Artificial Intelligence
How Harmonic Security improved their data-leakage detection system with low-latency fine-tuned models using Amazon SageMaker, Amazon Bedrock, and Amazon Nova Pro
This post was written with Bryan Woolgar-O’Neil, Jamie Cockrill and Adrian Cunliffe from Harmonic Security
Organizations face increasing challenges protecting sensitive data while supporting third-party generative AI tools. Harmonic Security, a cybersecurity company, developed an AI governance and control layer that spots sensitive data in line as employees use AI, giving security teams the power to keep PII, source code, and payroll information safe while the business accelerates.
The following screenshot demonstrates Harmonic Security’s software tool, highlighting the different data leakage detection types, including Employee PII, Employee Financial Information, and Source Code.
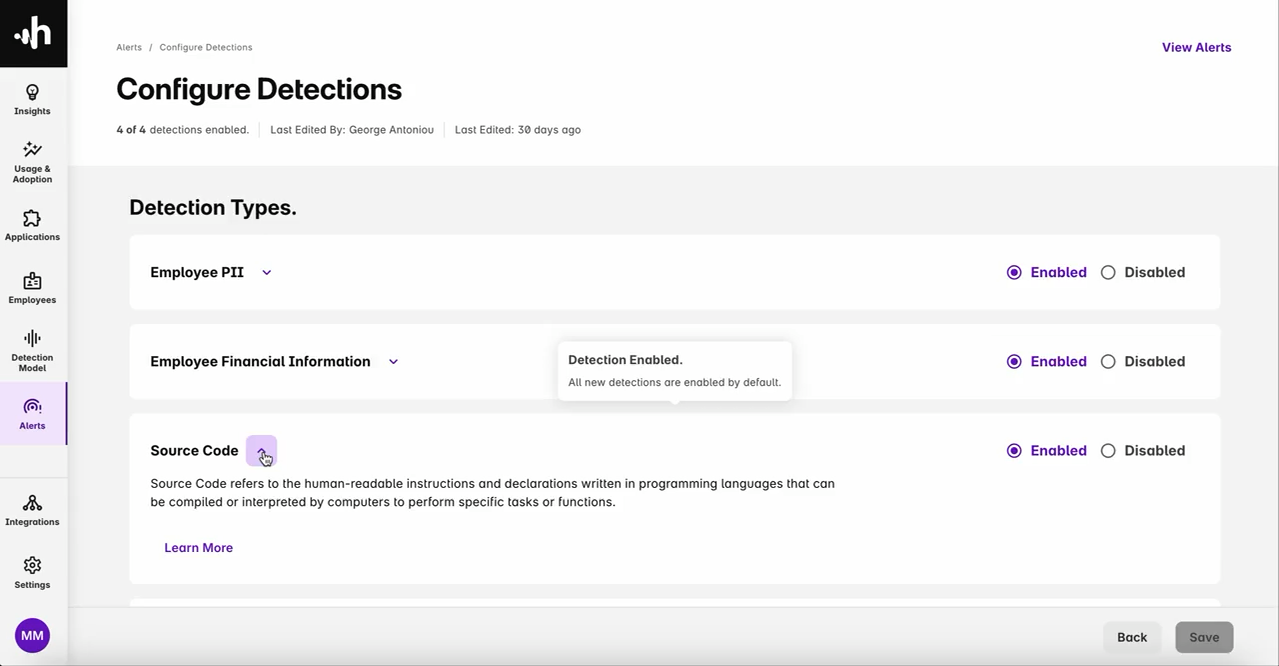
Harmonic Security’s solution is also now available on AWS Marketplace, enabling organizations to deploy enterprise-grade data leakage protection with seamless AWS integration. The platform provides prompt-level visibility into GenAI usage, real-time coaching at the point of risk, and detection of high-risk AI applications—all powered by the optimized models described in this post.
The initial version of their system was effective, but with a detection latency of 1–2 seconds, there was an opportunity to further enhance its capabilities and improve the overall user experience. To achieve this, Harmonic Security partnered with the AWS Generative AI Innovation Center to optimize their system with four key objectives:
- Reduce detection latency to under 500 milliseconds at the 95th percentile
- Maintain detection accuracy across monitored data types
- Continue to support EU data residency compliance
- Enable scalable architecture for production loads
This post walks through how Harmonic Security used Amazon SageMaker AI, Amazon Bedrock, and Amazon Nova Pro to fine-tune a ModernBERT model, achieving low-latency, accurate, and scalable data leakage detection.
