AWS Big Data Blog
How NerdWallet uses AWS and Apache Hudi to build a serverless, real-time analytics platform
This is a guest post by Kevin Chun, Staff Software Engineer in Core Engineering at NerdWallet.
NerdWallet’s mission is to provide clarity for all of life’s financial decisions. This covers a diverse set of topics: from choosing the right credit card, to managing your spending, to finding the best personal loan, to refinancing your mortgage. As a result, NerdWallet offers powerful capabilities that span across numerous domains, such as credit monitoring and alerting, dashboards for tracking net worth and cash flow, machine learning (ML)-driven recommendations, and many more for millions of users.
To build a cohesive and performant experience for our users, we need to be able to use large volumes of varying user data sourced by multiple independent teams. This requires a strong data culture along with a set of data infrastructure and self-serve tooling that enables creativity and collaboration.
In this post, we outline a use case that demonstrates how NerdWallet is scaling its data ecosystem by building a serverless pipeline that enables streaming data from across the company. We iterated on two different architectures. We explain the challenges we ran into with the initial design and the benefits we achieved by using Apache Hudi and additional AWS services in the second design.
Problem statement
NerdWallet captures a sizable amount of spending data. This data is used to build helpful dashboards and actionable insights for users. The data is stored in an Amazon Aurora cluster. Even though the Aurora cluster works well as an Online Transaction Processing (OLTP) engine, it’s not suitable for large, complex Online Analytical Processing (OLAP) queries. As a result, we can’t expose direct database access to analysts and data engineers. The data owners have to solve requests with new data derivations on read replicas. As the data volume and the diversity of data consumers and requests grow, this process gets more difficult to maintain. In addition, data scientists mostly require data files access from an object store like Amazon Simple Storage Service (Amazon S3).
We decided to explore alternatives where all consumers can independently fulfill their own data requests safely and scalably using open-standard tooling and protocols. Drawing inspiration from the data mesh paradigm, we designed a data lake based on Amazon S3 that decouples data producers from consumers while providing a self-serve, security-compliant, and scalable set of tooling that is easy to provision.
Initial design
The following diagram illustrates the architecture of the initial design.

The design included the following key components:
- We chose AWS Data Migration Service (AWS DMS) because it’s a managed service that facilitates the movement of data from various data stores such as relational and NoSQL databases into Amazon S3. AWS DMS allows one-time migration and ongoing replication with change data capture (CDC) to keep the source and target data stores in sync.
- We chose Amazon S3 as the foundation for our data lake because of its scalability, durability, and flexibility. You can seamlessly increase storage from gigabytes to petabytes, paying only for what you use. It’s designed to provide 11 9s of durability. It supports structured, semi-structured, and unstructured data, and has native integration with a broad portfolio of AWS services.
- AWS Glue is a fully managed data integration service. AWS Glue makes it easier to categorize, clean, transform, and reliably transfer data between different data stores.
- Amazon Athena is a serverless interactive query engine that makes it easy to analyze data directly in Amazon S3 using standard SQL. Athena scales automatically—running queries in parallel—so results are fast, even with large datasets, high concurrency, and complex queries.
This architecture works fine with small testing datasets. However, the team quickly ran into complications with the production datasets at scale.
Challenges
The team encountered the following challenges:
- Long batch processing time and complexed transformation logic – A single run of the Spark batch job took 2–3 hours to complete, and we ended up getting a fairly large AWS bill when testing against billions of records. The core problem was that we had to reconstruct the latest state and rewrite the entire set of records per partition for every job run, even if the incremental changes were a single record of the partition. When we scaled that to thousands of unique transactions per second, we quickly saw the degradation in transformation performance.
- Increased complexity with a large number of clients – This workload contained millions of clients, and one common query pattern was to filter by single client ID. There were numerous optimizations that we were forced to tack on, such as predicate pushdowns, tuning the Parquet file size, using a bucketed partition scheme, and more. As more data owners adopted this architecture, we would have to customize each of these optimizations for their data models and consumer query patterns.
- Limited extendibility for real-time use cases – This batch extract, transform, and load (ETL) architecture wasn’t going to scale to handle hourly updates of thousands of records upserts per second. In addition, it would be challenging for the data platform team to keep up with the diverse real-time analytical needs. Incremental queries, time-travel queries, improved latency, and so on would require heavy investment over a long period of time. Improving on this issue would open up possibilities like near-real-time ML inference and event-based alerting.
With all these limitations of the initial design, we decided to go all-in on a real incremental processing framework.
Solution
The following diagram illustrates our updated design. To support real-time use cases, we added Amazon Kinesis Data Streams, AWS Lambda, Amazon Kinesis Data Firehose and Amazon Simple Notification Service (Amazon SNS) into the architecture.
