Artificial Intelligence
How the Amazon AMET Payments team accelerates test case generation with Strands Agents
At Amazon.ae, we serve approximately 10 million customers monthly across five countries in the Middle East and North Africa region—United Arab Emirates (UAE), Saudi Arabia, Egypt, Türkiye, and South Africa. Our AMET (Africa, Middle East, and Türkiye) Payments team manages payment selections, transactions, experiences, and affordability features across these diverse countries, publishing on average five new features monthly. Each feature requires comprehensive test case generation, which traditionally consumed 1 week of manual effort per project. Our quality assurance (QA) engineers spent this time analyzing business requirement documents (BRDs), design documents, UI mocks, and historical test preparations—a process that required one full-time engineer annually merely for test case creation.
To improve this manual process, we developed SAARAM (QA Lifecycle App), a multi-agent AI solution that helps reduce test case generation from 1 week to hours. Using Amazon Bedrock with Claude Sonnet by Anthropic and the Strands Agents SDK, we reduced the time needed to generate test cases from 1 week to mere hours while also improving test coverage quality. Our solution demonstrates how studying human cognitive patterns, rather than optimizing AI algorithms alone, can create production-ready systems that enhance rather than replace human expertise.
In this post, we explain how we overcame the limitations of single-agent AI systems through a human-centric approach, implemented structured outputs to significantly reduce hallucinations and built a scalable solution now positioned for expansion across the AMET QA team and later across other QA teams in International Emerging Stores and Payments (IESP) Org.
Solution overview
The AMET Payments QA team validates code deployments affecting payment functionality for millions of customers across diverse regulatory environments and payment methods. Our manual test case generation process added turnaround time (TAT) in the product cycle, consuming valuable engineering resources on repetitive test prep and documentation tasks rather than strategic testing initiatives. We needed an automated solution that could maintain our quality standards while reducing the time investment.
Our objectives included reducing test case creation time from 1 week to under a few hours, capturing institutional knowledge from experienced testers, standardizing testing approaches across teams, and minimizing the hallucination issues common in AI systems. The solution needed to handle complex business requirements spanning multiple payment methods, regional regulations, and customer segments while generating specific, actionable test cases aligned with our existing test management systems.
The architecture employs a sophisticated multi-agent workflow. To achieve this, we went through 3 different iterations and continue to improve and enhance as new techniques are developed and new models are deployed.
The challenge with traditional AI approaches
Our initial attempts followed conventional AI approaches, feeding entire BRDs to a single AI agent for test case generation. This method frequently produced generic outputs like “verify payment works correctly” instead of the specific, actionable test cases our QA team requires. For example, we need test cases as specific as “verify that when a UAE customer selects cash on delivery (COD) for an order above 1,000 AED with a saved credit card, the system displays the COD fee of 11 AED and processes the payment through the COD gateway with order state transitioning to ‘pending delivery.'”
The single-agent approach presented several critical limitations. Context length restrictions prevented processing large documents effectively, but the lack of specialized processing phases meant the AI couldn’t understand testing priorities or risk-based approaches. Additionally, hallucination issues created irrelevant test scenarios that could mislead QA efforts. The root cause was clear: AI attempted to compress complex business logic without the iterative thinking process that experienced testers employ when analyzing requirements.
The following flow chart illustrates our issues when attempting to use a single agent with a comprehensive prompt.

The human-centric breakthrough
Our breakthrough came from a fundamental shift in approach. Instead of asking, “How should AI think about testing?”, we asked, “How do experienced humans think about testing?” to focus on following a specific step-by-step process instead of relying on the large language model (LLM) to realize this on its own. This philosophy change led us to conduct research interviews with senior QA professionals, studying their cognitive workflows in detail.
We discovered that experienced testers don’t process documents holistically—they work through specialized mental phases. First, they analyze documents by extracting acceptance criteria, identifying customer journeys, understanding UX requirements, mapping product requirements, analyzing user data, and assessing workstream capabilities. Then they develop tests through a systematic process: journey analysis, scenario identification, data flow mapping, test case development, and finally, organization and prioritization.
We then decomposed our original agent into sequential thinking actions that served as individual steps. We built and tested each step using Amazon Q Developer for CLI to make sure basic ideas were sound and incorporated both primary and secondary inputs.
