Artificial Intelligence
How Amazon Search increased ML training twofold using AWS Batch for Amazon SageMaker Training jobs
In this post, we show you how Amazon Search optimized GPU instance utilization by leveraging AWS Batch for SageMaker Training jobs. This managed solution enabled us to orchestrate machine learning (ML) training workloads on GPU-accelerated instance families like P5, P4, and others. We will also provide a step-by-step walkthrough of the use case implementation.
Machine learning at Amazon Search
At Amazon Search, we use hundreds of GPU-accelerated instances to train and evaluate ML models that help our customers discover products they love. Scientists typically train more than one model at a time to find the optimal set of features, model architecture, and hyperparameter settings that optimize the model’s performance. We previously leveraged a first-in-first-out (FIFO) queue to coordinate model training and evaluation jobs. However, we needed to employ a more nuanced criteria to prioritize which jobs should run in what order. Production models needed to run with high priority, exploratory research as medium priority, and hyperparameter sweeps and batch inference as low priority. We also needed a system that could handle interruptions. Should a job fail, or a given instance type become saturated, we needed the job to run on other available compatible instance types while respecting the overall prioritization criteria. Finally, we wanted a managed solution so we could focus more on model development instead of managing infrastructure.
After evaluating multiple options, we chose AWS Batch for Amazon SageMaker Training jobs because it best met our requirements. This solution seamlessly integrated AWS Batch with Amazon SageMaker and allowed us to run jobs per our prioritization criteria. This allows applied scientists to submit multiple concurrent jobs without manual resource management. By leveraging AWS Batch features such as advanced prioritization through fair-share scheduling, we increased peak utilization of GPU-accelerated instances from 40% to over 80%.
Amazon Search: AWS Batch for SageMaker Training Job implementation
We leveraged three AWS technologies to set up our job queue. We used Service Environments to configure the SageMaker AI parameters that AWS Batch uses to submit and manage SageMaker Training jobs. We used Share Identifiers to prioritize our workloads. Finally, we used Amazon CloudWatch to monitor and the provision of alerting capability for critical events or deviations from expected behavior. Let’s dive deep into these constructs.
Service environments. We set up service environments to represent the total GPU capacity available for each instance family, such as P5s and P4s. Each service environment was configured with fixed limits based on our team’s reserved capacity in AWS Batch. Note that for teams using SageMaker Training Plans, these limits can be set to the number of reserved instances, making capacity planning more straightforward. By defining these boundaries, we established how the total GPU instance capacity within a service environment was distributed across different production jobs. Each production experiment was allocated a portion of this capacity through Share Identifiers.
Figure 1 provides a real-world example of how we used AWS Batch’s fair-share scheduling to divide 100 GPU instance between ShareIDs. We allocated 60 instances to ProdExp1, and 40 to ProdExp2. When ProdExp2 used only 25 GPU instances, the remaining 15 could be borrowed by ProdExp1, allowing it to scale up to 75 GPU instances. When ProdExp2 later needed its full 40 GPU instances, the scheduler preempted jobs from ProdExp1 to restore balance. This example used the P4 instance family, but the same approach could apply to any SageMaker-supported EC2 instance family. This ensured that production workloads have guaranteed access to their assigned capacity, while exploratory or ad-hoc experiments could still make use of any idle GPU instances. This design safeguarded critical workloads and improved overall instance utilization by ensuring that no reserved capacity went unused.
