Artificial Intelligence
Automate annotation of image training data with Amazon Rekognition
Every machine learning (ML) model demands data to train it. If your model isn’t predicting Titanic survival or iris species, then acquiring a dataset might be one of the most time-consuming parts of your model-building process—second only to data cleaning.
What data cleaning looks like varies from dataset to dataset. For example, the following is a set of images tagged robin that you might want to use to train an image recognition model on bird species.

That nest might count as dirty data, and some model applications may make it inappropriate to include American and European robins in the same category, but this seems pretty good so far. Let’s keep looking at additional images.

Well, that’s clearly not right.
One thing that can be frustrating about bad data is its obvious wrongness—that roaring campfire and woman with a bow and arrow (perhaps doing a Robin Hood-themed photoshoot?) aren’t even birds, much less robins. If your image collections or datasets weren’t carefully assembled by human intelligence for the specific model training application, they’re likely dirty. Cleaning that kind of dirty data is where Amazon Rekognition comes in.
Solution overview
Amazon Rekognition Image is an image recognition service capable of detecting thousands of different objects using deep neural network models. By taking advantage of the training that’s already gone into the service, you can easily sort through a mass of data and pick out only images that contain a known object, whether that’s as general as animal or as specific as robin. This can lead to the development of a customized dataset narrowly suited for your needs that’s cleaned quickly and cheaply compared to manual solutions. You can apply this principle to any image repository that is expected to include a mix of correct and incorrect images, as long as the correct images fall under an existing Amazon Rekognition label that excludes some incorrect images.
Consider one alternative, Amazon Mechanical Turk, a crowdsourcing marketplace where people can post jobs for virtual gig workers. The minimum price of a task (in this case, one worker labeling an image as “a robin” or “not a robin”) is $0.012. To ensure quality, typical jobs on Mechanical Turk have three to five people view and label each image, bringing the cost floor up to $0.036–$0.06 per image. On Amazon Rekognition, the first million images (beyond the Free Tier, which covers 5,000 images a month for 12 months) each cost $0.001, or at most one twelfth the cost of using Mechanical Turk. For distinctions that don’t require human discernment, that can add up to considerable cost savings.
On top of that, you may desire to control costs by limiting the number of images scanned by Amazon Rekognition. We have a couple options for large repositories that might incur substantial costs if searched exhaustively:
- Place a cap on the number of images to scan. If you want to end up with 50 filtered images for a particular label, like
bird, you might set your algorithm to scan only up to several hundred at most. You might end up with fewer than 50 birds—but if the hit rate was so low that you reached the cap, your repository might not be a great source of bird pictures, and you’ve saved money searching to the end for the fiftieth bird. Ideally, you’ll find 50 birds before reaching the cap and stop then, but it’s the nature of dirty data that we often don’t know exactly how dirty it is. - Implement an early stopping algorithm. If some number, perhaps 20, images in a row fail to turn up any birds, then stop looking. Early stopping might mean the dataset is unsuited to its intended purpose, or that there was some error in the invocation of the function, like a typo in the label (for example a search for
birbinstead ofbird).
Try the demo filter function
The following diagram shows what this solution could look like in practice. A filter function running locally on the client’s computer can use an SDK to make API calls to Amazon Rekognition and Amazon Simple Storage Service (Amazon S3) to check each image in turn. When Amazon Rekognition detects the desired label in an image from the source bucket repository, the function copies that image into the destination bucket.
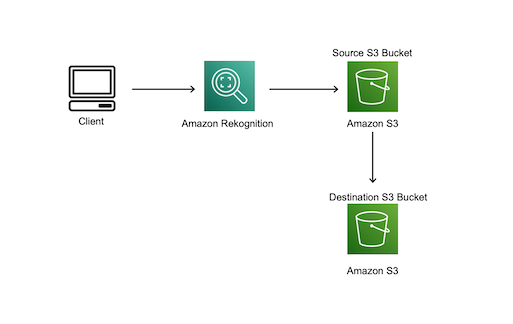
All the function needs are appropriate permissions within your AWS account and the following parameters:
- An Amazon Rekognition label to filter on. To find out which one might be best for your needs, check the current list of available labels (available in the documentation) or try testing a good image from your repository on the Amazon Rekognition console and seeing what labels come up.
- The name of a source bucket in Amazon S3 that contains an unsorted image repository.
- The name of a destination bucket that images are copied into if Amazon Rekognition detects the specified label.
Optionally, you can also specify a confidence threshold to even more stringently filter images, and a name to call the folder that images in the destination bucket are organized into.
A basic filter function might look something like this:
With the images already stored in Amazon S3, you don’t even need to upload them to Amazon Rekognition to get a prompt response.
The following are some ideas for customizing and exploring this procedure:
- Add a human-in-the-loop element to the filter function, so that for Amazon Rekognition confidence scores between certain values, the image is sent elsewhere for manual checking.
- Include the bounding box data from Amazon Rekognition as metadata to train an object detection model.
- Train an Amazon Rekognition Custom Labels model with the collected data—the filter function above stores images in the format expected by Amazon Rekognition Custom Labels, with each folder’s name corresponding to a label the model predicts.
Conclusion
In this post, we explored the possibility of using Amazon Rekognition to filter image sets intended for ML applications. This solution can remove egregiously off-the-mark images from a dataset, which results in cleaner training data and better-performing models at a fraction of the cost of hiring human data labelers.
Interested in learning about ML through blogs, tutorials, and more? Check out the AWS Machine Learning community.
About the Authors
 Samantha Finley is an Associate Solutions Architect at AWS.
Samantha Finley is an Associate Solutions Architect at AWS.
 Quentin Morris is an Associate Solutions Architect at AWS.
Quentin Morris is an Associate Solutions Architect at AWS.
 Jerry Mullis is an Associate Solutions Architect at AWS.
Jerry Mullis is an Associate Solutions Architect at AWS.
 Woodrow Bogucki is an Associate Technical Trainer at AWS. He has a Master’s Degree in Computer Engineering from Texas A&M. His favorite class was Deep Learning and his personal interests include Mexican food, BBQ, and fried chicken.
Woodrow Bogucki is an Associate Technical Trainer at AWS. He has a Master’s Degree in Computer Engineering from Texas A&M. His favorite class was Deep Learning and his personal interests include Mexican food, BBQ, and fried chicken.