使用 Amazon SageMaker
构建类似图像的智能索引
在本教程中,您将学习如何使用 Amazon SageMaker 训练模型,该模型的用途是为视觉上彼此相似的图像提供索引。您将使用示例图像测试模型,查看模型如何能够识别看起来与之相似的其他图像。在石油和天然气领域,这种模型可以帮助您在没有人工干预的情况下,通过即时比较类似项目来寻找类似的储层。例如,如果在地震勘探中发现了指示潜在油气田的新特征或图案,Sagemaker 可以使您根据相似的图案,从 TB 字节的存档地震资料中找出相关图像。智能搜索在整个行业中的应用是无穷无尽的。
大多数开发人员通常觉得机器学习要比它本身难得多,因为构建和训练模型,然后将其部署到生产中的流程通常很复杂,并且速度慢。Amazon SageMaker 是一个完全托管的平台,可以帮助开发人员和数据科学家快速而轻松地构建、训练和部署任何规模的机器学习模型。Amazon SageMaker 消除了通常会阻碍开发人员使用机器学习的障碍。
在接下来的几分钟内,您将启动一个 Amazon SageMaker 笔记本实例并加载一个示例笔记本,其中含有下载一些示例图像数据、准备测试和评估数据集,使用预训练模型创建测试图像向量,然后训练可识别相似图像向量的新模型的代码。然后,示例代码会将新模型部署到 Amazon SageMaker 进行托管,您将在那里生成推理请求并测算模型的准确性
AWS Free Tier 提供免费的 Amazon SageMaker 套餐,让您可以轻松开始使用 Amazon SageMaker。在注册后的前两个月,您可以享受免费月度套餐,其中包括在笔记本上免费使用 250 小时的 t2.medium 来构建模型,再加上免费使用 50 小时的 m4.xlarge 进行训练,以及免费使用 125 小时的 m4.xlarge 以通过 Amazon SageMaker 托管机器学习模型。
第 1 步:进入 Amazon Sagemaker 控制台
a. 打开 AWS 管理控制台,您就可以让本分步指南处于打开状态。此屏幕加载后,请输入用户名和密码以便开始操作。然后在搜索栏中键入 Sagemaker 并选择 Sagemaker 以打开 Sagemaker 控制台。

(单击可放大)
第 2 步:设置 Amazon SageMaker 笔记本实例
在此步骤中,您将设置并配置一个 Amazon SageMaker 笔记本实例。
a. 通过在屏幕右侧的“开始使用”部分中选择“创建笔记本实例”,启动 Amazon SageMaker 笔记本。

(单击可放大)
b. 在“笔记本实例设置”部分中,完成以下步骤:1) 为您的笔记本指定一个名称(例如 “ImageIndexing”),2) 选择笔记本实例类型(例如,最小且成本较低的 ml.t2.medium)及 3) 选择“创建新角色”。