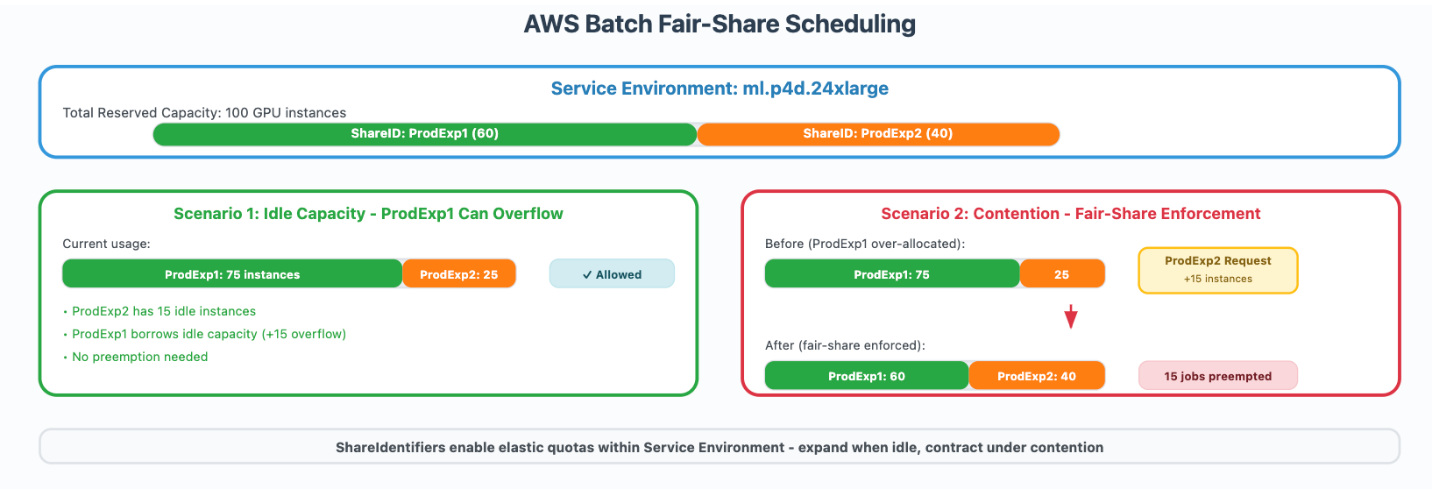
Figure 1: AWS Batch fair-share scheduling
Share Identifiers. We used Share Identifiers to allocate fractions of a service environment’s capacity to production experiments. Share Identifiers are string tags applied at job submission time. AWS Batch used these tags to track usage and enforce fair-share scheduling. For initiatives that required dedicated capacity, we defined preset Share Identifiers with quotas in AWS Batch. This reserved capacity for production tracks. These quotas acted as fairness targets rather than hard limits. Idle capacity could still be borrowed, but under contention, AWS Batch enforced fairness by preempting resources from overused identifiers and reassigned them to underused ones.
Within each Share Identifier, job priorities ranging from 0 to 99 determined execution order, but priority-based preemption only triggered when the ShareIdentifier reached its allocated capacity limit. Figure 2 illustrates how we setup and used our share identifiers. ProdExp1 had 60 p4d instances and ran jobs at various priorities. Job A had a priority of 80, Job B was set to 50, Job C was set to at 30, and Job D had a priority 10. When all 60 instances were occupied and a new high-priority job (priority 90) requiring 15 instances was submitted, the system preempted the lowest priority running job (Job D) to make room, while maintaining the total of 60 instances for that Share Identifier.
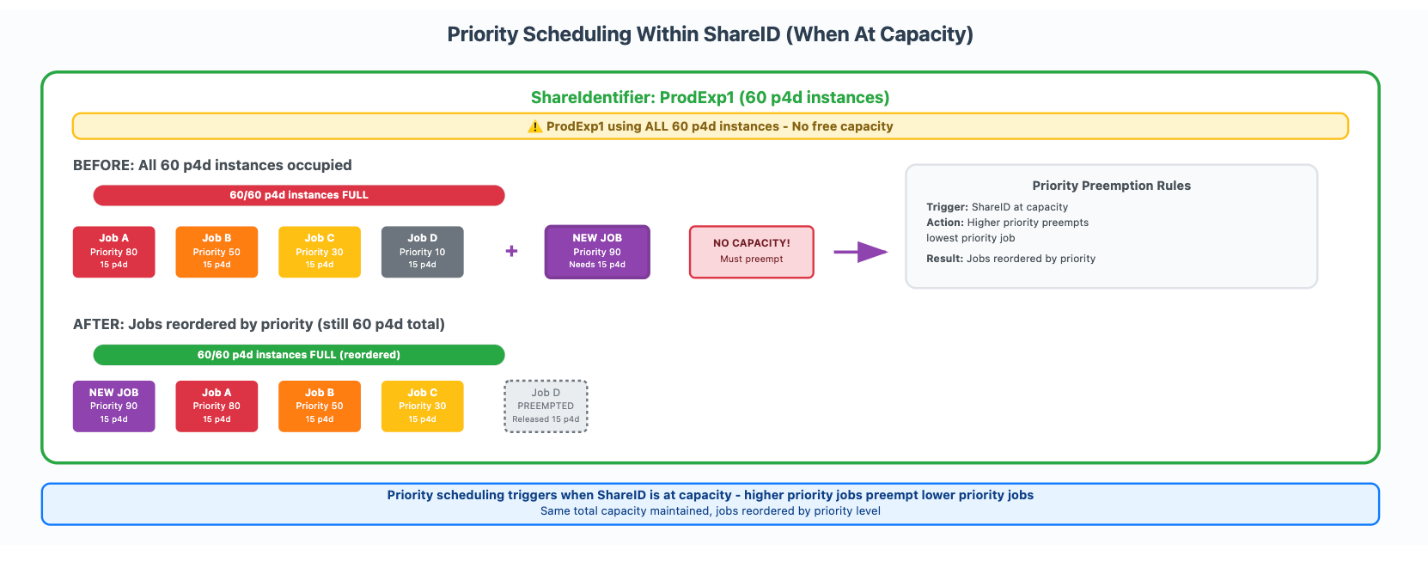
Figure 2: Priority scheduling within a Share ID
Amazon CloudWatch. We used Amazon CloudWatch to instrument our SageMaker training jobs. SageMaker automatically publishes metrics on job progress and resource utilization, while AWS Batch provides detailed information on job scheduling and execution. With AWS Batch, we queried the status of each job through the AWS Batch APIs. This made it possible to track jobs as they transitioned through states such as SUBMITTED, PENDING, RUNNABLE, STARTING, RUNNING, SUCCEEDED, and FAILED. We published these metrics and job states to CloudWatch and configured dashboards and alarms to alert anytime we encountered extended wait times, unexpected failures, or underutilized resources. This built-in integration provided both real-time visibility and historical trend analysis, which helped our team maintain operational efficiency across GPU clusters without building custom monitoring systems.
Operational impact on team performance
