Artificial Intelligence
Processing PDF documents with a human loop using Amazon Textract and Amazon Augmented AI
Businesses across many industries, including financial, medical, legal, and real estate, process a large number of documents for different business operations. Healthcare and life science organizations, for example, need to access data within medical records and forms to fulfill medical claims and streamline administrative processes. Amazon Textract is a machine learning (ML) service that makes it easy to process documents at a large scale by automatically extracting text and data from virtually any type of document. For example, it can extract patient information from an insurance claim or values from a table in a scanned medical chart.
Depending on the business use case, you may want to have a human review of ML predictions. For example, extracting information from a scanned mortgage application or medical claim form might require human review of certain fields due to regulatory requirements or potentially low-quality scans. Amazon Augmented AI (Amazon A2I) allows you to build and manage such human review workflows. This allows human review of ML predictions when needed based on a confidence score threshold, and you can audit the predictions on an ongoing basis. For more information, see Using with Amazon Textract with Amazon Augmented AI for processing critical documents.
In this post, we show how you can use Amazon Textract and Amazon A2I to build a workflow that enables multi-page PDF document processing with a human reviewers loop.
Solution overview
The following architecture shows how you can have a serverless architecture to process multi-page PDF documents with a human review. Although Amazon Textract can process images (PNG and JPG) and PDF documents, Amazon A2I human reviewers need to have individual pages as images and process them individually using the AnalyzeDocument API of Amazon Textract.
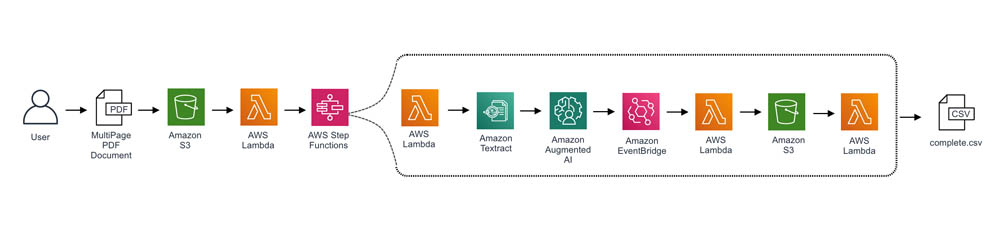
To implement this architecture, we take advantage of Amazon Step Functions to build the overall workflow. As the workflow starts, it extracts individual pages from the multi-page PDF document. It then uses the Map state to process multiple pages concurrently using the AnalyzeDocument API. When we call Amazon Textract, we also specify the Amazon A2I workflow as part of the request. This workflow is configured to trigger when form fields are detected below a certain confidence threshold. If triggered, Amazon Textract returns the extracted text and data along with the details. When the human review is complete, the callback task token is used to resume the state machine, combine the pages’ results, and store them in an output Amazon Simple Storage Service (Amazon S3) bucket.
For more information about the demo solution, see the GitHub repo.
Prerequisites
Before you get started, you must install the following prerequisites:
- Node.js
- Python
- AWS Command Line Interface (AWS CLI)—for instructions, see Installing the AWS CLI)
Deploying the solution
The following steps deploy the reference implementation in your AWS account. The solution deploys different components, including an S3 bucket, a Step Function, an Amazon Simple Queue Service (Amazon SQS) queue, and AWS Lambda functions using the AWS Cloud Development Kit (AWS CDK), which is an open-source software development framework to model and provision your cloud application resources using familiar programming languages.
- Install AWS CDK:
- Download the GitHub repo to your local machine:
- Go to the folder
multipagepdfa2iand enter the following: - Bootstrap AWS CDK:
- Deploy:
Creating a private work team
A work team is a group of people that you select to review your documents. You can create a work team from a workforce, which is made up of Amazon Mechanical Turk workers, vendor-managed workers, or your own private workers that you invite to work on your tasks. Whichever workforce type you choose, Amazon A2I takes care of sending tasks to workers. For this post, you create a work team using a private workforce and add yourself to the team to preview the Amazon A2I workflow.
To create and manage your private workforce, you can use the Labeling workforces page on the Amazon SageMaker console. On the console, you can create a private workforce by entering worker emails or importing a pre-existing workforce from an Amazon Cognito user pool.
