Artificial Intelligence
Category: Technical How-to

Build generative AI applications on Amazon Bedrock with the AWS SDK for Python (Boto3)
In this post, we demonstrate how to use Amazon Bedrock with the AWS SDK for Python (Boto3) to programmatically incorporate FMs. We explore invoking a specific FM and processing the generated text, showcasing the potential for developers to use these models in their applications for a variety of use cases

Governing the ML lifecycle at scale, Part 3: Setting up data governance at scale
This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product. It enables different business units within an organization to create, share, and govern their own data assets, promoting self-service analytics and reducing the time required to convert data experiments into production-ready applications.

Enhance speech synthesis and video generation models with RLHF using audio and video segmentation in Amazon SageMaker
In this post, we show you how to implement an audio and video segmentation solution using SageMaker Ground Truth. We guide you through deploying the necessary infrastructure using AWS CloudFormation, creating an internal labeling workforce, and setting up your first labeling job. By the end of this post, you will have a fully functional audio/video segmentation workflow that you can adapt for various use cases, from training speech synthesis models to improving video generation capabilities.
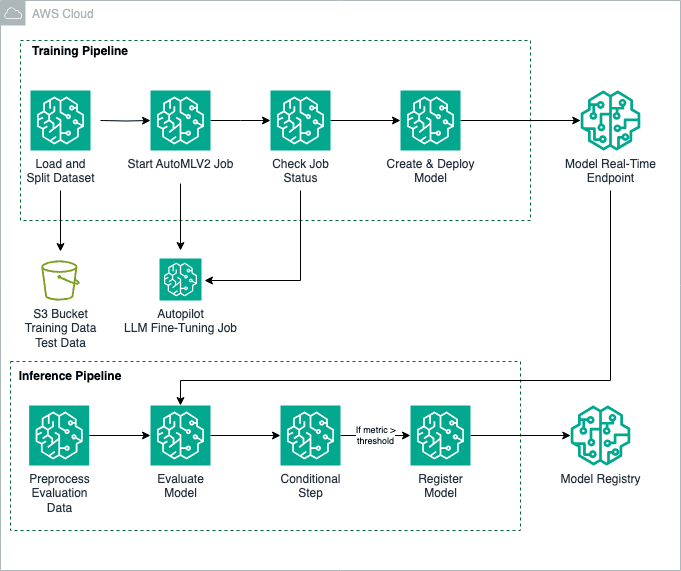
Fine-tune large language models with Amazon SageMaker Autopilot
Fine-tuning foundation models (FMs) is a process that involves exposing a pre-trained FM to task-specific data and fine-tuning its parameters. It can then develop a deeper understanding and produce more accurate and relevant outputs for that particular domain. In this post, we show how to use an Amazon SageMaker Autopilot training job with the AutoMLV2 […]
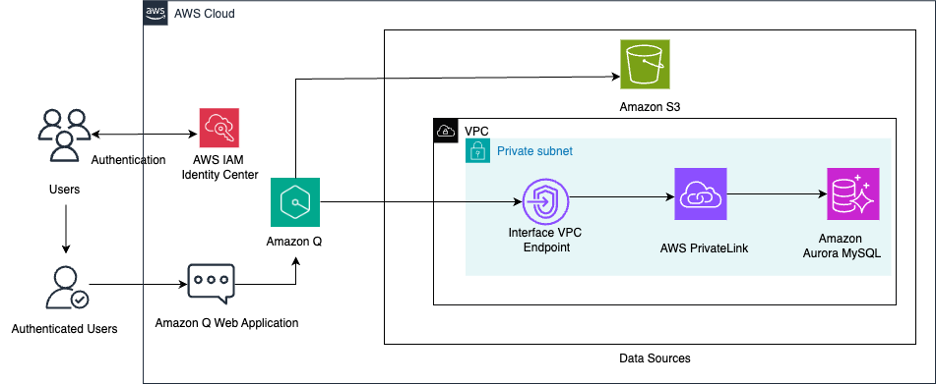
Unify structured data in Amazon Aurora and unstructured data in Amazon S3 for insights using Amazon Q
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. In this post, we explore how you can use Amazon […]

How FP8 boosts LLM training by 18% on Amazon SageMaker P5 instances
LLM training has seen remarkable advances in recent years, with organizations pushing the boundaries of what’s possible in terms of model size, performance, and efficiency. In this post, we explore how FP8 optimization can significantly speed up large model training on Amazon SageMaker P5 instances.

Automate emails for task management using Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases, and Amazon Bedrock Guardrails
In this post, we demonstrate how to create an automated email response solution using Amazon Bedrock and its features, including Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases, and Amazon Bedrock Guardrails.

Automate building guardrails for Amazon Bedrock using test-driven development
Amazon Bedrock Guardrails helps implement safeguards for generative AI applications based on specific use cases and responsible AI policies. Amazon Bedrock Guardrails assists in controlling the interaction between users and foundation models (FMs) by detecting and filtering out undesirable and potentially harmful content, while maintaining safety and privacy. In this post, we explore a solution that automates building guardrails using a test-driven development approach.
DXC transforms data exploration for their oil and gas customers with LLM-powered tools
In this post, we show you how DXC and AWS collaborated to build an AI assistant using large language models (LLMs), enabling users to access and analyze different data types from a variety of data sources. The AI assistant is powered by an intelligent agent that routes user questions to specialized tools that are optimized for different data types such as text, tables, and domain-specific formats. It uses the LLM’s ability to understand natural language, write code, and reason about conversational context.

Generate AWS Resilience Hub findings in natural language using Amazon Bedrock
This blog post discusses a solution that combines AWS Resilience Hub and Amazon Bedrock to generate architectural findings in natural language. By using the capabilities of Resilience Hub and Amazon Bedrock, you can share findings with C-suite executives, engineers, managers, and other personas within your corporation to provide better visibility over maintaining a resilient architecture.