Artificial Intelligence
Distributed training with Amazon EKS and Torch Distributed Elastic
Distributed deep learning model training is becoming increasingly important as data sizes are growing in many industries. Many applications in computer vision and natural language processing now require training of deep learning models, which are growing exponentially in complexity and are often trained with hundreds of terabytes of data. It then becomes important to use a vast cloud infrastructure to scale the training of such large models.
Developers can use open-source frameworks such as PyTorch to easily design intuitive model architectures. However, scaling the training of these models across multiple nodes can be challenging due to increased orchestration complexity.
Distributed model training mainly consists of two paradigms:
- Model parallel – In model parallel training, the model itself is so large that it can’t fit in the memory of a single GPU, and multiple GPUs are needed to train the model. The Open AI’s GPT-3 model with 175 billion trainable parameters (approximately 350 GB in size) is a good example of this.
- Data parallel – In data parallel training, the model can reside in a single GPU, but because the data is so large, it can take days or weeks to train a model. Distributing the data across multiple GPU nodes can significantly reduce the training time.
In this post, we provide an example architecture to train PyTorch models using the Torch Distributed Elastic framework in a distributed data parallel fashion using Amazon Elastic Kubernetes Service (Amazon EKS).
Prerequisites
To replicate the results reported in this post, the only prerequisite is an AWS account. In this account, we create an EKS cluster and an Amazon FSx for Lustre file system. We also push container images to an Amazon Elastic Container Registry (Amazon ECR) repository in the account. Instructions to set up these components are provided as needed throughout the post.
EKS clusters
Amazon EKS is a managed container service to run and scale Kubernetes applications on AWS. With Amazon EKS, you can efficiently run distributed training jobs using the latest Amazon Elastic Compute Cloud (Amazon EC2) instances without needing to install, operate, and maintain your own control plane or nodes. It is a popular orchestrator for machine learning (ML) and AI workflows. A typical EKS cluster in AWS looks like the following figure.

We have released an open-source project, AWS DevOps for EKS (aws-do-eks), which provides a large collection of easy-to-use and configurable scripts and tools to provision EKS clusters and run distributed training jobs. This project is built following the principles of the Do Framework: Simplicity, Flexibility, and Universality. You can configure your desired cluster by using the eks.conf file and then launch it by running the eks-create.sh script. Detailed instructions are provided in the GitHub repo.
Train PyTorch models using Torch Distributed Elastic
Torch Distributed Elastic (TDE) is a native PyTorch library for training large-scale deep learning models where it’s critical to scale compute resources dynamically based on availability. The TorchElastic Controller for Kubernetes is a native Kubernetes implementation for TDE that automatically manages the lifecycle of the pods and services required for TDE training. It allows for dynamically scaling compute resources during training as needed. It also provides fault-tolerant training by recovering jobs from node failure.
In this post, we discuss the steps to train PyTorch EfficientNet-B7 and ResNet50 models using ImageNet data in a distributed fashion with TDE. We use the PyTorch DistributedDataParallel API and the Kubernetes TorchElastic controller, and run our training jobs on an EKS cluster containing multiple GPU nodes. The following diagram shows the architecture diagram for this model training.
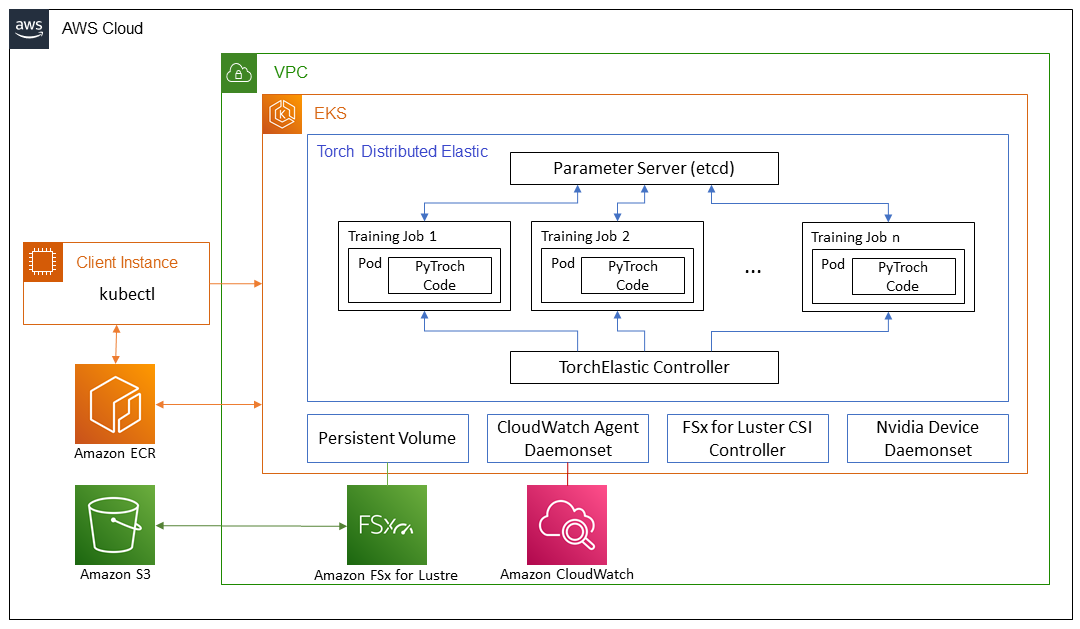
TorchElastic for Kubernetes consists mainly of two components: the TorchElastic Kubernetes Controller (TEC) and the parameter server (etcd). The controller is responsible for monitoring and managing the training jobs, and the parameter server keeps track of the worker nodes for distributed synchronization and peer discovery.