If you already have a work team for Amazon SageMaker Ground Truth, you can use the same work team with Amazon A2I and skip to the following section.
To create your private work team, complete the following steps:
- On the Amazon SageMaker console, choose Labeling workforces.
- On the Private tab, choose Create private team.

- Choose Invite new workers by email.
- In the Email addresses box, enter the email addresses for your work team (for this post, enter your email address).
You can enter a list of up to 50 email addresses, separated by commas.
- Enter an organization name and contact email.
- Choose Create private team.

After you create the private team, you get an email invitation. The following screenshot shows an example email.
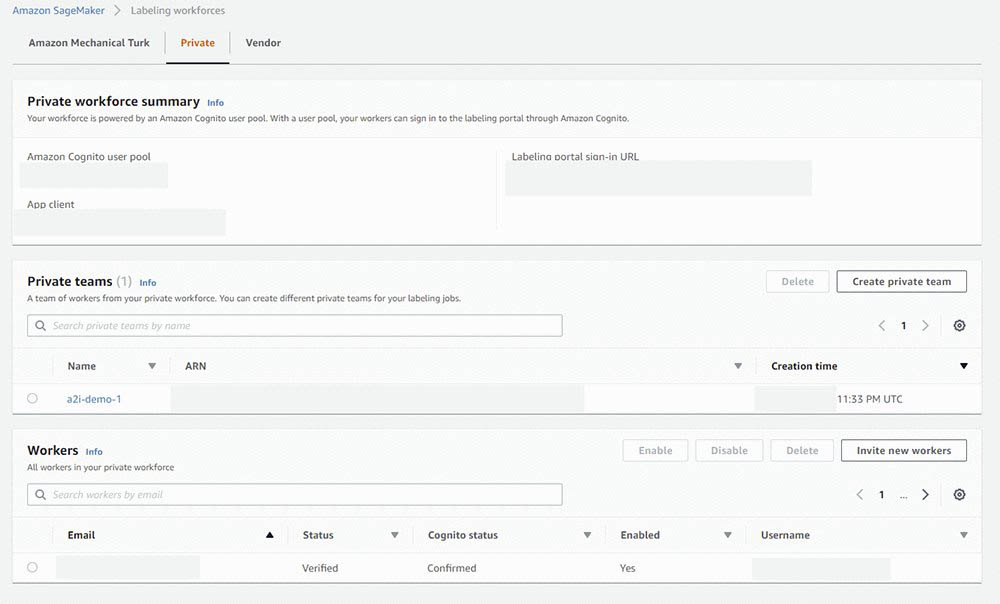
After you click the link and change your password, you are registered as a verified worker for this team. The following screenshot shows the updated information on the Private tab.
Your one-person team is now ready, and you can create a human review workflow.
Creating a human review workflow
You use a human review workflow to do the following:
- Define the business conditions under which the Amazon Textract predictions of the document content go to a human for review. For example, you can set confidence thresholds for important words in the form that the model must meet. If inference confidence for that word (or form key) falls below your confidence threshold, the form and prediction go for human review.
- Create instructions to help workers complete your document review task.
- On the Amazon SageMaker console, navigate to the Human review workflows page
- Choose Create human review workflow.

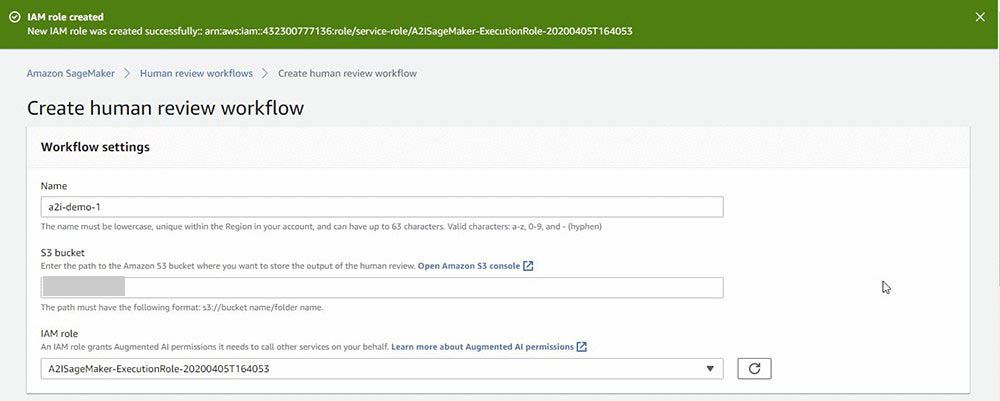
- In the Workflow settings section, for Name, enter a unique workflow name.
