Artificial Intelligence
Build trust and safety for generative AI applications with Amazon Comprehend and LangChain
We are witnessing a rapid increase in the adoption of large language models (LLM) that power generative AI applications across industries. LLMs are capable of a variety of tasks, such as generating creative content, answering inquiries via chatbots, generating code, and more.
Organizations looking to use LLMs to power their applications are increasingly wary about data privacy to ensure trust and safety is maintained within their generative AI applications. This includes handling customers’ personally identifiable information (PII) data properly. It also includes preventing abusive and unsafe content from being propagated to LLMs and checking that data generated by LLMs follows the same principles.
In this post, we discuss new features powered by Amazon Comprehend that enable seamless integration to ensure data privacy, content safety, and prompt safety in new and existing generative AI applications.

Amazon Comprehend is a natural language processing (NLP) service that uses machine learning (ML) to uncover information in unstructured data and text within documents. In this post, we discuss why trust and safety with LLMs matter for your workloads. We also delve deeper into how these new moderation capabilities are utilized with the popular generative AI development framework LangChain to introduce a customizable trust and safety mechanism for your use case.
Why trust and safety with LLMs matter
Trust and safety are paramount when working with LLMs due to their profound impact on a wide range of applications, from customer support chatbots to content generation. As these models process vast amounts of data and generate humanlike responses, the potential for misuse or unintended outcomes increases. Ensuring that these AI systems operate within ethical and reliable boundaries is crucial, not just for the reputation of businesses that utilize them, but also for preserving the trust of end-users and customers.
Moreover, as LLMs become more integrated into our daily digital experiences, their influence on our perceptions, beliefs, and decisions grows. Ensuring trust and safety with LLMs goes beyond just technical measures; it speaks to the broader responsibility of AI practitioners and organizations to uphold ethical standards. By prioritizing trust and safety, organizations not only protect their users, but also ensure sustainable and responsible growth of AI in society. It can also help to reduce risk of generating harmful content, and help adhere to regulatory requirements.
In the realm of trust and safety, content moderation is a mechanism that addresses various aspects, including but not limited to:
- Privacy – Users can inadvertently provide text that contains sensitive information, jeopardizing their privacy. Detecting and redacting any PII is essential.
- Toxicity – Recognizing and filtering out harmful content, such as hate speech, threats, or abuse, is of utmost importance.
- User intention – Identifying whether the user input (prompt) is safe or unsafe is critical. Unsafe prompts can explicitly or implicitly express malicious intent, such as requesting personal or private information and generating offensive, discriminatory, or illegal content. Prompts may also implicitly express or request advice on medical, legal, political, controversial, personal, or financial
Content moderation with Amazon Comprehend
In this section, we discuss the benefits of content moderation with Amazon Comprehend.
Addressing privacy
Amazon Comprehend already addresses privacy through its existing PII detection and redaction abilities via the DetectPIIEntities and ContainsPIIEntities APIs. These two APIs are backed by NLP models that can detect a large number of PII entities such as Social Security numbers (SSNs), credit card numbers, names, addresses, phone numbers, and so on. For a full list of entities, refer to PII universal entity types. DetectPII also provides character-level position of the PII entity within a text; for example, the start character position of the NAME entity (John Doe) in the sentence “My name is John Doe” is 12, and the end character position is 19. These offsets can be used to perform masking or redaction of the values, thereby reducing risks of private data propagation into LLMs.
Addressing toxicity and prompt safety
Today, we are announcing two new Amazon Comprehend features in the form of APIs: Toxicity detection via the DetectToxicContent API, and prompt safety classification via the ClassifyDocument API. Note that DetectToxicContent is a new API, whereas ClassifyDocument is an existing API that now supports prompt safety classification.
Toxicity detection
With Amazon Comprehend toxicity detection, you can identify and flag content that may be harmful, offensive, or inappropriate. This capability is particularly valuable for platforms where users generate content, such as social media sites, forums, chatbots, comment sections, and applications that use LLMs to generate content. The primary goal is to maintain a positive and safe environment by preventing the dissemination of toxic content.