In order for the training pods to access the data, we need a shared data volume that can be mounted by each pod. Some options for shared volumes through Container Storage Interface (CSI) drivers included in AWS DevOps for EKS are Amazon Elastic File System (Amazon EFS) and FSx for Lustre.
Cluster setup
In our cluster configuration, we use one c5.2xlarge instance for system pods. We use three p4d.24xlarge instances as worker pods to train an EfficientNet model. For ResNet50 training, we use p3.8xlarge instances as worker pods. Additionally, we use an FSx shared file system to store our training data and model artifacts.
AWS p4d.24xlarge instances are equipped with Elastic Fabric Adapter (EFA) to provide networking between nodes. We discuss EFA more later in the post. To enable communication through EFA, we need to configure the cluster setup through a .yaml file. An example file is provided in the GitHub repository.
After this .yaml file is properly configured, we can launch the cluster using the script provided in the GitHub repo:
Refer to the GitHub repo for detailed instructions.
There is practically no difference between running jobs on p4d.24xlarge and p3.8xlarge. The steps described in this post work for both. The only difference is the availability of EFA on p4d.24xlarge instances. For smaller models like ResNet50, standard networking compared to EFA networking has minimal impact on the speed of training.
FSx for Lustre file system
FSx is designed for high-performance computing workloads and provides sub-millisecond latency using solid-state drive storage volumes. We chose FSx because it provided better performance as we scaled to a large number of nodes. An important detail to note is that FSx can only exist in a single Availability Zone. Therefore, all nodes accessing the FSx file system should exist in the same Availability Zone as the FSx file system. One way to achieve this is to specify the relevant Availability Zone in the cluster .yaml file for the specific node groups before creating the cluster. Alternatively, we can modify the network part of the auto scaling group for these nodes after the cluster is set up, and limit it to using a single subnet. This can be easily done on the Amazon EC2 console.
Assuming that the EKS cluster is up and running, and the subnet ID for the Availability Zone is known, we can set up an FSx file system by providing the necessary information in the fsx.conf file as described in the readme and running the deploy.sh script in the fsx folder. This sets up the correct policy and security group for accessing the file system. The script also installs the CSI driver for FSx as a daemonset. Finally, we can create the FSx persistent volume claim in Kubernetes by applying a single .yaml file:
This creates an FSx file system in the Availability Zone specified in the fsx.conf file, and also creates a persistent volume claim fsx-pvc, which can be mounted by any of the pods in the cluster in a read-write-many (RWX) fashion.
In our experiment, we used complete ImageNet data, which contains more that 12 million training images divided into 1,000 classes. The data can be downloaded from the ImageNet website. The original TAR ball has several directories, but for our model training, we’re only interested in ILSVRC/Data/CLS-LOC/, which includes the train and val subdirectories. Before training, we need to rearrange the images in the val subdirectory to match the directory structure required by the PyTorch ImageFolder class. This can be done using a simple Python script after the data is copied to the persistent volume in the next step.
To copy the data from an Amazon Simple Storage Service (Amazon S3) bucket to the FSx file system, we create a Docker image that includes scripts for this task. An example Dockerfile and a shell script are included in the csi folder within the GitHub repo. We can build the image using the build.sh script and then push it to Amazon ECR using the push.sh script. Before using these scripts, we need to provide the correct URI for the ECR repository in the .env file in the root folder of the GitHub repo. After we push the Docker image to Amazon ECR, we can launch a pod to copy the data by applying the relevant .yaml file:
The pod automatically runs the script data-prep.sh to copy the data from Amazon S3 to the shared volume. Because the ImageNet data has more than 12 million files, the copy process takes a couple of hours. The Python script imagenet_data_prep.py is also run to rearrange the val dataset as expected by PyTorch.