- For S3 bucket, enter the S3 bucket that was created in CDK deployment step. It should have a name format as
multipagepdfa2i-multipagepdf-xxxxxxxxx. This S3 bucket is where A2I will store the human review results.

- For IAM role, choose Create a new role from the drop-down menu. Amazon A2I can create a role automatically for you.

- For S3 buckets you specify, select Specific S3 buckets.
- Enter the S3 bucket you specified earlier in Step 3; for example,
multipagepdfa2i-multipagepdf-xxxxxxxxx. - Choose Create.
You see a confirmation when role creation is complete, and your role is now pre-populated in the IAM role drop-down menu.
- For Task type, select Amazon Textract – Key-value pair extraction.
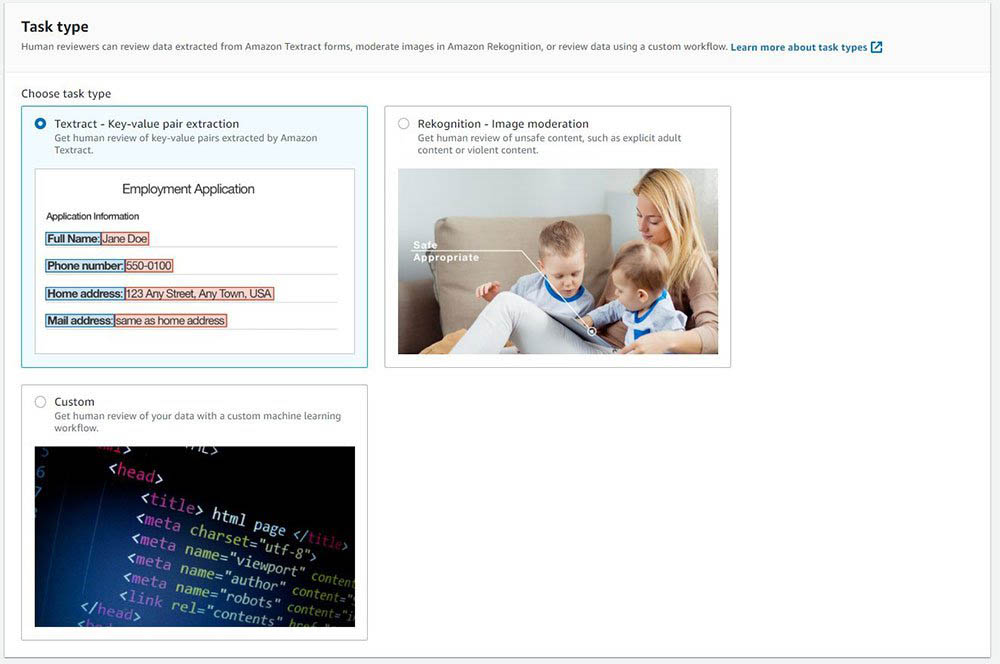
Defining the trigger conditions
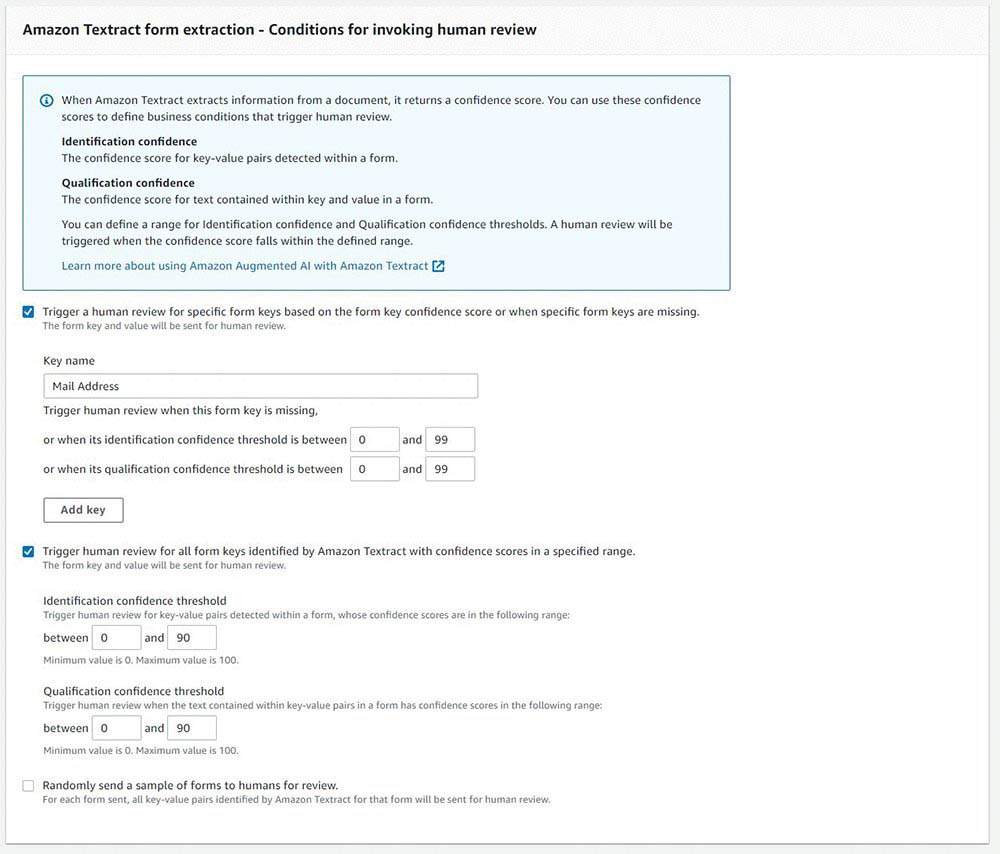
For this post, you want to trigger a human review if the key Mail Address is identified with a confidence score of less than 99% or not identified by Amazon Textract in the document. For all other keys, a human review starts if a key is identified with a confidence score less than 90%.
- Select Trigger a human review for specific form keys based on the form key confidence score or when specific form keys are missing.
- For Key name, enter
Mail Address. - Set the identification confidence threshold between 0 and 99.
- Set the qualification confidence threshold between 0 and 99.
- Select Trigger a human review for all form keys identified by Amazon Textract with confidence scores in a specific range.
