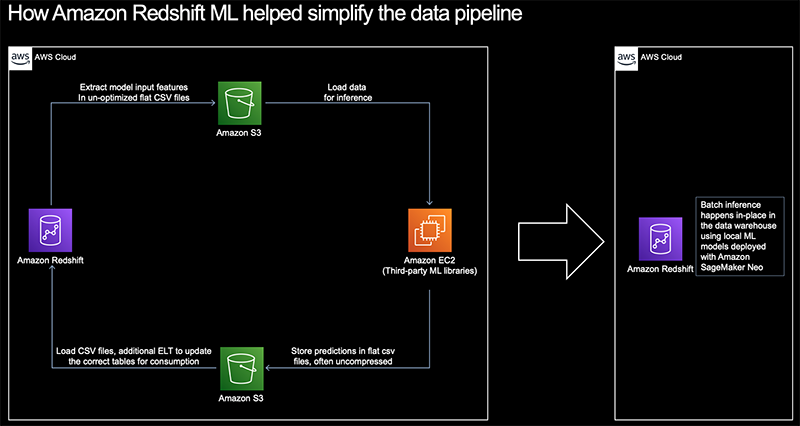
How Jobcase is using Amazon Redshift ML to recommend job search content at scale
This post is co-written with Clay Martin and Ajay Joshi from Jobcase as the lead authors. Jobcase is an online community dedicated to empowering and advocating for the world’s workers. We’re the third-largest destination for job search in the United States, and connect millions of Jobcasers to relevant job opportunities, companies, and other resources on […]

Query Snowflake using Athena Federated Query and join with data in your Amazon S3 data lake
This post was last reviewed and updated July, 2022 with updates in Athena federation connector. If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use Snowflake as your data warehouse solution, you may need to join your data in your data lake with Snowflake. For example, you may want to build […]