Network acceleration
We can use Elastic Fabric Adapter (EFA) in combination with supported EC2 instance types to accelerate network traffic between the GPU nodes in your cluster. This can be useful when running large distributed training jobs where standard network communication may be a bottleneck. Scripts to deploy and test the EFA device plugin in the EKS cluster that we use here are included in the efa-device-plugin folder in the GitHub repo. To enable a job with EFA in your EKS cluster, in addition to the cluster nodes having the necessary hardware and software, the EFA device plugin needs to be deployed to the cluster, and your job container needs to have compatible CUDA and NCCL versions installed.
To demonstrate running NCCL tests and evaluating the performance of EFA on p4d.24xlarge instances, we first must deploy the Kubeflow MPI operator by running the corresponding deploy.sh script in the mpi-operator folder. Then we run the deploy.sh script and update the test-efa-nccl.yaml manifest so limits and requests for resource vpc.amazonaws.com are set to 4. The four available EFA adapters in the p4d.24xlarge nodes get bundled together to provide maximum throughput.
Run kubectl apply -f ./test-efa-nccl.yaml to apply the test and then display the logs of the test pod. The following line in the log output confirms that EFA is being used:
The test results should look similar to the following output:
We can observe in the test results that the max throughput is about 42 GB/sec and average bus bandwidth is approximately 8 GB.
We also conducted experiments with a single EFA adapter enabled as well as no EFA adapters. All results are summarized in the following table.
| Number of EFA Adapters | Net/OFI Selected Provider | Avg. Bandwidth (GB/s) | Max. Bandwith (GB/s) |
| 4 | efa | 8.24 | 42.04 |
| 1 | efa | 3.02 | 5.89 |
| 0 | socket | 0.97 | 2.38 |
We also found that for relatively small models like ImageNet, the use of accelerated networking reduces the training time per epoch only with 5–8% at batch size of 64. For larger models and smaller batch sizes, when increased network communication of weights is needed, the use of accelerated networking has greater impact. We observed a decrease of epoch training time with 15–18% for training of EfficientNet-B7 with batch size 1. The actual impact of EFA on your training will depend on the size of your model.
GPU monitoring
Before running the training job, we can also set up Amazon CloudWatch metrics to visualize the GPU utilization during training. It can be helpful to know whether the resources are being used optimally or potentially identify resource starvation and bottlenecks in the training process.
The relevant scripts to set up CloudWatch are located in the gpu-metrics folder. First, we create a Docker image with amazon-cloudwatch-agent and nvidia-smi. We can use the Dockerfile in the gpu-metrics folder to create this image. Assuming that the ECR registry is already set in the .env file from the previous step, we can build and push the image using build.sh and push.sh. After this, running the deploy.sh script automatically completes the setup. It launches a daemonset with amazon-cloudwatch-agent and pushes various metrics to CloudWatch. The GPU metrics appear under the CWAgent namespace on the CloudWatch console. The rest of the cluster metrics show under the ContainerInsights namespace.
Model training
All the scripts needed for PyTorch training are located in the elasticjob folder in the GitHub repo. Before launching the training job, we need to run the etcd server, which is used by the TEC for worker discovery and parameter exchange. The deploy.sh script in the elasticjob folder does exactly that.
To take advantage of EFA in p4d.24xlarge instances, we need to use a specific Docker image available in the Amazon ECR Public Gallery that supports NCCL communication through EFA. We just need to copy our training code to this Docker image. The Dockerfile under the samples folder creates an image to be used when running training job on p4d instances. As always, we can use the build.sh and push.sh scripts in the folder to build and push the image.
The imagenet-efa.yaml file describes the training job. This .yaml file sets up the resources needed for running the training job and also mounts the persistent volume with the training data set up in the previous section.
A couple of things are worth pointing out here. The number of replicas should be set to the number of nodes available in the cluster. In our case, we set this to 3 because we had three p4d.24xlarge nodes. In the imagenet-efa.yaml file, the nvidia.com/gpu parameter under resources and nproc_per_node under args should be set to the number of GPUs per node, which in the case of p4d.24xlarge is 8. Also, the worker argument for the Python script sets the number of CPUs per process. We chose this to be 4 because, in our experiments, this provides optimal performance when running on p4d.24xlarge instances. These settings are necessary in order to maximize the use of all the hardware resources available in the cluster.
