亚马逊AWS官方博客
Fannie Mae 如何利用 Amazon Redshift 数据共享构建数据网格架构以实现自助服务
Amazon Redshift 数据分享支持跨 Amazon Redshift 集群的即时、精细和快速数据访问,而无需复制或移动数据。数据共享提供了对数据的实时访问,因此当创建者更新数据时,用户始终可以看到所有使用者的最新且事务一致的数据视图。您可以跨区域与相同或不同 AWS 账户中的 Amazon Redshift 集群安全地共享实时数据。通过数据共享,可以在组织内部和组织之间以及外部各方之间实现安全且受管控的协作。
在这篇博文中,我们将看到 Fannie Mae 如何使用 Amazon Redshift 跨账户数据共享实施数据网格架构,以打破业务部门之间数据仓库中的孤岛。
关于 Fannie Mae
Fannie Mae于 1938 年由美国国会特许成立,致力于为全美数百万人提供公平且可持续的住房所有权,以及经济适用的优质租赁住房。Fannie Mae 支持 30 年期固定利率抵押贷款,并推动负责任的创新,使购房和租房更轻松、更公平、更方便。我们专注于提高运营敏捷性和效率,加快公司的数字化转型,以提供更多价值和更可靠的现代化平台,支持更广泛的住房融资体系。
背景
为了履行在美国各地促进公平且可持续地获得房屋所有权以及经济适用的优质租赁住房的使命,Fannie Mae 采用了基于云的现代化架构,该架构利用数据来推动切实可行的见解和业务决策。作为现代化战略的一部分,我们踏上了将传统本地工作负载迁移到 AWS Cloud 的旅程,包括 Amazon Redshift 和 Amazon S3 等托管服务。AWS Cloud 上的现代化数据平台充当分析、研究和数据科学的中央数据存储。此外,该平台还用于治理、监管和财务报告。
为了满足超过 4PB 的较大数据占用空间的容量、可扩展性和弹性需求,我们将数据存储和相关管理功能的所有权分散并委托给各自的业务部门。为了实现去中心化以及高效的数据访问和管理,我们采用了数据网格架构。
数据网格解决方案架构
为了实现跨账户和业务部门的数据无缝访问,我们研究了各种选项来构建可持续和可扩展的架构。数据网状结构使我们能够将各业务部门的数据保存在各自的账户中,但是仍能以安全的方式实现跨业务部门账户的无缝访问。 我们对 AWS 账户结构进行了重组,为每个业务部门设置了单独的账户,其中业务数据和相关应用程序并置在各自的 AWS 账户中。
通过这种去中心化模式,业务部门可以独立管理数据的水化、整理和安全责任。 但是,迫切需要跨业务部门实现对数据的无缝高效访问,并能够管理数据的使用。Amazon Redshift 跨账户数据共享满足了这一需求,使我们能够保持业务连续性。
为了促进数据网格上的自助式功能,我们构建了一个 Web 门户,允许发现数据并能够订阅 Amazon Redshift 数据仓库和 Amazon Simple Storage Service(Amazon S3)数据湖(智能湖仓)中的数据。一旦使用者在 Web 门户上发起请求,就会触发审批工作流并通知治理和业务数据所有者。成功完成请求工作流后,将触发自动化流程以向使用者授予访问权限,并向该使用者发送通知。随后,使用者可以访问所请求的数据集。使用 API 和 AWS 命令行界面(AWS CLI)命令自动执行访问权限的请求、审批和后续预置工作流,整个过程设计为在几分钟内完成。
借助这一使用 Amazon Redshift 跨账户数据共享的新架构,我们得以实施数据网格架构的以下关键原则并从中受益,这些原则非常适合我们的使用案例:
- 数据即产品方法