Solution overview
Harmonic Security’s initial data leakage detection system relied on an 8 billion (8B) parameter model, which effectively identified sensitive data but incurred 1–2 second latency, which ran close to the threshold of impacting user experience. To achieve sub-500 millisecond latency while maintaining accuracy, we developed two classification approaches using a fine-tuned ModernBERT model.
First, a binary classification model was prioritized to detect Mergers & Acquisitions (M&A) content, a critical category for helping prevent sensitive data leaks. We initially focused on binary classification because it was the simplest approach that would seamlessly integrate within their current system that invokes multiple binary classification models in parallel. Secondly, as an extension, we explored a multi-label classification model to detect multiple sensitive data types (such as billing information, financial projections, and employment records) in a single pass, aiming to reduce the computational overhead of running multiple parallel binary classifiers for greater efficiency. Although the multi-label approach showed promise for future scalability, Harmonic Security decided to stick with the binary classification model for the initial version.The solution uses the following key services:
- Amazon SageMaker AI – For fine-tuning and deploying the model
- Amazon Bedrock – For accessing industry-leading large language models (LLMs)
- Amazon Nova Pro – A highly capable multimodal model that balances accuracy, speed, and cost
The following diagram illustrates the solution architecture for low-latency inference and scalability.
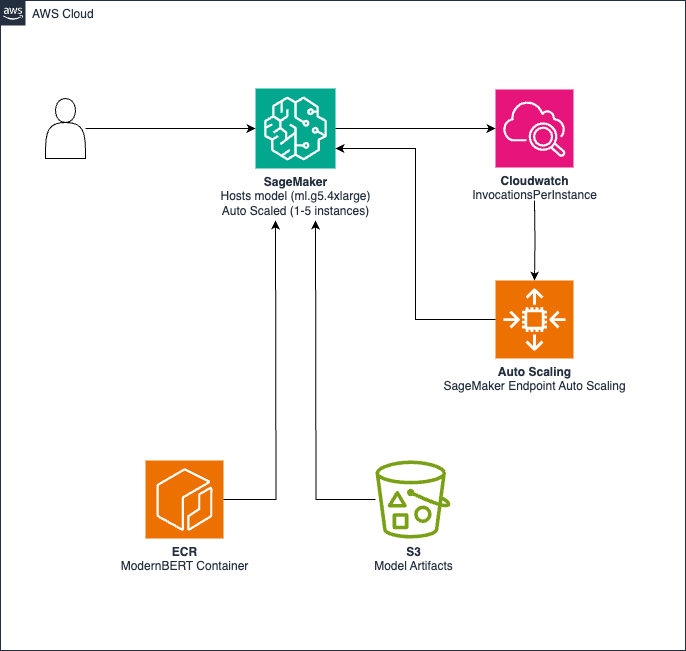
The architecture consists of the following components:
- Model artifacts are stored in Amazon Simple Storage Service (Amazon S3)
- A custom container with inference code is hosted in Amazon Elastic Container Registry (Amazon ECR)
- A SageMaker endpoint uses ml.g5.4xlarge instances for GPU-accelerated inference
- Amazon CloudWatch monitors invocations, triggering auto scaling to adjust instances (1–5) based on an 830 requests per minute (RPM) threshold.
The solution supports the following features:
- Sub-500 milliseconds inference latency
- EU AWS Region deployment support
- Automatic scaling between 1–5 instances based on demand
- Cost optimization during low-usage periods
Synthetic data generation
High-quality training data for sensitive information (such as M&A documents and financial data) is scarce. We used Meta Llama 3.3 70B Instruct and Amazon Nova Pro to generate synthetic data, expanding upon Harmonic’s existing dataset that included examples of data in the following categories: M&A, billing information, financial projection, employment records, sales pipeline, and investment portfolio. The following diagram provides a high-level overview of the synthetic data generation process.
