亚马逊AWS官方博客
使用 Amazon EMR 上的 Apache MXNet 和 Apache Spark 进行分布式推理
在这篇博客文章中,我们将演示如何使用 Amazon EMR 上的 Apache MXNet (孵化) 和 Apache Spark 对大型数据集运行分布式离线推理。我们将说明离线推理如何起作用、为何离线推理具有挑战性以及如何利用 Amazon EMR 上的 MXNet 和 Spark 来应对这些挑战。
大型数据集上的分布式推理 – 需求与挑战
在进行有关深度学习模型的培训后,可以对新数据上运行推理了。可对需要即时反馈的任务 (如欺诈检测) 执行实时推理。这通常称作在线推理。或者,也可在预计算有用时执行离线推理。离线推理的常用案例是用于具有低延迟要求的服务,例如,要求对许多用户-产品分数进行排序和排名的推荐系统。在这些情况下,将使用离线推理来预计算推荐。结果将存储在低延迟存储中,而且将按需使用存储中的推荐。离线推理的另一个使用案例是使用从先进模型中生成的预测回填历史数据。作为一个假想的示例,报纸可利用此设置来使用从人员检测模型中预测的人员姓名回填已存档的照片。分布式推理还可用于基于历史数据测试新模型以验证这些模型在部署到生产之前是否会产生更好的结果。
通常,会在跨数百万条或更多记录的大型数据集上执行分布式推理。在合理的时间范围内处理这类大规模数据集需要一组计算机设置和深度学习功能。借助分布式群集,可使用数据分区、批处理和任务并行化来进行高吞吐量处理。但是,设置深度学习数据处理群集会面临一些挑战:
- 群集设置和管理:设置和监控节点、维护高可用性、部署和配置软件包等。
- 资源和作业管理:计划和跟踪作业、对数据进行分区和处理作业失败。
- 深度学习设置:部署、配置和运行深度学习任务。
接下来,本博客文章将介绍如何使用 Amazon EMR 上的 MXNet 和 Spark 来应对这些挑战。
使用 MXNet 和 Spark 进行分布式推理
利用 Amazon EMR,可轻松、经济高效地使用 Spark 和 MXNet 来启动可扩展群集。Amazon EMR 按秒计费,并且可使用 Amazon EC2 竞价型实例来降低工作负载的成本。
Amazon EMR 与 Spark 相结合,可简化群集和分布式作业管理的任务。Spark 是一种群集计算框架,支持各种数据处理应用程序。Spark 还可跨群集对数据进行高效分区以实现处理的并行化。Spark 与 Apache Hadoop 生态系统及多个其他大数据解决方案紧密集成。
MXNet 是一种快速且可扩展的深度学习框架,该框架已针对 CPU 和 GPU 上的性能进行优化。
我们将演练使用 Amazon EMR 上的 Spark 和 MXNet 在大型数据集上设置和执行分布式推理的步骤。我们将使用 MXNet model zoo上提供的预训练的ResNet-18图像识别模型。我们将对包含 60000 张彩色图像的公开可用的 CIFAR-10 数据集运行推理。该示例演示的是在 CPU 上运行的推理,但您可以轻松将其扩展为使用 GPU。
以下列表包含设置和执行的高级步骤,并且以下部分将详述这些步骤:
- 在 Amazon EMR 上设置 MXNet 和 Spark。
- 初始化 Spark 应用程序。
- 在群集上加载数据并对数据进行分区。
- 提取数据并将数据加载到 Spark 执行程序中。
- 在执行程序上使用 MXNet 进行推理。
- 收集预测。
- 使用 spark-submit 运行 Inference 应用程序。
- 监控 Spark 应用程序。
Amazon EMR 上的 MXNet 和 Spark 群集设置
我们将使用 Amazon EMR 创建带 Spark 和 MXNet 的群集,可使用 EMR 5.10.0 将该群集安装为应用程序。我们将使用 AWS CLI 创建包含 4 个 c4.8xlarge 类型的核心实例和 1 个 m3.xlarge 类型的主实例的群集,但您也可以使用 Amazon EMR 控制台创建该群集。
用于创建群集的命令如下所示。我们假设您拥有创建该命令的正确凭证。
替换以下参数:
- <YOUR-KEYPAIR> – 您的用于通过 SSH 登录主实例的 Amazon EC2 密钥对。
- <YOUR-SUBNET-ID> – 在其中启动群集的子网。您必须传递此参数以创建高计算实例,如 c4.8xlarge