At its core, the toxicity detection model analyzes text to determine the likelihood of it containing hateful content, threats, obscenities, or other forms of harmful text. The model is trained on vast datasets containing examples of both toxic and nontoxic content. The toxicity API evaluates a given piece of text to provide toxicity classification and confidence score. Generative AI applications can then use this information to take appropriate actions, such as stopping the text from propagating to LLMs. As of this writing, the labels detected by the toxicity detection API are HATE_SPEECH, GRAPHIC, HARRASMENT_OR_ABUSE, SEXUAL, VIOLENCE_OR_THREAT, INSULT, and PROFANITY. The following code demonstrates the API call with Python Boto3 for Amazon Comprehend toxicity detection:
Prompt safety classification
Prompt safety classification with Amazon Comprehend helps classify an input text prompt as safe or unsafe. This capability is crucial for applications like chatbots, virtual assistants, or content moderation tools where understanding the safety of a prompt can determine responses, actions, or content propagation to LLMs.
In essence, prompt safety classification analyzes human input for any explicit or implicit malicious intent, such as requesting personal or private information and generation of offensive, discriminatory, or illegal content. It also flags prompts looking for advice on medical, legal, political, controversial, personal, or financial subjects. Prompt classification returns two classes, UNSAFE_PROMPT and SAFE_PROMPT, for an associated text, with an associated confidence score for