This insight led us to design SAARAM with specialized agents that mirror these expert testing approaches. Each agent focuses on a specific aspect of the testing process, such as how human experts mentally compartmentalize different analysis phases.
Multi-agent architecture with Strands Agents
Based on our understanding of human QA workflows, we initially attempted to build our own agents from scratch. We had to create our own looping, serial, or parallel execution. We also created our own orchestration and workflow graphs, which demanded considerable manual effort. To address these challenges, we migrated to Strands Agents SDK. This provided the multi-agent orchestration capabilities essential for coordinating complex, interdependent tasks while maintaining clear execution paths, helping improve our performance and reduce our development time.
Workflow iteration 1: End-to-end test generation
Our first iteration of SAARAM consisted of a single input and created our first specialized agents. It involved processing a work document through five specialized agents to generate comprehensive test coverage.
Agent 1 is called the Customer Segment Creator, and it focuses on customer segmentation analysis, using four subagents:
- Customer Segment Discovery identifies product user segments
- Decision Matrix Generator creates parameter-based matrices
- E2E Scenario Creation develops end-to-end (E2E) scenarios per segment
- Test Steps Generation detailed test case development
Agent 2 is called the User Journey Mapper, and it employs four subagents to map product journeys comprehensively:
- The Flow Diagram and Sequence Diagram are creators using Mermaid syntax.
- The E2E Scenarios generator builds upon these diagrams.
- The Test Steps Generator is used for detailed test documentation.
Agent 3 is called Customer Segment x Journey Coverage, and it combines inputs from agents 1 and 2 to create detailed segment-specific analyses. It uses four subagents:
- Mermaid-based flow diagrams
- User journeys
- Sequence diagrams for each customer segment
- Corresponding test steps.