- <AWS-REGION> – 要在其中启动群集的 AWS 区域
- <YOUR-S3-BUCKET-FOR-EMR-LOGS> – 应将 EMR 日志存储到的 S3 存储桶。
--bootstrap-actions 用于安装 Git、Pillow 和 Boto 库。
请参阅 AWS 文档以了解有关创建和使用 IAM 角色 (设置 Amazon EMR 群集所需) 的更多信息。
下面将讨论的代码段位于 mxnet-spark 文件夹下的 deeplearning-emr GitHub 存储库中。它包含用于使用 MXNet 和 Spark 运行推理的完整代码。我们还将在后续部分之一中讨论如何使用 spark-submit 提交 Spark 应用程序。 GitHub 存储库中的 mxnet-spark 文件夹包含以下 3 个文件:
- infer_main.py,此文件包含要在驱动程序上运行的代码;
- utils.py,此文件包含几个辅助标记方法;
- mxinfer.py,此文件包含用于在工作程序节点上下载模型文件、将字节加载到 numpy 以及在一批图像上运行预测的代码。
初始化
我们将使用 PySpark (Spark 的 Python 接口) 创建我们的应用程序。Spark 应用程序包含一个运行用户的主函数的驱动程序以及一个或多个并行运行各种任务的执行程序进程。
为执行 Spark 应用程序,该驱动程序会将工作拆分为多个作业。每个作业会进一步拆分为多个阶段,而每个阶段包含一系列并行运行的独立任务。任务是 Spark 中的最小工作单元并且执行相同代码,每个任务位于不同的数据分区 (大型分布式数据集的逻辑数据块) 中。
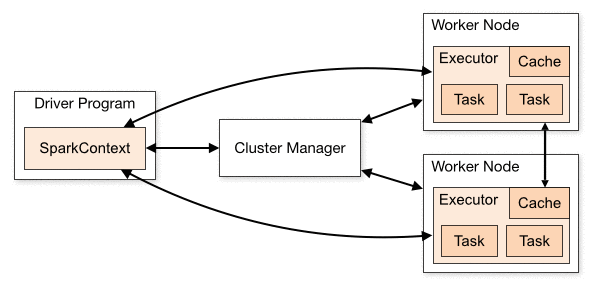
图像所有权: Apache Spark 文档
Spark 提供一个用于处理分布式数据集的抽象,即弹性分布式数据集 (RDD)。RDD 是一个已跨可并行操作的群集分区的对象的不可变的分布式集合。可通过并行处理集合或外部数据集来创建 RDD。
从较高的层面来说,分布式推理应用程序的管道如下所示:

默认情况下,Spark 在执行程序上为每个内核创建一个任务。由于 MXNet 具有内置的并行机制来有效使用所有 CPU 内核,因此,我们会将应用程序配置为仅为每个执行程序创建一个任务并让 MXNet 在该实例上使用所有内核。在以下代码中,我们将配置密钥 spark.executor.cores 设置为 1,然后在创建 SparkContext 时传递 conf 对象。在提交应用程序时,您将看到我们还将执行程序数设置为群集上可用的工作程序数。这使每个节点均有一个执行程序并关闭执行程序的动态分配。
在群集上加载数据并对数据进行分区
我们已将 CIFAR-10 数据复制到 Amazon S3 存储桶 mxnet-spark-demo。由于可在所有节点上访问存储在 S3 中的数据,因此,我们无需在驱动程序与执行程序之间移动数据。我们仅在驱动程序上提取 S3 密钥并使用 boto 库创建密钥的 RDD,后者是用于访问 AWS 服务的 Python 接口。此 RDD 将进行分区并分发到群集中的执行程序,并且我们将在这些执行程序上直接提取并处理少量图像。
我们将使用辅助标记方法 fetch_s3_keys (来自 utils.py) 以从 Amazon S3 存储桶获取所有密钥。此方法还采用一个前缀以列出以该前缀开头的密钥。在提交主应用程序时将传递这些参数。
由 args['batch'] 决定的批处理大小是在每个执行程序上可一次性提取、预处理和运行推理的图像的数量。这受每个任务可用的内存量的约束。 args['access_key'] 和 args['secret_key'] 是可选参数,用于在使用正确权限设置实例角色的情况下访问其他账户中的 S3 存储桶。该脚本将自动使用在启动时分配给群集的 IAM 角色。
我们会将密钥的 RDD 拆分为多个分区,其中每个分区均包含小批量图像密钥。如果密钥无法划分为多个批处理大小的分区,我们将填充最后一个分区以重用其中一些初始密钥组。这是必需的,因为我们将绑定 (请参阅以下代码) 到固定批处理大小。
提取数据并将数据加载到 Spark 执行程序中
