AWS Big Data Blog
How GE Aviation built cloud-native data pipelines at enterprise scale using the AWS platform
This post was co-written with Alcuin Weidus, Principal Architect from GE Aviation.
GE Aviation, an operating unit of GE, is a world-leading provider of jet and turboprop engines, as well as integrated systems for commercial, military, business, and general aviation aircraft. GE Aviation has a global service network to support these offerings.
From the turbosupercharger to the world’s most powerful commercial jet engine, GE’s history of powering the world’s aircraft features more than 90 years of innovation.
In this post, we share how GE Aviation built cloud-native data pipelines at enterprise scale using the AWS platform.
A focus on the foundation
At GE Aviation, we’ve been invested in the data space for many years. Witnessing the customer value and business insights that could be extracted from data at scale has propelled us forward. We’re always looking for new ways to evolve, grow, and modernize our data and analytics stack. In 2019, this meant moving from a traditional on-premises data footprint (with some specialized AWS use cases) to a fully AWS Cloud-native design. We understood the task was challenging, but we were committed to its success. We saw the tremendous potential in AWS, and were eager to partner closely with a company that has over a decade of cloud experience.
Our goal from the outset was clear: build an enterprise-scale data platform to accelerate and connect the business. Using the best of cloud technology would set us up to deliver on our goal and prioritize performance and reliability in the process. From an early point in the build, we knew that if we wanted to achieve true scale, we had to start with solid foundations. This meant first focusing on our data pipelines and storage layer, which serve as the ingest point for hundreds of source systems. Our team chose Amazon Simple Storage Service (Amazon S3) as our foundational data lake storage platform.
Amazon S3 was the first choice as it provides an optimal foundation for a data lake store delivering virtually unlimited scalability and 11 9s of durability. In addition to its scalable performance, it has ease-of-use features, native encryption, and access control capabilities. Equally important, Amazon S3 integrates with a broad portfolio of AWS services, such as Amazon Athena, the AWS Glue Data Catalog, AWS Glue ETL (extract, transform, and load) Amazon Redshift, Amazon Redshift Spectrum, and many third-party tools, providing a growing ecosystem of data management tools.
How we started
The journey started with an internal hackathon that brought cross-functional team members together. We organized around an initial design and established an architecture to start the build using serverless patterns. A combination of Amazon S3, AWS Glue ETL, and the Data Catalog were central to our solution. These three services in particular aligned to our broader strategy to be serverless wherever possible and build on top of AWS services that were experiencing heavy innovation in the way of new features.
We felt good about our approach and promptly got to work.
Solution overview
Our cloud data platform built on Amazon S3 is fed from a combination of enterprise ELT systems. We have an on-premises system that handles change data capture (CDC) workloads and another that works more in a traditional batch manner.
Our design has the on-premises ELT systems dropping files into an S3 bucket set up to receive raw data for both situations. We made the decision to standardize our processed data layer into Apache Parquet format for our cataloged S3 data lake in preparation for more efficient serverless consumption.
Our enterprise CDC system can already land files natively in Parquet; however, our batch files are limited to CSV, so the landing of CSV files triggers another serverless process to convert these files to Parquet using AWS Glue ETL.
The following diagram illustrates this workflow.
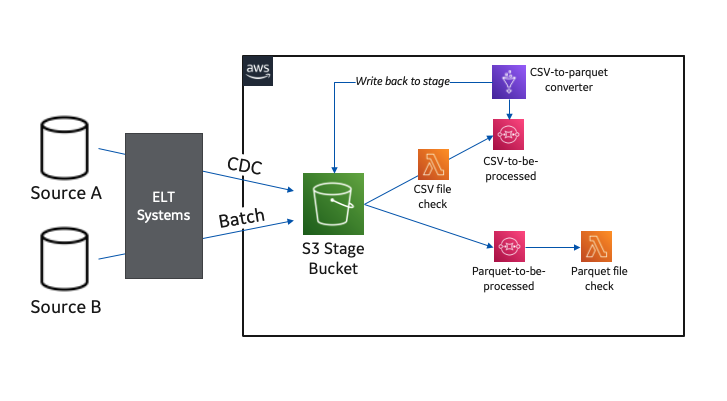
When raw data is present and ready in Apache Parquet format, we have an event-triggered solution that processes the data and loads it to another mirror S3 bucket (this is where our users access and consume the data).
Pipelines are developed to support loading at a table level. We have specific AWS Lambda functions to identify schema errors by comparing each file’s schema against the last successful run. Another function validates that a necessary primary key file is present for any CDC tables.
Data partitioning and CDC updates
When our preprocessing Lambda functions are complete, the files are processed in one of two distinct paths based on the table type. Batch table loads are by far the simpler of the two and are handled via a single Lambda function.
For CDC tables, we use AWS Glue ETL to load and perform the updates against our tables stored in the mirror S3 bucket. The AWS Glue job uses Apache Spark data frames to combine historical data, filter out deleted records, and union with any records inserted. For our process, updates are treated as delete-then-insert. After performing the union, the entire dataset is written out to the mirror S3 bucket in a newly created bucket partition.
The following diagram illustrates this workflow.

We write data into a new partition for each table load, so we can provide read consistency in a way that makes sense to our consuming business partners.
Building the Data Catalog
When each Amazon S3 mirror data load is complete, another separate serverless branch is triggered to handle catalog management.
The branch updates the location property within the catalog for pre-existing tables, indicating each newly added partition. When loading a table for the first time, we trigger a series of purpose-built Lambda functions to create the AWS Glue Data Catalog database (only required when it’s an entirely new source schema), create an AWS Glue crawler, start the crawler, and delete the crawler when it’s complete.