Agent 4 is called the State Transition Agent. It analyzes various product state points in customer journey flows. Its sub-agents create Mermaid state diagrams representing different journey states, segment-specific state scenario diagrams, and generate related test scenarios and steps.
The workflow, shown in the following diagram, concludes with a basic extract, transform, and load (ETL) process that consolidates and deduplicates the data from the agents, saving the final output as a text file.
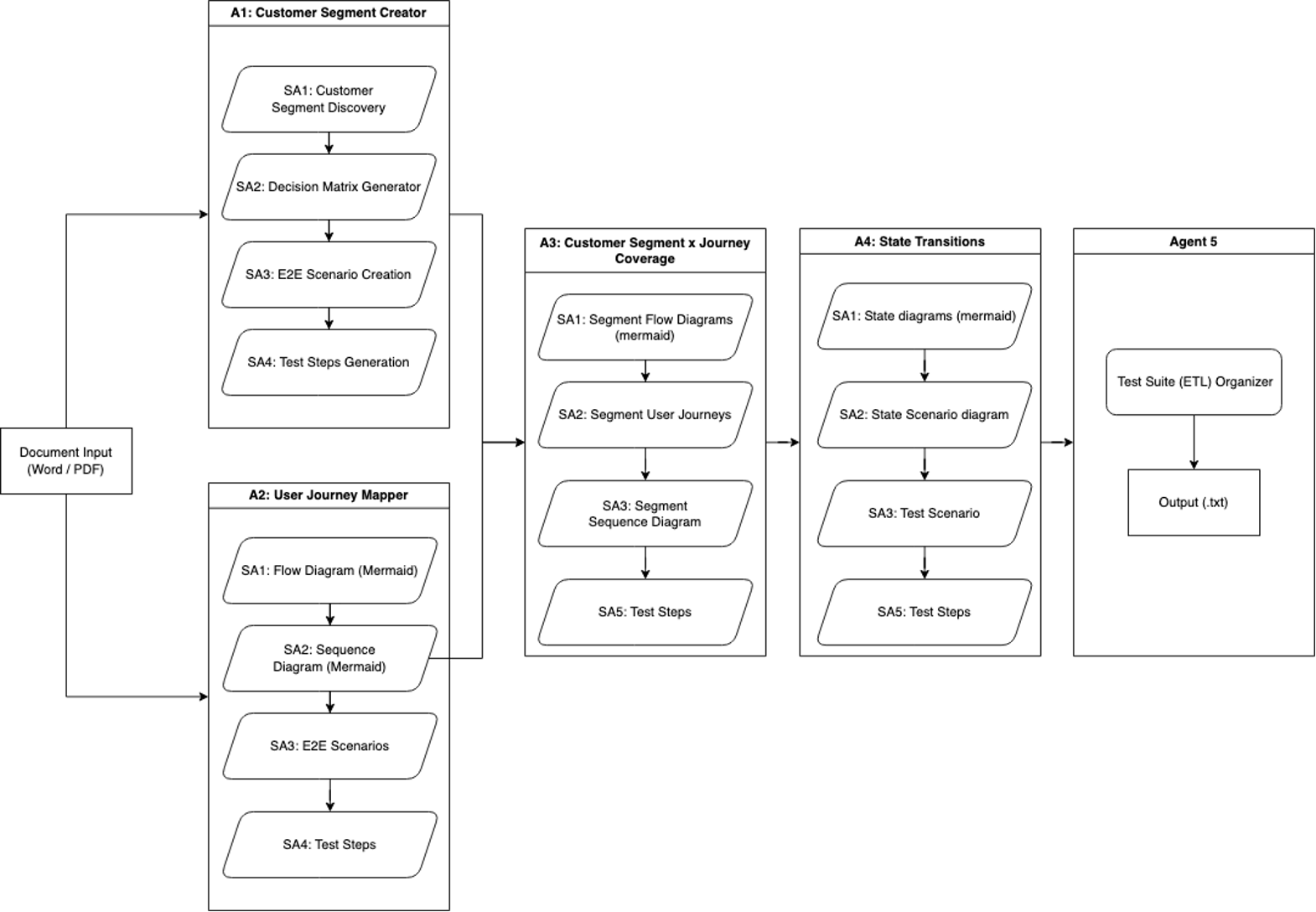
This systematic approach facilitates comprehensive coverage of customer journeys, segments, and various diagram types, enabling thorough test coverage generation through iterative processing by agents and subagents.
Addressing limitations and enhancing capabilities
In our journey to develop a more robust and efficient tool using Strands Agents, we identified five crucial limitations in our initial approach:
- Context and hallucination challenges – Our first workflow faced limitations from segregated agent operations where individual agents independently collected data and created visual representations. This isolation led to limited contextual understanding, resulting in reduced accuracy and increased hallucinations in the outputs.
- Data generation inefficiencies – The limited context available to agents caused another critical issue: the generation of excessive irrelevant data. Without proper contextual awareness, agents produced less focused outputs, leading to noise that obscured valuable insights.
- Restricted parsing capabilities – The initial system’s data parsing scope proved too narrow, limited to only customer segments, journey mapping, and basic requirements. This restriction prevented agents from accessing the full spectrum of information needed for comprehensive analysis.
- Single-source input constraint – The workflow could only process Word documents, creating a significant bottleneck. Modern development environments require data from multiple sources, and this limitation prevented holistic data collection.
- Rigid architecture problems – Importantly, the first workflow employed a tightly coupled system with rigid orchestration. This architecture made it difficult to modify, extend, or reuse components, limiting the system’s adaptability to changing requirements.