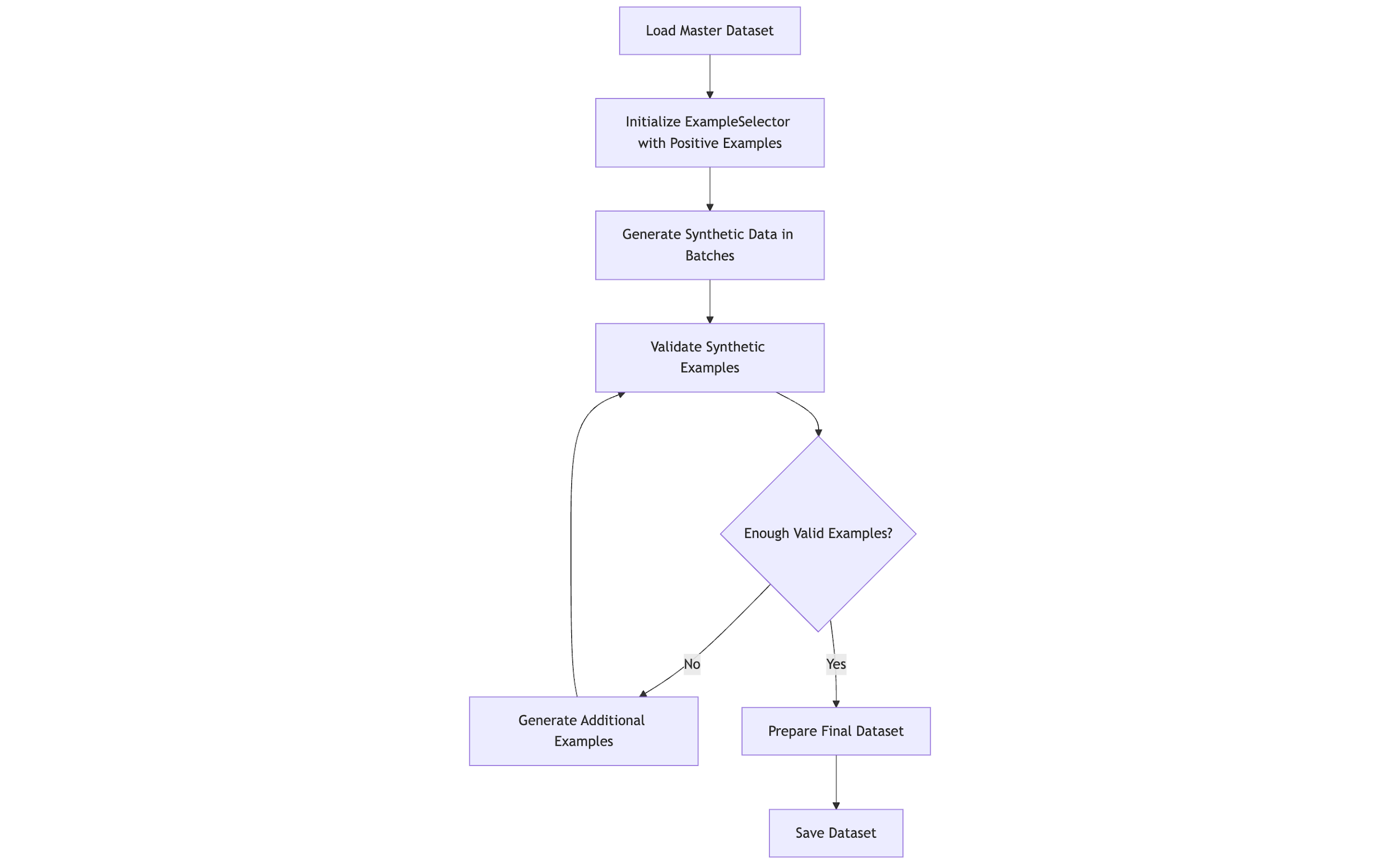
Data generation framework
The synthetic data generation framework is comprised of a series of steps, including:
- Smart example selection – K-means clustering on sentence embeddings supports diverse example selection
- Adaptive prompts – Prompts incorporate domain knowledge, with temperature (0.7–0.85) and top-p sampling adjusted per category
- Near-miss augmentation – Negative examples resembling positive cases to improve precision
- Validation – An LLM-as-a-judge approach using Amazon Nova Pro and Meta Llama 3 validates examples for relevance and quality
Binary classification
For the binary M&A classification task, we generated three distinct types of examples:
- Positive examples – These contained explicit M&A information while maintaining realistic document structures and finance-specific language patterns. They included key indicators like “merger,” “acquisition,” “deal terms,” and “synergy estimates.”
- Negative examples – We created domain-relevant content that deliberately avoided M&A characteristics while remaining contextually appropriate for business communications.
- Near-miss examples – These resembled positive examples but fell just outside the classification boundary. For instance, documents discussing strategic partnerships or joint ventures that didn’t constitute actual M&A activity.
The generation process maintained careful proportions between these example types, with particular emphasis on near-miss examples to address precision requirements.
