Erste Schritte / Praktische Übungen / ...
Prepare Training Data for Machine Learning with Minimal Code
TUTORIAL
Übersicht
Was Sie erreichen werden
In diesem Leitfaden werden Sie:
- Daten visualisieren und analysieren, um wichtige Zusammenhänge zu verstehen;
- Transformationen anwenden, um die Daten zu bereinigen und neue Merkmale zu generieren;
- Notebooks für wiederholbare Workflows zur Datenaufbereitung automatisch generieren.
Voraussetzungen
Bevor Sie mit diesem Tutorial beginnen, benötigen Sie:
- Ein AWS-Konto: Wenn Sie noch kein Konto haben, folgen Sie dem Leitfaden für die ersten Schritte zum Einrichten Ihrer AWS-Umgebung, um einen schnellen Überblick zu erhalten.
Erfahrung mit AWS
Einsteiger
Benötigte Zeit
30 Minuten
Veranschlagte Kosten
Siehe Amazon-SageMaker-Preise, um die Kosten für dieses Tutorial abzuschätzen.
Erfordert
Sie müssen bei einem AWS-Konto angemeldet sein.
Verwendete Services
Amazon SageMaker Data Wrangler
Letzte Aktualisierung
01. Juli 2022
Implementierung
Schritt 1: Einrichtung Ihrer Amazon SageMaker Studio-Domäne
Mit Amazon SageMaker können Sie ein Modell visuell über die Konsole oder programmgesteuert mit SageMaker Studio oder SageMaker-Notebooks bereitstellen. In diesem Tutorial stellen Sie das Modell programmgesteuert mithilfe eines SageMaker-Studio-Notebooks bereit, wofür eine SageMaker-Studio-Domäne erforderlich ist.
Ein AWS-Konto kann nur eine SageMaker-Studio-Domäne pro Region haben. Wenn Sie bereits über eine SageMaker-Studio-Domäne in der Region USA Ost (Nord-Virginia) verfügen, befolgen Sie die Anleitung zur Einrichtung von SageMaker Studio, um die erforderlichen AWS-IAM-Richtlinien mit Ihrem Konto von SageMaker Studio zu verknüpfen, überspringen Sie dann Schritt 1 und fahren Sie direkt mit Schritt 2 fort.
Wenn Sie keine bestehende SageMaker-Studio-Domäne haben, fahren Sie mit Schritt 1 fort, um eine AWS-CloudFormation-Vorlage auszuführen, die eine SageMaker-Studio-Domäne erstellt und die für den Rest dieses Tutorials erforderlichen Berechtigungen hinzufügt.
Wählen Sie den Link für AWS-CloudFormation-Stack. Dieser Link öffnet die AWS-CloudFormation-Konsole und erstellt Ihre SageMaker-Studio-Domäne und einen Benutzer mit dem Namen studio-user. Er fügt auch die erforderlichen Berechtigungen zu Ihrem SageMaker-Studio-Konto hinzu. Bestätigen Sie in der CloudFormation-Konsole, dass USA Ost (Nord-Virginia) die Region ist, die in der oberen rechten Ecke angezeigt wird. Der Stack-Name sollte CFN-SM-IM-Lambda-catalog lauten und sollte nicht geändert werden. Dieser Stack benötigt etwa 10 Minuten, um alle Ressourcen zu erstellen.
Dieser Stack geht davon aus, dass Sie bereits eine öffentliche VPC in Ihrem Konto eingerichtet haben. Wenn Sie keine öffentliche VPC haben, lesen Sie VPC mit einem einzigen öffentlichen Subnetz, um zu erfahren, wie Sie eine öffentliche VPC erstellen können.

Wählen Sie Ich bestätige, dass AWS CloudFormation möglicherweise IAM-Ressourcen erstellt und wählen Sie dann Stack erstellen aus.

Wählen Sie im Bereich CloudFormation die Option Stacks. Es dauert etwa 10 Minuten, bis der Stack erstellt ist. Wenn der Stack erstellt wird, ändert sich der Status des Stacks von CREATE_IN_PROGRESS zu CREATE_COMPLETE.