- Set Identification confidence threshold between 0 and 90.
- Set Qualification confidence threshold between 0 and 90.
For model-monitoring purposes, you can also randomly send a specific percent of pages for human review. This is the third option on the Conditions for invoking human review page: Randomly send a sample of forms to humans for review. This post doesn’t include this condition.
Creating a UI template
In the next steps, you create a UI template that the worker sees for document review. Amazon A2I provides pre-built templates that workers use to identify key-value pairs in documents.
- In the Worker task template creation section, select Create from a default template.
- For Template name, enter a name.

When you use the default template, you can provide task-specific instructions to help the worker complete your task. For this post, you can enter instructions similar to the default instructions you see in the console.
- Under Task Description, enter something similar to
Please review the Key Value Pairs in this document. - Under Instructions, review the default instructions provided and make modifications as needed.

- In the Workers section, select Private.
- For Private teams, choose the work team you created earlier.
- Choose Create.

You’re redirected to the Human review workflows page and see a confirmation message similar to the following screenshot.
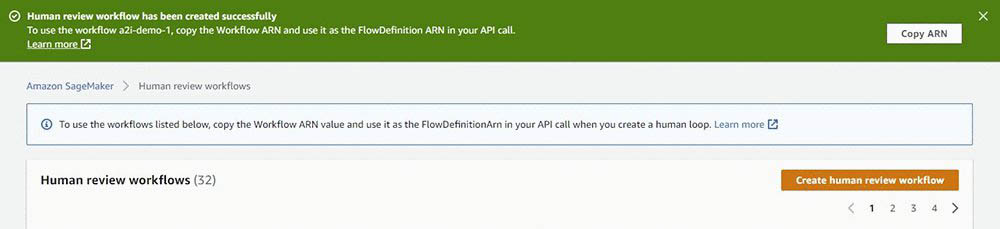
Record your new human review workflow ARN, which you use to configure your human loop in the next section.
