Artificial Intelligence
Accelerate Enterprise AI Development using Weights & Biases and Amazon Bedrock AgentCore
This post is co-written by Thomas Capelle and Ray Strickland from Weights & Biases (W&B).
Generative artificial intelligence (AI) adoption is accelerating across enterprises, evolving from simple foundation model interactions to sophisticated agentic workflows. As organizations transition from proof-of-concepts to production deployments, they require robust tools for development, evaluation, and monitoring of AI applications at scale.
In this post, we demonstrate how to use Foundation Models (FMs) from Amazon Bedrock and the newly launched Amazon Bedrock AgentCore alongside W&B Weave to help build, evaluate, and monitor enterprise AI solutions. We cover the complete development lifecycle from tracking individual FM calls to monitoring complex agent workflows in production.
Overview of W&B Weave
Weights & Biases (W&B) is an AI developer system that provides comprehensive tools for training models, fine-tuning, and leveraging foundation models for enterprises of all sizes across various industries.
W&B Weave offers a unified suite of developer tools to support every stage of your agentic AI workflows. It enables:
- Tracing & monitoring: Track large language model (LLM) calls and application logic to debug and analyze production systems.
- Systematic iteration: Refine and iterate on prompts, datasets and models.
- Experimentation: Experiment with different models and prompts in the LLM Playground.
- Evaluation: Use custom or pre-built scorers alongside our comparison tools to systematically assess and enhance application performance. Collect user and expert feedback for real-life testing and evaluation.