each. The confidence score ranges between 0–1 and combined will sum up to 1. For instance, in a customer support chatbot, the text “How do I reset my password?” signals an intent to seek guidance on password reset procedures and is labeled as SAFE_PROMPT. Similarly, a statement like “I wish something bad happens to you” can be flagged for having a potentially harmful intent and labeled as UNSAFE_PROMPT. It’s important to note that prompt safety classification is primarily focused on detecting intent from human inputs (prompts), rather than machine-generated text (LLM outputs). The following code demonstrates how to access the prompt safety classification feature with the ClassifyDocument API:
Note that endpoint_arn in the preceding code is an AWS-provided Amazon Resource Number (ARN) of the pattern arn:aws:comprehend:<region>:aws:document-classifier-endpoint/prompt-safety, where <region> is the AWS Region of your choice where Amazon Comprehend is available.
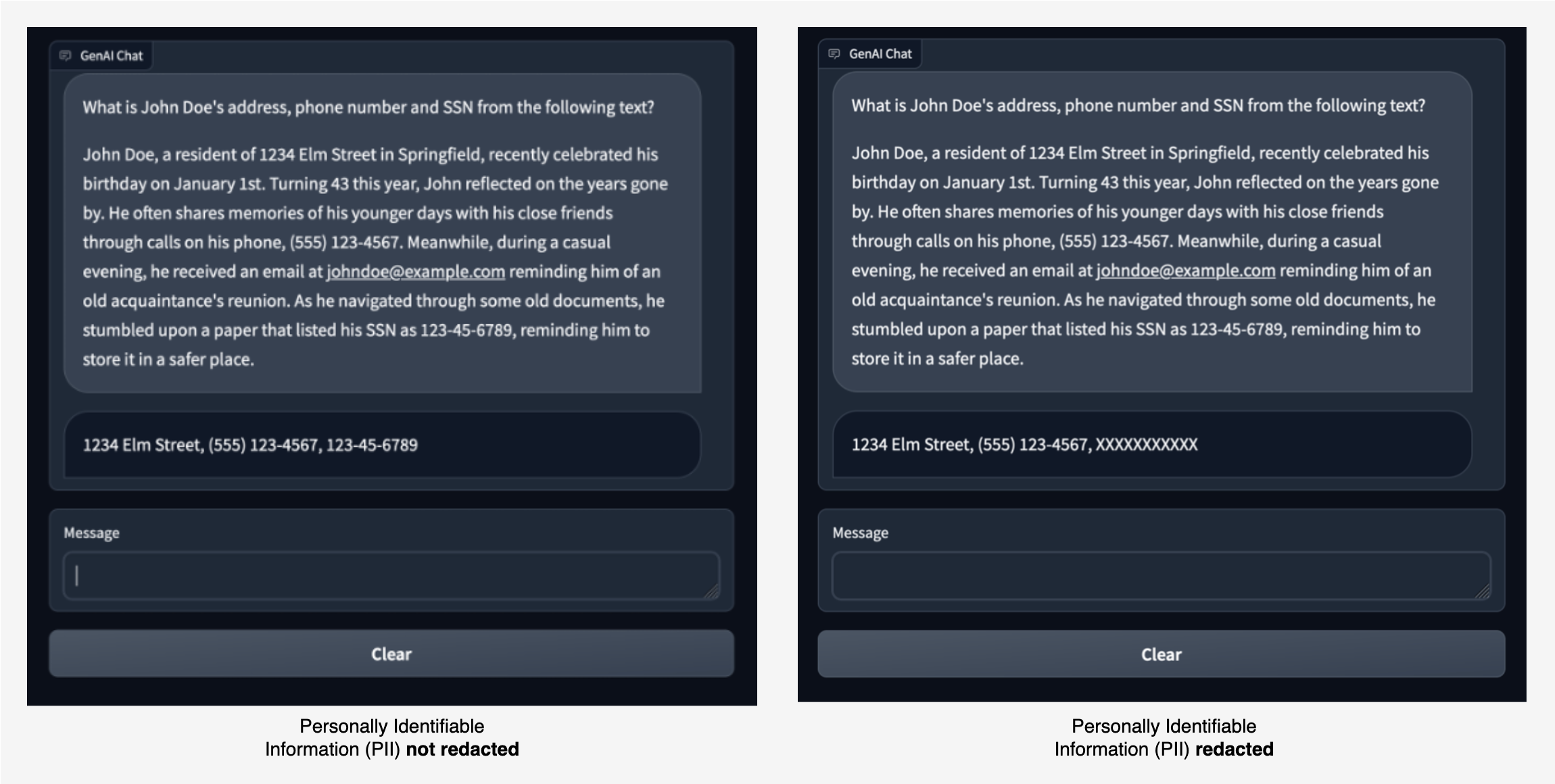
To demonstrate these capabilities, we built a sample chat application where we ask an LLM to extract PII entities such as address, phone number, and SSN from a given piece of text. The LLM finds and returns the appropriate PII entities, as shown in the image on the left.
With Amazon Comprehend moderation, we can redact the input to the LLM and output from the LLM. In the image on the right, the SSN value is allowed to be passed to the LLM without redaction. However, any SSN value in the LLM’s response is redacted.