在 Apache Spark 中,您可以在 RDD 上执行两类操作。转换对一个 RDD 中的数据运行并创建新的 RDD,而操作计算 RDD 中的结果。
RDD 上的转换已延时评估。即,Spark 将不会执行转换直到它看到操作,相反,Spark 会通过创建有向无环图来跟踪不同的 RDD 之间的依赖项,这些依赖项会引导操作以形成执行计划。这有助于按需计算 RDD 并在 RDD 的分区丢失时执行恢复。
我们将使用 Spark 的 mapPartitions,该项提供分区记录的迭代器。转换方法对 RDD 的每个分区 (数据块) 单独运行。我们将使用来自 utils.py 的 download_objects 方法作为 RDD 分区上的转换,以将该分区的所有图像从 Amazon S3 下载到内存中。
我们将运行其他转换以使用 Python Pillow – Python Imaging Library 将内存中的每个图像转换为 numpy 数组对象。我们使用 Pillow 对内存中的图像 (采用 png 格式) 进行解码并将其转换为 numpy 对象。此操作在 mxinfer.py 的 read_images 和 load_images 中完成。
注意:在此应用程序中,您将看到我们正在 mapPartitions 函数内部而不是文件顶部导入模块 (numpy、mxnet、pillow 等)。这是因为,PySpark 将尝试序列化在模块级别导入的所有模块和任何相关库,而且常常无法挑选模块及模块的任何其他关联二进制文件。否则,Spark 将预计例程和库在节点上可用。我们将在使用 spark-submit 脚本提交应用程序时以代码文件形式发送例程。这些库已安装到所有节点上。还需要注意一点,如果您在函数中使用某个对象的成员,则 Spark 可终止对整个对象的序列化。
在执行程序上使用 MXNet 进行推理
如之前所述,对于此应用程序,我们将对每个节点运行一个执行程序,并对每个执行程序运行一个任务。
运行推理前,我们必须加载模型文件。 MXModel 类 (在 mxinfer.py 中) 从 MXNet Model Zoo 下载模型文件,然后创建 MXNet 模块,并在第一次使用时将其存储在 MXModel 类中。我们实施了单例模式,这样一来,我们无需在每次预测中都实例化和加载模型。
download_model_files 方法 (在 MXModel 单例类中) 将下载 ResNet-18 模型文件。该模型包含一个扩展名为 .json 的描述神经网络图的符号文件和一个扩展名为 .params 的包含模型参数的二进制文件。对于分类模型,将有一个包含类及其相应标签的 synsets.txt 文件。
下载模型文件后,我们将加载这些文件并在执行以下步骤的 init_module 例程中实例化 MXNet 模块对象:
- 加载符号文件并创建输入符号,将参数加载到 MXNet NDArray 并解析 arg_params 和 aux_params。
- 创建新的 MXNet 模块并分配符号。
- 将符号绑定到输入数据。
- 设置模型参数。
我们将在首次调用预测方法后立即下载并实例化 MXModel 对象。该预测转换方法还采用包含一批 (大小为 args['batch']) 彩色图像的四维数组 (RGB 的其他 3 个维度) 并调用 MXNet 模块转发方法以生成该批量图像的预测。
注意:我们出于上一个注释中讨论的原因在此方法内导入 mxnet 和 numpy 模块。
运行 Inference Spark 应用程序
首先克隆 deeplearning-emr GitHub 存储库,该库包含用于使用 MXNet 和 Spark 运行推理的代码。
我们将使用来自 utils.py 的 spark-submit 脚本运行 Spark 应用程序。
注意:将 <YOUR_S3_BUCKET> 替换为要在其中存储结果的 Amazon S3 存储桶。您应具有传递访问/私有密钥或具有实例 IAM 角色中的权限。
spark-submit 的参数包括:
- --py-files:需要发送至工作程序的代码文件的逗号分隔的列表 (不含空格)。
- --deploy-mode:群集或客户端。当您在群集模式下运行应用程序时,Spark 将选择其中一个工作程序来运行驱动程序和执行程序。当群集较大且 EMR 群集上的主节点忙于运行针对 Hadoop、Spark 等的 Web 服务器时,在群集模式下运行将非常有用;您还可以在客户端部署模式下运行应用程序。