By adopting AWS Batch for SageMaker Training jobs, we enabled experiments to run without concerns about resource availability or contention. Researchers could submit jobs without waiting for manual scheduling, which increased the number of experiments that could be run in parallel. This led to shorter queue times, higher GPU utilization, and faster turnaround of training results, directly improving both research throughput and delivery timelines.
How to set up AWS Batch for SageMaker Training jobs
To set up a similar environment, you can follow this tutorial, which shows you how to orchestrate multiple GPU large language model (LLM) fine-tuning jobs using multiple GPU-powered instances. The solution is also available on GitHub.
Prerequisites
To orchestrate multiple SageMaker Training jobs with AWS Batch, first you need to complete the following prerequisites:
Clone the GitHub repository with the assets for this deployment. This repository consists of notebooks that reference assets:
Create AWS Batch resources
To create the necessary resources to manage SageMaker Training job queues with AWS Batch, we provide utility functions in the example to automate the creation of the Service Environment, Scheduling Policy, and Job Queue.
The service environment represents the Amazon SageMaker AI capacity limits available to schedule, expressed by maximum number of instances. The scheduling policy indicates how resource computes are allocated in a job queue between users or workloads. The job queue is the scheduler interface that researchers interact with to submit jobs and interrogate job status. AWS Batch provides two different queues we can operate with:
- FIFO queues – Queues in which no scheduling policies are required
- Fair-share queues – Queues in which a scheduling policy Amazon Resource Name (ARN) is required to orchestrate the submitted jobs
We recommend creating dedicated service environments for each job queue in a 1:1 ratio. FIFO queues provide basic message delivery, while fair-share scheduling (FSS) queues provide more sophisticated scheduling, balancing utilization within a Share Identifier, share weights, and job priority. For customers who don’t need multiple shares but would like the ability to assign a priority on job submission, we recommend creating an FSS queue and using a single share within it for all submissions.To create the resources, execute the following commands:
You can navigate the AWS Batch Dashboard, shown in the following screenshot, to explore the created resources.