Multi-label classification
For the more complex multi-label classification task across four sensitive information categories, we developed a sophisticated generation strategy:
- Single-label examples – We generated examples containing information relevant to exactly one category to establish clear category-specific features
- Multi-label examples – We created examples spanning multiple categories with controlled distributions, covering various combinations (2–4 labels)
- Category-specific requirements – For each category, we defined mandatory elements to maintain explicit rather than implied associations:
- Financial projections – Forward-looking revenue and growth data
- Investment portfolio – Details about holdings and performance metrics
- Billing and payment information – Invoices and supplier accounts
- Sales pipeline – Opportunities and projected revenue
Our multi-label generation prioritized realistic co-occurrence patterns between categories while maintaining sufficient representation of individual categories and their combinations. As a result, synthetic data increased training examples by 10 times (binary) and 15 times (multi-label) more. It also improved the class balance because we made sure to generate the data with a more balanced label distribution.
Model fine-tuning
We fine-tuned ModernBERT models on SageMaker to achieve low latency and high accuracy. Compared with decoder-only models such as Meta Llama 3.2 3B and Google Gemma 2 2B, ModernBERT’s compact size (149M and 395M parameters) translated into faster latency while still delivering higher accuracy. We therefore selected ModernBERT over fine-tuning those alternatives. In addition, ModernBERT is one of the few BERT-based models that supports context lengths of up to 8,192 tokens, which was a key requirement for our project.
Binary classification model
Our first fine-tuned model used ModernBERT-base, and we focused on binary classification of M&A content.We approached this task methodically:
- Data preparation – We enriched our M&A dataset with the synthetically generated data
- Framework selection – We used the Hugging Face transformers library with the Trainer API in a PyTorch environment, running on SageMaker
- Training process – Our process included:
- Stratified sampling to maintain label distribution across training and evaluation sets
- Specialized tokenization with sequence lengths up to 3,000 tokens to match what the client had in production
- Binary cross-entropy loss optimization
- Early stopping based on F1 score to prevent overfitting.
The result was a fine-tuned model that could distinguish M&A content from non-sensitive information with a higher F1 score than the 8B parameter model.
Multi-label classification model
For our second model, we tackled the more complex challenge of multi-label classification (detecting multiple sensitive data types simultaneously within single text passages).We fine-tuned a ModernBERT-large model to identify various sensitive data types like billing information, employment records, and financial projections in a single pass. This required:
- Multi-hot label encoding – We converted our categories into vector format for simultaneous prediction.
- Focal loss implementation – Instead of standard cross-entropy loss, we implemented a custom FocalLossTrainer class. Unlike static weighted loss functions, Focal Loss adaptively down-weights straightforward examples during training. This helps the model concentrate on challenging cases, significantly improving performance for less frequent or harder-to-detect classes.
- Specialized configuration – We added configurable class thresholds (for example, 0.1 to 0.8) for each class probability to determine label assignment as we observed varying performance in different decision boundaries.
This approach enabled our system to identify multiple sensitive data types in a single inference pass.
Hyperparameter optimization
To find the optimal configuration for our models, we used Optuna to optimize key parameters. Optuna is an open-source hyperparameter optimization (HPO) framework that helps find the best hyperparameters for a given machine learning (ML) model by running many experiments (called trials). It uses a Bayesian algorithm called Tree-structured Parzen Estimator (TPE) to choose promising hyperparameter combinations based on past results.
The search space explored numerous combinations of key hyperparameters, as listed in the following table.
| Hyperparameter | Range |
| Learning rate | 5e-6–5e-5 |
| Weight decay | 0.01–0.5 |
| Warmup ratio | 0.0–0.2 |
| Dropout rates | 0.1–0.5 |
| Batch size | 16, 24, 32 |
| Gradient accumulation steps | 1, 4 |
| Focal loss gamma (multi-label only) | 1.0–3.0 |
| Class threshold (multi-label only) | 0.1–0.8 |
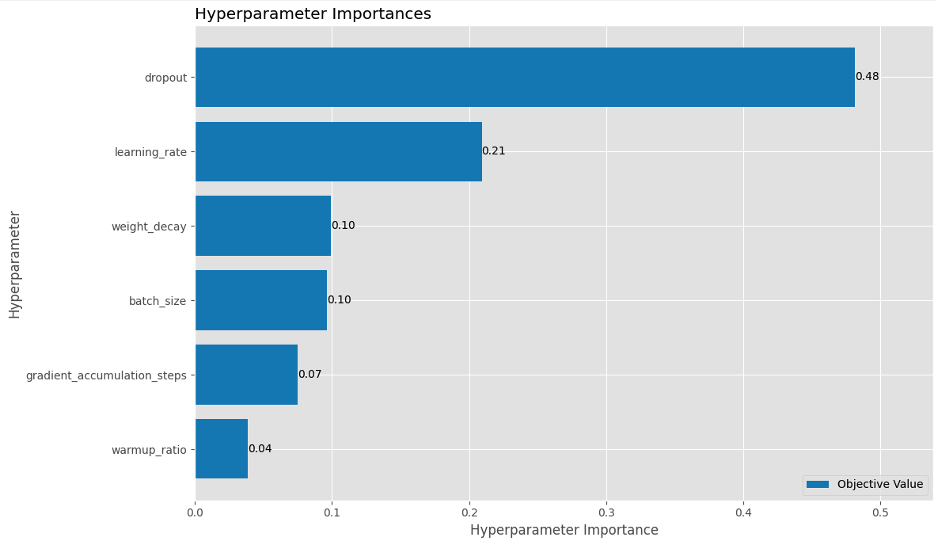
To optimize computational resources, we implemented pruning logic to stop under-performing trials early, so we could discard configurations that were less optimal. As seen in the following Optuna HPO history plot, trial 42 had the most optimal parameters with the highest F1 score for the binary classification, whereas trial 32 was the most optimal for the multi-label.
