AWS Big Data Blog
Category: Amazon Simple Storage Service (S3)

Securely share your data across AWS accounts using AWS Lake Formation
Data lakes have become very popular with organizations that want a centralized repository that allows you to store all your structured data and unstructured data at any scale. Because data is stored as is, there is no need to convert it to a predefined schema in advance. When you have new business use cases, you […]

Backtest trading strategies with Amazon Kinesis Data Streams long-term retention and Amazon SageMaker
July 2023: This post was reviewed for accuracy. Real-time insight is critical when it comes to building trading strategies. Any delay in data insight can cost lot of money to the traders. Often, you need to look at historical market trends to predict future trading pattern and make the right bid. More the historical data […]

Enforce customized data quality rules in AWS Glue DataBrew
GIGO (garbage in, garbage out) is a concept common to computer science and mathematics: the quality of the output is determined by the quality of the input. In modern data architecture, you bring data from different data sources, which creates challenges around volume, velocity, and veracity. You might write unit tests for applications, but it’s […]
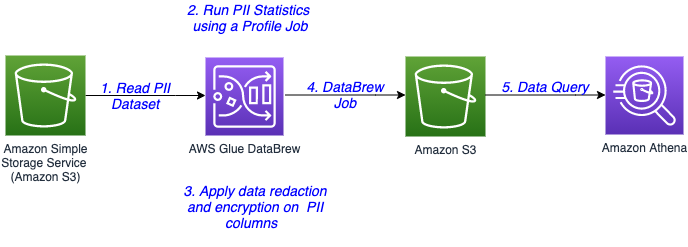
Introducing PII data identification and handling using AWS Glue DataBrew
AWS Glue DataBrew, a visual data preparation tool, now allows users to identify and handle sensitive data by applying advanced transformations like redaction, replacement, encryption, and decryption on their personally identifiable information (PII) data, and other types of data they deem sensitive. With exponential growth of data, companies are handling huge volumes and a wide […]
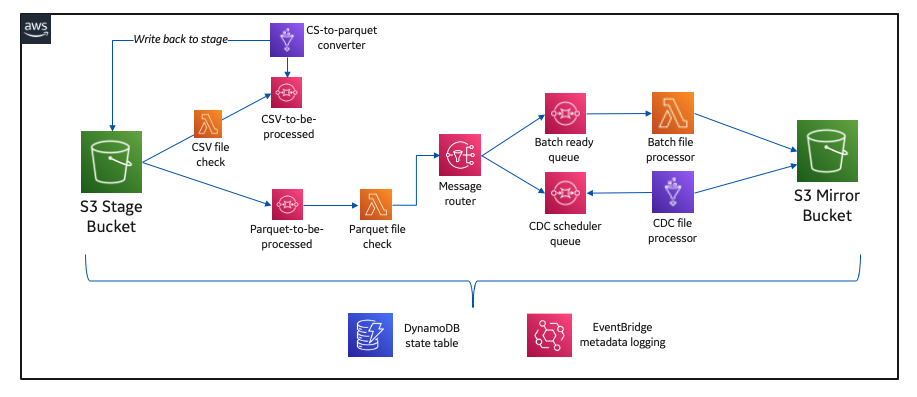
How GE Aviation built cloud-native data pipelines at enterprise scale using the AWS platform
This post was co-written with Alcuin Weidus, Principal Architect from GE Aviation. GE Aviation, an operating unit of GE, is a world-leading provider of jet and turboprop engines, as well as integrated systems for commercial, military, business, and general aviation aircraft. GE Aviation has a global service network to support these offerings. From the turbosupercharger […]

Create a serverless event-driven workflow to ingest and process Microsoft data with AWS Glue and Amazon EventBridge
Microsoft SharePoint is a document management system for storing files, organizing documents, and sharing and editing documents in collaboration with others. Your organization may want to ingest SharePoint data into your data lake, combine the SharePoint data with other data that’s available in the data lake, and use it for reporting and analytics purposes. AWS […]