In our second iteration, we needed to implement strategic solutions to address these issues.
Workflow iteration 2: Comprehensive analysis workflow
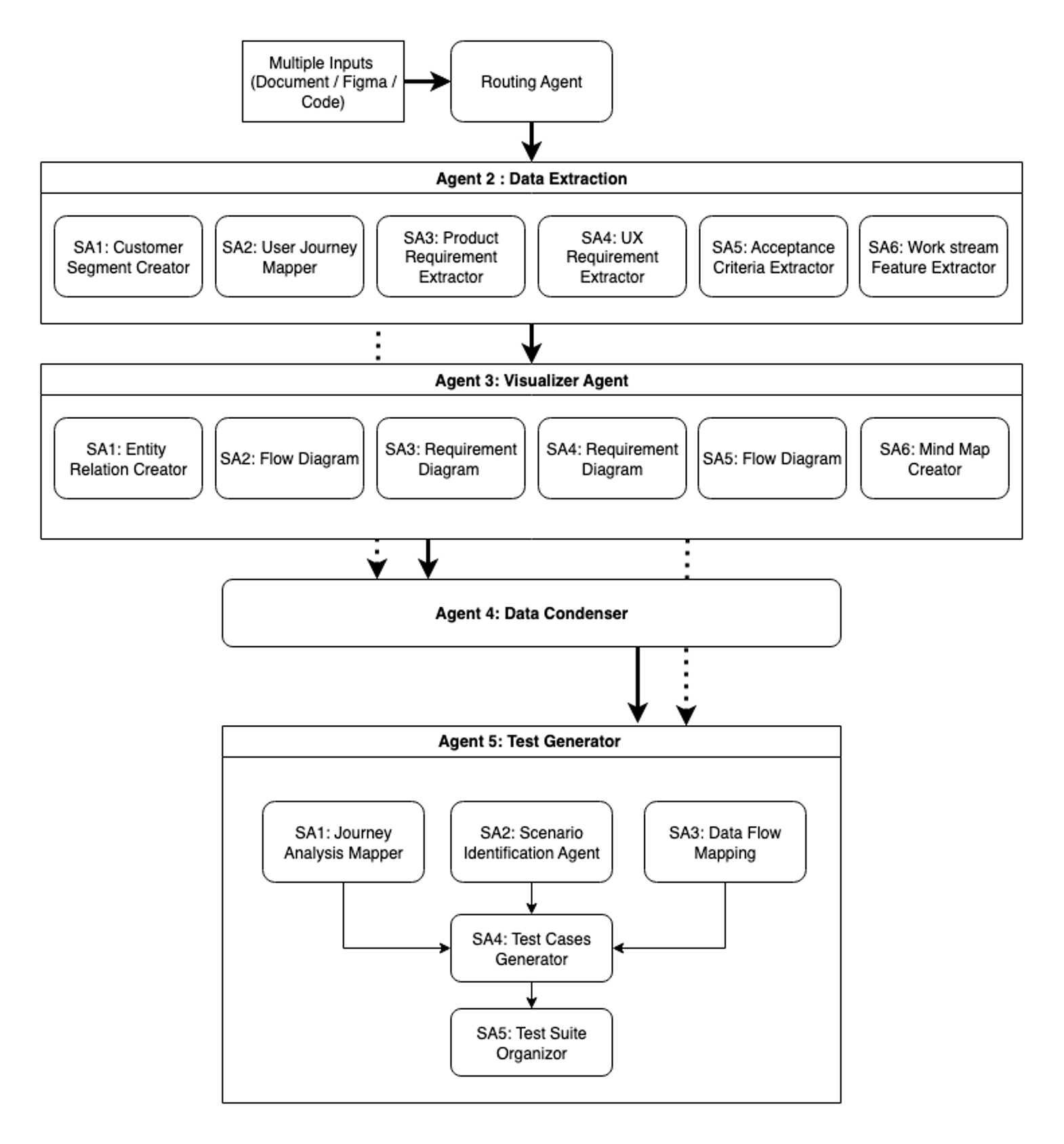
Our second iteration represents a complete reimagining of the agentic workflow architecture. Rather than patching individual problems, we rebuilt from the ground up with modularity, context-awareness, and extensibility as core principles:
Agent 1 is the intelligent gateway. The file type decision agent serves as the system’s entry point and router. Processing documentation files, Figma designs, and code repositories, it categorizes and directs data to appropriate downstream agents. This intelligent routing is essential for maintaining both efficiency and accuracy throughout the workflow.
Agent 2 is for specialized data extraction. The Data Extractor agent employs six specialized subagents, each focused on specific extraction domains. This parallel processing approach facilitates thorough coverage while maintaining practical speed. Each subagent operates with domain-specific knowledge, extracting nuanced information that generalized approaches might overlook.
Agent 3 is the Visualizer agent, and it transforms extracted data into six distinct Mermaid diagram types, each serving specific analytical purposes. Entity relation diagrams map data relationships and structures, and flow diagrams visualize processes and workflows. Requirement diagrams clarify product specifications, and UX requirement visualizations illustrate user experience flows. Process flow diagrams detail system operations, and mind maps reveal feature relationships and hierarchies. These visualizations provide multiple perspectives on the same information, helping both human reviewers and downstream agents understand patterns and connections within complex datasets.
Agent 4 is the Data Condenser agent, and it performs crucial synthesis through intelligent context distillation, making sure each downstream agent receives exactly the information needed for its specialized task. This agent, powered by its condensed information generator, merges outputs from both the Data Extractor and Visualizer agents while performing sophisticated analysis.