Build a serverless event-driven workflow with AWS Glue and Amazon EventBridge
April 2025: This post was reviewed for accuracy. Customers are adopting event-driven-architectures to improve the agility and resiliency of their applications. As a result, data engineers are increasingly looking for simple-to-use yet powerful and feature-rich data processing tools to build pipelines that enrich data, move data in and out of their data lake and data […]
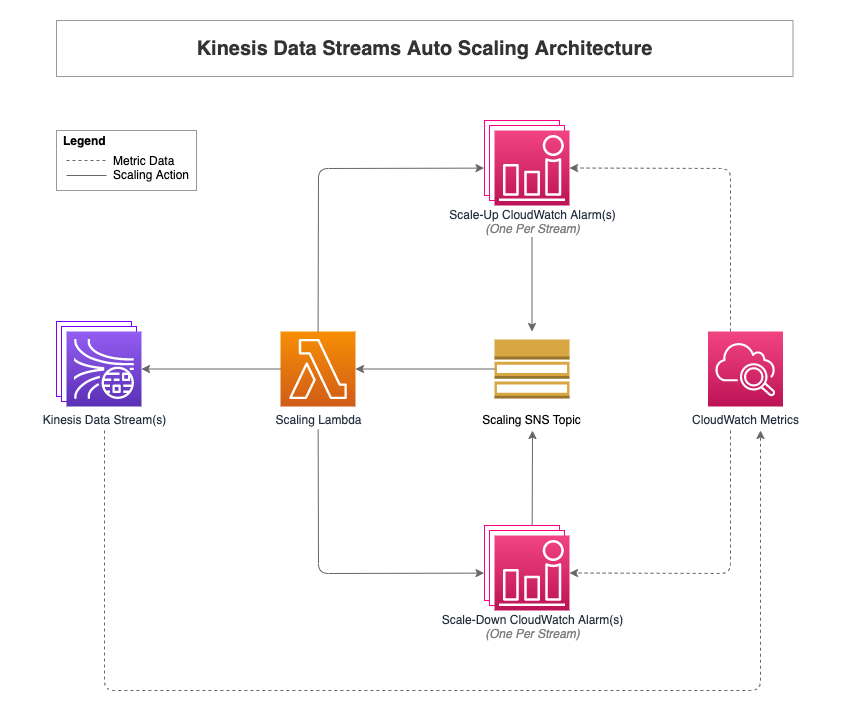
Auto scaling Amazon Kinesis Data Streams using Amazon CloudWatch and AWS Lambda
This post is co-written with Noah Mundahl, Director of Public Cloud Engineering at United Health Group. Update (12/1/2021): Amazon Kinesis Data Streams On-Demand mode is now the recommended way to natively auto scale your Amazon Kinesis Data Streams. In this post, we cover a solution to add auto scaling to Amazon Kinesis Data Streams. Whether […]
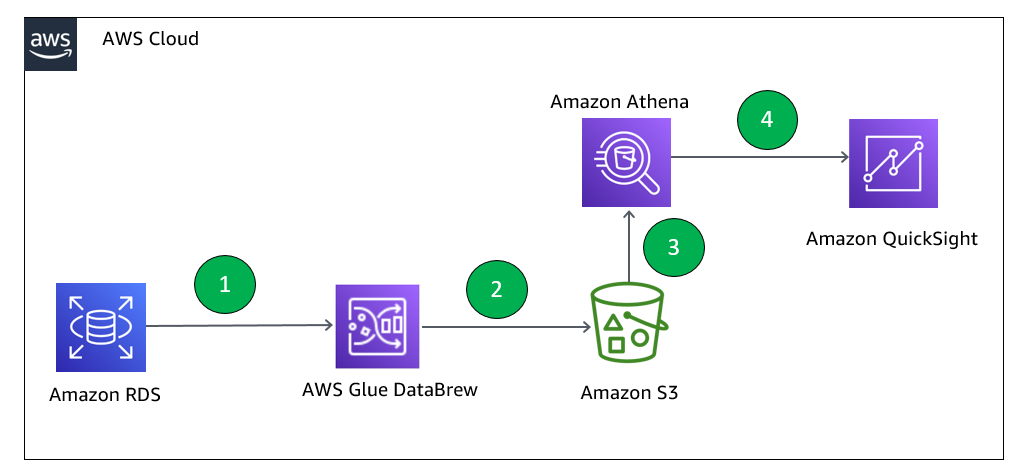
Data preparation using an Amazon RDS for MySQL database with AWS Glue DataBrew
With AWS Glue DataBrew, data analysts and data scientists can easily access and visually explore any amount of data across their organization directly from their Amazon Simple Storage Service (Amazon S3) data lake, Amazon Redshift data warehouse, or Amazon Aurora and Amazon Relational Database Service (Amazon RDS) databases. You can choose from over 250 built-in […]

Incremental data matching using AWS Lake Formation and AWS Glue
AWS Lake Formation provides a machine learning (ML) capability (FindMatches transform) to identify duplicate or matching records in your dataset, even when the records don’t have a common unique identifier and no fields match exactly. Customers across many industries have come to rely on this feature for linking datasets like patient records, customer databases, and […]

Query your Oracle database using Athena Federated Query and join with data in your Amazon S3 data lake
This post was last reviewed and updated July, 2022 with updates in Athena federation connector. If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use Oracle as your transactional data store, you may need to join the data in your data lake with Oracle on Amazon Relational Database Service (Amazon RDS), Oracle running on Amazon […]

Enable federation to multiple Amazon QuickSight accounts with Microsoft Azure Active Directory
Amazon QuickSight is a scalable, serverless, embeddable, machine learning (ML)-powered business intelligence (BI) service built for the cloud that supports identity federation in both Standard and Enterprise editions. Organizations are working towards centralizing their identity and access strategy across all of their applications, including on-premises, third-party, and applications on AWS. Many organizations use Microsoft Azure […]

Create a secure data lake by masking, encrypting data, and enabling fine-grained access with AWS Lake Formation
You can build data lakes with millions of objects on Amazon Simple Storage Service (Amazon S3) and use AWS native analytics and machine learning (ML) services to process, analyze, and extract business insights. You can use a combination of our purpose-built databases and analytics services like Amazon EMR, Amazon OpenSearch Service, and Amazon Redshift as […]