Artificial Intelligence
Semantic segmentation data labeling and model training using Amazon SageMaker
In computer vision, semantic segmentation is the task of classifying every pixel in an image with a class from a known set of labels such that pixels with the same label share certain characteristics. It generates a segmentation mask of the input images. For example, the following images show a segmentation mask of the cat label.
 |
 |
In November 2018, Amazon SageMaker announced the launch of the SageMaker semantic segmentation algorithm. With this algorithm, you can train your models with a public dataset or your own dataset. Popular image segmentation datasets include the Common Objects in Context (COCO) dataset and PASCAL Visual Object Classes (PASCAL VOC), but the classes of their labels are limited and you may want to train a model on target objects that aren’t included in the public datasets. In this case, you can use Amazon SageMaker Ground Truth to label your own dataset.
In this post, I demonstrate the following solutions:
- Using Ground Truth to label a semantic segmentation dataset
- Transforming the results from Ground Truth to the required input format for the SageMaker built-in semantic segmentation algorithm
- Using the semantic segmentation algorithm to train a model and perform inference
Semantic segmentation data labeling
To build a machine learning model for semantic segmentation, we need to label a dataset at the pixel level. Ground Truth gives you the option to use human annotators through Amazon Mechanical Turk, third-party vendors, or your own private workforce. To learn more about workforces, refer to Create and Manage Workforces. If you don’t want to manage the labeling workforce on your own, Amazon SageMaker Ground Truth Plus is another great option as a new turnkey data labeling service that enables you to create high-quality training datasets quickly and reduces costs by up to 40%. For this post, I show you how to manually label the dataset with the Ground Truth auto-segment feature and crowdsource labeling with a Mechanical Turk workforce.
Manual labeling with Ground Truth
In December 2019, Ground Truth added an auto-segment feature to the semantic segmentation labeling user interface to increase labeling throughput and improve accuracy. For more information, refer to Auto-segmenting objects when performing semantic segmentation labeling with Amazon SageMaker Ground Truth. With this new feature, you can accelerate your labeling process on segmentation tasks. Instead of drawing a tightly fitting polygon or using the brush tool to capture an object in an image, you only draw four points: at the top-most, bottom-most, left-most, and right-most points of the object. Ground Truth takes these four points as input and uses the Deep Extreme Cut (DEXTR) algorithm to produce a tightly fitting mask around the object. For a tutorial using Ground Truth for image semantic segmentation labeling, refer to Image Semantic Segmentation. The following is an example of how the auto-segmentation tool generates a segmentation mask automatically after you choose the four extreme points of an object.


Crowdsourcing labeling with a Mechanical Turk workforce
If you have a large dataset and you don’t want to manually label hundreds or thousands of images yourself, you can use Mechanical Turk, which provides an on-demand, scalable, human workforce to complete jobs that humans can do better than computers. Mechanical Turk software formalizes job offers to the thousands of workers willing to do piecemeal work at their convenience. The software also retrieves the work performed and compiles it for you, the requester, who pays the workers for satisfactory work (only). To get started with Mechanical Turk, refer to Introduction to Amazon Mechanical Turk.
Create a labeling job
The following is an example of a Mechanical Turk labeling job for a sea turtle dataset. The sea turtle dataset is from the Kaggle competition Sea Turtle Face Detection, and I selected 300 images of the dataset for demonstration purposes. Sea turtle isn’t a common class in public datasets so it can represent a situation that requires labeling a massive dataset.
- On the SageMaker console, choose Labeling jobs in the navigation pane.
- Choose Create labeling job.
- Enter a name for your job.
- For Input data setup, select Automated data setup.
This generates a manifest of input data. - For S3 location for input datasets, enter the path for the dataset.

- For Task category, choose Image.
- For Task selection, select Semantic segmentation.