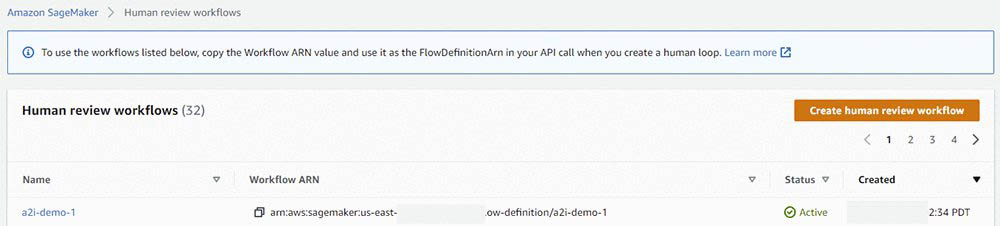
Updating the solution with the Human Review workflow
You’re now ready to add your human review workflow ARN.
- Within the code you downloaded from GitHub repo, open the file
multipagepdfa2i/multipagepdfa2i_stack.py.
On line 23, you should see the following code:
- Within the quotes, enter the human review workflow ARN you copied at the end of the last section.
Line 23 should now look like the following code:
- Save the changes you made.
- Deploy by entering the following code:
Testing the workflow
To test your workflow, complete the following steps:
- Create a folder named
uploadsin the S3 bucket that was created by CDK deployment (Example:multipagepdfa2i-multipagepdf-xxxxxxxxx) - Upload the sample PDF document to the
uploadsFor example,uploads/Sampledoc.pdf.

- On the Amazon SageMaker console, choose Labeling workforces.
- On the Private tab, choose the link under Labeling portal sign-in URL.

- Sign in with the account you configured with Amazon Cognito.
If the document required a human review, a job appears under Jobs section .
- Select the job you want to complete and choose Start working.

In the reviewer UI, you see instructions and the first document to work on. You can use the toolbox to zoom in and out, fit image, and reposition document. See the following screenshot.
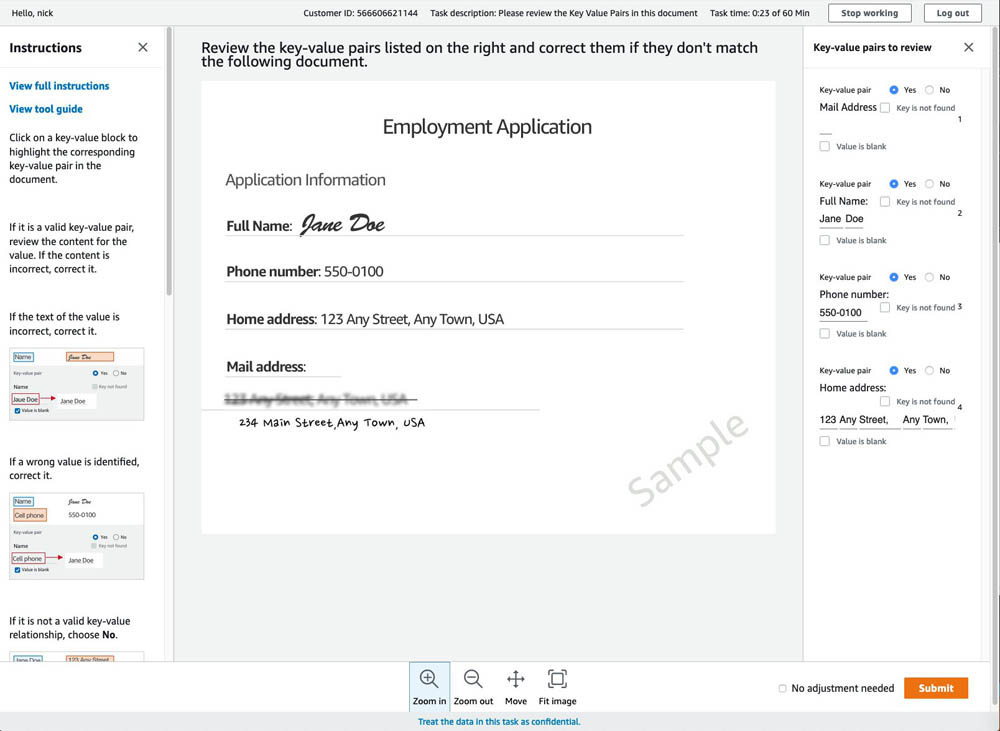
This UI is specifically designed for document-processing tasks. On the right side of the preceding screenshot, the key-value pairs are automatically pre-filled with the Amazon Textract response. As a worker, you can quickly refer to this sidebar to make sure the key-values are identified correctly (which is the case for this post).