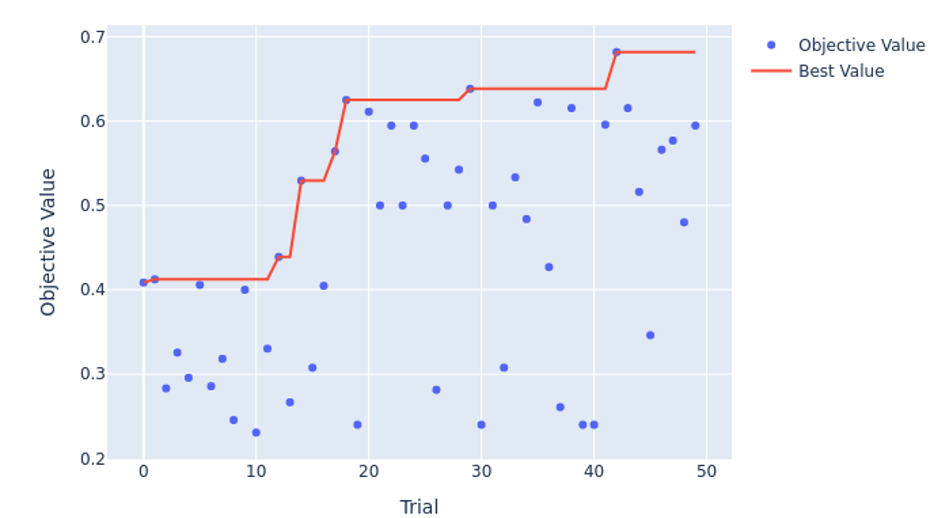
Moreover, our analysis showed that dropout and learning rate were the most important hyperparameters, accounting for 48% and 21% of the variance of the F1 score for the binary classification model. This explained why we noticed the model overfitting quickly during previous runs and stresses the importance of regularization.
After the optimization experiments, we discovered the following:
- We were able to identify the optimal hyperparameters for each task
- The models converged faster during training
- The final performance metrics showed measurable improvements over configurations we tested manually
This allowed our models to achieve a high F1 score efficiently by running hyperparameter tuning in an automated fashion, which is crucial for production deployment.
Load testing and autoscaling policy
After fine-tuning and deploying the optimized model to a SageMaker real-time endpoint, we performed load testing to validate the performance and autoscaling under pressure to meet Harmonic Security’s latency, throughput, and elasticity needs. The objectives of the load testing were:
- Validate latency SLA with an average of less than 500 milliseconds and P95 of approximately 1 second varying loads
- Determine throughput capacity with maximum RPM using ml.g5.4xlarge instances within latency SLA
- Inform the auto scaling policy design
The methodology involved the following:
- Traffic simulation – Locust simulated concurrent user traffic with varying text lengths (50–9,999 characters)
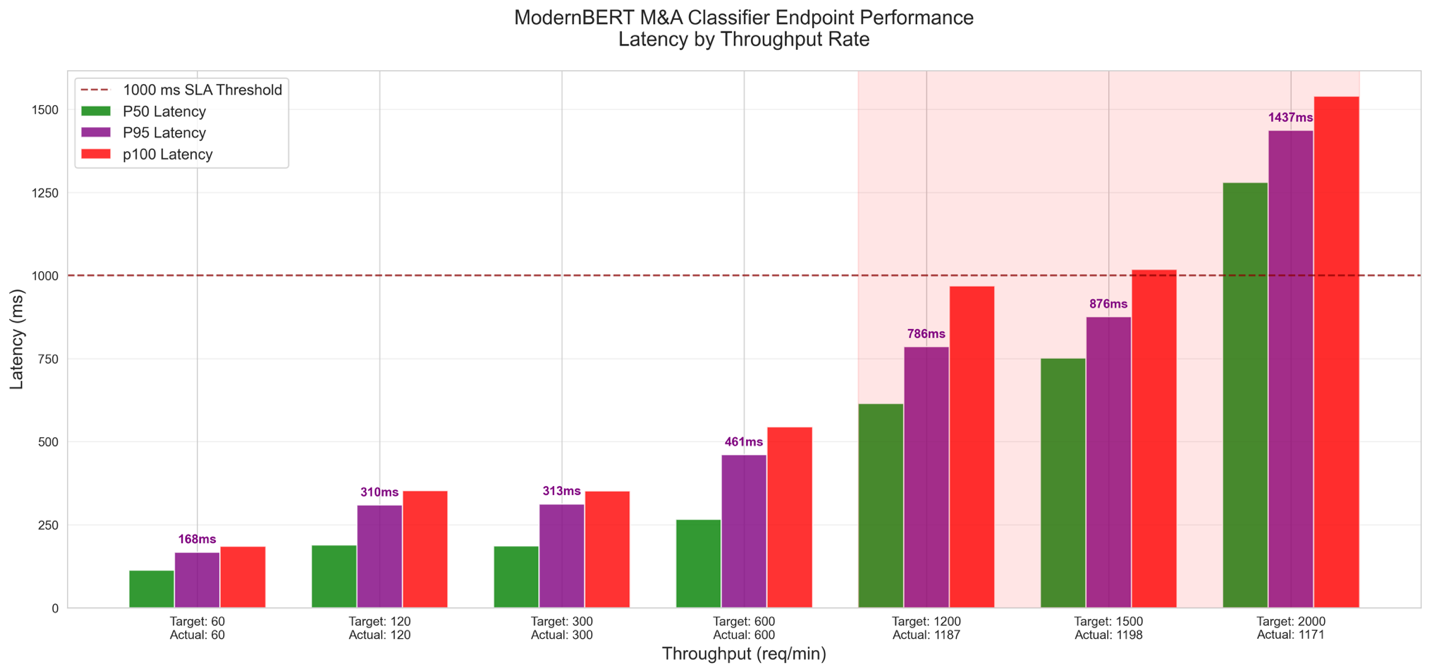
- Load pattern – We stepped ramp-up tests (60–2,000 RPM, 60 seconds each) and identified bottlenecks and stress-tested limits
As shown in the following graph, we found that the maximum throughput under a latency of 1 second was 1,185 RPM, so we decided to set the auto scaling threshold to 70% of that at 830 RPM.
Based on the performance observed during load testing, we configured a target-tracking auto scaling policy for the SageMaker endpoint using Application Auto Scaling. The following figure illustrates this policy workflow.

The key parameters defined were:
- Metric –