The following is an example of how a prompt containing PII information can be prevented from reaching the LLM altogether. This example demonstrates a user asking a question that contains PII information. We use Amazon Comprehend moderation to detect PII entities in the prompt and show an error by interrupting the flow.
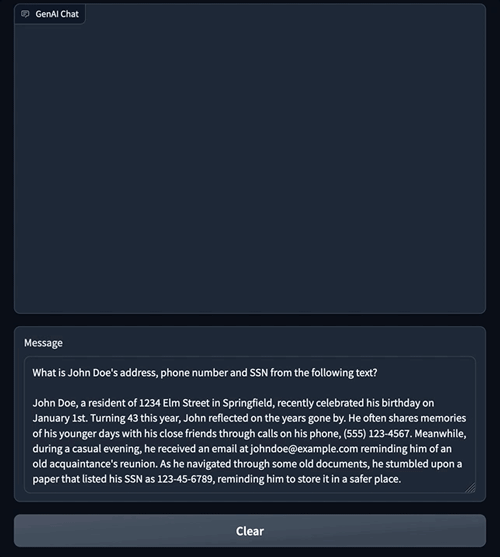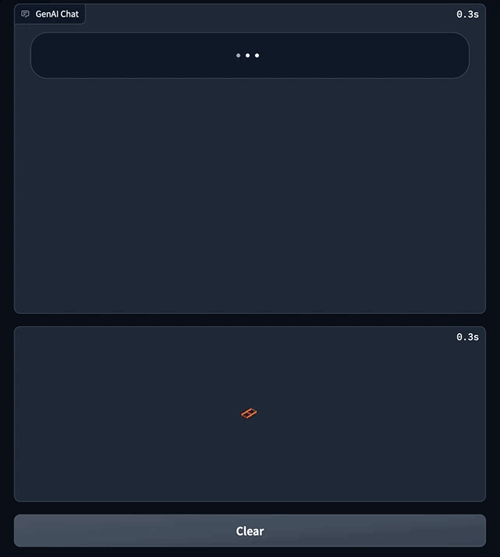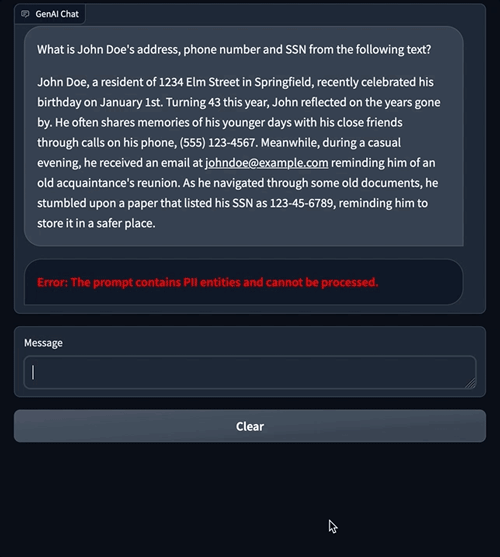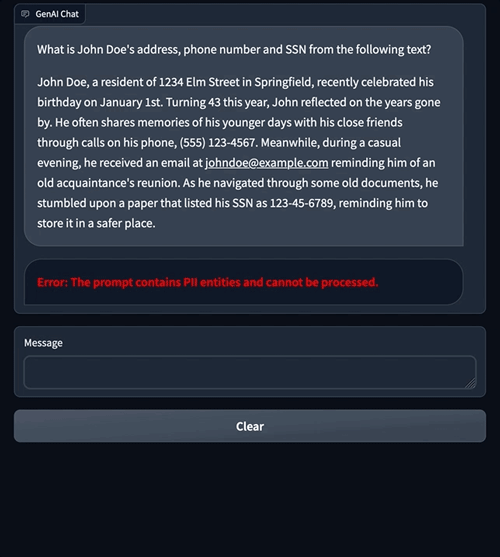
The preceding chat examples showcase how Amazon Comprehend moderation applies restrictions on data being sent to an LLM. In the following sections, we explain how this moderation mechanism is implemented using LangChain.
Integration with LangChain
With the endless possibilities of the application of LLMs into various use cases, it has become equally important to simplify the development of generative AI applications. LangChain is a popular open source framework that makes it effortless to develop generative AI applications. Amazon Comprehend moderation extends the LangChain framework to offer PII identification and redaction, toxicity detection, and prompt safety classification capabilities via AmazonComprehendModerationChain.
AmazonComprehendModerationChain is a custom implementation of the LangChain base chain interface. This means that applications can use this chain with their own LLM chains to apply the desired moderation to the input prompt as well as to the output text from the LLM. Chains can be built by merging numerous chains or by mixing chains with other components. You can use AmazonComprehendModerationChain with other LLM chains to develop complex AI applications in a modular and flexible manner.