(单击可放大)
c.在“创建 IAM 角色”屏幕上的“您指定的 S3 存储桶 - 可选”下,选择“无”。保持所有其他默认值不变,以允许与 SageMaker 相关的存储桶和对象被访问。选择“创建角色”。
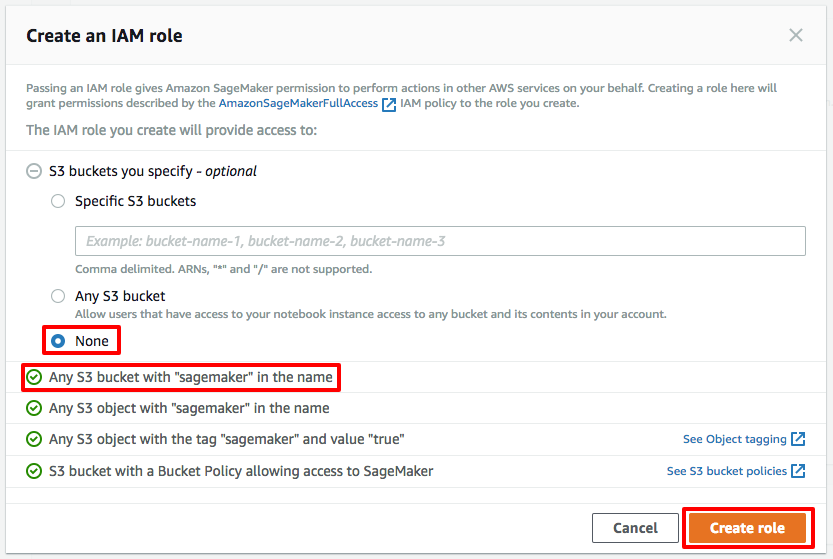
(单击可放大)
d.返回“创建笔记本实例”屏幕,选择您刚在步骤 2.c. 中创建的 IAM 角色,然后选择“创建笔记本实例”。