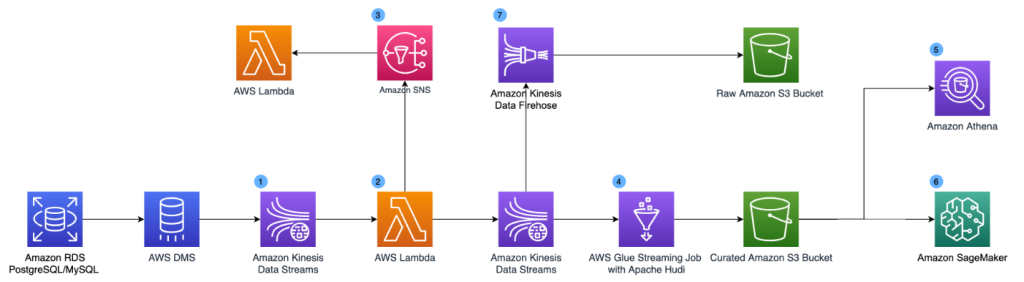
The updated components are as follows:
- Amazon Kinesis Data Streams is a serverless streaming data service that makes it easy to capture, process, and store data streams. We set up a Kinesis data stream as a target for AWS DMS. The data stream collects the CDC logs.
- We use a Lambda function to transform the CDC records. We apply schema validation and data enrichment at the record level in the Lambda function. The transformed results are published to a second Kinesis data stream for the data lake consumption and an Amazon SNS topic so that changes can be fanned out to various downstream systems.
- Downstream systems can subscribe to the Amazon SNS topic and take real-time actions (within seconds) based on the CDC logs. This can support use cases like anomaly detection and event-based alerting.
- To solve the problem of long batch processing time, we use Apache Hudi file format to store the data and perform streaming ETL using AWS Glue streaming jobs. Apache Hudi is an open-source transactional data lake framework that greatly simplifies incremental data processing and data pipeline development. Hudi allows you to build streaming data lakes with incremental data pipelines, with support for transactions, record-level updates, and deletes on data stored in data lakes. Hudi integrates well with various AWS analytics services such as AWS Glue, Amazon EMR, and Athena, which makes it a straightforward extension of our previous architecture. While Apache Hudi solves the record-level update and delete challenges, AWS Glue streaming jobs convert the long-running batch transformations into low-latency micro-batch transformations. We use the AWS Glue Connector for Apache Hudi to import the Apache Hudi dependencies in the AWS Glue streaming job and write transformed data to Amazon S3 continuously. Hudi does all the heavy lifting of record-level upserts, while we simply configure the writer and transform the data into Hudi Copy-on-Write table type. With Hudi on AWS Glue streaming jobs, we reduce the data freshness latency for our core datasets from hours to under 15 minutes.
- To solve the partition challenges for high cardinality UUIDs, we use the bucketing technique. Bucketing groups data based on specific columns together within a single partition. These columns are known as bucket keys. When you group related data together into a single bucket (a file within a partition), you significantly reduce the amount of data scanned by Athena, thereby improving query performance and reducing cost. Our existing queries are filtered on the user ID already, so we significantly improve the performance of our Athena usage without having to rewrite queries by using bucketed user IDs as the partition scheme. For example, the following code shows total spending per user in specific categories:
- Our data scientist team can access the dataset and perform ML model training using Amazon SageMaker.
- We maintain a copy of the raw CDC logs in Amazon S3 via Amazon Kinesis Data Firehose.
Conclusion
In the end, we landed on a serverless stream processing architecture that can scale to thousands of writes per second within minutes of freshness on our data lakes. We’ve rolled out to our first high-volume team! At our current scale, the Hudi job is processing roughly 1.75 MiB per second per AWS Glue worker, which can automatically scale up and down (thanks to AWS Glue auto scaling). We’ve also observed an outstanding improvement of end-to-end freshness at less than 5 minutes due to Hudi’s incremental upserts vs. our first attempt.
With Hudi on Amazon S3, we’ve built a high-leverage foundation to personalize our users’ experiences. Teams that own data can now share their data across the organization with reliability and performance characteristics built into a cookie-cutter solution. This enables our data consumers to build more sophisticated signals to provide clarity for all of life’s financial decisions.
We hope that this post will inspire your organization to build a real-time analytics platform using serverless technologies to accelerate your business goals.
About the authors
 Kevin Chun is a Staff Software Engineer in Core Engineering at NerdWallet. He builds data infrastructure and tooling to help NerdWallet provide clarity for all of life’s financial decisions.
Kevin Chun is a Staff Software Engineer in Core Engineering at NerdWallet. He builds data infrastructure and tooling to help NerdWallet provide clarity for all of life’s financial decisions.
 Dylan Qu is a Specialist Solutions Architect focused on big data and analytics with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
Dylan Qu is a Specialist Solutions Architect focused on big data and analytics with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.