To explain it further, we provide a few samples in the following sections. The source code for the AmazonComprehendModerationChain implementation can be found within the LangChain open source repository. For full documentation of the API interface, refer to the LangChain API documentation for the Amazon Comprehend moderation chain. Using this moderation chain is as simple as initializing an instance of the class with default configurations:
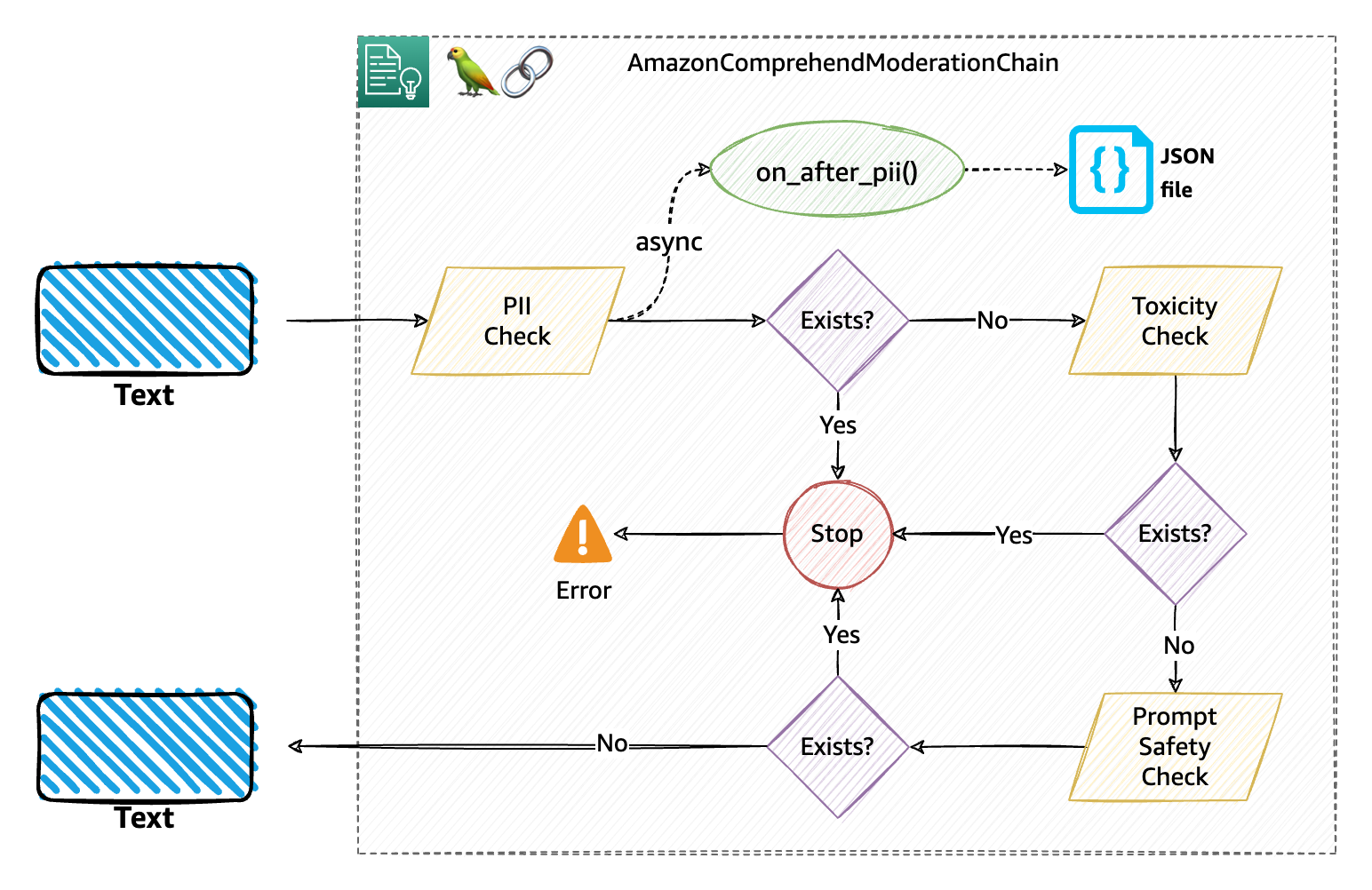
Behind the scenes, the moderation chain performs three consecutive moderation checks, namely PII, toxicity, and prompt safety, as explained in the following diagram. This is the default flow for the moderation.
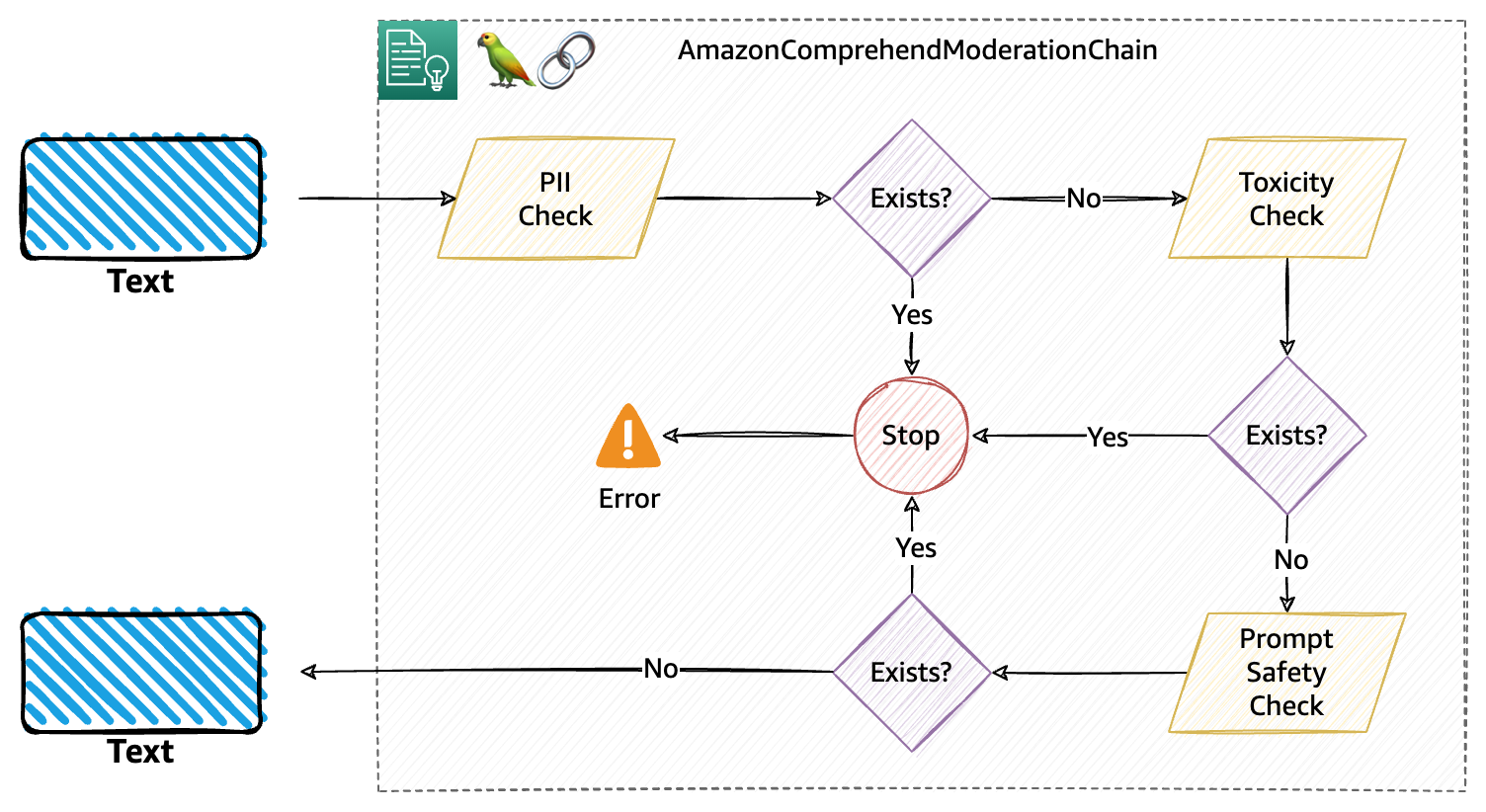
The following code snippet shows a simple example of using the moderation chain with the Amazon FalconLite LLM (which is a quantized version of the Falcon 40B SFT OASST-TOP1 model) hosted in Hugging Face Hub:
In the preceding example, we augment our chain with comprehend_moderation for both text going into the LLM and text generated by the LLM. This will perform default moderation that will check PII, toxicity, and prompt safety classification in that sequence.
Customize your moderation with filter configurations
You can use the AmazonComprehendModerationChain with specific configurations, which gives you the ability to control what moderations you wish to perform in your generative AI–based application. At the core of the configuration, you have three filter configurations available.
- ModerationPiiConfig – Used to configure PII filter.
- ModerationToxicityConfig – Used to configure toxic content filter.
- ModerationIntentConfig – Used to configure intent filter.
You can use each of these filter configurations to customize the behavior of how your moderations behave. Each filter’s configurations have a few common parameters, and some unique parameters, that they can be initialized with. After you define the configurations, you use the BaseModerationConfig class to define the sequence in which the filters must apply to the text. For example, in the following code, we first define the three filter configurations, and subsequently specify the order in which they must apply:
Let’s dive a little deeper to understand what this configuration achieves:
- First, for the toxicity filter, we specified a threshold of 0.6. This means that if the text contains any of the available toxic labels or entities with a score greater than the threshold, the whole chain will be interrupted.
- If there is no toxic content found in the text, a PII check is In this case, we’re interested in checking if the text contains SSN values. Because the
redactparameter is set toTrue, the chain will mask the detected SSN values (if any) where the SSN entitiy’s confidence score is greater than or equal to 0.5, with the mask character specified (X). Ifredactis set toFalse, the chain will be interrupted for any SSN detected. - Finally, the chain performs prompt safety classification, and will stop the content from propagating further down the chain if the content is classified with
UNSAFE_PROMPTwith a confidence score of greater than or equal to 0.8.
The following diagram illustrates this workflow.