- 数据所有权的联合模式
- 使用者能够利用自助式数据访问进行订阅
- 联合数据治理,能够授予和撤销访问权限
以下架构图显示了我们在 Fannie Mae 实施的高级数据网格架构。从每个运营系统收集的数据存储在各个智能湖仓中,通过集中式控制面板账户中的数据网格目录来管理订阅。
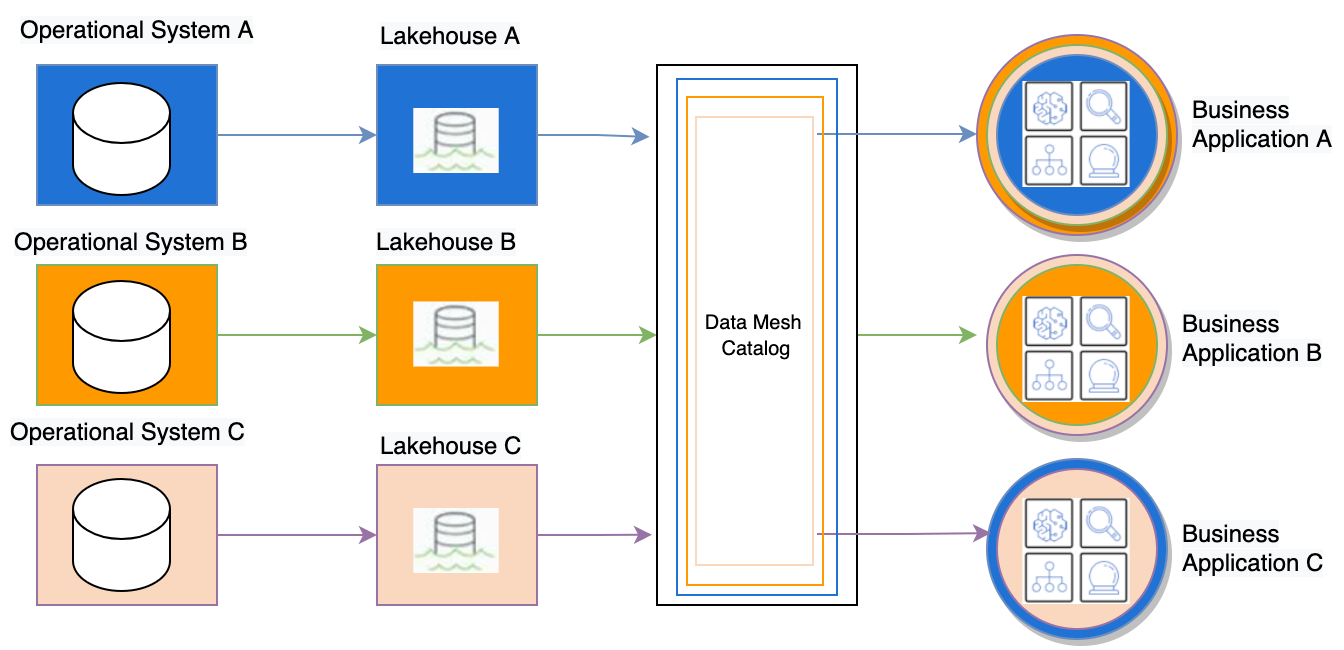
图 1.数据网格目录简要架构
数据网格的控制面板
通过重新设计的账户结构,数据分布在 S3 数据湖或 Amazon Redshift 集群中每个业务应用程序区域的不同账户中。我们设计了一个中心辐射型点对点数据分布方案,采用集中式语义搜索来增强数据相关性。我们使用集中式控制面板账户来存储数据网格的目录信息、合同详细信息、审批工作流策略和访问管理详细信息。借助策略驱动的访问范式,我们可以实现对数据的精细访问管理,通过优化的方法实现数据即服务的自动化。它有三个模块用于存储和管理目录、合同和访问管理。
数据目录
数据目录提供数据术语表和目录信息,有助于完全满足治理和安全标准。借助 AWS Glue 爬网程序,我们在集中式控制面板账户中为智能湖仓创建目录,然后以安全的方式自动执行共享流程。这使基于查询的框架能够精确定位数据的确切位置。数据目录收集有关数据集的运行时信息以编制索引,并提供运行时指标,用于分析数据集使用情况和访问模式。该目录还提供了一种机制,可在新数据集可用时通过自动化来更新目录。
合同注册表
合同注册表托管策略引擎,并使用 Amazon DynamoDB 存储注册表策略。其中详细介绍了数据物理映射的授权,以及访问管理流程的工作流。我们还用它来存储和维护现有数据合同的注册表,并启用审计功能以确定和监控访问模式。此外,合同注册表还用作状态管理功能的存储。
访问管理自动化
通过访问管理来控制和管理对数据集的访问。这通过 IAM 会话策略(使用角色驱动方法)提供了即时数据访问。该访问管理模块还托管数据的事件通知(如访问频率或读取次数),然后我们利用这些信息来管理数据访问生命周期。该模块在状态管理中起着至关重要的作用,并提供大量记录和监控数据状态的功能。
使用 Amazon Redshift 跨账户数据共享的数据网格流程
该流程从创建控制面板账户中所有可用数据集的目录开始。使用者可通过 Web 前端目录请求访问数据,审批流程通过中央控制面板账户触发。以下架构图简要展示了通过数据网格架构实施 Amazon Redshift 数据共享的情况。该流程的步骤如下所示:
- 所有数据产品、Amazon Redshift 表和 S3 存储桶都在一个集中的 AWS Glue Data Catalog 中注册。
- 数据科学家和 LOB 用户可以浏览 Data Catalog,以查找 Fannie Mae 所有智能湖仓中可用的数据产品。
- 通过注册使用者合同,业务应用程序可以使用其他智能湖仓中的数据。例如,LOB1-Lakehouse 可以注册合同,以利用来自 LOB3-Lakehouse 的数据。
- 合同由数据创建者审核和批准,随后通过 Amazon Simple Notification Service(Amazon SNS)触发技术事件。
- 订阅 AWS Lambda 函数会运行 AWS CLI 命令、ACL 和 IAM 策略,以设置 Amazon Redshift 数据共享并向使用者提供数据。
- 使用者可以使用自己的集群访问已订阅的 Amazon Redshift 集群数据。

图 2.使用 Amazon Redshift 数据共享的数据网格架构