Schritt 2: Erstellen eines neuen SageMaker-Data-Wrangler-Ablaufs
SageMaker Data Wrangler akzeptiert Daten aus einer Vielzahl von Quellen, darunter Amazon S3, Amazon Athena, Amazon Redshift, Snowflake und Databricks. In diesem Schritt erstellen Sie einen neuen SageMaker-Data-Wrangler-Ablauf unter Verwendung des in Amazon S3 gespeicherten deutschen UCI-Kreditrisikodatensatzes. Dieser Datensatz enthält demografische und finanzielle Informationen über Einzelpersonen zusammen mit einer Kennzeichnung, die das Kreditrisiko der Person angibt.
Geben Sie SageMaker Studio in die Suchleiste der Konsole ein und wählen Sie dann SageMaker Studio.

Wählen Sie USA Ost (Nord-Virginia) aus der Dropdown-Liste Region in der oberen rechten Ecke der SageMaker-Konsole. Wählen Sie für App starten die Option Studio, um SageMaker Studio mit dem studio-user-Profil zu öffnen.

Öffnen Sie die Oberfläche von SageMaker Studio. Wählen Sie in der Navigationsleiste Datei, Neu, Data Wrangler Flow.

Wählen Sie auf der Registerkarte Importieren unter Daten importieren die Option Amazon S3 aus.
Geben Sie in das Feld S3-URI-Pfad s3://sagemaker-sample-files/datasets/tabular/uci_statlog_german_credit_data/german_credit_data.csv ein, und wählen Sie dann Go. Klicken Sie unter Objektname auf german_credit_data.csv und wählen Sie dann Importieren aus.