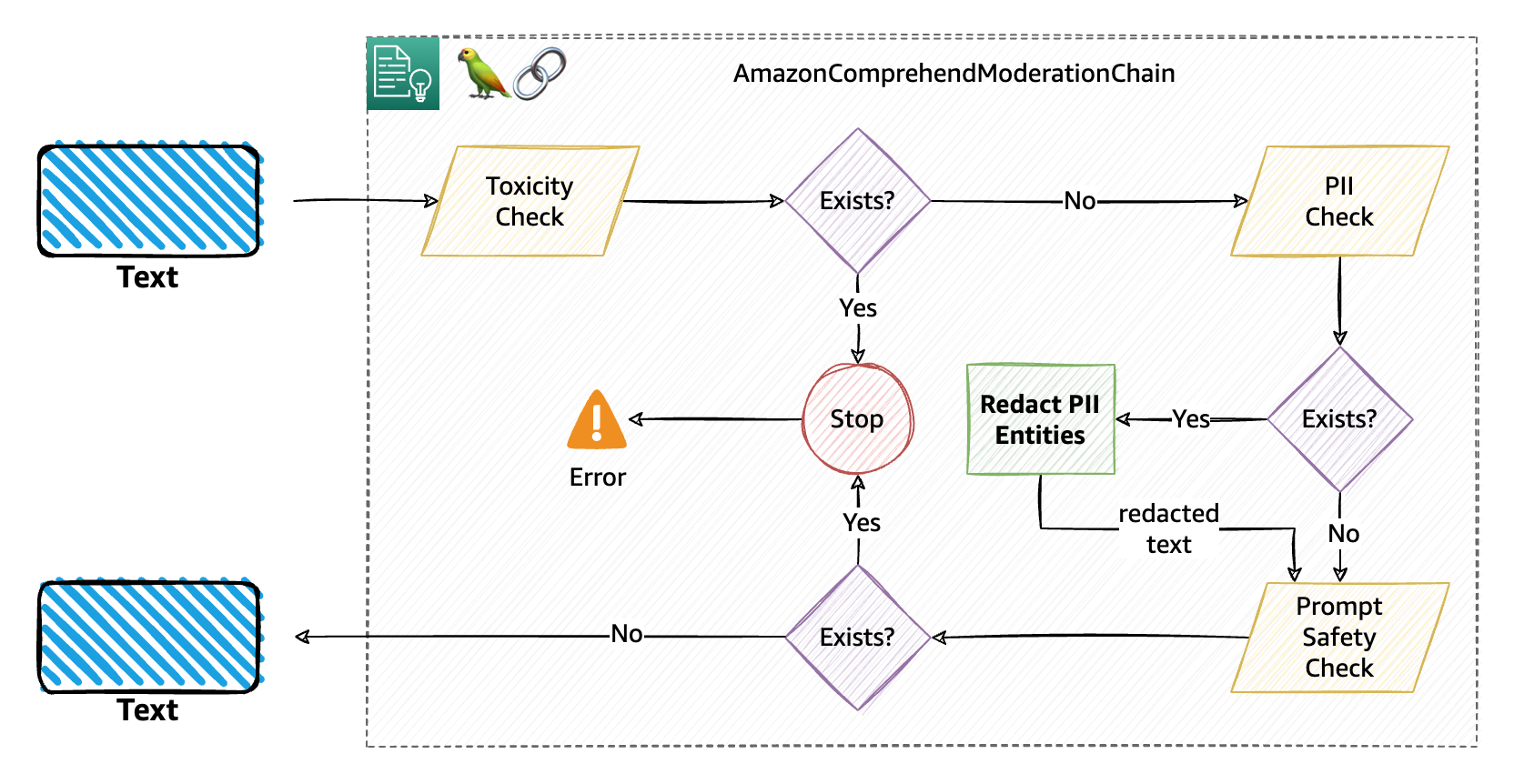
In case of interruptions to the moderation chain (in this example, applicable for the toxicity and prompt safety classification filters), the chain will raise a Python exception, essentially stopping the chain in progress and allowing you to catch the exception (in a try-catch block) and perform any relevant action. The three possible exception types are:
ModerationPIIErrorModerationToxicityErrorModerationPromptSafetyError
You can configure one filter or more than one filter using BaseModerationConfig. You can also have the same type of filter with different configurations within the same chain. For example, if your use case is only concerned with PII, you can specify a configuration that must interrupt the chain if in case an SSN is detected; otherwise, it must perform redaction on age and name PII entities. A configuration for this can be defined as follows:
Using callbacks and unique identifiers
If you’re familiar with the concept of workflows, you may also be familiar with callbacks. Callbacks within workflows are independent pieces of code that run when certain conditions are met within the workflow. A callback can either be blocking or nonblocking to the workflow. LangChain chains are, in essence, workflows for LLMs. AmazonComprehendModerationChain allows you to define your own callback functions. Initially, the implementation is limited to asynchronous (nonblocking) callback functions only.
This effectively means that if you use callbacks with the moderation chain, they will run independently of the chain’s run without blocking it. For the moderation chain, you get options to run pieces of code, with any business logic, after each moderation is run, independent of the chain.