在这个简单的教程中,不需要 VPC 和 KMS 的其他值,但在使用真实的私有数据时,应使用这些值。
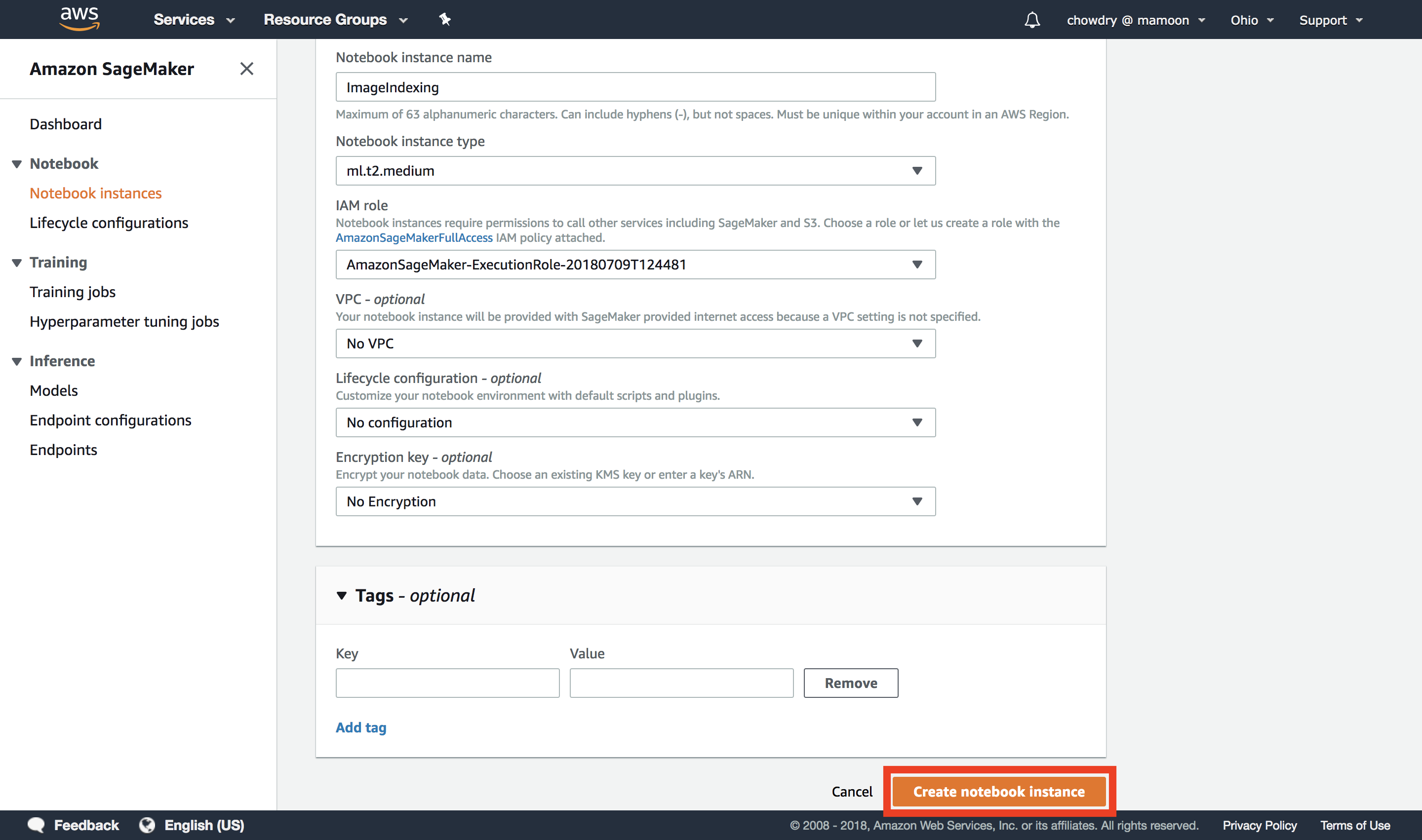
(单击可放大)
e.当实例准备就绪时,笔记本的状态将从“待处理”变为“服务中”。在实例启动期间,我们需要添加额外的权限,以确保它可以访问 Amazon EC2 Container Registry。为此,请导航到 IAM 控制台并选择“角色”。