Schritt 3: Profilieren der Daten
In diesem Schritt verwenden Sie SageMaker Data Wrangler, um die Qualität des Trainingsdatensatzes zu bewerten. Sie können die Funktion Quick Model verwenden, um die erwartete Vorhersagequalität und die Vorhersagekraft der Merkmale in Ihrem Datensatz grob abzuschätzen.
Wählen Sie auf der Registerkarte Datenablauf im Datenflussdiagramm das Symbol +, Analyse hinzufügen aus.
Wählen Sie im Bereich Analyse erstellen für Analysetyp, die Option Histogramm aus.
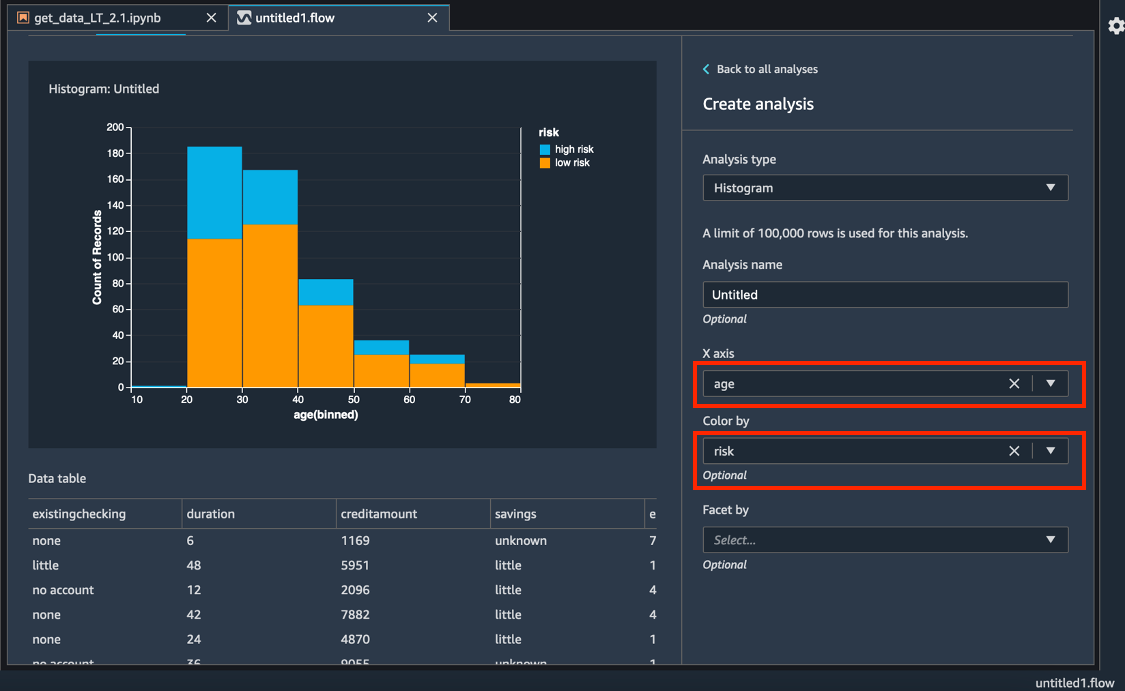
Wählen Sie für die X-Achse das Alter aus.
Wählen Sie für Färben nach die Option Risiko.
Wählen Sie Vorschau, um ein Histogramm des Feldes Kreditrisiko zu erstellen, das nach Alters-gruppe farbcodiert ist.
Wählen Sie Speichern, um diese Analyse im Ablauf zu speichern.
Um zu verstehen, wie gut der Datensatz zum Trainieren eines Modells geeignet ist, das die Risiko-Zielvariable vorhersagt, führen Sie die Quick Model-Analyse aus. Wählen Sie auf der Registerkarte Analyse die Option Neue Analyse erstellen aus.
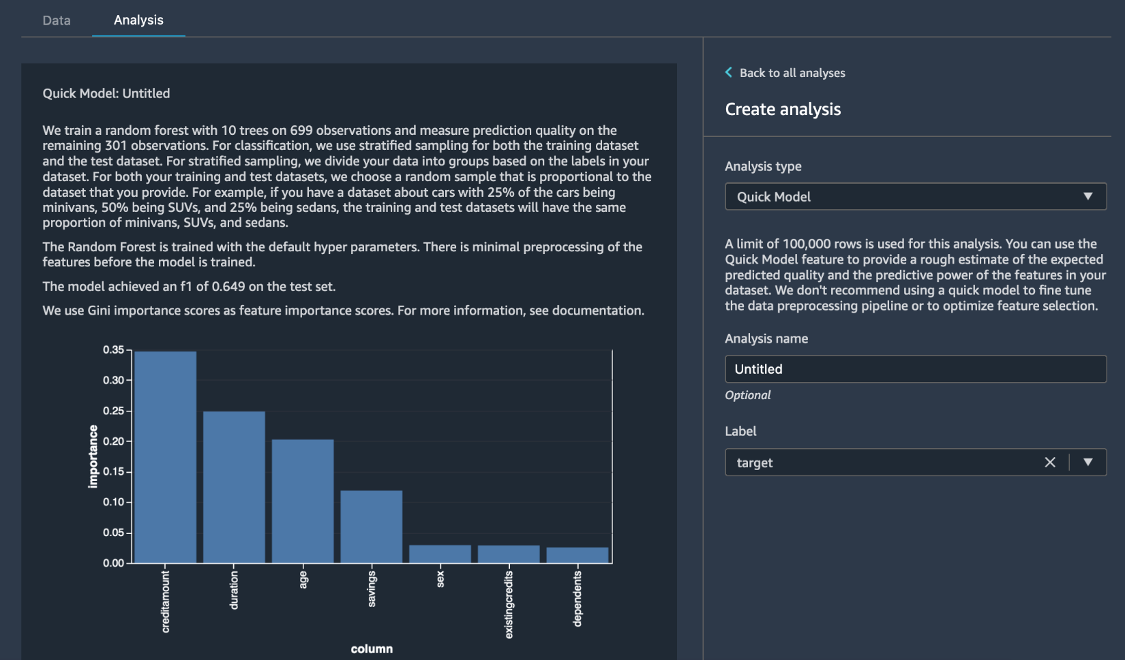
Wählen Sie im Bereich Analyse erstellen als Analysetyp, die Option Quick Model aus. Wählen Sie für Bezeichnung die Option Risiko, und wählen Sie dann Vorschau. Der Bereich Quick Model zeigt Ihnen einen kurzen Überblick über das verwendete Modell und einige grundlegende Statistiken, einschließlich des F1-Scores und der Merkmalsbedeutung, um Ihnen bei der Bewertung der Qualität des Datensatzes zu helfen. Wählen Sie Speichern aus.
Schritt 4: Hinzufügen von Transformationen zum Datenablauf
SageMaker Data Wrangler vereinfacht die Datenverarbeitung, indem es eine visuelle Schnittstelle bereitstellt, mit der Sie eine Vielzahl von vorgefertigten Transformationen hinzufügen können. Sie können Ihre benutzerdefinierten Transformationen auch mithilfe von SageMaker Data Wrangler schreiben. In diesem Schritt können Sie komplexe Zeichenkettendaten reduzieren, Kategorien kodieren, Spalten umbenennen und überflüssige Spalten mit dem visuellen Editor entfernen. Anschließend teilen Sie die Spalte status_sex in zwei neue Spalten auf, marital_status und sex.
Um zum Datenablaufdiagramm zu navigieren, wählen Sie Datenablauf.