- Guardrails: Help protect your application with safeguards for content moderation, prompt safety, and more. Use custom or third-party guardrails (including Amazon Bedrock Guardrails) or W&B Weave’s native guardrails.
W&B Weave can be fully managed by Weights & Biases in a multi-tenant or single-tenant environment or can be deployed in a customer’s Amazon Virtual Private Cloud (VPC) directly. In addition, W&B Weave’s integration into the W&B Development Platform provides organizations a seamlessly integrated experience between the model training/fine-tuning workflow and the agentic AI workflow.
To get started, subscribe to the Weights & Biases AI Development Platform through AWS Marketplace. Individuals and academic teams can subscribe to W&B at no additional cost.
Tracking Amazon Bedrock FMs with W&B Weave SDK
W&B Weave integrates seamlessly with Amazon Bedrock through Python and TypeScript SDKs. After installing the library and patching your Bedrock client, W&B Weave automatically tracks the LLM calls:
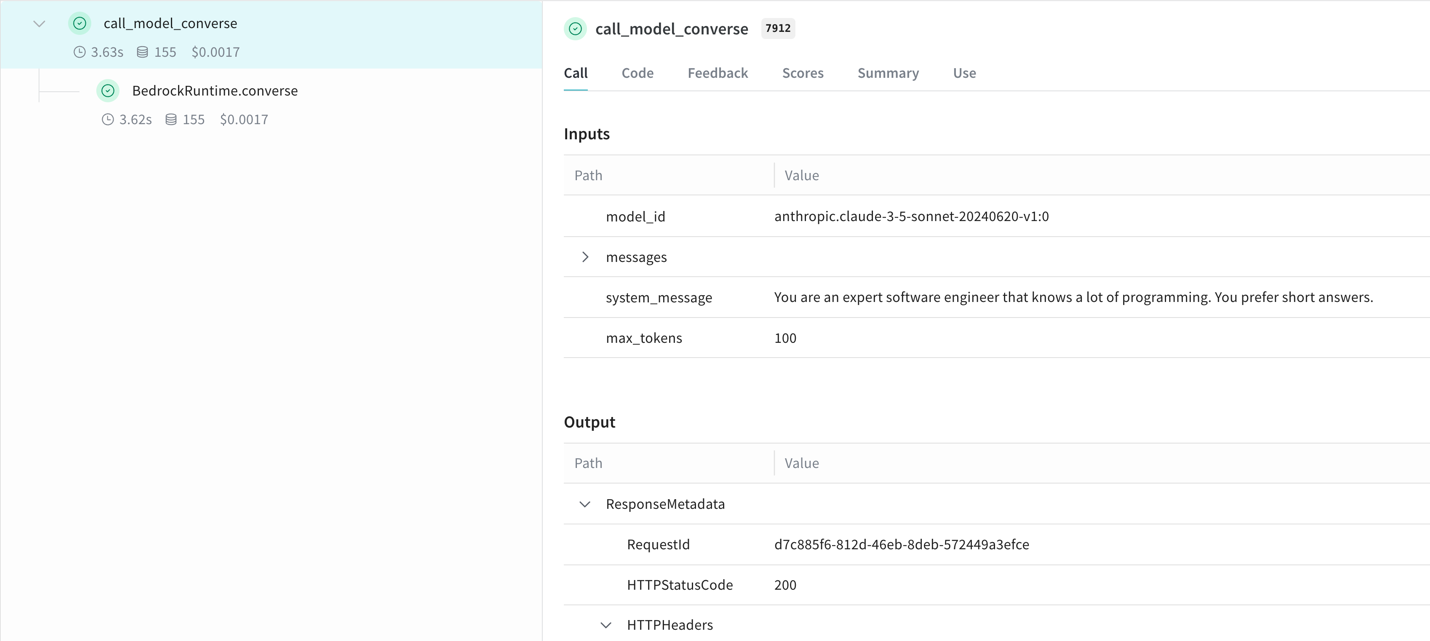
This integration automatically versions experiments and tracks configurations, providing complete visibility into your Amazon Bedrock applications without modifying core logic.
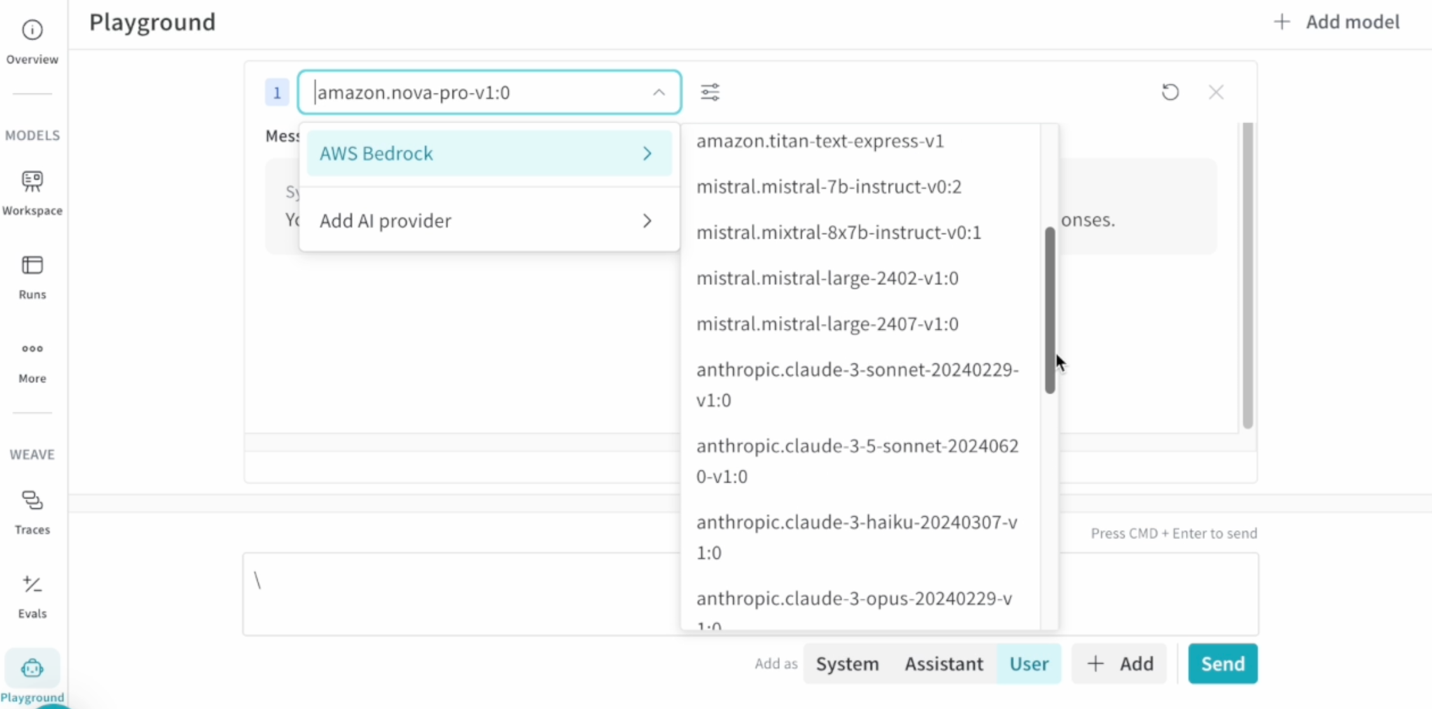
Experimenting with Amazon Bedrock FMs in W&B Weave Playground
The W&B Weave Playground accelerates prompt engineering with an intuitive interface for testing and comparing Bedrock models. Key features include:
- Direct prompt editing and message retrying
- Side-by-side model comparison
