Artificial Intelligence
Reduce ML inference costs on Amazon SageMaker with hardware and software acceleration
Amazon SageMaker is a fully-managed service that enables data scientists and developers to build, train, and deploy machine learning (ML) models at 50% lower TCO than self-managed deployments on Elastic Compute Cloud (Amazon EC2). Elastic Inference is a capability of SageMaker that delivers 20% better performance for model inference than AWS Deep Learning Containers on EC2 by accelerating inference through model compilation, model server tuning, and underlying hardware and software acceleration technologies.
Inference is the process of making predictions using a trained ML model. For production ML applications, inference accounts for up to 90% of total compute costs. Hence, when deploying an ML model for inference, accelerating inference performance on low-cost instance types is an effective way to reduce overall compute costs while meeting performance requirements such as latency and throughput. For example, running ML models on GPU-based instances provides good inference performance; however, selecting the right instance size and optimizing GPU utilization is challenging because different ML models require different amounts of compute and memory resources.
Elastic Inference Accelerators (EIA) solve this problem by enabling you to attach the right amount of GPU-powered inference acceleration to any Amazon SageMaker ML instance. You can choose any CPU instance type that best suits your application’s overall compute and memory needs, and separately attach the right amount of GPU-powered inference acceleration needed to satisfy your performance requirements. This allows you to reduce inference costs by using compute resources more efficiently. Along with hardware acceleration, Elastic Inference offers software acceleration through SageMaker Neo, a capability of SageMaker that automatically compiles ML models for any ML framework and to any target hardware. With SageMaker Neo, you don’t need to set up third-party or framework-specific compiler software or tune the model manually for optimizing inference performance. With Elastic Inference, you can combine software and hardware acceleration to get the best inference performance on SageMaker.
This post demonstrates how you can use hardware and software-based inference acceleration to reduce costs and improve latency for pre-trained TensorFlow models on Amazon SageMaker. We show you how to compile a pre-trained TensorFlow ResNet-50 model using SageMaker Neo and how to deploy this model to a SageMaker Endpoint with Elastic Inference.
Setup
First, we need to ensure we have SageMaker Python SDK >=2.32.1 and import necessary Python packages. If you are using SageMaker Notebook Instances, select conda_tensorflow_p36 as your kernel. Note that you may have to restart your kernel after upgrading packages.
Next, we’ll get the IAM execution role and a few other SageMaker specific variables from our notebook environment so that SageMaker can access resources in your AWS account. See the documentation for more information on how to set this up.
Get pre-trained model for compilation
SageMaker Neo supports compiling TensorFlow/Keras, PyTorch, ONNX, and XGBoost models. However, only Neo-compiled TensorFlow models are supported on EIA as of this writing. TensorFlow models should be in SavedModel format or frozen graph format. Learn more here.
Import ResNet50 model from Keras
We will import ResNet50 model from Keras applications and create a model artifact model.tar.gz.
Upload model artifact to S3
SageMaker Neo expects a path to the model artifact in Amazon S3, so we will upload the model artifact to an S3 bucket.
Compile model for EI Accelerator using SageMaker Neo
Now the model is ready to be compiled by SageMaker Neo. Note that ml_eia2 needs to be set for target_instance_family field in order for the model to be optimized for EI accelerator deployment. If you want to compile your own model for EI accelerator, refer to Neo compilation API. In order to compile the model, you also need to provide the model input_shape and any optional compiler_options to your model. Note that 32-bit floating-point types (FP32) are the default precision mode for ML models. We include this here to be explicit versus compiling with lower precision models. Learn more about advantages of different precision types here.
Deploy compiled model to an Endpoint with EI Accelerator attached
Deploying a model to a SageMaker Endpoint uses the same deploy function whether or not a model is compiled using SageMaker Neo. The only change required for utilizing EI Accelerator is to provide an accelerator_type parameter, which determines the type of EI accelerator to be attached to your endpoint. All supported types of accelerators can be found here.
Benchmarking endpoints
Once the endpoint is created, we will benchmark to measure latency. The model expects input shape of 1 x 224 x 224 x 3, so we expand the dog image (224x224x3) with a batch size of 1 to be compatible with the model input. The benchmark first runs a series of 100 warmup inferences, and then runs 1000 inferences to make sure that we get an accurate estimate of latency ignoring startup times. Latency percentiles are reported from these 1000 inferences.