Wählen Sie im Datenablaufdiagramm das Symbol +, Transformation hinzufügen aus.

Wählen Sie im Bereich ALL STEPS die Option Schritt hinzufügen aus.

Wählen Sie in der Liste ADD TRANSFORM die Option Suchen und bearbeiten, eine Transformation, die zur Bearbeitung von Zeichenfolgendaten verwendet wird.

Wählen Sie im Bereich SEARCH AND EDIT für Transformieren die Option Zeichenfolge nach Trennzeichen teilen. Wählen Sie für Eingabespalten status_sex aus. Geben Sie im Feld Trennzeichen das Symbol : ein. Geben Sie in der Ausgabespalte vec ein. Wählen Sie Vorschau und dann Hinzufügen aus.
Diese Transformation erstellt eine neue Spalte namens vec am Ende des Datenrahmens, indem die Spalte status_sex geteilt wird. Die Spalte status_sex enthält durch Doppelpunkte getrennte Zeichenfolgen, und die neue Spalte vec enthält durch Kommas getrennte Vektoren.

So teilen Sie die Spalte vec und erstellen zwei neue Spalten, sex_split_0 und sex_split_1:
Wählen Sie unter ALL STEPS die Option + Schritt hinzufügen aus.
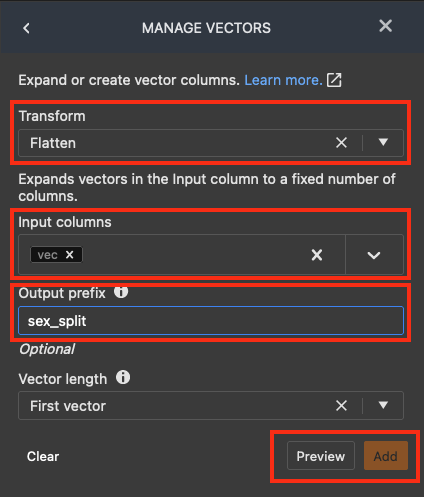
Wählen Sie in der Liste ADD TRANSFORM die Option Vektoren verwalten.
Wählen Sie im Bereich MANAGE VECTORS unter Transformieren die Option Abflachen. Wählen Sie für Eingabespalten vec aus. Geben Sie für output_prefix sex_split ein.
Wählen Sie Vorschau und dann Hinzufügen aus.
So benennen Sie die durch die Split-Transformation erstellten Spalten um:
Wählen Sie im Bereich ALL STEPS die Option + Schritt hinzufügen aus.
Wählen Sie in der Liste ADD TRANSFORM die Option Spalten verwalten.
Wählen Sie im Bereich MANAGE COLUMNS für Transformieren die Option Spalte umbenennen. Wählen Sie für die Eingabespalte sex_split_0 aus. Geben Sie im Feld Neuer Name sex ein.
Wählen Sie Vorschau und dann Hinzufügen aus.
Wiederholen Sie diesen Vorgang, um sex_split_1 in marital_status umzubenennen.