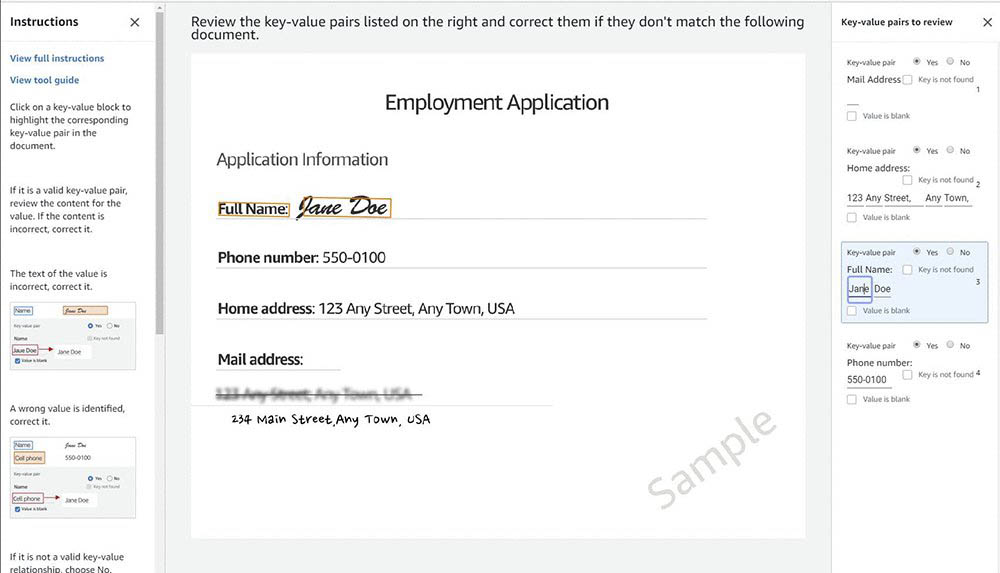
When you select any field on the right, a corresponding bounding box appears, which highlights its location on the document. See the following screenshot.
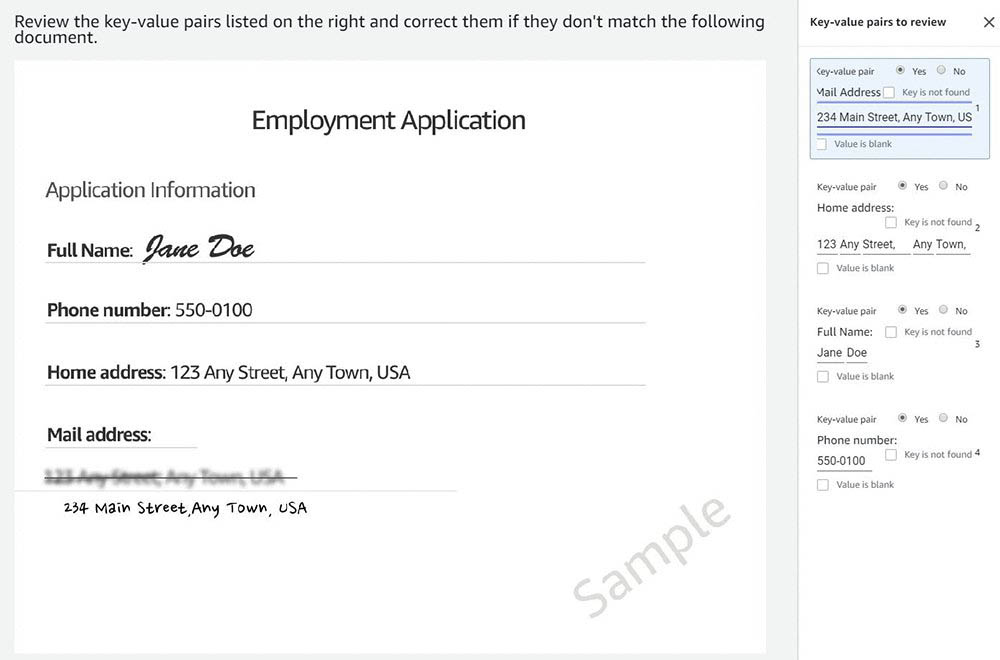
In the following screenshot, Amazon Textract didn’t identify Mail Address. The human review workflow identified this as an important field. Even though Amazon Textract didn’t identify it, the worker task UI asks you to enter d details on the right side.