The agent extracts critical elements from the full text context—acceptance criteria, business rules, customer segments, and edge cases—creating structured summaries that preserve essential details while reducing token usage. It compares each text file with its corresponding Mermaid diagram, capturing information that might be missed in visual representations alone. This careful processing maintains information integrity across agent handoffs, making sure important data is not lost as it flows through the system. The result is a set of condensed addendums that enrich the Mermaid diagrams with comprehensive context. This synthesis makes sure that when information moves to test generation, it arrives complete, structured, and optimized for processing.
Agent 5 is the Test Generator agent brings together the collected, visualized, and condensed information to produce comprehensive test suites. Working with six Mermaid diagrams plus condensed information from Agent 4, this agent employs a pipeline of five subagents. The Journey Analysis Mapper, Scenario Identification Agent, and the Data Flow Mapping subagents generate comprehensive test cases based on their take of the input data flowing from Agent 4.With the test cases generated across three critical perspectives, the Test Cases Generator evaluates them, reformatting according to internal guidelines for consistency. Finally, the Test Suite Organizer performs deduplication and optimization, delivering a final test suite that balances comprehensiveness with efficiency.
The system now handles far more than the basic requirements and journey mapping of Workflow 1—it processes product requirements, UX specifications, acceptance criteria, and workstream extraction while accepting inputs from Figma designs, code repositories, and multiple document types. Most importantly, the shift to modular architecture fundamentally changed how the system operates and evolves. Unlike our rigid first workflow, this design allows for reusing outputs from earlier agents, integrating new testing type agents, and intelligently selecting test case generators based on user requirements, positioning the system for continuous adaptation.
The following figure shows our second iteration of SAARAM with five main agents and multiple subagents with context engineering and compression.
Additional Strands Agents features
Strands Agents provided the foundation for our multi-agent system, offering a model-driven approach that simplified complex agent development. Because the SDK can connect models with tools through advanced reasoning capabilities, we built sophisticated workflows with only a few lines of code. Beyond its core functionality, two key features proved essential for our production deployment: reducing hallucinations with structured outputs and workflow orchestration.
Reducing hallucinations with structured outputs
The structured output feature of Strands Agents uses Pydantic models to transform traditionally unpredictable LLM outputs into reliable, type-safe responses. This approach addresses a fundamental challenge in generative AI: although LLMs excel at producing humanlike text, they can struggle with consistently formatted outputs needed for production systems. By enforcing schemas through Pydantic validation, we make sure that responses conform to predefined structures, enabling seamless integration with existing test management systems.
The following sample implementation demonstrates how structured outputs work in practice:
Pydantic automatically validates LLM responses against defined schemas to facilitate type correctness and required field presence. When responses don’t match the expected structure, validation errors provide clear feedback about what needs correction, helping prevent malformed data from propagating through the system. In our environment, this approach delivered consistent, predictable outputs across the agents regardless of prompt variations or model updates, minimizing an entire class of data formatting errors. As a result, our development team worked more efficiently with full IDE support.
Workflow orchestration benefits
The Strands Agents workflow architecture provided the sophisticated coordination capabilities our multi-agent system required. The framework enabled structured coordination with explicit task definitions, automatic parallel execution for independent tasks, and sequential processing for dependent operations. This meant we could build complex agent-to-agent communication patterns that would have been difficult to implement manually.
The following sample snippet shows how to create a workflow in Strands Agents SDK:
The workflow system delivered three critical capabilities for our use case. First, parallel processing optimization allowed journey analysis, scenario identification, and coverage analysis to run simultaneously, with independent agents processing different aspects without blocking each other. The system automatically allocated resources based on availability, maximizing throughput.
Second, intelligent dependency management made sure that test development waited for scenario identification to be completed, and organization tasks depended on the test cases being generated. Context was preserved and passed efficiently between dependent stages, maintaining information integrity throughout the workflow.
Finally, the built-in reliability features provided the resilience our system required. Automatic retry mechanisms handled transient failures gracefully, state persistence enabled pause and resume capabilities for long-running workflows, and comprehensive audit logging supported both debugging and performance optimization efforts.