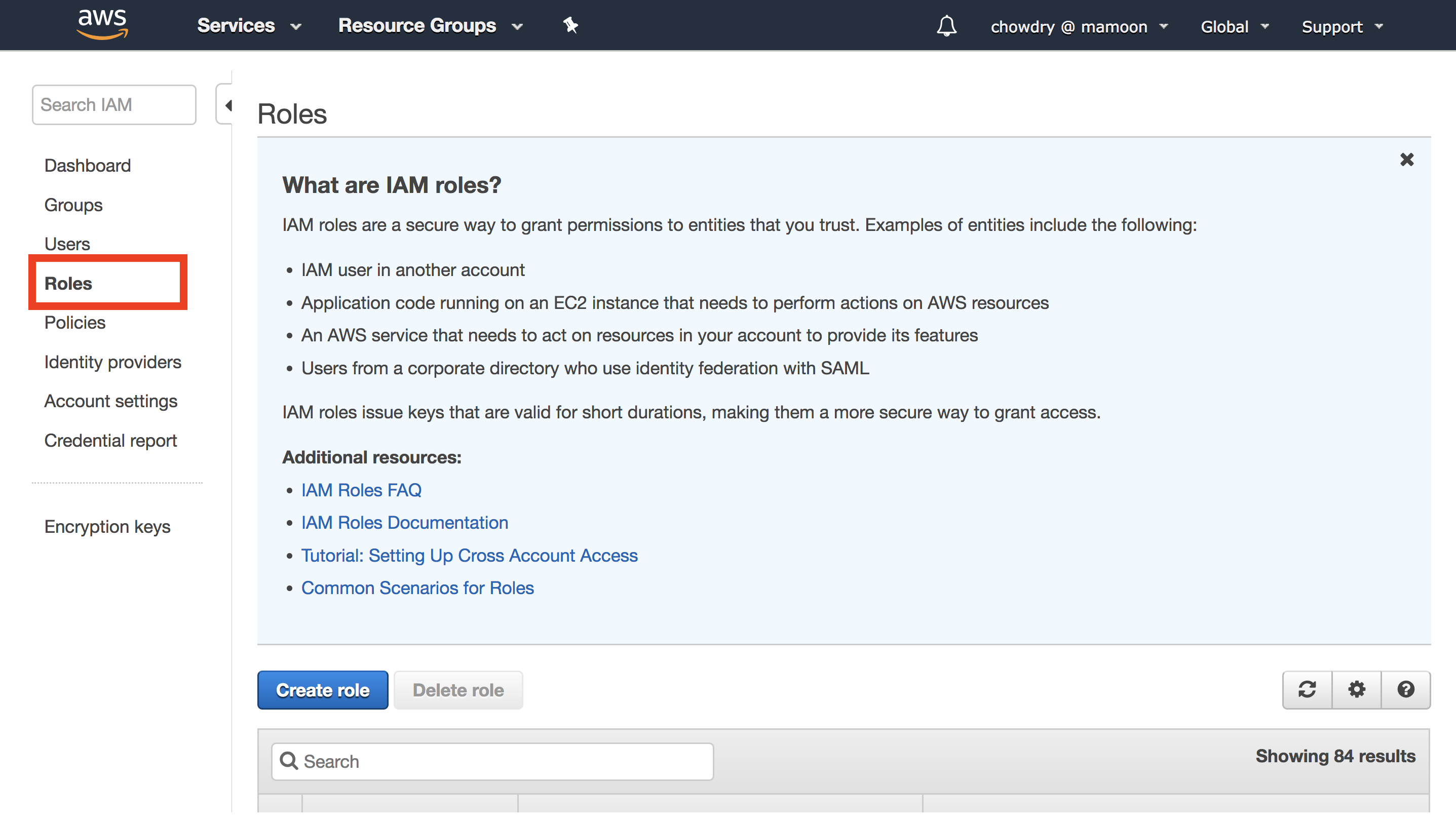
(单击可放大)
f.向下滚动角色列表,然后选择您刚刚创建的 SageMaker 角色。选择“附加策略”。
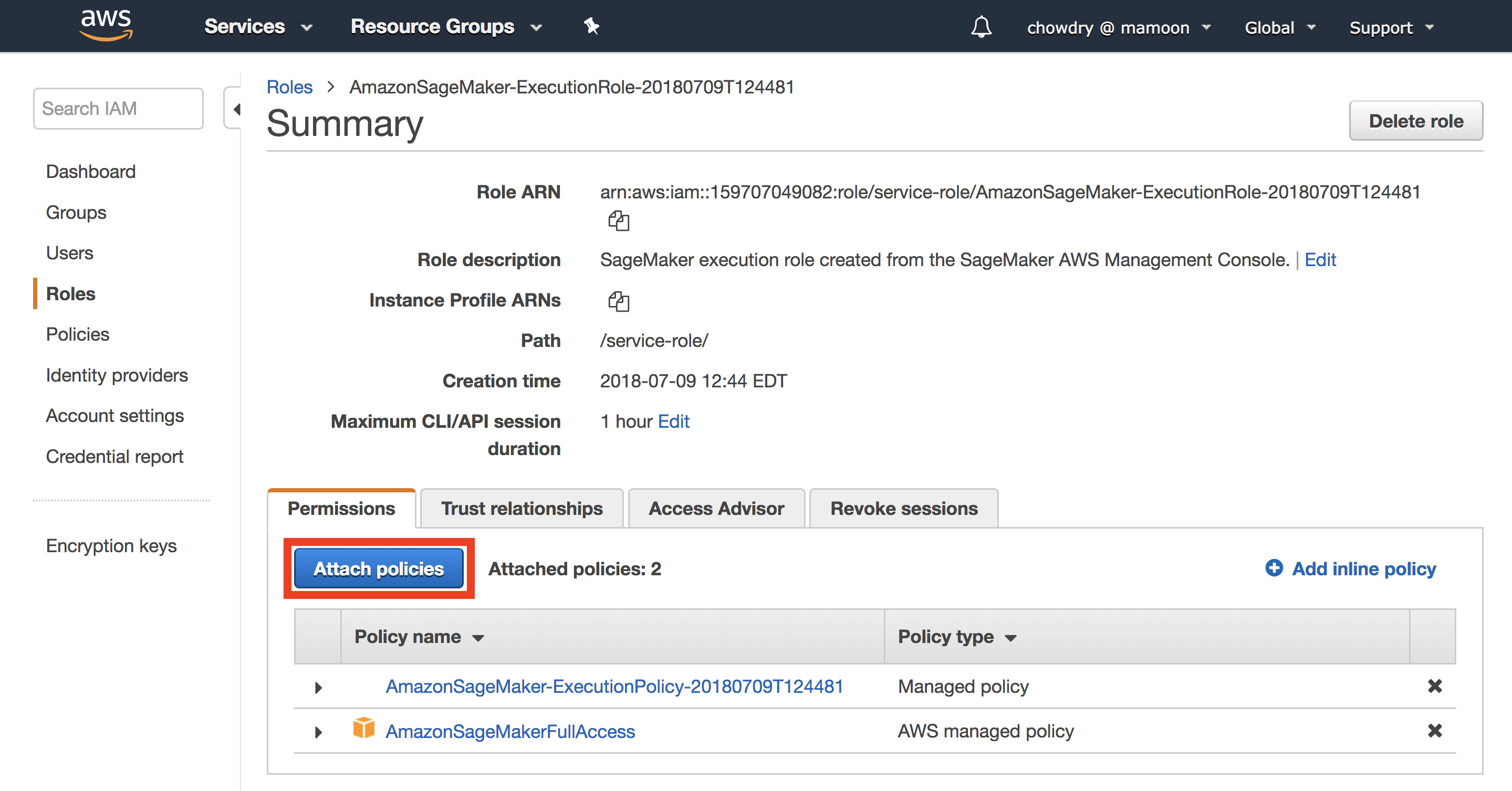
(单击可放大)
g.向下滚动角色列表,然后选择您刚刚创建的 SageMaker 角色。选择“附加策略”。

