AWS Storage Blog
How Zoolz migrated PBs of data to Amazon S3 Glacier Deep Archive
Zoolz, residing on the trusted and reliable AWS global infrastructure, designs, develops, and markets cloud storage management and disaster recovery (DR) solutions. The company’s suite includes easy-to-use and secure data backup and DR solutions for home users, small and medium businesses, large enterprises, and service providers. Using Zoolz, customers can back up almost any kind of files including videos, PDFs, office documents, audio files, and images.
Since 2011, Zoolz uses Amazon S3 and Glacier Direct to securely and reliably store tens of petabytes of customer mobile, backup, and archival data on AWS. They closely monitor customer usage patterns of this data and are frequently looking to implement ways to save on storage costs to pass on the savings to their end users. Amazon S3 Standard serves as the ideal storage class for Zoolz’s mobile, instant access, and syncing services. Glacier Direct offered the ideal low-cost storage for massive amounts of asynchronous long-term storage like backups and archives for DR workloads.
Zoolz is continuously innovating to create efficient and cost-effective solutions for customers. They wanted to use S3 Glacier Deep Archive to create a new data archiving solution. The plan was to store larger files on S3 Glacier Deep Archive at a low cost with file snippets on S3 Standard. Doing so would enable customers to perform actions like instant preview of their archival data. To drive this new innovative approach, the Zoolz engineering team wanted to seamlessly migrate multiple PBs of data that they had stored in Glacier Direct into S3 Glacier Deep Archive. This would allow them to use the unified Amazon S3 APIs across all Amazon S3 storage classes streamlining their workflows, while also significantly lowering their AWS bill.
In this post, we discuss how Zoolz successfully migrated petabytes of data in six weeks from Amazon Glacier Direct to S3 Glacier Deep Archive, saving 75% on their monthly storage costs for the data they migrated.
The evolution of Amazon Glacier Direct to Amazon S3 Glacier storage class
Amazon S3 was introduced in 2006 as a secure, reliable, highly scalable, low-latency data storage service. AWS introduced Amazon Glacier in 2012, as a separate storage service for secure, reliable, and low-cost data archiving and backups. Although Glacier was not an S3 storage class, customers long thought of and used Amazon Glacier as a storage class. We added Glacier as an S3 storage class to make it even easier for customers to integrate their archival workloads and applications through things like S3 Lifecycle policies that move colder data into Amazon Glacier. S3 Glacier supports S3 APIs, AWS software development kits (SDKs), and the AWS Management Console. All of the existing Glacier direct APIs continue to work just as they have, but we’ve now made it even easier to use the S3 APIs to store data in the Amazon S3 Glacier storage class.
Amazon S3 Glacier Deep Archive
In 2018, AWS introduced Amazon S3 Glacier Deep Archive, a new Amazon S3 storage class that provides secure, durable object storage for long-term data retention and digital preservation. With storage costs in some Regions as low as $0.00099 per GB-month (less than one-tenth of one cent, or about $1 per TB-month), S3 Glacier Deep Archive offers the lowest cost storage in the cloud. At prices lower than what you’d pay storing and maintaining data in on-premises magnetic tape libraries or archiving data offsite, S3 Glacier Deep Archive reliably stores any amount of data. It is the ideal storage class for customers who must make archival, durable copies of data that are rarely, if ever, accessed.
S3 Glacier Deep Archive is easy to use and only requires minor configuration if you are already familiar with using other S3 storage classes like S3 Glacier. S3 Glacier Deep Archive is fully integrated with S3 features including S3 Storage Class Analysis, S3 Lifecycle policies, S3 Object Lock, S3 Replication, and server-side encryption – even with customer managed keys.
The easiest way to store data in S3 Glacier Deep Archive is to use the S3 PUT API to upload data directly. You can also upload data to S3 Glacier Deep Archive over the internet or using AWS Direct Connect and the AWS Management Console, AWS Storage Gateway, AWS Command Line Interface, or the AWS SDKs. S3 Glacier Deep Archive is integrated with Tape Gateway, a cloud-based virtual tape library feature of AWS Storage Gateway. With this capability, you can now manage your on-premises tape-based backups and reduce monthly storage costs by choosing to archive your new virtual tapes in either the S3 Glacier or S3 Glacier Deep Archive storage classes.