- Access from trace views for rapid iteration
To begin, add your AWS credentials in the Playground settings, select your preferred Amazon Bedrock FMs, and start experimenting. The interface enables rapid iteration on prompts while maintaining full traceability of experiments.
Evaluating Amazon Bedrock FMs with W&B Weave Evaluations
W&B Weave Evaluations provides dedicated tools for evaluating generative AI models effectively. By leveraging W&B Weave Evaluations alongside Amazon Bedrock, users can efficiently evaluate these models, analyze outputs, and visualize performance across key metrics. Users can use built in scorers from W&B Weave, 3rd party or custom scorers, and human/expert feedback as well. This combination allows for a deeper understanding of the tradeoffs between models, such as differences in cost, accuracy, speed, and output quality.
W&B Weave has a first-class way to track evaluations with Model & Evaluation classes. To set up an evaluation job, customers can:
- Define a dataset or list of dictionaries with a collection of examples to be evaluated
- Create a list of scoring functions. Each function should have a model_output and optionally, other inputs from your examples, and return a dictionary with the scores
- Define an Amazon Bedrock model by using Model class
- Evaluate this model by calling Evaluation
Here’s an example of setting up an evaluation job:
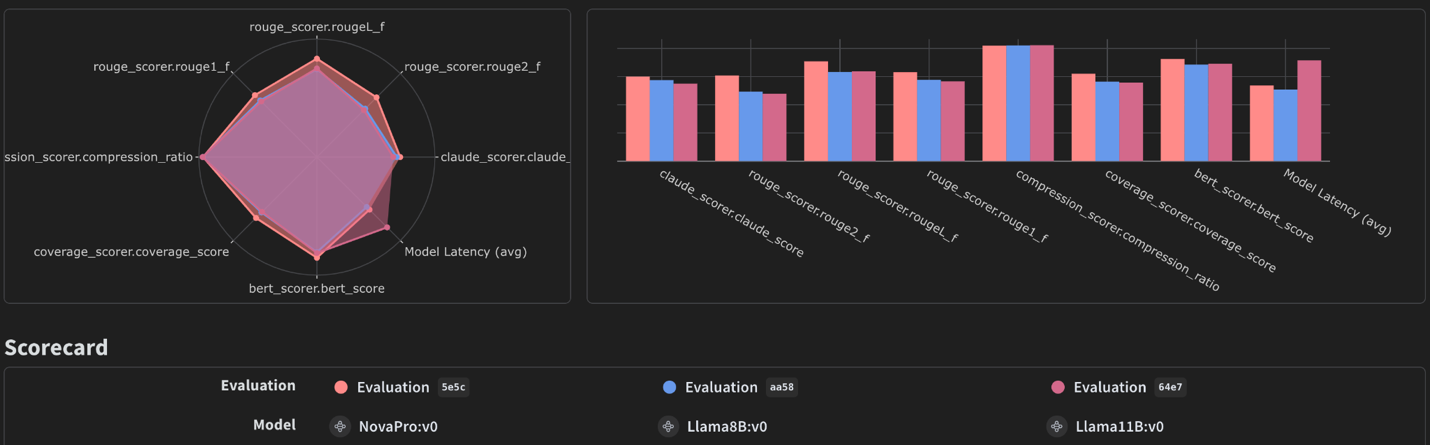
The evaluation dashboard visualizes performance metrics, enabling informed decisions about model selection and configuration. For detailed guidance, see our previous post on evaluating LLM summarization with Amazon Bedrock and Weave.
