亚马逊AWS官方博客
零代码实现基于机器学习的游戏运营优化
背景
对于在线游戏来说,优化广告投放策略、预测玩家流失是提升游戏经济效益的良好方式。然而,虽然很多游戏公司手中掌握着大量用户数据,使用传统非机器学习的方式很难从这些海量数据中获得见解,从而优化游戏的运营。
亚马逊云科技于2019年12月推出了Amazon SageMaker Autopilot。这是一个实现【自动机器学习】的服务,使您不需要拥有机器学习相关的知识,甚至不需要写代码,就可以快速训练/部署机器学习模型,解决分类、回归预测的问题。
借助Amazon SageMaker Autopilot,您只需要准备好您的数据,就可以轻松实现优化广告投放策略、预测玩家流失等优化运营的需求。
将运营问题转换为机器学习问题
在我们开始进行机器学习相关的工作之前,我们首先要明白如何将我们遇到的运营业务问题转换为适合被机器学习解决的问题。

比如,假设您希望优化您的广告投放策略/买量策略,您可以通过对比不同渠道所引入的新玩家的付费倾向来实现。如果渠道A带来的新玩家付费倾向远大于渠道B带来的新玩家付费倾向,您就可以向渠道A投入更多资金从而获得更高的经济收益。您也可以在对玩家进行分类之后,针对不同类型的玩家实施不同的广告投放策略。您甚至可以使用类似的方式,识别买量中的机器人玩家,避免买量欺诈行为。
至此,我们就把问题从【买量策略优化】转换为了【玩家付费预测】。这是一个典型的二分类问题,我们希望根据玩家首日的游玩数据,预测玩家在一个月内的付费情况,从而提前得知我们在某个渠道的广告投放质量。
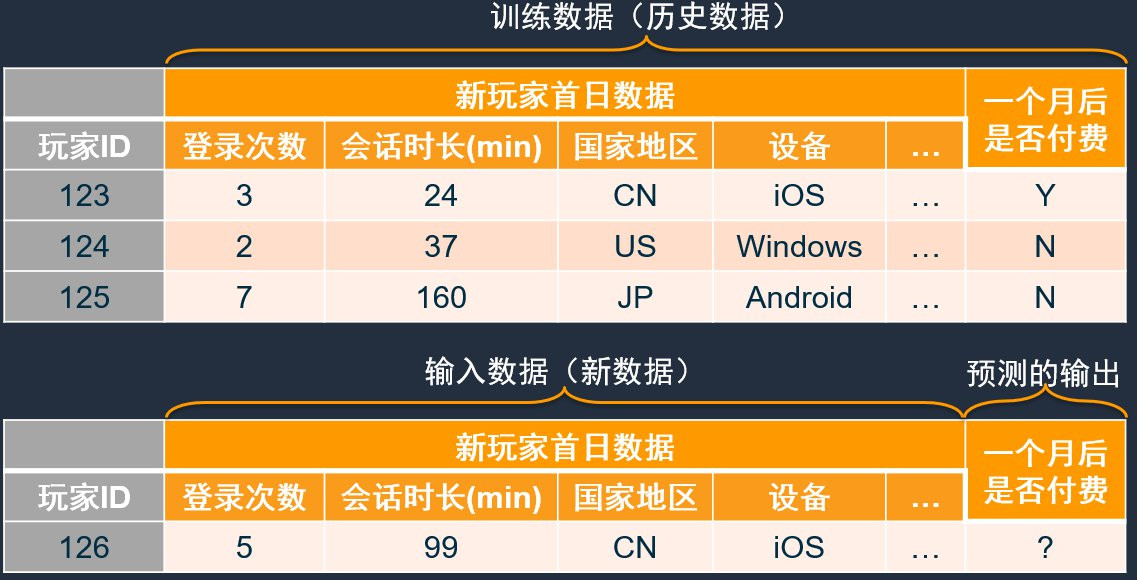
如何准备数据
在明确了我们的任务目标之后,我们需要准备机器学习所需要的训练数据。游戏行业有很多可以量化的数据,如下表格是常见的,被用来训练模型的数据。其中数值类型的数据,可以额外把最大值、最小值、平均值、和积差商、变化率作为训练数据。您也可以根据您的实际业务场景来收集并整理您的特色数据。

Amazon SageMaker Autopilot使用CSV作为输入数据的格式,您需要将您的数据整理为CSV文件才可以被Amazon SageMaker Autopilot使用。
Demo: 零代码实现付费玩家预测
游戏介绍
假设我们研发了一款移动端休闲游戏。玩家开始游戏后,屏幕上会在随机位置出现西瓜,玩家点击西瓜即可消除西瓜并获得分数。如果西瓜一段时间内没有被点击则会自动消失,并减少玩家生命值。玩家生命值归零时游戏结束。玩家可以通过充值的方式获得额外的生命值。
我们目前拥有如下数据
- 玩家注册数据
- 玩家ID
- 出生日期
- 注册时间
- 国家和地区
- 用户名
- 玩家会话数据
- 玩家ID
- 会话ID
- 会话开始时间戳
- 会话结束时间戳
- 设备型号
- 玩家点击数据
- 玩家ID
- 点击时间戳
- 是否命中西瓜
- 玩家充值数据
- 玩家ID
- 时间戳
- 充值金额
示例数据
经过整理之后,我们得到了一个CSV文件作为训练数据,包含如下字段:
- birthday: 玩家出生日期的时间戳
- region: 玩家的国家或地区
- sessionDuration: 玩家首日会话的累计时长
- clickCount: 玩家首日点击次数
- hitCount: 玩家首日击中西瓜的次数
- isPayer: 玩家首月是否存在付费记录
以下是部分训练数据。