You can also optionally provide an arbitrary unique identifier string when creating an AmazonComprehendModerationChain to enable logging and analytics later. For example, if you’re operating a chatbot powered by an LLM, you may want to track users who are consistently abusive or are deliberately or unknowingly exposing personal information. In such cases, it becomes necessary to track the origin of such prompts and perhaps store them in a database or log them appropriately for further action. You can pass a unique ID that distinctly identifies a user, such as their user name or email, or an application name that is generating the prompt.
The combination of callbacks and unique identifiers provides you with a powerful way to implement a moderation chain that fits your use case in a much more cohesive manner with less code that is easier to maintain. The callback handler is available via the BaseModerationCallbackHandler, with three available callbacks: on_after_pii(), on_after_toxicity(), and on_after_prompt_safety(). Each of these callback functions is called asynchronously after the respective moderation check is performed within the chain. These functions also receive two default parameters:
- moderation_beacon – A dictionary containing details such as the text on which the moderation was performed, the full JSON output of the Amazon Comprehend API, the type of moderation, and if the supplied labels (in the configuration) were found within the text or not
- unique_id – The unique ID that you assigned while initializing an instance of the
AmazonComprehendModerationChain.
The following is an example of how an implementation with callback works. In this case, we defined a single callback that we want the chain to run after the PII check is performed:
We then use the my_callback object while initializing the moderation chain and also pass a unique_id. You may use callbacks and unique identifiers with or without a configuration. When you subclass BaseModerationCallbackHandler, you must implement one or all of the callback methods depending on the filters you intend to use. For brevity, the following example shows a way to use callbacks and unique_id without any configuration:
The following diagram explains how this moderation chain with callbacks and unique identifiers works. Specifically, we implemented the PII callback that should write a JSON file with the data available in the moderation_beacon and the unique_id passed (the user’s email in this case).
In the following Python notebook, we have compiled a few different ways you can configure and use the moderation chain with various LLMs, such as LLMs hosted with Amazon SageMaker JumpStart and hosted in Hugging Face Hub. We have also included the sample chat application that we discussed earlier with the following Python notebook.
Conclusion
The transformative potential of large language models and generative AI is undeniable. However, their responsible and ethical use hinges on addressing concerns of trust and safety. By recognizing the challenges and actively implementing measures to mitigate risks, developers, organizations, and society at large can harness the benefits of these technologies while preserving the trust and safety that underpin their successful integration. Use Amazon Comprehend ContentModerationChain to add trust and safety features to any LLM workflow, including Retrieval Augmented Generation (RAG) workflows implemented in LangChain.
For information on building RAG based solutions using LangChain and Amazon Kendra’s highly accurate, machine learning (ML)-powered intelligent search, see – Quickly build high-accuracy Generative AI applications on enterprise data using Amazon Kendra, LangChain, and large language models. As a next step, refer to the code samples we created for using Amazon Comprehend moderation with LangChain. For full documentation of the Amazon Comprehend moderation chain API, refer to the LangChain API documentation.
About the authors
 Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service team. He works with AWS customers to help them adopt machine learning on a large scale. Outside of work, he enjoys reading and photography.
Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service team. He works with AWS customers to help them adopt machine learning on a large scale. Outside of work, he enjoys reading and photography.
 Anjan Biswas is a Senior AI Services Solutions Architect with a focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS AI services.
Anjan Biswas is a Senior AI Services Solutions Architect with a focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS AI services.
 Nikhil Jha is a Senior Technical Account Manager at Amazon Web Services. His focus areas include AI/ML, and analytics. In his spare time, he enjoys playing badminton with his daughter and exploring the outdoors.
Nikhil Jha is a Senior Technical Account Manager at Amazon Web Services. His focus areas include AI/ML, and analytics. In his spare time, he enjoys playing badminton with his daughter and exploring the outdoors.
 Chin Rane is an AI/ML Specialist Solutions Architect at Amazon Web Services. She is passionate about applied mathematics and machine learning. She focuses on designing intelligent document processing solutions for AWS customers. Outside of work, she enjoys salsa and bachata dancing.
Chin Rane is an AI/ML Specialist Solutions Architect at Amazon Web Services. She is passionate about applied mathematics and machine learning. She focuses on designing intelligent document processing solutions for AWS customers. Outside of work, she enjoys salsa and bachata dancing.