AWS Big Data Blog

Multi-tenancy Apache Kafka clusters in Amazon MSK with IAM access control and Kafka Quotas – Part 1
With Amazon Managed Streaming for Apache Kafka (Amazon MSK), you can build and run applications that use Apache Kafka to process streaming data. To process streaming data, organizations either use multiple Kafka clusters based on their application groupings, usage scenarios, compliance requirements, and other factors, or a dedicated Kafka cluster for the entire organization. It […]

Multi-tenancy Apache Kafka clusters in Amazon MSK with IAM access control and Kafka quotas – Part 2
Kafka quotas are integral to multi-tenant Kafka clusters. They prevent Kafka cluster performance from being negatively affected by poorly behaved applications overconsuming cluster resources. Furthermore, they enable the central streaming data platform to be operated as a multi-tenant platform and used by downstream and upstream applications across multiple business lines. Kafka supports two types of quotas: […]

Ingest, transform, and deliver events published by Amazon Security Lake to Amazon OpenSearch Service
With the recent introduction of Amazon Security Lake, it has never been simpler to access all your security-related data in one place. Whether it’s findings from AWS Security Hub, DNS query data from Amazon Route 53, network events such as VPC Flow Logs, or third-party integrations provided by partners such as Barracuda Email Protection, Cisco […]

Optimize queries using dataset parameters in Amazon QuickSight
Amazon QuickSight powers data-driven organizations with unified business intelligence (BI) at hyperscale. With QuickSight, all users can meet varying analytic needs from the same source of truth through modern interactive dashboards, paginated reports, embedded analytics and natural language queries. We have introduced dataset parameters, a new kind of parameter in QuickSight that can help you […]

Best practices for enabling business users to answer questions about data using natural language in Amazon QuickSight
In this post, we explain how you can enable business users to ask and answer questions about data using their everyday business language by using the Amazon QuickSight natural language query function, Amazon QuickSight Q. QuickSight is a unified BI service providing modern interactive dashboards, natural language querying, paginated reports, machine learning (ML) insights, and […]

Efficiently crawl your data lake and improve data access with an AWS Glue crawler using partition indexes
In today’s world, customers manage vast amounts of data in their Amazon Simple Storage Service (Amazon S3) data lakes, which requires convoluted data pipelines to continuously understand the changes in the data layout and make them available to consuming systems. AWS Glue crawlers provide a straightforward way to catalog data in the AWS Glue Data […]

Enable data collaboration among public health agencies with AWS Clean Rooms – Part 1
In this post, we show how you can use AWS Clean Rooms to enable data collaboration between public health agencies. Public health governmental agencies need to understand trends related to a variety of health conditions and care across populations in order to create policies and treatments with the goal of improving the well-being of the […]
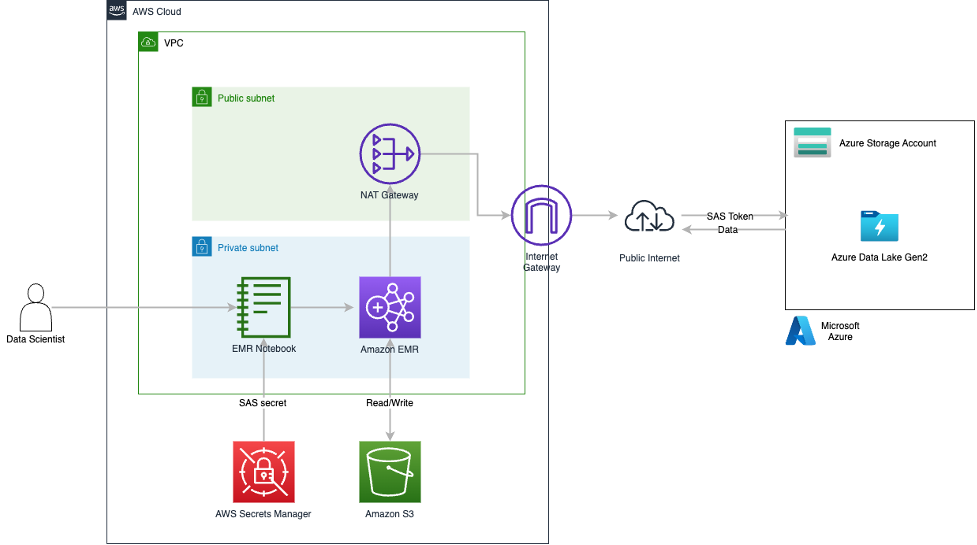
Enable remote reads from Azure ADLS with SAS tokens using Spark in Amazon EMR
Organizations use data from many sources to understand, analyze, and grow their business. These data sources are often spread across various public cloud providers. Enterprises may also expand their footprint by mergers and acquisitions, and during such events they often end up with data spread across different public cloud providers. These scenarios can create the […]

Improved resiliency with backpressure and admission control for Amazon OpenSearch Service
Amazon OpenSearch Service is a managed service that makes it simple to secure, deploy, and operate OpenSearch clusters at scale in the AWS Cloud. Last year, we introduced Shard Indexing Backpressure and admission control, which monitors cluster resources and incoming traffic to selectively reject requests that would otherwise pose stability risks like out of memory […]

AWS Professional Services scales by improving performance and democratizing data with Amazon QuickSight
The AWS Professional Services (ProServe) Insights team builds global operational data products that serve over 8,000 users within Amazon. Our team was formed in 2019 as an informal group of four analysts who supported ad hoc analysis for a division of ProServe consultants. ProServe is responsible for assisting enterprises as they shift to the cloud […]