这篇博文的目的不是为创建数据网格的各个方面提供详细步骤,而是简要概述所实施的架构,以及如何使用各种分析服务和第三方工具通过 Amazon Redshift 和 Amazon S3 创建可扩展的数据网格。如果您想尝试创建此架构,可以使用这些步骤,并使用您为前端用户界面选择的工具来自动执行该过程,让用户能够订阅数据集。
此处介绍的步骤是实际实施的简化版本,因此并非涉及所有工具和账户。为了设置这种缩减的数据网格架构,我们使用一个控制面板账户和两个使用者账户来演示如何使用跨账户数据共享。为此,您应符合以下先决条件:
- 三个 AWS 账户,一个是创建者账户 <ProducerAWSAccount1>,两个是使用者账户:<ConsumerAWSAccount1> 和 <ConsumerAWSAccount2>
- 预置 Amazon Redshift 以及创建 IAM 角色和策略的 AWS 权限
- 所需的 Amazon Redshift 集群:一个用于创建者 AWS 账户中的创建者,
ConsumerCluster1中的集群,以及ConsumerCluster2中的集群(可选) - 创建者账户中有两个用户,使用者账户 1 中有两个用户:
- ProducerClusterAdmin – 对创建者集群具有管理员访问权限的 Amazon Redshift 用户
- ProducerCloudAdmin – 有权在创建者账户中运行
authorize-data-share和deauthorize-data-shareAWS CLI 命令的 IAM 用户或角色 - Consumer1ClusterAdmin – 对使用者集群具有管理员访问权限的 Amazon Redshift 用户
- Consumer1CloudAdmin – 有权在使用者账户中运行
associate-data-share-consumer和disassociate-data-share-consumerAWS CLI 命令的 IAM 用户或角色
实施解决方案
在 Amazon Redshift 控制台上,登录到创建者集群,并使用查询编辑器运行以下语句:
要在 AWS 账户之间共享数据,您可以使用以下 GRANT USAGE 命令。通常由经理或审批者来授权数据共享。在本例中,我们将展示如何使用 AWS CLI 命令 authorize-data-share 自动执行此过程。
为了让使用者访问来自创建者的共享数据,使用者账户的管理员需要将数据共享与一个或多个集群相关联。可通过使用 Amazon Redshift 控制台或 AWS CLI 命令来完成这项操作。我们提供以下 AWS CLI 命令,因为这是您从中央控制面板账户自动执行该过程的方法:
要启用对 AWS Glue 和 Amazon S3 的 Amazon Redshift Spectrum 跨账户存取并了解所需的 IAM 角色,请参阅如何创建对 AWS Glue 和 Amazon S3 的 Amazon Redshift Spectrum 跨账户存取。
结论
Amazon Redshift 数据共享提供了一个简单、无缝且安全的平台,用于在面向域的分布式数据网格架构中共享数据。Fannie Mae 在数据湖和数据网格平台上部署了 Amazon Redshift 数据共享功能,该平台目前托管着超过 4 PB 的业务数据。该功能已与其即时(JIT)数据预置框架无缝集成,支持角色驱动的一键式数据访问。此外,Amazon Redshift 数据共享与 Fannie Mae 的集中式策略驱动型数据治理框架相结合,极大地简化了对数据湖生态系统中数据的访问,同时完全符合极其严格的数据治理政策和标准。这表明 Amazon Redshift 用户可以将数据共享创建为产品,以便跨多个数据域进行分发。