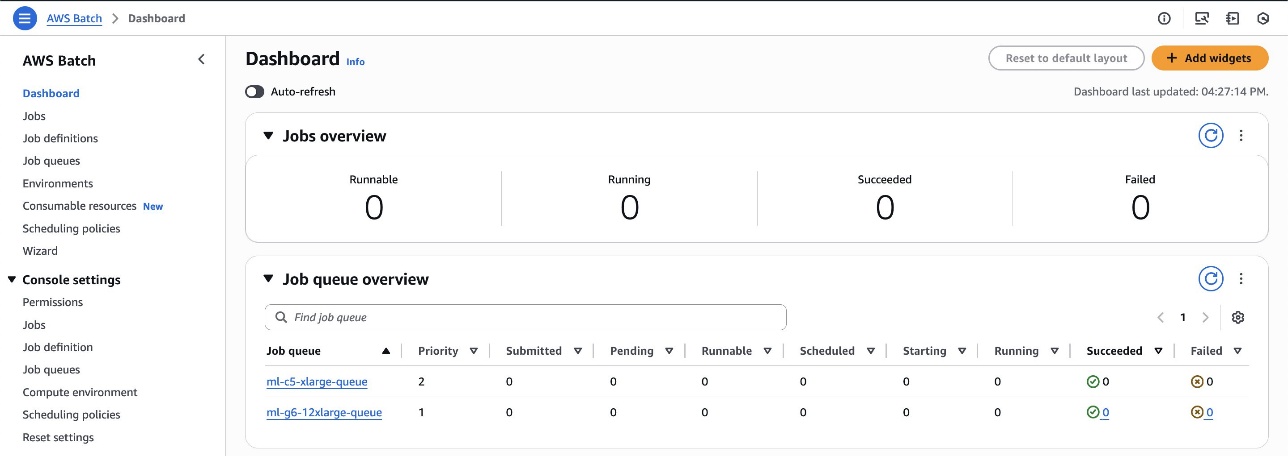
This automation script created two queues:
ml-c5-xlarge-queue– A FIFO queue with priority 2 used for CPU workloadsml-g6-12xlarge-queue– A fair-share queue with priority 1 used for GPU workloads
The associated scheduling policy for the queue ml-g6-12xlarge-queue is with share attributes such as High priority (HIGHPRI), Medium priority (MIDPRI) and Low priority (LOWPRI) along with the queue weights. Users can submit jobs and assign them to one of three shares: HIGHPRI, MIDPRI, or LOWPRI and assign weights such as 1 for high priority and 3 for medium and 5 for low priority. Below is the screenshot showing the scheduling policy details:
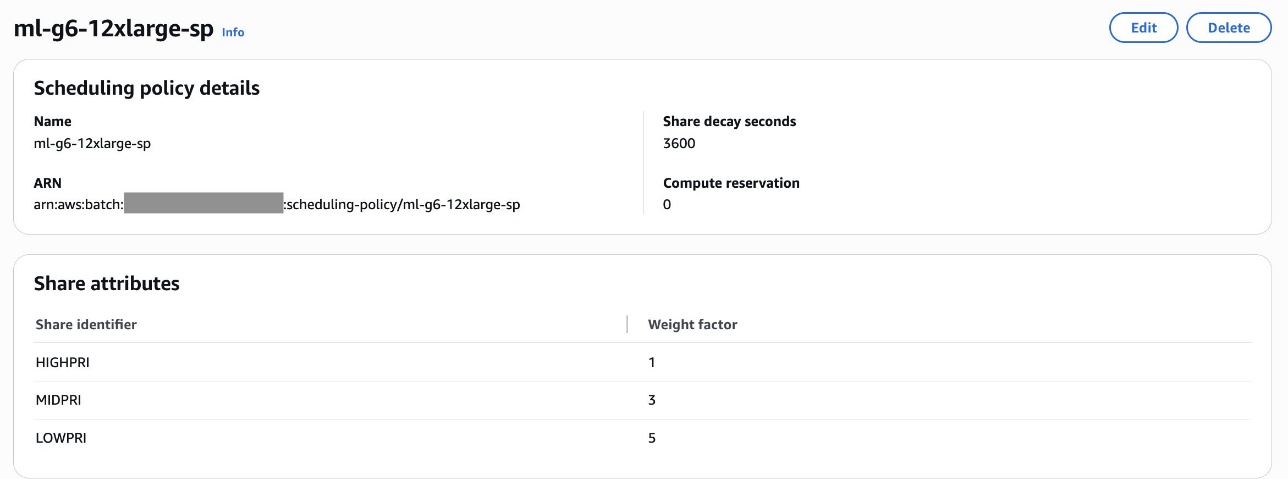
For instructions on how to set up the service environment and a job queue, refer to the Getting started section in Introducing AWS Batch support for SageMaker Training Jobs blog.