SageMakerVariantInvocationsPerInstance(830 invocations/instance/minute) - Min/Max Instances – 1–5
- Cooldown – Scale-out 300 seconds, scale-in 600 seconds
This target-tracking policy adjusts instances based on traffic, maintaining performance and cost-efficiency. The following table summarizes our findings.
| Model | Requests per Minute |
|---|---|
| 8B model | 800 |
| ModernBERT with auto scaling (5 instances) | 1,185-5925 |
| Additional capacity (ModernBERT vs. 8B model) | 48%-640% |
Results
This section showcases the significant impact of the fine-tuning and optimization efforts on Harmonic Security’s data leakage detection system, with a primary focus on achieving substantial latency reductions. Absolute latency improvements are detailed first, underscoring the success in meeting the sub-500 millisecond target, followed by an overview of performance enhancements. The following subsections provide detailed results for binary M&A classification and multi-label classification across multiple sensitive data types.
Binary classification
We evaluated the fine-tuned ModernBERT-base model for binary M&A classification against the baseline 8B model, introduced in the solution overview. The most striking achievement was a transformative reduction in latency, addressing the initial 1–2 second delay that risked disrupting user experience. This leap to sub-500 millisecond latency is detailed in the following table, marking a pivotal enhancement in system responsiveness.
| Model | median_ms | p95_ms | p99_ms | p100_ms |
|---|---|---|---|---|
| Modernbert-base-v2 | 46.03 | 81.19 | 102.37 | 183.11 |
| 8B model | 189.15 | 259.99 | 286.63 | 346.36 |
| Difference | -75.66% | -68.77% | -64.28% | -47.13% |
Building on this latency breakthrough, the following performance metrics reflect percentage improvements in accuracy and F1 score.
| Model | Accuracy Improvement | F1 Improvement |
| ModernBERT-base-v2 | +1.56% | +2.26% |
| 8B model | – | – |
These results highlight that ModernBERT-base-v2 delivers a groundbreaking latency reduction, complemented by modest accuracy and F1 improvements of 1.56% and 2.26%, respectively, aligning with Harmonic Security’s objectives to enhance data leakage detection without impacting user experience.