(单击可放大)
h.在以下摘要页面中,确保新策略已添加到规则中。添加策略后,您的笔记本实例将有权访问 Amazon EC2 Container 服务。

(单击可放大)
i.返回 Amazon SageMaker 控制台,检查笔记本的状态是否列为“服务中”。笔记本准备就绪后,选择“打开”。这将在您的实例中打开 Jupyter Web 应用程序。

(单击可放大)
第 3 步:导入和配置示例图像索引笔记本
在此步骤中,您将在示例 Jupyter Notebook 中准备一些数据、训练模型并启动索引服务。
a.当 Jupyter Notebook 打开后,依次选择“新建”、“终端”,以打开新的终端来检索教程笔记本。您将把教程笔记本用于自定义模型。

(单击可放大)
b.现在,您将从 git 存储库中检索笔记本。在此终端中,通过输入 cd SageMaker 更改为 SageMaker 目录。接下来,通过输入 git clone https://gitlab.com/smartpartrol/seismic-vision-search 从 GitHub 中克隆存储库
c.返回“Jupyter 主页”屏幕,并通过选择 seismic-vision-search 文件夹导航至笔记本。

(单击可放大)
d.打开名为 Seismic-Vision-search.ipynb 的笔记本。滚动浏览笔记本以阅读注释和代码,其中解释了制作图像索引服务所需的所有步骤。
(单击可放大)
e.要写入其输出,模型需要 S3 存储桶。因此,现在打开“S3 控制台”并选择“创建存储桶”。