Run LLM fine-tuning jobs on SageMaker AI
We run the notebook notebook.ipynb to start submitting SageMaker Training jobs with AWS Batch. The notebook contains the code to prepare the data used for the workload, upload on Amazon Simple Storage Service (Amazon S3), and define the hyperparameters required by the job to be executed.
To run the fine-tuning workload using SageMaker Training jobs, this example uses the ModelTrainer class. The ModelTrainer class is a newer and more intuitive approach to model training that significantly enhances user experience. It supports distributed training, build your own container (BYOC), and recipes.
For additional information about ModelTrainer, you can refer to Accelerate your ML lifecycle using the new and improved Amazon SageMaker Python SDK – Part 1: ModelTrainer.
To set up the fine-tuning workload, complete the following steps:
- Select the instance type, the container image for the training job, and define the checkpoint path where the model will be stored:
- Create the ModelTrainer function to encapsulate the training setup. The ModelTrainer class simplifies the experience by encapsulating code and training setup. In this example:
SourceCode– The source code configuration. This is used to configure the source code for running the training job by using your local python scripts.Compute– The compute configuration. This is used to specify the compute resources for the training job.
- Set up the input channels for ModelTrainer by creating InputData objects from the provided S3 bucket paths for the training and validation datasets:
Queue SageMaker Training jobs
This section and the following are intended to be used interactively so that you can explore how to use the Amazon SageMaker Python SDK to submit jobs to your Batch queues. Follow these steps:
- Select the queue to use:
- In the next cell, submit two training jobs in the queue:
LOW PRIORITYMEDIUM PRIORITY
- Use the API
submitto submit all the jobs:
Display the status of running and in queue jobs
We can use the job queue list and job queue snapshot APIs to programmatically view a snapshot of the jobs that the queue will run next. For fair-share queues, this ordering is dynamic and occasionally needs to be refreshed because new jobs are submitted to the queue or as share usage changes over time.
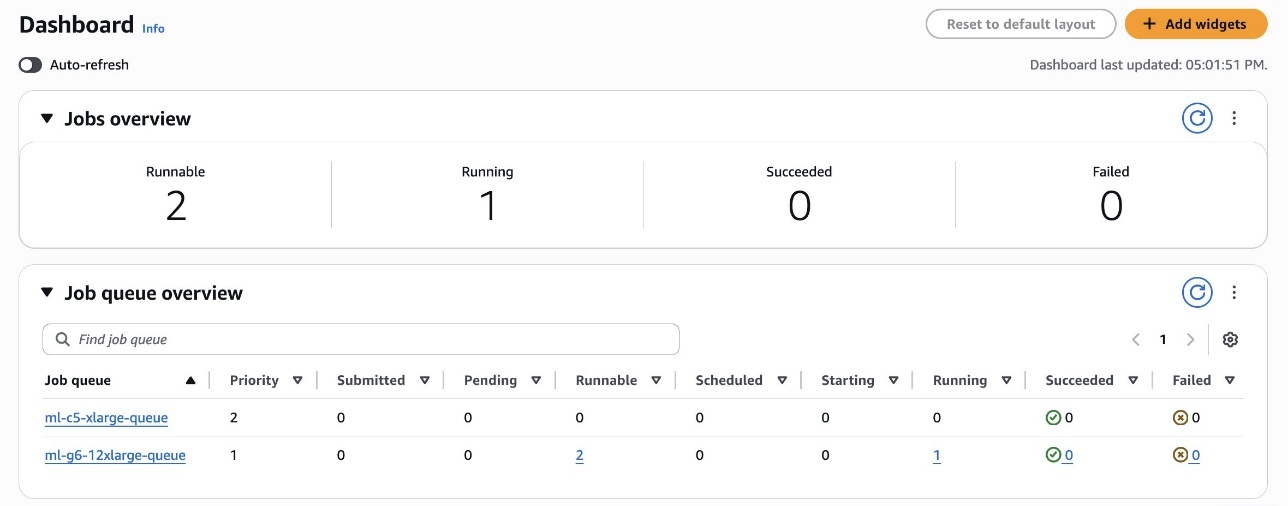
The following screenshot shows the jobs submitted with low priority and medium priority in the Runnable State and in the queue.
