Artificial Intelligence
Use contextual information and third party data to improve your recommendations
Have you noticed that your shopping preferences are influenced by the weather? For example, on hot days would you rather drink a lemonade vs. a hot coffee?
Customers from consumer-packaged goods (CPG) and retail industries wanted to better understand how weather conditions like temperature and rain can be used to provide better purchase suggestions to consumers. Data was taken over a year long period. Based on observations like demand for refreshing beverages increasing on hot days, customers want to enrich their Amazon Personalize models with weather information.
In December 2019, AWS announced support for contextual recommendations in Amazon Personalize. This feature allows you to include contextual information with interactions when training a model, as well as include context when generating recommendations for users. For more information about how to implement contextual recommendations in real time, see Increasing the relevance of your Amazon Personalize recommendations by leveraging contextual information.
In this post, we share a hands-on approach to include context when generating recommendations, by using data from our partners in the AWS Data Exchange, a service that makes it easy to find, subscribe to, and use third-party data in the cloud.
Solution overview
For this example, we use a subset of the temperatures and precipitation dataset provided by Weather Trends International, combined with a fictitious dataset representing a bottler company beverage catalog and a user demo dataset from the Retail Demo Store. Retail Demo Store is an application and workshop platform intended as an educational tool for demonstrating how to use AWS services to build compelling customer experiences for ecommerce.
With all three datasets, we create sampled interactions to mimic a direct-to-customer ecommerce experience and an Amazon Personalize model to show how weather affects the recommendations for different users.
Preparing the data
First, we prepare the data to be used by Amazon Personalize. Let’s look at each dataset.
interactions.csv
An interactions dataset stores historical and real-time data from interactions between users and items. At minimum, you must provide the following for each interaction: User ID, Item ID, and Timestamp (in Unix epoch time format). You can also include metadata fields to further describe the interaction. For example, you can include the event type or other relevant contextual information like device type used or daily temperature.
To create the interactions dataset, we use a slightly modified upsampling process from Retail Demo Store. Basically, we create fictitious interactions events between our users and items, and add the average temperature for that day as a categorical attribute in our interaction’s dataset. Our ranges are as follows:
- Less than 5˚ Celsius =
very cold - Between 5–10˚ Celsius =
cold - Between 10–15˚ Celsius =
slightly cold - Between 15–21˚ Celsius =
lukewarm - Between 21–28˚ Celsius =
hot - More than 28˚ Celsius =
very hot
The upsampling process takes into account the user persona field to generate interactions. A user with the persona sparkling_waters_other can view, add, and purchase products from those categories.
The interactions dataset enriched with temperature data looks like the following screenshot.
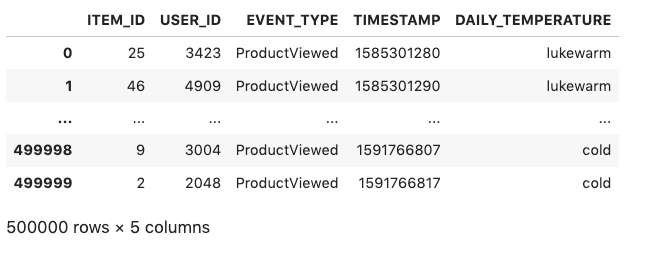
Context is environmental information that can shift rapidly over time, influencing your customer’s perception and behavior. We use DAILY_TEMPERATURE as an optional categorical attribute in our interactions dataset as context information at inference time.
Now let’s look at the distribution of temperatures from the interactions generated during the period of 3 months starting on March 25, 2020.
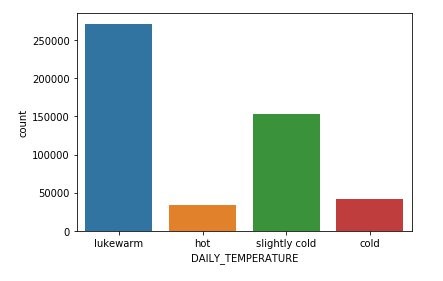
The preceding graphic shows that our interactions dataset doesn’t have many hot or cold days. This could be a good signal to the model to learn about the behavior customers display during those days and use that information at inference time. We can provide Amazon Personalize the weather context when asking for recommendations, and explore how the recommendations are influenced by this contextual information.
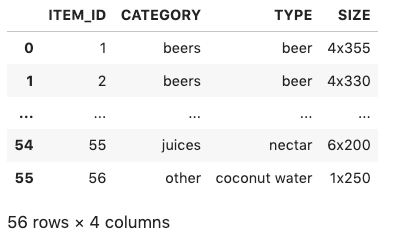
items.csv
This fictitious dataset simulates a product catalog for a CPG company.
The items dataset stores metadata about your items. This dataset is optional when using Amazon Personalize; however, in this use case we need to include attributes category and size to test the recommendations behavior.
users.csv
This dataset is a subset of a fictitious dataset taken from the Retail Demo Store project.