The following table shows examples of input into the workflow and the potential outputs.
| Input: Business requirement document | Output: Test cases generated |
Functional requirements:
|
TC006: Credit card payment success
Scenario: Customer completes purchase using valid credit card Steps: 1. Add items to cart and proceed to checkout. Expected result: Checkout form displayed. 2. Enter shipping information. Expected result: Shipping details saved. 3. Select credit card payment method. Expected result: Card form shown. 4. Enter valid card details. Expected result: Card validated. 5. Submit payment. Expected result: Payment processed, order confirmed.TC008: Payment failure handling Scenario: Payment fails due to insufficient funds or card decline Steps: 1. Enter card with insufficient funds. Expected result: Payment declined message. 2. System offers retry option. Expected result: Payment form redisplayed. 3. Try alternative payment method. Expected result: Alternative payment successful. TC009: Payment gateway timeout
TC010: Refund processing
|
Integration with Amazon Bedrock
Amazon Bedrock served as the foundation for our AI capabilities, providing seamless access to Claude Sonnet by Anthropic through the Strands Agents built-in AWS service integration. We selected Claude Sonnet by Anthropic for its exceptional reasoning capabilities and ability to understand complex payment domain requirements. The Strands Agents flexible LLM API integration made this implementation straightforward. The following snippet shows how to effortlessly create an agent in Strands Agents:
The managed service architecture of Amazon Bedrock reduced infrastructure complexity from our deployment. The service provided automatic scaling that adjusted to our workload demands, facilitating consistent performance across the agents regardless of traffic patterns. Built-in retry logic and error handling improved system reliability significantly, reducing the operational overhead typically associated with managing AI infrastructure at scale. The combination of the sophisticated orchestration capabilities of Strands Agents and the robust infrastructure of Amazon Bedrock created a production-ready system that could handle complex test generation workflows while maintaining high reliability and performance standards.
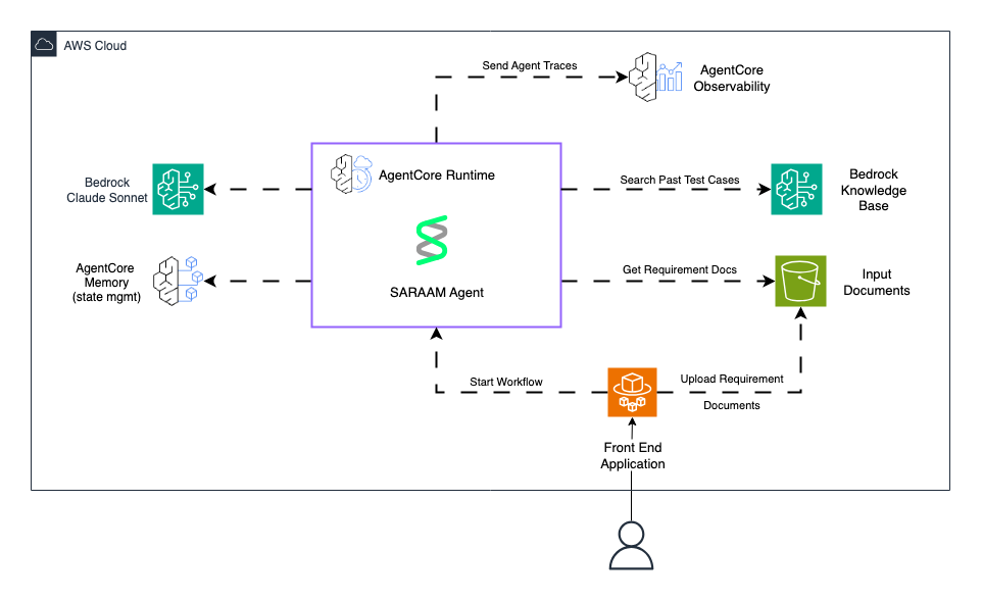
The following diagram shows the deployment of the SARAAM agent with Amazon Bedrock AgentCore and Amazon Bedrock.
Results and business impact
The implementation of SAARAM has improved our QA processes with measurable improvements across multiple dimensions. Before SAARAM, our QA engineers spent 3–5 days manually analyzing BRD documents and UI mocks to create comprehensive test cases. This manual process is now reduced to hours, with the system achieving:
- Test case generation time: Potential reduced from 1 week to hours
- Resource optimization: QA effort decreased from 1.0 full-time employee (FTE) to 0.2 FTE for validation
- Coverage improvement: 40% more edge cases identified compared to manual process
- Consistency: 100% adherence to test case standards and formats
The accelerated test case generation has driven improvements in our core business metrics:
- Payment success rate: Increased through comprehensive edge case testing and risk-based test prioritization
- Payment experience: Enhanced customer satisfaction because teams can now iterate on test coverage during the design phase
- Developer velocity: Product and development teams generate preliminary test cases during design, enabling early quality feedback
SAARAM captures and preserves institutional knowledge that was previously dependent on individual QA engineers:
- Testing patterns from experienced professionals are now codified
- Historical test case learnings are automatically applied to new features
- Consistent testing approaches across different payment methods and industries
- Reduced onboarding time for new QA team members
This iterative improvement means that the system becomes more valuable over time.