The data migration plan
Zoolz and AWS assembled a thoughtful data migration plan that involved retrieving the data from Glacier Direct and uploading to S3 Glacier Deep Archive using the S3 PUT APIs. The data migration plan developed successfully moved data while maintaining data security and data integrity.
- First, the Zoolz team categorized their data into two sets. The first set was made of critical archives and archives that were larger. The second set was of archives that were less critical to their end users and the archives that are smaller. The goal of categorization was to migrate the data in stages, to split the migration costs over two monthly billing cycles and provide a layer of compartmentalization.
- For each set, Zoolz requested a vault inventory from Glacier Direct and sorted the list in a time correlated order, or the order in which the archives appear on the inventory report.
- At scale, Zools had to perform these restores seamlessly alongside regular non-migration workloads. Zools made the retrieval requests at a certain transaction per second (TPS) rate to allow Glacier Direct to service retrieval requests at scale while they uploaded data to S3 Glacier Deep Archive.
The application workflow used multiple AWS services including Amazon SQS, Amazon CloudWatch, and Amazon EC2:
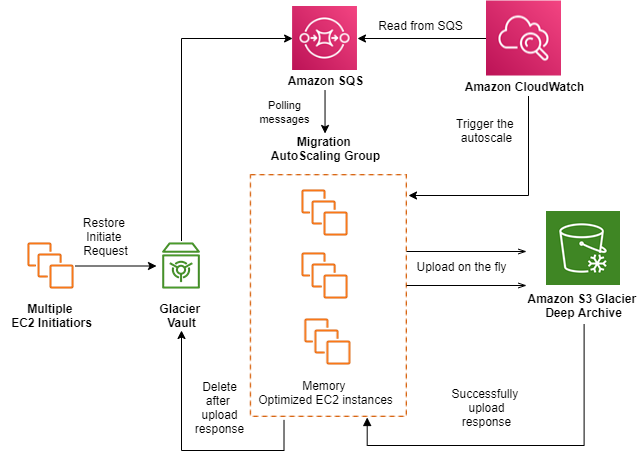
- Archive retrievals from Glacier Direct were initiated using bulk retrieval, the lowest-cost retrieval option in Glacier Direct, enabling retrieval of large amounts (even petabytes) of data inexpensively. Bulk retrievals typically complete within 5–12 hours.
- Because Glacier Direct retrieval requests are run asynchronously, the migration application was configured to poll the Amazon Simple Queue Service (Amazon SQS) queue for the archive to be available. Once available to download, the data was uploaded to S3 Glacier Deep Archive using the S3 PUT API.
- Upon successful upload of objects to S3 Glacier Deep Archive (verified through file hashes), the archives were deleted from Glacier Direct.
- EC2 Auto Scaling was used to maintain application availability and to allow dynamic scaling of EC2 instances defined by Amazon CloudWatch and Amazon SQS metrics.
Conclusion
In this post, we covered some of the thinking and actions behind Zoolz’s migration of data to Amazon S3 Glacier Deep Archive. Here are some of the key takeaways from Zoolz’s seamless data migration:
- Zoolz effectively and seamlessly migrated PBs of their data from Glacier Direct to the S3 Glacier Deep Archive storage class in less than six weeks, 1 month ahead of schedule.
- Zoolz reduced their overall archive storage costs by 55%. These savings are driven by a 75% reduction in the storage cost for objects moved from Glacier Direct to S3 Glacier Deep Archive.
- The company streamlined data classification strategies, which are now more granular and prescriptive about how data is stored in each of the Amazon S3 storage classes.
- Non-migration workloads proceeded undisrupted, enabling continued provisioning of our services for our customers, through effective management on transaction per second (TPS) during the migration process.
- Zoolz was able to start offering new plans with more competitive pricing for large archival datasets.
With seven different storage class options, Amazon S3 provides the broadest array of cost-optimization options available in the cloud today. S3 Glacier Deep Archive expanded AWS’s data archiving offerings, enabling you to select the optimal storage class based on cost and retrieval time.
Thanks for reading this blog post on how Zools was able to leverage Amazon S3 Glacier and S3 Glacier Deep Archive to realize significant storage-costs savings with minimal interruptions to their ongoing workloads. If you have any comments or questions, please don’t hesitate to leave them in the comments section.