我们需要把训练数据上传到S3桶中,以便Amazon SageMaker Autopilot可以访问到它。
使用Amazon SageMaker Autopilot训练与部署模型
打开亚马逊云科技的web控制台,导航到SageMaker服务控制台,使用默认配置创建SageMaker Studio。

创建完毕后,点击【Open Studio】以打开SageMaker Studio

点击左侧【SageMaker Components and Registries】,然后点击【Create Experiment】
 为您的任务起一个名字,比如【gaming-payer-prediction】
为您的任务起一个名字,比如【gaming-payer-prediction】
 指定您的输入数据所在的位置,以及目标列【isPayer】。
指定您的输入数据所在的位置,以及目标列【isPayer】。
 选择AI模型等文件输出的位置。
选择AI模型等文件输出的位置。

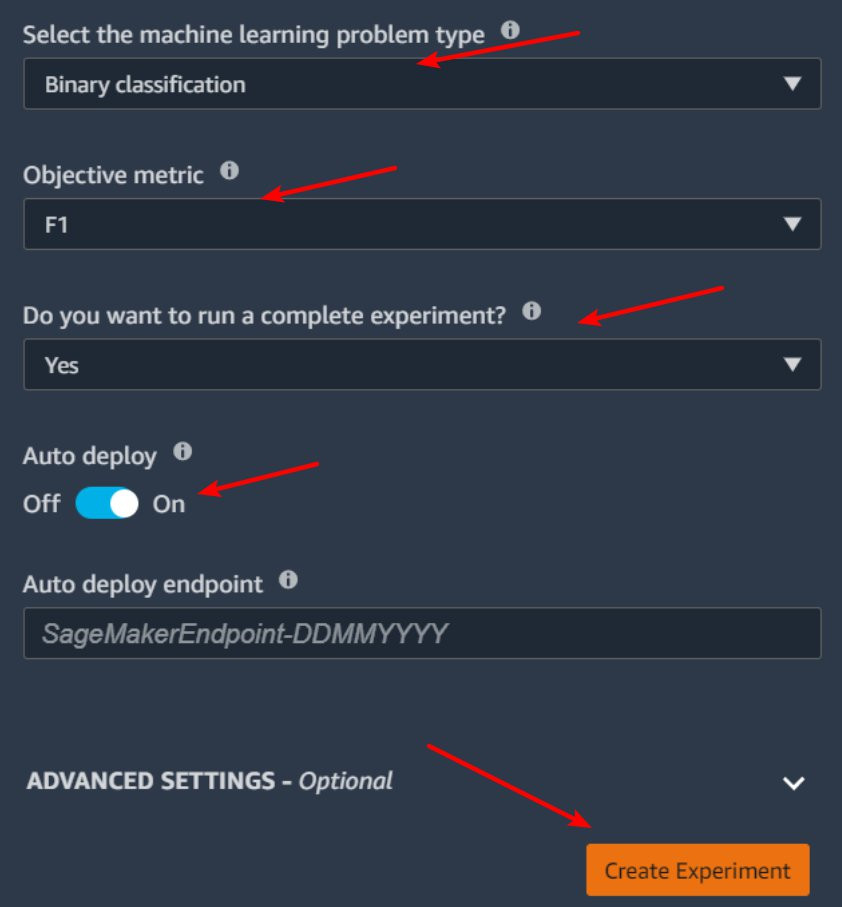
选择任务类型为【二分类/Binary classification】,目标指标为【F1】,启用自动部署,然后点击【Create Experiment】。
等待任务完成即可。SageMaker Autopilot会自动选择合适的算法来训练模型,并自动优化训练任务的超参数来提升性能。您可以点击右上角的【Open candidate generation notebook】和【Open data exploration notebook】来查看SageMaker Autopilot如何选择算法、如何进行数据探索。页面下方的表格会显示目前已经完成训练的任务,并按照结果的性能进行排序,即按照F1从大到小排序。

部署完毕后会生成一个endpoint。点击页面中的endpoint可以查看详情。

在endpoint详情页面,点击【AWS settings】,可以看到endpoint的URL。我们可以直接向此URL发送请求,以获得预测结果。

检测模型效果
使用Postman向endpoint发起请求。
配置Postman,把请求方法设置为【Post】,请求URL为endpoint的URL。配置Authorization,类型选择AWS Signature,填入您的IAM用户对应的AccessKey和SecretKey,选择您的endpoint所在的区域代码(如us-east-1),并把Service Name填写为sagemaker

设置其他Headers

最后在【Body】内填写测试数据,点击【Send】,即可获得预测结果。
 测试数据为
测试数据为
1426756582,A,1690,336,280
1290241758,F,5348,801,485
1151548404,E,2894,672,429
1362933492,E,6395,1908,1785
1039090651,A,749,144,66
841949324,D,8913,888,497
753535582,A,3195,583,101
1047787317,C,8717,3190,1786
1459465132,D,8907,4440,4033
891116384,E,6096,1212,1188
这些数据对应的真实标签为:0,0,0,0,0,1,0,1,0,0。可以看到模型对于所有的输入都得到了正确的输出。
集成到您的环境
Amazon SageMaker Autopilot已经自动将您的模型部署为endpoint以便通过HTTP/S的方式进行调用,默认使用AWS IAM的方式进行鉴权。您也可以集成Amazon API Gateway来实现自定义鉴权方式。
除了部署为endpoint,您也可以使用Amazon SageMaker Batch Transform对数据进行批量转换。
您可以联系与您对接的亚马逊云科技解决方案架构师,一同商讨模型的最佳部署、使用方案。
结束语
本文仅关注核心的自动机器学习操作流程。对于面向生产的预测类应用,您仍需考虑使用数据探索、特征优化、标签平衡等多种方式对数据进行预处理,从而优化自动机器学习的效果,具体实现方案欢迎咨询。