Lessons learned
Our journey developing SAARAM provided crucial insights for building production-ready AI systems. Our breakthrough came from studying how domain experts think rather than optimizing how AI processes information. Understanding the cognitive patterns of testers and QA professionals led to an architecture that naturally aligns with human reasoning. This approach produced better results compared to purely technical optimizations. Organizations building similar systems should invest time observing and interviewing domain experts before designing their AI architecture—the insights gained directly translate to more effective agent design.
Breaking complex tasks into specialized agents dramatically improved both accuracy and reliability. Our multi-agent architecture, enabled by the orchestration capabilities of Strands Agents, handles nuances that monolithic approaches consistently miss. Each agent’s focused responsibility enables deeper domain expertise while providing better error isolation and debugging capabilities.
A key discovery was that the Strands Agents workflow and graph-based orchestration patterns significantly outperformed traditional supervisor agent approaches. Although supervisor agents make dynamic routing decisions that can introduce variability, workflows provide “agents on rails”—a structured path facilitating consistent, reproducible results. Strands Agents offers multiple patterns, including supervisor-based routing, workflow orchestration for sequential processing with dependencies, and graph-based coordination for complex scenarios. For test generation where consistency is paramount, the workflow pattern with its explicit task dependencies and parallel execution capabilities delivered the optimal balance of flexibility and control. This structured approach aligns perfectly with production environments where reliability matters more than theoretical flexibility.
Implementing Pydantic models through the Strands Agents structured output feature effectively reduced type-related hallucinations in our system. By enforcing AI responses to conform to strict schemas, we facilitate reliable, programmatically usable outputs. This approach has proven essential when consistency and reliability are nonnegotiable. The type-safe responses and automatic validation have become foundational to our system’s reliability.
Our condensed information generator pattern demonstrates how intelligent context management maintains quality throughout multistage processing. This approach of knowing what to preserve, condense, and pass between agents helps prevent the context degradation that typically occurs in token-limited environments. The pattern is broadly applicable to multistage AI systems facing similar constraints.
What’s next
The modular architecture we’ve built with Strands Agents enables straightforward adaptation to other domains within Amazon. The same patterns that generate payment test cases can be applied to retail systems testing, customer service scenario generation for support workflows, and mobile application UI and UX test case generation. Each adaptation requires only domain-specific prompts and schemas while reusing the core orchestration logic. Throughout the development of SAARAM, the team successfully addressed many challenges in test case generation—from reducing hallucinations through structured outputs to implementing sophisticated multi-agent workflows. However, one critical gap remains: the system hasn’t yet been provided with examples of what high-quality test cases actually look like in practice.
To bridge this gap, integrating Amazon Bedrock Knowledge Bases with a curated repository of historical test cases would provide SAARAM with concrete, real-world examples during the generation process. By using the integration capabilities of Strands Agents with Amazon Bedrock Knowledge Bases, the system could search through past successful test cases to find similar scenarios before generating new ones. When processing a BRD for a new payment feature, SAARAM would first query the knowledge base for comparable test cases—whether for similar payment methods, customer segments, or transaction flows—and use these as contextual examples to guide its output.
Future deployment will use Amazon Bedrock AgentCore for comprehensive agent lifecycle management. Amazon Bedrock AgentCore Runtime provides the production execution environment with ephemeral, session-specific state management that maintains conversational context during active sessions while facilitating isolation between different user interactions. The observability capabilities of Bedrock AgentCore help deliver detailed visualizations of each step in SAARAM’s multi-agent workflow, which the team can use to trace execution paths through the five agents, audit intermediate outputs from the Data Condenser and Test Generator agents, and identify performance bottlenecks through real-time dashboards powered by Amazon CloudWatch with standardized OpenTelemetry-compatible telemetry.