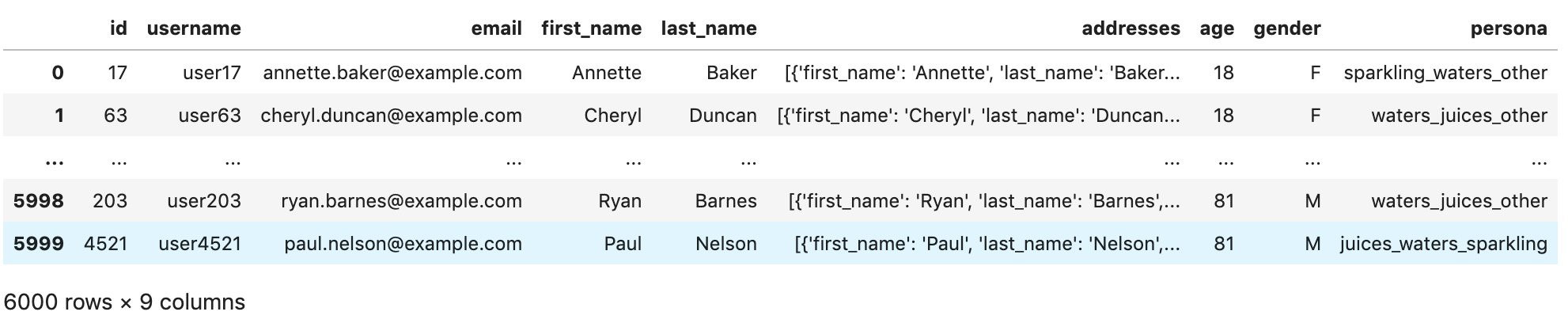
A users dataset stores metadata about your users. This can include information such as age, gender, name, and more. It’s an optional dataset when using Amazon Personalize.
For this post, we need the information from columns id and persona to be included in our model. persona is a categorical metadata field representing the categories of products that a customer likes and is used to test the recommendations behavior.
weather_data.csv
We use a real weather dataset provided by Weather Trends International to enrich the interactions dataset with temperature data.
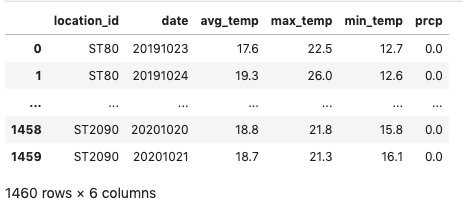
For simplicity, we keep only the rows representing Santiago de Chile, location_id = ‘ST650’.
Create Amazon Personalize components
When the datasets are ready to be imported, we’re ready to start creating an Amazon Personalize deployment. If you want to reproduce this process in your own account, you can use our sample notebook to complete the following steps:
- Create a dataset group with interactions, users, and items metadata datasets.
- Import historical data into each dataset.
- Configure a solution with a context-aware algorithm (aws-user-personalization) and train a solution version.
- Explore the solution version metrics.
- Create a campaign (managed recommendations endpoint).
- Query for personalized recommendations.
Explore Amazon Personalize recommendations
Now we can explore the recommendations provided by the campaign we created earlier. To do so, we pick a random user with ID 170 and get the top five beverages recommended for them with and without daily temperature as context.
The following screenshot shows the top five without context information.
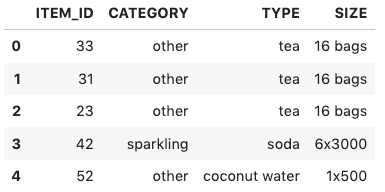
The following screenshot shows the top five with DAILY_TEMPERATURE = “cold”.

This user’s persona is other_waters_sparkling, which indicates a preference for those categories of beverages. The Amazon Personalize recommendations are consistent with their preferences with and without context. However, when we ask for recommendations on a cold day, the ranking of recommendations change:
- The category of the top three items in the ranking doesn’t change
- Tea item 33 went down from first to third in the ranking
- Coconut water, a refreshing item 52, was replaced by the same beverage in a bigger size format: item 15
These changes were driven by the behavior of customers in our dataset. For example, maybe user 170 likes different brands to prepare hot and iced tea, and the recommendations ranking is reflecting that preference on cold days.
Context is especially useful when dealing with new users without previous interactions. The following screenshot shows the top recommendations for a nonexistent user, ID 7000, without context.
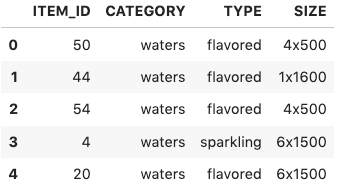
The following shows the recommendations for the same user with DAILY_TEMPERATURE = “hot”.
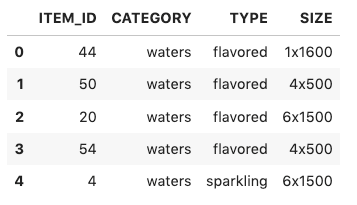
In the case of generating recommendations for a cold user, recommended items are the same, but the position in the ranking varies when considering a hot day vs. not providing context. In ecommerce with anonymous shopping functionality, this is particularly useful to prioritize which products to visualize, or suggest popular items to an unknown user considering their current context.
Conclusion
As stated in study How Context Affects Choice, context influences customer outcomes by altering the process by which decisions are made. Data like temperature, precipitation, device type, and channel of interaction can enrich models and improve the relevance of recommendations generated by Amazon Personalize. More relevant recommendations lead to better user experience and better business outcomes.
If you found this post useful and want to test how it works in real life, you can gather your own context data, or purchase datasets on AWS Data Exchange and use the approach of this post to put your use case into production. Feel free to explore any other creative ideas you can find.
If you want to recreate this use case with your own data, Daily Historical Weather Dataset – Demo is free for a month and code from this post is available on GitHub.
Additional resources about Amazon Personalize can be found on the Amazon Personalize GitHub repository.
About the Author
 Angel Goñi is an Enterprise Solutions Architect at AWS. He helps enterprise customers drive their digital transformation process leveraging AWS services. Usually works with Consumer Packaged Goods customers with emphasis on SAP migrations to AWS.
Angel Goñi is an Enterprise Solutions Architect at AWS. He helps enterprise customers drive their digital transformation process leveraging AWS services. Usually works with Consumer Packaged Goods customers with emphasis on SAP migrations to AWS.