AWS Big Data Blog

iostudio delivers key metrics to public sector recruiters with Amazon QuickSight
This is a guest post by Jon Walker and Ari Orlinsky from iostudio written in collaboration with Sumitha AP from AWS. iostudio is an award-winning marketing agency based in Nashville, TN. We build solutions that bring brands to life, making content and platforms work together. We serve our customers, who range from small technology startups […]

Harmonize data using AWS Glue and AWS Lake Formation FindMatches ML to build a customer 360 view
In today’s digital world, data is generated by a large number of disparate sources and growing at an exponential rate. Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their data lake to derive […]

Enable business users to analyze large datasets in your data lake with Amazon QuickSight
This blog post is co-written with Ori Nakar from Imperva. Imperva Cloud WAF protects hundreds of thousands of websites and blocks billions of security events every day. Events and many other security data types are stored in Imperva’s Threat Research Multi-Region data lake. Imperva harnesses data to improve their business outcomes. To enable this transformation […]
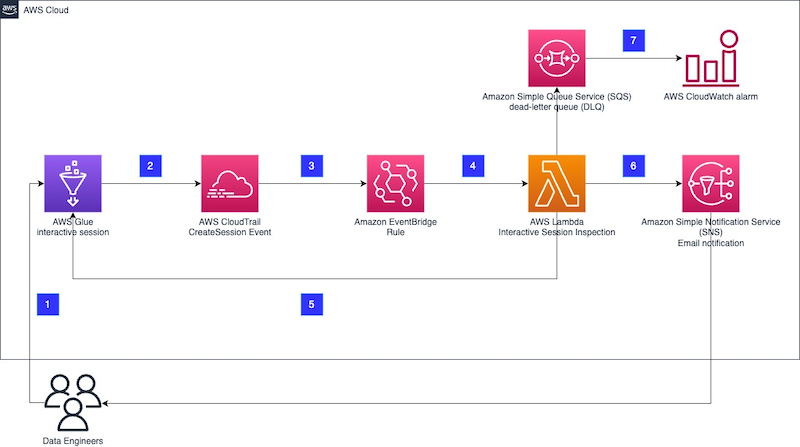
Enforce boundaries on AWS Glue interactive sessions
AWS Glue interactive sessions allow engineers to build, test, and run data preparation and analytics workloads in an interactive notebook. Interactive sessions provide isolated development environments, take care of the underlying compute cluster, and allow for configuration to stop idling resources. Glue interactive sessions provides default recommended configurations, and also allows users to customize the […]

Get started managing partitions for Amazon S3 tables backed by the AWS Glue Data Catalog
Large organizations processing huge volumes of data usually store it in Amazon Simple Storage Service (Amazon S3) and query the data to make data-driven business decisions using distributed analytics engines such as Amazon Athena. If you simply run queries without considering the optimal data layout on Amazon S3, it results in a high volume of […]

Amazon OpenSearch Service’s vector database capabilities explained
Using Amazon OpenSearch Service’s vector database capabilities, you can implement semantic search, Retrieval Augmented Generation (RAG) with LLMs, recommendation engines, and search in rich media. Learn how.

Accelerate onboarding and seamless integration with ThoughtSpot using Amazon Redshift partner integration
Amazon Redshift is a fast, petabyte-scale cloud data warehouse that makes it simple and cost-effective to analyze all of your data using standard SQL. Tens of thousands of customers today rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the most widely used cloud data warehouse. You can […]

Build an Amazon Redshift data warehouse using an Amazon DynamoDB single-table design
DynamoDB zero-ETL integration with Amazon Redshift is now generally available and provides fully-managed replication of DynamoDB tables into an Amazon Redshift database. Learn more at DynamoDB zero-ETL integration with Amazon Redshift. Amazon DynamoDB is a fully managed NoSQL service that delivers single-digit millisecond performance at any scale. It’s used by thousands of customers for mission-critical […]

Stream VPC Flow Logs to Datadog via Amazon Kinesis Data Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. It’s common to store the logs generated by customer’s applications and services in various tools. These logs are important for compliance, audits, troubleshooting, security incident responses, meeting security policies, and many other […]

Accelerate data science feature engineering on transactional data lakes using Amazon Athena with Apache Iceberg
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) and data sources residing in AWS, on-premises, or other cloud systems using SQL or Python. Athena is built on open-source Trino and Presto engines, and Apache Spark frameworks, with no provisioning or configuration effort […]