Multi-label classification
We evaluated the fine-tuned ModernBERT-large model for multi-label classification against the baseline 8B model, with latency reduction as the cornerstone of this approach. The most significant advancement was a substantial decrease in latency across all evaluated categories, achieving sub-500 millisecond responsiveness and addressing the previous 1–2 second bottleneck. The latency results shown in the following table underscore this critical improvement.
| Dataset | model | median_ms | p95_ms | p99_ms |
| Billing and payment | 8B model | 198 | 238 | 321 |
| ModernBERT-large | 158 | 199 | 246 | |
| Difference | -20.13% | -16.62% | -23.60% | |
| Sales pipeline | 8B model | 194 | 265 | 341 |
| ModernBERT-large | 162 | 243 | 293 | |
| Difference | -16.63% | -8.31% | -13.97% | |
| Financial projections | 8B model | 384 | 510 | 556 |
| ModernBERT-large | 160 | 275 | 310 | |
| Difference | -58.24% | -46.04% | -44.19% | |
| Investment portfolio | 8B model | 397 | 498 | 703 |
| ModernBERT-large | 160 | 259 | 292 | |
| Difference | -59.69% | -47.86% | -58.46% |
This approach also delivered a second key benefit: a reduction in computational parallelism by consolidating multiple classifications into a single pass. However, the multi-label model encountered challenges in maintaining consistent accuracy across all classes. Although categories like Financial Projections and Investment Portfolio showed promising accuracy gains, others such as Billing and Payment and Sales Pipeline experienced significant accuracy declines. This indicates that, despite its latency and parallelism advantages, the approach requires further development to maintain reliable accuracy across data types.
Conclusion
In this post, we explored how Harmonic Security collaborated with the AWS Generative AI Innovation Center to optimize their data leakage detection system achieving transformative results:
Key performance improvements:
- Latency reduction: From 1–2 seconds to under 500 milliseconds (76% reduction at median)
- Throughput increase: 48%–640% additional capacity with auto scaling
- Accuracy gains: +1.56% for binary classification, with maintained precision across categories
By using SageMaker, Amazon Bedrock, and Amazon Nova Pro, Harmonic Security fine-tuned ModernBERT models that deliver sub-500 millisecond inference in production, meeting stringent performance goals while supporting EU compliance and establishing a scalable architecture.
This partnership showcases how tailored AI solutions can tackle critical cybersecurity challenges without hindering productivity. Harmonic Security’s solution is now available on AWS Marketplace, enabling organizations to adopt AI tools safely while protecting sensitive data in real time. Looking ahead, these high-speed models have the potential to add further controls for additional AI workflows.
To learn more, consider the following next steps:
- Try Harmonic Security – Deploy the solution directly from AWS Marketplace to protect your organization’s GenAI usage
- Explore AWS services – Dive into SageMaker, Amazon Bedrock, and Amazon Nova Pro to build advanced AI-driven security solutions. Visit the AWS Generative AI page for resources and tutorials.
- Deep dive into fine-tuning – Explore the AWS Machine Learning Blog for in-depth guides on fine-tuning LLMs for specialized use cases.
- Stay updated – Subscribe to the AWS Podcast for weekly insights on AI innovations and practical applications.
- Connect with experts – Join the AWS Partner Network to collaborate with experts and scale your AI initiatives.
- Attend AWS events – Register for AWS re: Invent. to explore cutting-edge AI advancements and network with industry leaders.
By adopting these steps, organizations can harness AI-driven cybersecurity to maintain robust data protection and seamless user experiences across diverse workflows.
About the authors
 Babs Khalidson is a Deep Learning Architect at the AWS Generative AI Innovation Centre in London, where he specializes in fine-tuning large language models, building AI agents, and model deployment solutions. He has over 6 years of experience in artificial intelligence and machine learning across finance and cloud computing, with expertise spanning from research to production deployment.
Babs Khalidson is a Deep Learning Architect at the AWS Generative AI Innovation Centre in London, where he specializes in fine-tuning large language models, building AI agents, and model deployment solutions. He has over 6 years of experience in artificial intelligence and machine learning across finance and cloud computing, with expertise spanning from research to production deployment.