The following diagram illustrates this workflow.

These event-driven design patterns allow us to fully automate the catalog management piece of our architecture, which became a big win for our team because it lowered the operational overhead associated with onboarding new source tables. Every achievement like this mattered because it realized the potential the cloud had to transform how we build and support products across our technology organization.
Final implementation architecture and best practices
The solution evolved several times throughout the development cycle, typically due to learning something new in terms of serverless and cloud-native development, and further working with AWS Solutions Architect and AWS Professional Services teams. Along the way, we’ve discovered many cloud-native best practices and accelerated our serverless data journey to AWS.
The following diagram illustrates our final architecture.
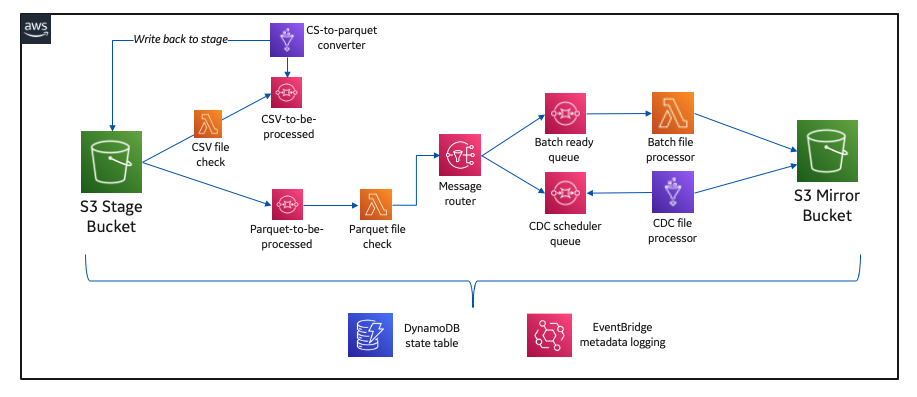
We strategically added Amazon Simple Queue Service (Amazon SQS) between purpose-built Lambda functions to decouple the architecture. Amazon SQS gave our system a level of resiliency and operational observability that otherwise would have been a challenge.
Another best practice arose from using Amazon DynamoDB as a state table to help ensure our entire serverless integration pattern was writing to our mirror bucket with ACID guarantees.
On the topic of operational observability, we use Amazon EventBridge to capture and report on operational metadata like table load status, time of the last load, and row counts.
Bringing it all together
At the time of writing, we’ve had production workloads running through our solution for the better part of 14 months.
Production data is integrated from more than 30 source systems at present and totals several hundred tables. This solution has given us a great starting point for building our cloud data ecosystem. The flexibility and extensibility of AWS’s many services have been key to our success.
Appreciation for the AWS Glue Data Catalog has been an essential element. Without knowing it at the time we started building a data lake, we’ve been embracing a modern data architecture pattern and organizing around our transactionally consistent and cataloged mirror storage layer.
The introduction of a more seamless Apache Hudi experience within AWS has been a big win for our team. We’ve been busy incorporating Hudi into our CDC transaction pipeline and are thrilled with the results. We’re able to spend less time writing code managing the storage of our data, and more time focusing on the reliability of our system. This has been critical in our ability to scale. Our development pipeline has grown beyond 10,000 tables and more than 150 source systems as we approach another major production cutover.
Looking ahead, we’re intrigued by the potential for AWS Lake Formation goverened tables to further accelerate our momentum and management of CDC table loads.
Conclusion
Building our cloud-native integration pipeline has been a journey. What started as an idea and has turned into much more in a brief time. It’s hard to appreciate how far we’ve come when there’s always more to be done. That being said, the entire process has been extraordinary. We built deep and trusted partnerships with AWS, learned more about our internal value statement, and aligned more of our organization to a cloud-centric way of operating.
The ability to build solutions in a serverless manner opens up many doors for our data function and, most importantly, our customers. Speed to delivery and the pace of innovation is directly related to our ability to focus our engineering teams on business-specific problems while trusting a partner like AWS to do the heavy lifting of data center operations like racking, stacking, and powering servers. It also removes the operational burden of managing operating systems and applications with managed services. Finally, it allows us to focus on our customers and business process enablement rather than on IT infrastructure.
The breadth and depth of data and analytics services on AWS make it possible to solve our business problems by using the right resources to run whatever analysis is most appropriate for a specific need. AWS Data and Analytics has deep integrations across all layers of the AWS ecosystem, giving us the tools to analyze data using any approach quickly. We appreciate AWS’s continual innovation on behalf of its customers.
About the Authors
 Alcuin Weidus is a Principal Data Architect for GE Aviation. Serverless advocate, perpetual data management student, and cloud native strategist, Alcuin is a data technology leader on a team responsible for accelerating technical outcomes across GE Aviation. Connect him on Linkedin.
Alcuin Weidus is a Principal Data Architect for GE Aviation. Serverless advocate, perpetual data management student, and cloud native strategist, Alcuin is a data technology leader on a team responsible for accelerating technical outcomes across GE Aviation. Connect him on Linkedin.
 Suresh Patnam is a Sr Solutions Architect at AWS; He works with customers to build IT strategy, making digital transformation through the cloud more accessible, focusing on big data, data lakes, and AI/ML. In his spare time, Suresh enjoys playing tennis and spending time with his family. Connect him on LinkedIn.
Suresh Patnam is a Sr Solutions Architect at AWS; He works with customers to build IT strategy, making digital transformation through the cloud more accessible, focusing on big data, data lakes, and AI/ML. In his spare time, Suresh enjoys playing tennis and spending time with his family. Connect him on LinkedIn.