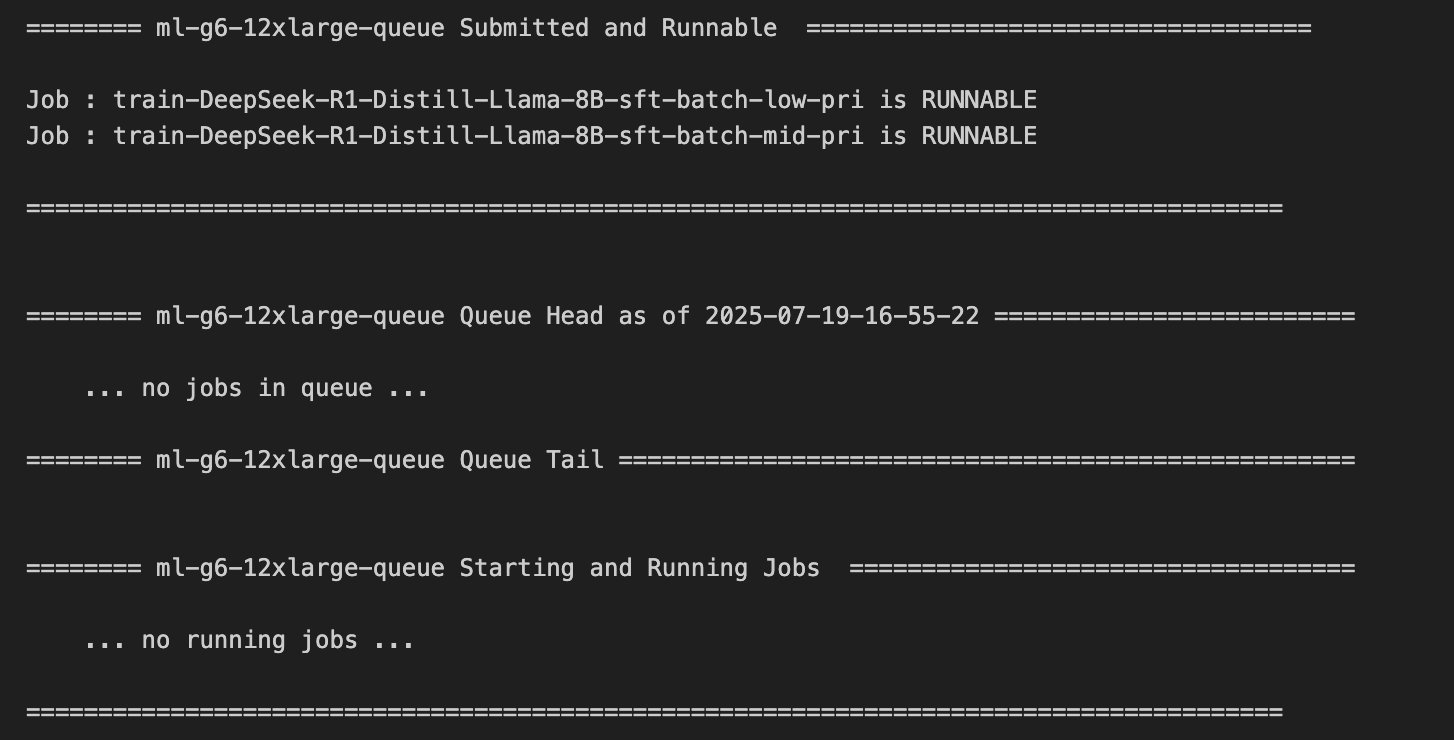
You can also refer to the AWS Batch Dashboard, shown in the following screenshot, to analyze the status of the jobs.