Copy large datasets from Google Cloud Storage to Amazon S3 using Amazon EMR
Data migration between GCS and Amazon S3 is possible by utilizing Hadoop’s native support for S3 object storage and using a Google-provided Hadoop connector for GCS. This post demonstrates how to configure an EMR cluster for DistCp and S3DistCP, goes over the settings and parameters for both tools, performs a copy of a test 9.4 TB dataset, and compares the performance of the copy.
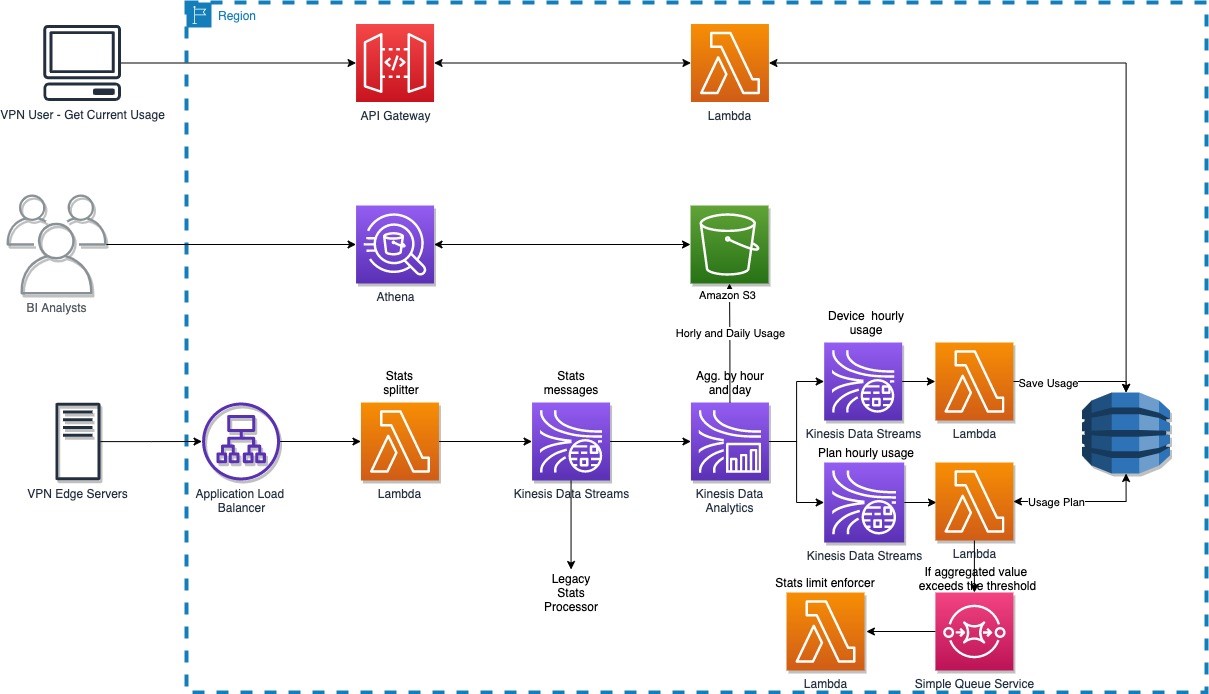
How NortonLifelock built a serverless architecture for real-time analysis of their VPN usage metrics
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This post presents a reference architecture and optimization strategies for building serverless data analytics solutions on AWS using Amazon Kinesis Data Analytics. In addition, this post shows […]

Integral Ad Science secures self-service data lake using AWS Lake Formation
This post is co-written with Mat Sharpe, Technical Lead, AWS & Systems Engineering from Integral Ad Science. Integral Ad Science (IAS) is a global leader in digital media quality. The company’s mission is to be the global benchmark for trust and transparency in digital media quality for the world’s leading brands, publishers, and platforms. IAS […]

Create a custom Amazon S3 Storage Lens metrics dashboard using Amazon QuickSight
Companies use Amazon Simple Storage Service (Amazon S3) for its flexibility, durability, scalability, and ability to perform many things besides storing data. This has led to an exponential rise in the usage of S3 buckets across numerous AWS Regions, across tens or even hundreds of AWS accounts. To optimize costs and analyze security posture, Amazon […]