Enhancing Amazon Bedrock AgentCore Observability with W&B Weave
Amazon Bedrock AgentCore is a complete set of services for deploying and operating highly capable agents more securely at enterprise scale. It provides more secure runtime environments, workflow execution tools, and operational controls that work with popular frameworks like Strands Agents, CrewAI, LangGraph, and LlamaIndex, as well as many LLM models – whether from Amazon Bedrock or external sources.
AgentCore includes built-in observability through Amazon CloudWatch dashboards that track key metrics like token usage, latency, session duration, and error rates. It also traces workflow steps, showing which tools were invoked and how the model responded, providing essential visibility for debugging and quality assurance in production.
When working with AgentCore and W&B Weave together, teams can use AgentCore’s built-in operational monitoring and security foundations while also using W&B Weave if it aligns with their existing development workflows. Organizations already invested in the W&B environment may choose to incorporate W&B Weave’s visualization tools alongside AgentCore’s native capabilities. This approach gives teams flexibility to use the observability solution that best fits their established processes and preferences when developing complex agents that chain multiple tools and reasoning steps.
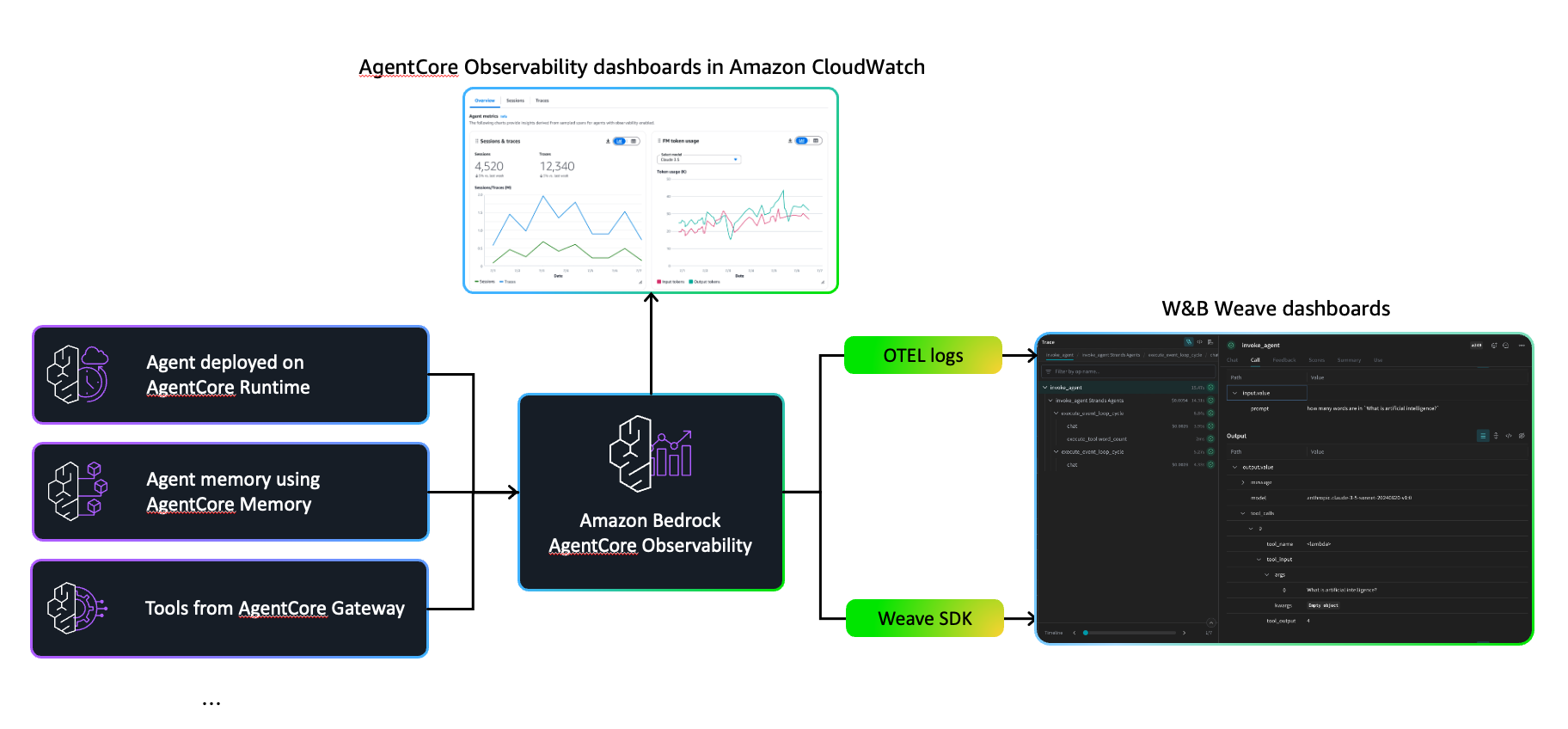
There are two main approaches to add W&B Weave observability to your AgentCore agents: using the native W&B Weave SDK or integrating through OpenTelemetry.
Native W&B Weave SDK
The simplest approach is to use W&B Weave’s @weave.op decorator to automatically track function calls. Initialize W&B Weave with your project name and wrap the functions you want to monitor:
Since AgentCore runs as a docker container, add W&B weave to your dependencies (for example, uv add weave) to include it in your container image.
OpenTelemetry Integration