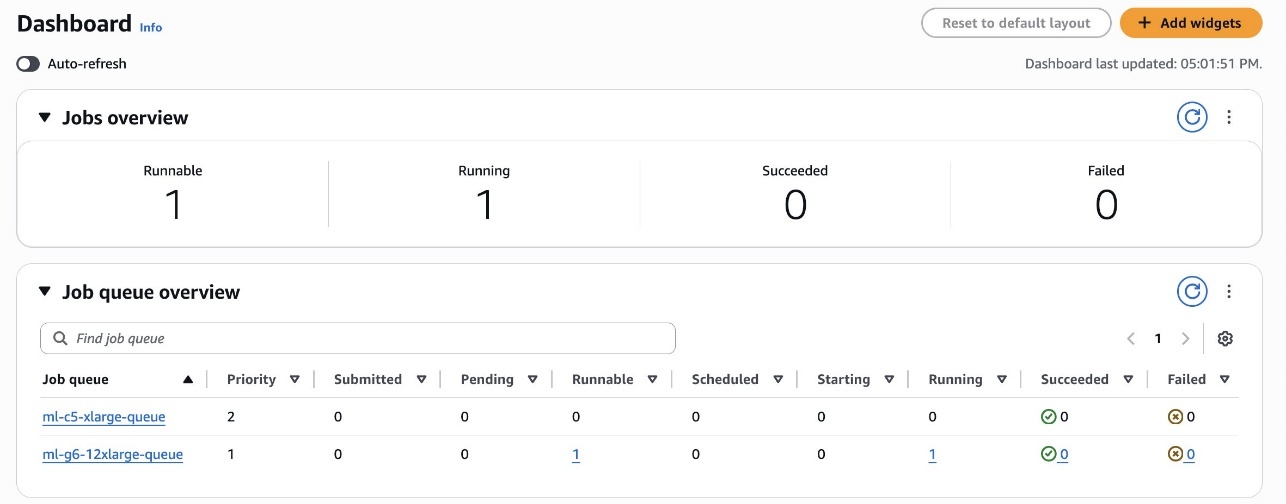
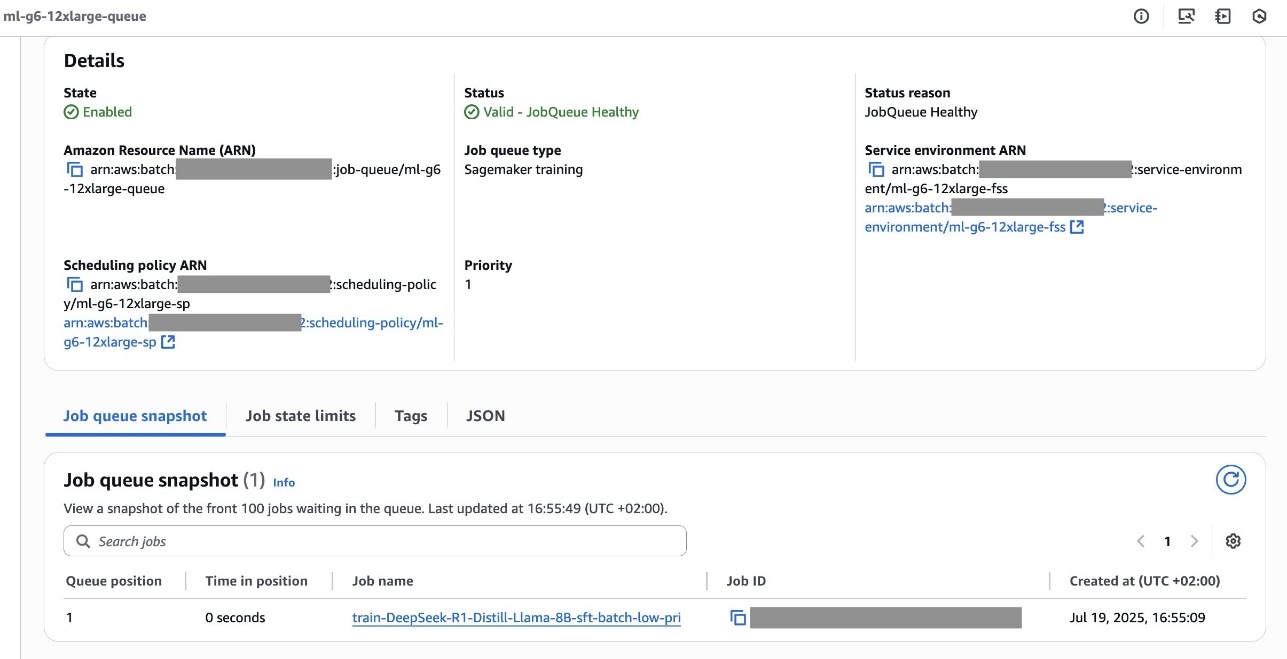
As shown in the following screenshot, the first job executed with the SageMaker Training job is the MEDIUM PRIORITY one, by respecting the scheduling policy rules defined previously.