(单击可放大)
f.以 sagemaker- 为前缀命名存储桶,从而允许 Amazon SageMaker 访问它,并为其附加上您的姓名以表示唯一性。在“区域”下,选择您要在其中创建此存储桶的区域。请注意,存储桶应与笔记本实例位于同一区域。选择左下角的“创建”。
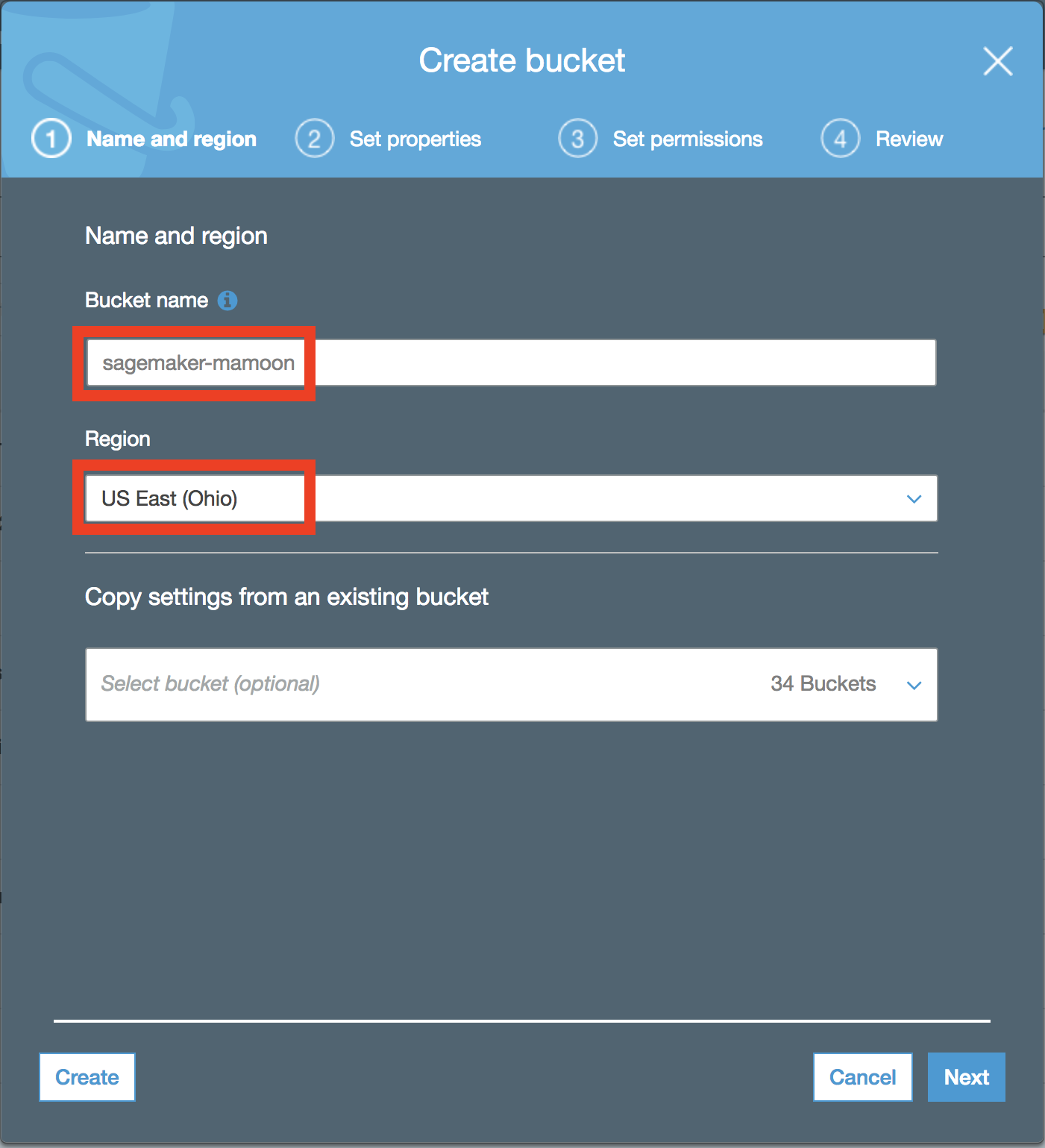
(单击可放大)
第 4 步:更新然后执行您的笔记本
a.接下来,将笔记本单元格向下滚动到第一个带有 S3 存储桶名称的代码单元格,并赋予您创建的 S3 存储桶的名称(例如,sagemaker-mamoon)。

(单击可放大)
b.从 Jupyter 页面顶部的“单元格”菜单中选择“全部运行”选项。
第 5 步:清理
a.SageMaker 模型托管按小时计费,如果继续使用,费用可能会超出您的免费套餐。为确保不使用任何不必要的计费时间,您可以运行最后一个单元格来关闭托管实例,并移除 SageMaker 端点。

(单击可放大)
恭喜!
您已经使用 Amazon SageMaker 为基于内容的图像索引和检索创建了自定义的模型!
现在,您可以针对自己的图像自定义此模型,以尝试推断任何输入图像的相似性。