- --master: yarn. EMR 将 YARN 配置为资源管理器。
- --conf spark.executor.memory 每个执行程序可使用的内存量。
- --conf spark.executorEnv.LD_LIBRARY_PATH 和 --driver-library-path: 将 设置为 LD_LIBRARY_PATH
- --num-executors:EMR 群集中核心和任务节点的总数。
- infer_main.py:启动 Spark 应用程序的主程序,该程序采用参数 S3 存储桶、S3 密钥前缀、批处理大小等。
- --batch:可在每个执行程序上一次性处理的图像的数量。此值受每个工作程序节点上可用的内存和 CPU 的约束。
收集预测
最后,我们将使用 Spark 收集操作来收集为每个分区生成的预测并将这些预测写入 Amazon S3。结果将写入到的 S3 位置 (args['output_s3_bucket'], args['output_s3_key']) 可作为参数传递至 infer_main.py。
监控 Spark 应用程序
您可在 Amazon EMR 控制台中查看 Spark 应用程序历史记录和 YARN 应用程序状态。在整个运行时期间近实时更新应用程序历史记录,并且历史记录可在应用程序完成后 (甚至在您终止群集后) 最多保留 7 天。它还在一个位置集中提供高级指标,如内存使用率、S3 读取数、HDFS 利用率等。这还将消除对 SSH 转发的需求,这与您使用 YARN UI 时不同。您可以查找这些功能并了解如何在 EMR 控制台上的 Spark 应用程序历史记录中使用它们。
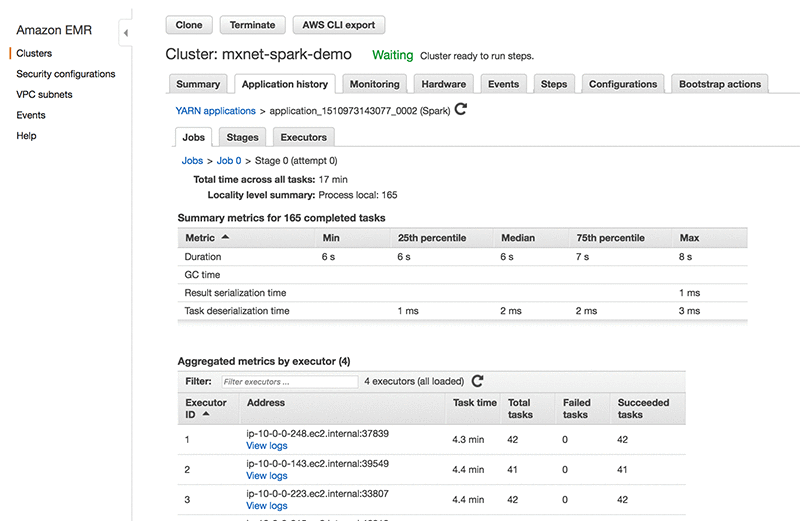
来自 EMR 控制台应用程序历史记录的以下屏幕截图显示了应用程序任务、执行时间等。
还可使用驱动程序主机端口 8088 上的 Yarn ResourceManager Web UI 监控在 Amazon EMR 上运行的 Spark 应用程序。下面列出了 Amazon EMR 群集上可用的各种 Web UI 及其访问方式:EMR 上的 YARN Web UI。
以下屏幕截图说明了 Web 监控工具。我们可以查看执行时间表、作业持续时间和任务成功和失败。

Amazon EMR 的另一项出色功能是与 Amazon CloudWatch 的集成,这将允许监控群集资源和应用程序。在以下屏幕截图中,我们可以看到跨群集节点的 CPU 利用率,该值保持在 25% 以下。

结论
简而言之,我们演示了如何设置一个包含 4 个节点的 Spark 群集,该群集使用 MXNet 跨 Amazon S3 上存储的 10000 个图像运行分布式推理,同时在 5 (4.4) 分钟内完成该处理。
了解更多
- Amazon Elastic MapReduce
- Apache Spark – 快速群集计算
- Apache MXNet – 灵活高效的深度学习。
- MXNet Symbol – 神经网络图和自动区分
- MXNet 模块 – 神经网络训练和推理
- MXNet – 使用预训练模型
- Spark 群集概述
- 提交 Spark 应用程序
未来改进
- 计算/IO 访问优化 – 在此应用程序中,我们观察到执行程序上的计算/IO 访问具有方波图样,其中 IO (无计算) 和计算 (无 IO) 是交替的。理想情况下,这可通过交错 IO 与计算来进行优化。但是,由于我们在每个节点上仅使用一个执行程序,因此,手动管理每个节点上的资源利用率也变得具有挑战性。
- 使用 GPU:另一个重大改进将是使用 GPU 来基于批量数据运行推理。
作者简介
 Naveen Swamy 是 Amazon AI 的一名软件开发人员,负责构建创新性的深度学习工具。他专注于使深度学习可供软件工程师使用以发挥其技能并将其应用于日常应用。在业余时间,他喜欢和家人呆在一起。
Naveen Swamy 是 Amazon AI 的一名软件开发人员,负责构建创新性的深度学习工具。他专注于使深度学习可供软件工程师使用以发挥其技能并将其应用于日常应用。在业余时间,他喜欢和家人呆在一起。