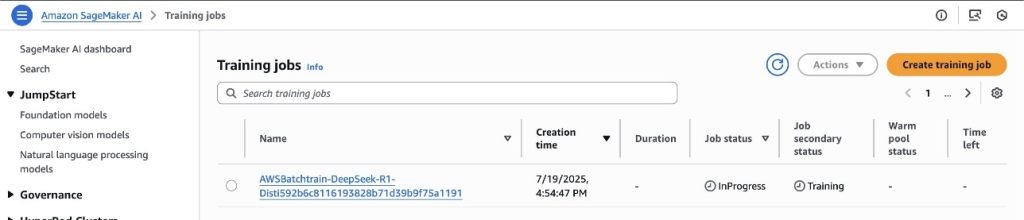
You can explore the running training job in the SageMaker AI console, as shown in the following screenshot.
Submit an additional job
You can now submit an additional SageMaker Training job with HIGH PRIORITY to the queue:
You can explore the status from the dashboard, as shown in the following screenshot.
The HIGH PRIORITY job, despite being submitted later in the queue, will be executed before the other runnable jobs by respecting the scheduling policy rules, as shown in the following screenshot.
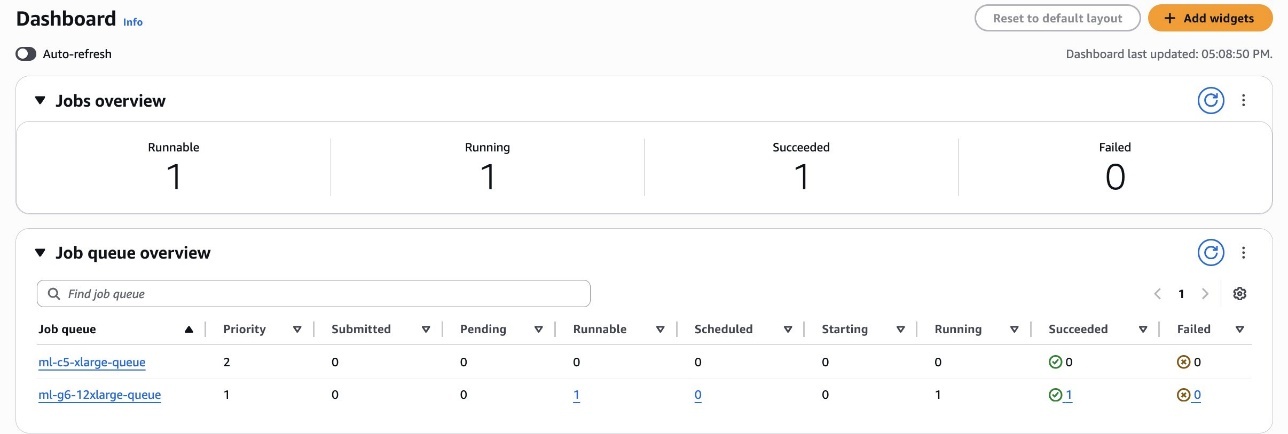
As the scheduling policy in the screenshot shows, the LOWPRI share has a higher weight factor (5) than the MIDPRI share (3). Since a lower weight signifies higher priority, a LOWPRI job will be executed after a MIDPRI job, even if they are submitted at the same time.

Clean up
To clean up your resources to avoid incurring future charges, follow these steps:
- Verify that your training job isn’t running anymore. To do so, on your SageMaker console, choose Training and check Training jobs.
- Delete AWS Batch resources by using the command
python create_resources.py --cleanfrom the GitHub example or by manually deleting them from the AWS Management Console.
Conclusion
In this post, we demonstrated how Amazon Search used AWS Batch for SageMaker Training Jobs to optimize GPU resource utilization and training job management. The solution transformed their training infrastructure by implementing sophisticated queue management and fair share scheduling, increasing peak GPU utilization from 40% to over 80%.We recommend that organizations facing similar ML training infrastructure challenges explore AWS Batch integration with SageMaker, which provides built-in queue management capabilities and priority-based scheduling. The solution eliminates manual resource coordination while providing workloads with appropriate prioritization through configurable scheduling policies.
To begin implementing AWS Batch with SageMaker Training jobs, you can access our sample code and implementation guide in the amazon-sagemaker-examples repository on GitHub. The example demonstrates how to set up AWS Identity and Access Management (IAM) permissions, create AWS Batch resources, and orchestrate multiple GPU-powered training jobs using ModelTrainer class.
The authors would like to thank Charles Thompson and Kanwaljit Khurmi for their collaboration.