From the benchmark above, the output will be similar to the following:
Compile and benchmark model with quantization
Quantization based model optimizations represent model weights in lower precision (e.g. FP16) which increases throughput and offers lower latency. Using FP16 precision in particular provides faster performance than FP32 with effectively no drop (<0.1%) in model accuracy. When you enable FP16 precision, SageMaker Neo chooses kernels from both FP16 and FP32 precision. For the ResNet50 model in this post, we are able to compile the model along with FP16 quantization by setting the precision_mode under compiler_options.
Benchmark data for model compiled with FP16 will appear as follows:
Compare latency with unoptimized model on EIA
We could see that model compiled with FP16 precision mode is faster than the model compiled with FP32, now let’s get the latency for an uncompiled model as well.
Benchmark data for uncompiled model will appear as follows:
Clean up endpoints
Having an endpoint running will incur some costs. Therefore, we would delete the endpoint to release the resources after finishing this example.
Performance comparison
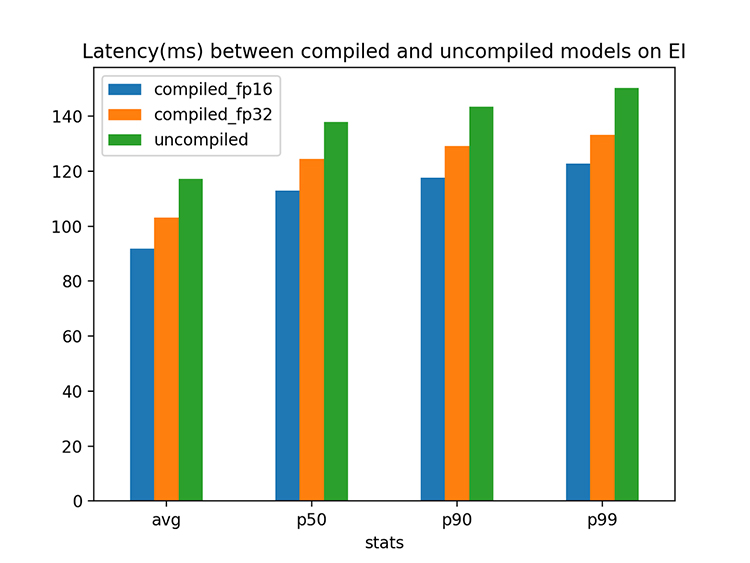
To understand the performance improvement from model compilation and quantization, you can visualize differences in percentile latency for models with different optimizations in following plot. For our model, we find that adding model compilation improves latency by 13.5% compared to the unoptimized model. Adding quantization (FP16) to the compiled model results in 27.5% improvement in latency compared to the unoptimized model.
Summary
SageMaker Elastic Inference is an easy-to-use solution for adding model optimizations to improve inference performance on Amazon SageMaker. With Elastic Inference accelerators, you can get GPU inference acceleration and remain more cost-effective than standalone SageMaker GPU instances. With SageMaker Neo, software-based acceleration provided by model optimizations further improves performance (27.5%) over unoptimized models.
If you have any questions or comments, use the Amazon SageMaker Discussion Forums or send an email to amazon-ei-feedback@amazon.com.
About the Authors
 Jiacheng Guo is a Software Engineer with AWS AI. He is passionate about building high performance deep learning systems with state-of-art techniques. In his spare time, he enjoys drifting on dirt track and playing with his Ragdoll cat.
Jiacheng Guo is a Software Engineer with AWS AI. He is passionate about building high performance deep learning systems with state-of-art techniques. In his spare time, he enjoys drifting on dirt track and playing with his Ragdoll cat.
 Santosh Bhavani is a Senior Technical Product Manager with the Amazon SageMaker Elastic Inference team. He focuses on helping SageMaker customers accelerate model inference and deployment. In his spare time, he enjoys traveling, playing tennis, and drinking lots of Pu’er tea.
Santosh Bhavani is a Senior Technical Product Manager with the Amazon SageMaker Elastic Inference team. He focuses on helping SageMaker customers accelerate model inference and deployment. In his spare time, he enjoys traveling, playing tennis, and drinking lots of Pu’er tea.