- For Worker types, select Amazon Mechanical Turk.
- Configure your settings for task timeout, task expiration time, and price per task.
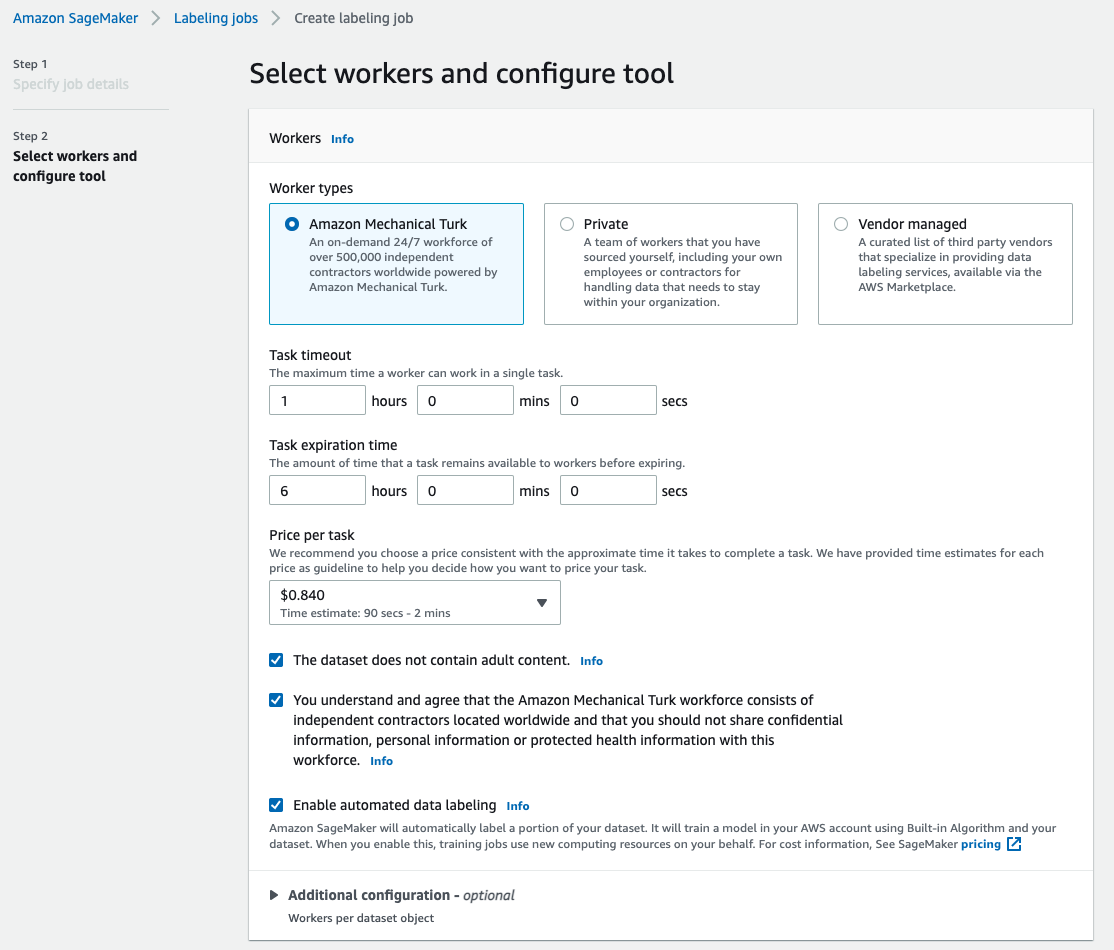
- Add a label (for this post,
sea turtle), and provide labeling instructions. - Choose Create.