The service enables several advanced capabilities essential for production deployment: centralized agent management and versioning through the Amazon Bedrock AgentCore control plane, A/B testing of different workflow strategies and prompt variations across the five subagents within the Test Generator, performance monitoring with metrics tracking token usage and latency across the parallel execution phases, automated agent updates without disrupting active test generation workflows, and session persistence for maintaining context when QA engineers iteratively refine test suite outputs. This integration positions SAARAM for enterprise-scale deployment while providing the operational visibility and reliability controls that transform it from a proof of concept into a production system capable of handling the AMET team’s ambitious goal of expanding beyond Payments QA to serve the broader organization.
Conclusion
SAARAM demonstrates how AI can change traditional QA processes when designed with human expertise at its core. By reducing test case creation from 1 week to hours while improving quality and coverage, we’ve enabled faster feature deployment and enhanced payment experiences for millions of customers across the MENA region. The key to our success wasn’t merely advanced AI technology—it was the combination of human expertise, thoughtful architecture design, and robust engineering practices. Through careful study of how experienced QA professionals think, implementation of multi-agent systems that mirror these cognitive patterns, and minimization of AI limitations through structured outputs and context engineering, we’ve created a system that enhances rather than replaces human expertise.
For teams considering similar initiatives, our experience emphasizes three critical success factors: invest time understanding the cognitive processes of domain experts, implement structured outputs to minimize hallucinations, and design multi-agent architectures that mirror human problem-solving approaches. These QA tools aren’t intended to replace human testers, they amplify their expertise through intelligent automation. If you’re interested in starting your journey on agents with AWS, check out our sample Strands Agents implementations repo or our newest launch, Amazon Bedrock AgentCore, and the end-to-end examples with deployment on our Amazon Bedrock AgentCore samples repo.
About the authors
 Jayashree is a Quality Assurance Engineer at Amazon Music Tech, where she combines rigorous manual testing expertise with an emerging passion for GenAI-powered automation. Her work focuses on maintaining high system quality standards while exploring innovative approaches to make testing more intelligent and efficient. Committed to reducing testing monotony and enhancing product quality across Amazon’s ecosystem, Jayashree is at the forefront of integrating artificial intelligence into quality assurance practices.
Jayashree is a Quality Assurance Engineer at Amazon Music Tech, where she combines rigorous manual testing expertise with an emerging passion for GenAI-powered automation. Her work focuses on maintaining high system quality standards while exploring innovative approaches to make testing more intelligent and efficient. Committed to reducing testing monotony and enhancing product quality across Amazon’s ecosystem, Jayashree is at the forefront of integrating artificial intelligence into quality assurance practices.
 Harsha Pradha G is a Snr. Quality Assurance Engineer part in MENA Payments at Amazon. With a strong foundation in building comprehensive quality strategies, she brings a unique perspective to the intersection of QA and AI as an emerging QA-AI integrator. Her work focuses on bridging the gap between traditional testing methodologies and cutting-edge AI innovations, while also serving as an AI content strategist and AI Author.
Harsha Pradha G is a Snr. Quality Assurance Engineer part in MENA Payments at Amazon. With a strong foundation in building comprehensive quality strategies, she brings a unique perspective to the intersection of QA and AI as an emerging QA-AI integrator. Her work focuses on bridging the gap between traditional testing methodologies and cutting-edge AI innovations, while also serving as an AI content strategist and AI Author.
 Fahim Surani is Senior Solutions Architect as AWS, helping customers across Financial Services, Energy, and Telecommunications design and build cloud and generative AI solutions. His focus since 2022 has been driving enterprise cloud adoption, spanning cloud migrations, cost optimization, event-driven architectures, including leading implementations recognized as early adopters of Amazon’s latest AI capabilities. Fahim’s work covers a wide range of use cases, with a primary interest in generative AI, agentic architectures. He is a regular speaker at AWS summits and industry events across the region.
Fahim Surani is Senior Solutions Architect as AWS, helping customers across Financial Services, Energy, and Telecommunications design and build cloud and generative AI solutions. His focus since 2022 has been driving enterprise cloud adoption, spanning cloud migrations, cost optimization, event-driven architectures, including leading implementations recognized as early adopters of Amazon’s latest AI capabilities. Fahim’s work covers a wide range of use cases, with a primary interest in generative AI, agentic architectures. He is a regular speaker at AWS summits and industry events across the region.