There may be a series of pages you need to submit based on the Amazon Textract confidence score ranges you configured. When you finish reviewing them, continue with steps below.
- When you complete the human review, go to the S3 bucket you used earlier (Example:
multipagepdfa2i-multipagepdf-xxxxxxxxx) - In the
completefolder, choose the folder that has the name of input document (Example:uploads-Sampledoc.pdf-b5d54fdb75b143ee99f7524de56626a3).
That folder contains output.csv, which contains all your key-value pairs.
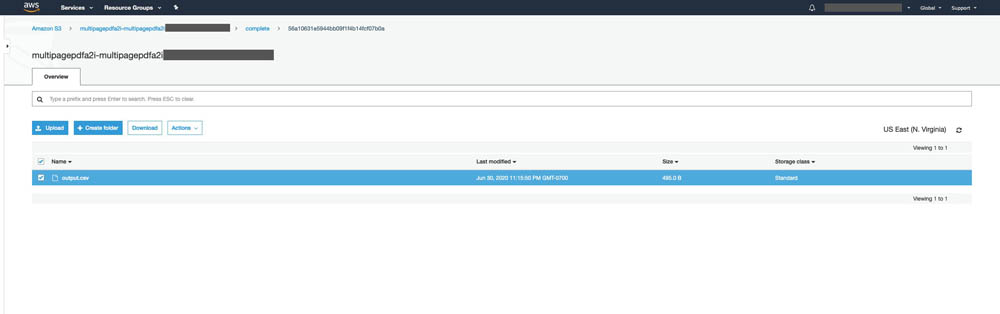
The following screenshot shows the content of an example output.csv file.
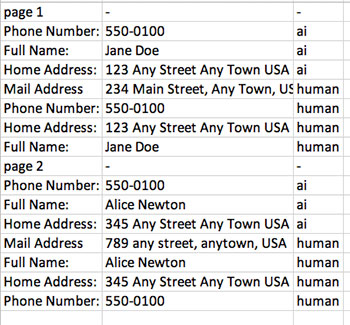
Conclusion
In this post, we showed you how to use Amazon Textract and Amazon A2I to automatically extract data from scanned multi-page PDF documents, and the human review of the pages for given business criteria. For more information about Amazon Textract and Amazon A2I, see Using Amazon Augmented AI with Amazon Textract.
For video presentations, sample Jupyter notebooks, or more information about use cases like document processing, content moderation, sentiment analysis, text translation, and more, see Amazon Augmented AI Resources.
About the Authors
 Nicholas Nelson is an AWS Solutions Architect for Strategic Accounts based out of Seattle, Washington. His interests and experience include Computer Vision, Serverless Technology, and Construction Technology. Outside of work, you can find Nicholas out cycling, paddle boarding, or grilling!
Nicholas Nelson is an AWS Solutions Architect for Strategic Accounts based out of Seattle, Washington. His interests and experience include Computer Vision, Serverless Technology, and Construction Technology. Outside of work, you can find Nicholas out cycling, paddle boarding, or grilling!
 Kashif Imran is a Principal Solutions Architect at Amazon Web Services. He works with some of the largest AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement computer vision applications at scale. His expertise spans application architecture, serverless, containers, NoSQL and machine learning.
Kashif Imran is a Principal Solutions Architect at Amazon Web Services. He works with some of the largest AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement computer vision applications at scale. His expertise spans application architecture, serverless, containers, NoSQL and machine learning.
 Anuj Gupta is Senior Product Manager for Amazon Augmented AI. He focuses on delivering products that make it easier for customers to adopt machine learning. In his spare time, he enjoys road trips and watching Formula 1.
Anuj Gupta is Senior Product Manager for Amazon Augmented AI. He focuses on delivering products that make it easier for customers to adopt machine learning. In his spare time, he enjoys road trips and watching Formula 1.