After you set up the labeling job, you can check the labeling progress on the SageMaker console. When it’s marked as complete, you can choose the job to check the results and use them for the next steps.
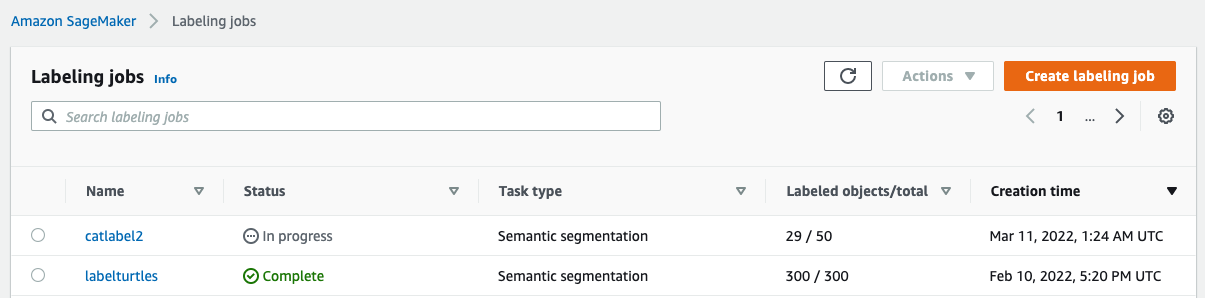
Dataset transformation
After you get the output from Ground Truth, you can use SageMaker built-in algorithms to train a model on this dataset. First, you need to prepare the labeled dataset as the requested input interface for the SageMaker semantic segmentation algorithm.
Requested input data channels
SageMaker semantic segmentation expects your training dataset to be stored on Amazon Simple Storage Service (Amazon S3). The dataset in Amazon S3 is expected to be presented in two channels, one for train and one for validation, using four directories, two for images and two for annotations. Annotations are expected to be uncompressed PNG images. The dataset might also have a label map that describes how the annotation mappings are established. If not, the algorithm uses a default. For inference, an endpoint accepts images with an image/jpeg content type. The following is the required structure of the data channels:
Every JPG image in the train and validation directories has a corresponding PNG label image with the same name in the train_annotation and validation_annotation directories. This naming convention helps the algorithm associate a label with its corresponding image during training. The train, train_annotation, validation, and validation_annotation channels are mandatory. The annotations are single-channel PNG images. The format works as long as the metadata (modes) in the image helps the algorithm read the annotation images into a single-channel 8-bit unsigned integer.
Output from the Ground Truth labeling job
The outputs generated from the Ground Truth labeling job have the following folder structure:
The segmentation masks are saved in s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Each annotation image is a .png file named after the index of the source image and the time when this image labeling was completed. For example, the following are the source image (Image_1.jpg) and its segmentation mask generated by the Mechanical Turk workforce (0_2022-02-10T17:41:04.724225.png). Notice that the index of the mask is different than the number in the source image name.
 |
 |
The output manifest from the labeling job is in the /manifests/output/output.manifest file. It’s a JSON file, and each line records a mapping between the source image and its label and other metadata. The following JSON line records a mapping between the shown source image and its annotation:
The source image is called Image_1.jpg, and the annotation’s name is 0_2022-02-10T17:41: 04.724225.png. To prepare the data as the required data channel formats of the SageMaker semantic segmentation algorithm, we need to change the annotation name so that it has the same name as the source JPG images. And we also need to split the dataset into train and validation directories for source images and the annotations.
Transform the output from a Ground Truth labeling job to the requested input format
To transform the output, complete the following steps:
- Download all the files from the labeling job from Amazon S3 to a local directory:
- Read the manifest file and change the names of the annotation to the same names as the source images:
- Split the train and validation datasets:
- Make a directory in the required format for the semantic segmentation algorithm data channels:
- Move the train and validation images and their annotations to the created directories.
- For images, use the following code:
- For annotations, use the following code:
- Upload the train and validation datasets and their annotation datasets to Amazon S3:
SageMaker semantic segmentation model training
In this section, we walk through the steps to train your semantic segmentation model.
Follow the sample notebook and set up data channels
You can follow the instructions in Semantic Segmentation algorithm is now available in Amazon SageMaker to implement the semantic segmentation algorithm to your labeled dataset. This sample notebook shows an end-to-end example introducing the algorithm. In the notebook, you learn how to train and host a semantic segmentation model using the fully convolutional network (FCN) algorithm using the Pascal VOC dataset for training. Because I don’t plan to train a model from the Pascal VOC dataset, I skipped Step 3 (data preparation) in this notebook. Instead, I directly created train_channel, train_annotation_channe, validation_channel, and validation_annotation_channel using the S3 locations where I stored my images and annotations:
Adjust hyperparameters for your own dataset in SageMaker estimator
I followed the notebook and created a SageMaker estimator object (ss_estimator) to train my segmentation algorithm. One thing we need to customize for the new dataset is in ss_estimator.set_hyperparameters: we need to change num_classes=21 to num_classes=2 (turtle and background), and I also changed epochs=10 to epochs=30 because 10 is only for demo purposes. Then I used the p3.2xlarge instance for model training by setting instance_type="ml.p3.2xlarge". The training completed in 8 minutes. The best MIoU (Mean Intersection over Union) of 0.846 is achieved at epoch 11 with a pix_acc (the percent of pixels in your image that are classified correctly) of 0.925, which is a pretty good result for this small dataset.
Model inference results
I hosted the model on a low-cost ml.c5.xlarge instance:
Finally, I prepared a test set of 10 turtle images to see the inference result of the trained segmentation model:
The following images show the results.

The segmentation masks of the sea turtles look accurate and I’m happy with this result trained on a 300-image dataset labeled by Mechanical Turk workers. You can also explore other available networks such as pyramid-scene-parsing network (PSP) or DeepLab-V3 in the sample notebook with your dataset.
Clean up
Delete the endpoint when you’re finished with it to avoid incurring continued costs:
Conclusion
In this post, I showed how to customize semantic segmentation data labeling and model training using SageMaker. First, you can set up a labeling job with the auto-segmentation tool or use a Mechanical Turk workforce (as well as other options). If you have more than 5,000 objects, you can also use automated data labeling. Then you transform the outputs from your Ground Truth labeling job to the required input formats for SageMaker built-in semantic segmentation training. After that, you can use an accelerated computing instance (such as p2 or p3) to train a semantic segmentation model with the following notebook and deploy the model to a more cost-effective instance (such as ml.c5.xlarge). Lastly, you can review the inference results on your test dataset with a few lines of code.
Get started with SageMaker semantic segmentation data labeling and model training with your favorite dataset!
About the Author
 Kara Yang is a Data Scientist in AWS Professional Services. She is passionate about helping customers achieve their business goals with AWS cloud services. She has helped organizations build ML solutions across multiple industries such as manufacturing, automotive, environmental sustainability and aerospace.
Kara Yang is a Data Scientist in AWS Professional Services. She is passionate about helping customers achieve their business goals with AWS cloud services. She has helped organizations build ML solutions across multiple industries such as manufacturing, automotive, environmental sustainability and aerospace.