 Vushesh Babu Adhikari is a Data scientist at the AWS Generative AI Innovation center in London with extensive expertise in developing Gen AI solutions across diverse industries. He has over 7 years of experience spanning across a diverse set of industries including Finance , Telecom , Information Technology with specialized expertise in Machine learning & Artificial Intelligence.
Vushesh Babu Adhikari is a Data scientist at the AWS Generative AI Innovation center in London with extensive expertise in developing Gen AI solutions across diverse industries. He has over 7 years of experience spanning across a diverse set of industries including Finance , Telecom , Information Technology with specialized expertise in Machine learning & Artificial Intelligence.
 Zainab Afolabi is a Senior Data Scientist at the AWS Generative AI Innovation Centre in London, where she leverages her extensive expertise to develop transformative AI solutions across diverse industries. She has over nine years of specialized experience in artificial intelligence and machine learning, as well as a passion for translating complex technical concepts into practical business applications.
Zainab Afolabi is a Senior Data Scientist at the AWS Generative AI Innovation Centre in London, where she leverages her extensive expertise to develop transformative AI solutions across diverse industries. She has over nine years of specialized experience in artificial intelligence and machine learning, as well as a passion for translating complex technical concepts into practical business applications.
 Nuno Castro is a Sr. Applied Science Manager at the AWS Generative AI Innovation Center. He leads Generative AI customer engagements, helping AWS customers find the most impactful use case from ideation, prototype through to production. He’s has 19 years experience in the field in industries such as finance, manufacturing, and travel, leading ML teams for 11 years.
Nuno Castro is a Sr. Applied Science Manager at the AWS Generative AI Innovation Center. He leads Generative AI customer engagements, helping AWS customers find the most impactful use case from ideation, prototype through to production. He’s has 19 years experience in the field in industries such as finance, manufacturing, and travel, leading ML teams for 11 years.
 Christelle Xu is a Senior Generative AI Strategist who leads model customization and optimization strategy across EMEA within the AWS Generative AI Innovation Center, working with customers to deliver scalable Generative AI solutions, focusing on continued pre-training, fine-tuning, reinforcement learning, and training and inference optimization. She holds a Master’s degree in Statistics from the University of Geneva and a Bachelor’s degree from Brigham Young University.
Christelle Xu is a Senior Generative AI Strategist who leads model customization and optimization strategy across EMEA within the AWS Generative AI Innovation Center, working with customers to deliver scalable Generative AI solutions, focusing on continued pre-training, fine-tuning, reinforcement learning, and training and inference optimization. She holds a Master’s degree in Statistics from the University of Geneva and a Bachelor’s degree from Brigham Young University.
 Manuel Gomez is a Solutions Architect at AWS supporting generative AI startups across the UK and Ireland. He works with model producers, fine-tuning platforms, and agentic AI applications to design secure and scalable architectures. Before AWS, he worked in startups and consulting, and he has a background in industrial technologies and IoT. He is particularly interested in how multi-modal AI can be applied to real industry problems.
Manuel Gomez is a Solutions Architect at AWS supporting generative AI startups across the UK and Ireland. He works with model producers, fine-tuning platforms, and agentic AI applications to design secure and scalable architectures. Before AWS, he worked in startups and consulting, and he has a background in industrial technologies and IoT. He is particularly interested in how multi-modal AI can be applied to real industry problems.
 Bryan Woolgar-O’Neil is the co-founder & CTO at Harmonic Security. With over 20 years of software development experience, the last 10 were dedicated to building the Threat Intelligence company Digital Shadows, which was acquired by Reliaquest in 2022. His expertise lies in developing products based on cutting-edge software, focusing on making sense of large volumes of data.
Bryan Woolgar-O’Neil is the co-founder & CTO at Harmonic Security. With over 20 years of software development experience, the last 10 were dedicated to building the Threat Intelligence company Digital Shadows, which was acquired by Reliaquest in 2022. His expertise lies in developing products based on cutting-edge software, focusing on making sense of large volumes of data.
 Jamie Cockrill is the Director of Machine Learning at Harmonic Security, where he leads a team focused on building, training, and refining Harmonic’s Small Language Models.
Jamie Cockrill is the Director of Machine Learning at Harmonic Security, where he leads a team focused on building, training, and refining Harmonic’s Small Language Models.
 Adrian Cunliffe is a Senior Machine Learning Engineer at Harmonic Security, where he focuses on scaling Harmonic’s Machine Learning engine that powers Harmonic’s proprietary models.
Adrian Cunliffe is a Senior Machine Learning Engineer at Harmonic Security, where he focuses on scaling Harmonic’s Machine Learning engine that powers Harmonic’s proprietary models.