When the job is running, we can observe the GPU usage in CloudWatch for all the GPUs in the cluster. The following is an example from one of our training jobs with three p4d.24xlarge nodes in the cluster. Here we’ve selected one GPU from each node. With the settings mentioned earlier, the GPU usage is close to 100% during the training phase of the epoch for all of the nodes in the cluster.

For training a ResNet50 model using p3.8xlarge instances, we need exactly the same steps as described for the EfficientNet training using p4d.24xlarge. We can also use the same Docker image. As mentioned earlier, p3.8xlarge instances aren’t equipped with EFA. However, for the ResNet50 model, this is not a significant drawback. The imagenet-fsx.yaml script provided in the GitHub repository sets up the training job with appropriate resources for the p3.8xlarge node type. The job uses the same dataset from the FSx file system.
GPU scaling
We ran some experiments to observe how the training time scales for the EfficientNet-B7 model by increasing the number of GPUs. To do this, we changed the number of replicas from 1 to 3 in our training .yaml file for each training run. We only observed the time for a single epoch while using the complete ImageNet dataset. The following figure shows the results for our GPU scaling experiment. The red dotted line represents how the training time should go down from a run using 8 GPUs by increasing the number of GPUs. As we can see, the scaling is quite close to what is expected.

Similarly, we obtained the GPU scaling plot for ResNet50 training on p3.8xlarge instances. For this case, we changed the replicas in our .yaml file from 1 to 4. The results of this experiment are shown in the following figure.

Clean up
It’s important to spin down resources after model training in order to avoid costs associated with running idle instances. With each script that creates resources, the GitHub repo provides a matching script to delete them. To clean up our setup, we must delete the FSx file system before deleting the cluster because it’s associated with a subnet in the cluster’s VPC. To delete the FSx file system, we just need to run the following command (from inside the fsx folder):
Note that this will not only delete the persistent volume, it will also delete the FSx file system, and all the data on the file system will be lost. When this step is complete, we can delete the cluster by using the following script in the eks folder:
This will delete all the existing pods, remove the cluster, and delete the VPC created in the beginning.
Conclusion
In this post, we detailed the steps needed for running PyTorch distributed data parallel model training on EKS clusters. This task may seem daunting, but the AWS DevOps for EKS project created by the ML Frameworks team at AWS provides all the necessary scripts and tools to simplify the process and make distributed model training easily accessible.
For more information on the technologies used in this post, visit Amazon EKS and Torch Distributed Elastic. We encourage you to apply the approach described here to your own distributed training use cases.
Resources
- Amazon EC2 Instance Types
- Machine Learning on Amazon EKS
- Running TorchServe on Amazon Elastic Kubernetes Service
- Distributed Model Training Workshop for AWS EKS
About the authors
 Imran Younus is a Principal Solutions Architect for ML Frameworks team at AWS. He focuses on large scale machine learning and deep learning workloads across AWS services like Amazon EKS and AWS ParallelCluster. He has extensive experience in applications of Deep Leaning in Computer Vision and Industrial IoT. Imran obtained his PhD in High Energy Particle Physics where he has been involved in analyzing experimental data at peta-byte scales.
Imran Younus is a Principal Solutions Architect for ML Frameworks team at AWS. He focuses on large scale machine learning and deep learning workloads across AWS services like Amazon EKS and AWS ParallelCluster. He has extensive experience in applications of Deep Leaning in Computer Vision and Industrial IoT. Imran obtained his PhD in High Energy Particle Physics where he has been involved in analyzing experimental data at peta-byte scales.
 Alex Iankoulski is a full-stack software and infrastructure architect who likes to do deep, hands-on work. He is currently a Principal Solutions Architect for Self-managed Machine Learning at AWS. In his role he focuses on helping customers with containerization and orchestration of ML and AI workloads on container-powered AWS services. He is also the author of the open source Do framework and a Docker captain who loves applying container technologies to accelerate the pace of innovation while solving the world’s biggest challenges. During the past 10 years, Alex has worked on combating climate change, democratizing AI and ML, making travel safer, healthcare better, and energy smarter.
Alex Iankoulski is a full-stack software and infrastructure architect who likes to do deep, hands-on work. He is currently a Principal Solutions Architect for Self-managed Machine Learning at AWS. In his role he focuses on helping customers with containerization and orchestration of ML and AI workloads on container-powered AWS services. He is also the author of the open source Do framework and a Docker captain who loves applying container technologies to accelerate the pace of innovation while solving the world’s biggest challenges. During the past 10 years, Alex has worked on combating climate change, democratizing AI and ML, making travel safer, healthcare better, and energy smarter.