总而言之,Fannie Mae 成功地将数据共享功能整合到其数据生态系统中,从而提高了数据普及化效率,并在各业务部门引入了更快速、近乎实时的数据访问方式。我们鼓励您探索 Amazon Redshift 的数据共享功能,以构建自己的数据网格架构并改善企业用户对数据的访问。
关于作者
 Kiran Ramineni 是 Fannie Mae 副总裁,负责单户家庭、云、数据、机器学习/人工智能和基础设施架构,向首席技术官和首席架构师汇报工作。Kiran 和团队领导的云端可扩展企业数据网格(数据湖)支持即时(JIT),也支持零信任(因为它适用于公民数据科学家和公民数据工程师)。过去,Kiran 曾构建/领导过几个可扩展的互联网始终在线平台。
Kiran Ramineni 是 Fannie Mae 副总裁,负责单户家庭、云、数据、机器学习/人工智能和基础设施架构,向首席技术官和首席架构师汇报工作。Kiran 和团队领导的云端可扩展企业数据网格(数据湖)支持即时(JIT),也支持零信任(因为它适用于公民数据科学家和公民数据工程师)。过去,Kiran 曾构建/领导过几个可扩展的互联网始终在线平台。
 Basava Hubli 是企业架构部门的总监兼首席数据/机器学习架构师。他负责监督 Fannie Mae 企业数据、分析和数据科学平台的战略和架构。他的工作重点是架构监督和创新技术能力交付,以解决企业的关键业务需求。他领导着一支充满激情和积极进取的架构师团队,该团队正推动云端数据、分析和机器学习平台的现代化和采用。在他的带领下,企业架构部门成功部署了多个可扩展的创新平台和功能,其中包括一个托管 PB 级业务数据的完全受管的数据网格,以及一个基于零信任的角色驱动型数据访问管理框架,该框架可满足组织的数据普及化需求。
Basava Hubli 是企业架构部门的总监兼首席数据/机器学习架构师。他负责监督 Fannie Mae 企业数据、分析和数据科学平台的战略和架构。他的工作重点是架构监督和创新技术能力交付,以解决企业的关键业务需求。他领导着一支充满激情和积极进取的架构师团队,该团队正推动云端数据、分析和机器学习平台的现代化和采用。在他的带领下,企业架构部门成功部署了多个可扩展的创新平台和功能,其中包括一个托管 PB 级业务数据的完全受管的数据网格,以及一个基于零信任的角色驱动型数据访问管理框架,该框架可满足组织的数据普及化需求。
 Rajesh Francis 是 AWS 的高级分析客户体验专家。他专门研究 Amazon Redshift,致力于帮助推动 AWS 数据仓库和分析的市场与技术战略。Rajesh 与大型战略客户密切合作,帮助他们采用我们的新服务和功能,建立长期合作伙伴关系,并将客户需求反馈给我们的产品开发团队,为产品开发指明方向。
Rajesh Francis 是 AWS 的高级分析客户体验专家。他专门研究 Amazon Redshift,致力于帮助推动 AWS 数据仓库和分析的市场与技术战略。Rajesh 与大型战略客户密切合作,帮助他们采用我们的新服务和功能,建立长期合作伙伴关系,并将客户需求反馈给我们的产品开发团队,为产品开发指明方向。
 Kiran Sharma 是 AWS Professional Services 的一名高级数据架构师。Kiran 帮助客户在 AWS 上构建、实施和优化 PB 级大数据解决方案。
Kiran Sharma 是 AWS Professional Services 的一名高级数据架构师。Kiran 帮助客户在 AWS 上构建、实施和优化 PB 级大数据解决方案。