For teams already using OpenTelemetry or wanting vendor-neutral instrumentation, W&B Weave supports OTLP (OpenTelemetry Protocol) directly:
This approach maintains compatibility with AgentCore’s existing OpenTelemetry infrastructure while routing traces to W&B Weave for visualization.When using both AgentCore and W&B Weave together, teams have multiple options for observability. AgentCore’s CloudWatch integration monitors system health, resource utilization, and error rates while providing tracing for agent reasoning and tool selection. W&B Weave offers visualization capabilities that present execution data in formats familiar to teams already using the W&B environment. Both solutions provide visibility into how agents process information and make decisions, allowing organizations to choose the observability approach that best aligns with their existing workflows and preferences.This dual-layer approach means users can:
- Monitor production service level agreements (SLAs) through CloudWatch alerts
- Debug complex agent behaviors in W&B Weave’s trace explorer
- Optimize token usage and latency with detailed execution breakdowns
- Compare agent performance across different prompts and configurations
The integration requires minimal code changes, preserves your existing AgentCore deployment, and scales with your agent complexity. Whether you’re building simple tool-calling agents or orchestrating multi-step workflows, this observability stack provides the insights needed to iterate quickly and deploy confidently.
For implementation details and complete code examples, refer to our previous post.
Conclusion
In this post, we demonstrated how to build and optimize enterprise-grade agentic AI solutions by combining Amazon Bedrock’s FMs and AgentCore with W&B Weave’s comprehensive observability toolkit. We explored how W&B Weave can enhance every stage of the LLM development lifecycle—from initial experimentation in the Playground to systematic evaluation of model performance, and finally to production monitoring of complex agent workflows.
The integration between Amazon Bedrock and W&B Weave provides several key capabilities:
- Automatic tracking of Amazon Bedrock FM calls with minimal code changes using the W&B Weave SDK
- Rapid experimentation through the W&B Weave Playground’s intuitive interface for testing prompts and comparing models
- Systematic evaluation with custom scoring functions to evaluate different Amazon Bedrock models
- Comprehensive observability for AgentCore deployments, with CloudWatch metrics providing more robust operational monitoring supplemented by detailed execution traces
To get started:
- Request a free trial or subscribe to Weights &Biases AI Development Platform through AWS Marketplace
- Install the W&B Weave SDK and follow our code examples to begin tracking your Bedrock FM calls
- Experiment with different models in the W&B Weave Playground by adding your AWS credentials and testing various Amazon Bedrock FMs
- Set up evaluations using the W&B Weave Evaluation framework to systematically compare model performance for your use cases
- Enhance your AgentCore agents by adding W&B Weave observability using either the native SDK or OpenTelemetry integration
Start with a simple integration to track your Amazon Bedrock calls, then progressively adopt more advanced features as your AI applications grow in complexity. The combination of Amazon Bedrock and W&B Weave’s comprehensive development tools provides the foundation needed to build, evaluate, and maintain production-ready AI solutions at scale.
About the authors
 James Yi is a Senior AI/ML Partner Solutions Architect at AWS. He spearheads AWS’s strategic partnerships in Emerging Technologies, guiding engineering teams to design and develop cutting-edge joint solutions in generative AI. He enables field and technical teams to seamlessly deploy, operate, secure, and integrate partner solutions on AWS. James collaborates closely with business leaders to define and execute joint Go-To-Market strategies, driving cloud-based business growth. Outside of work, he enjoys playing soccer, traveling, and spending time with his family.
James Yi is a Senior AI/ML Partner Solutions Architect at AWS. He spearheads AWS’s strategic partnerships in Emerging Technologies, guiding engineering teams to design and develop cutting-edge joint solutions in generative AI. He enables field and technical teams to seamlessly deploy, operate, secure, and integrate partner solutions on AWS. James collaborates closely with business leaders to define and execute joint Go-To-Market strategies, driving cloud-based business growth. Outside of work, he enjoys playing soccer, traveling, and spending time with his family.
 Ray Strickland is a Senior Partner Solutions Architect at AWS specializing in AI/ML, Agentic AI and Intelligent Document Processing. He enables partners to deploy scalable generative AI solutions using AWS best practices and drives innovation through strategic partner enablement programs. Ray collaborates across multiple AWS teams to accelerate AI adoption and has extensive experience in partner evaluation and enablement.
Ray Strickland is a Senior Partner Solutions Architect at AWS specializing in AI/ML, Agentic AI and Intelligent Document Processing. He enables partners to deploy scalable generative AI solutions using AWS best practices and drives innovation through strategic partner enablement programs. Ray collaborates across multiple AWS teams to accelerate AI adoption and has extensive experience in partner evaluation and enablement.
 Thomas Capelle is a Machine Learning Engineer at Weights & Biases. He is responsible for keeping the www.github.com/wandb/examples repository live and up to date. He also builds content on MLOPS, applications of W&B to industries, and fun deep learning in general. Previously he was using deep learning to solve short-term forecasting for solar energy. He has a background in Urban Planning, Combinatorial Optimization, Transportation Economics, and Applied Math.
Thomas Capelle is a Machine Learning Engineer at Weights & Biases. He is responsible for keeping the www.github.com/wandb/examples repository live and up to date. He also builds content on MLOPS, applications of W&B to industries, and fun deep learning in general. Previously he was using deep learning to solve short-term forecasting for solar energy. He has a background in Urban Planning, Combinatorial Optimization, Transportation Economics, and Applied Math.
 Scott Juang is the Director of Alliances at Weights & Biases. Prior to W&B, he led a number of strategic alliances at AWS and Cloudera. Scott studied Materials Engineering and has a passion for renewable energy.
Scott Juang is the Director of Alliances at Weights & Biases. Prior to W&B, he led a number of strategic alliances at AWS and Cloudera. Scott studied Materials Engineering and has a passion for renewable energy.