Schritt 5: Hinzufügen kategorischer Kodierung
In diesem Schritt erstellen Sie ein Modellierungsziel und codieren kategoriale Variablen. Die kategoriale Codierung wandelt Kategorien von Zeichenfolgedatentypen in numerische Bezeichnungen um. Dies ist eine gängige Vorverarbeitungsaufgabe, da die numerischen Beschriftungen in einer Vielzahl von Modelltypen verwendet werden können.
Im Datensatz wird die Kreditrisikoklassifizierung durch die Zeichenfolgen hohes Risiko und niedriges Risiko dargestellt. In diesem Schritt konvertieren Sie diese Klassifizierung in eine binäre Darstellung, 0 oder 1.
Wählen Sie im Bereich ALL STEPS die Option + Schritt hinzufügen aus. Wählen Sie in der Liste ADD TRANSFORM die Option Kategorial codieren aus. SageMaker Data Wrangler bietet drei Transformationstypen: Ordinale Codierung, One-Hot-Codierung und Ähnlichkeits-Codierung. Belassen Sie im Bereich ENCODE CATEGORICAL für Transformieren die Standardeinstellung Ordinale Codierung. Wählen Sie für Eingabespalten Risiko. Geben Sie in der Ausgabespalte Ziel ein. Ignorieren Sie das Feld Ungültige Behandlungsstrategie für dieses Tutorial. Wählen Sie Vorschau und dann Hinzufügen aus.

# Table is available as variable ‘df’
savings_map = {"unknown":0, "little":1, "moderate":2, "high":3, "very high":4}
df["savings"] = df["savings"].map(savings_map).fillna(df["savings"])

Verwenden Sie die Transformation kategorial codieren, um die übrigen Spalten housing, job, sex und marital_status wie folgt zu codieren: Wählen Sie unter ALL STEPS die Option + Schritt hinzufügen aus. Wählen Sie in der Liste ADD TRANSFORM die Option kategorial codieren aus. Belassen Sie im Bereich ENCODE CATEGORICAL für Transformieren die Standardeinstellung Ordinale Codierung. Wählen Sie für Eingabespalten housing, job, sex und marital_status aus. Lassen Sie die Ausgabespalte leer, damit die codierten Werte die kategorialen Werte ersetzen. Wählen Sie Vorschau und dann Hinzufügen aus.

Um die numerische Spalte creditamount zu skalieren, wenden Sie einen Scaler auf den Kreditbetrag an, um die Verteilung der Daten in dieser Spalte zu normalisieren: Wählen Sie im Bereich ALL STEPS die Option + Schritt hinzufügen aus. Wählen Sie in der Liste ADD TRANSFORM die Option Numerisch verarbeiten. Wählen Sie für Scaler die Standardoption Standard-Scaler. Wählen Sie für Eingabespalten creditamount aus. Wählen Sie Vorschau und dann Hinzufügen.


So löschen Sie die transformierten Originalspalten: Wählen Sie im Bereich ALL STEPS die Option + Schritt hinzufügen aus. Wählen Sie in der Liste ADD TRANSFORM die Option Spalten verwalten. Wählen Sie im Bereich MANAGE COLUMNS für Transformieren die Option Spalte verwerfen. Wählen Sie für die Zu verwerfenden Spalten status_sex, existingchecking, employmentsince, risk, und vec. Wählen Sie Vorschau und dann Hinzufügen.

Schritt 6: Ausführen einer Datenverzerrungskontrolle
Überprüfen Sie in diesem Schritt Ihre Daten mithilfe von Amazon SageMaker Clarify auf Verzerrungen. Diese bieten Ihnen einen besseren Einblick in Ihre Trainingsdaten und -modelle, damit Sie Verzerrungen erkennen und begrenzen und Vorhersagen erklären können.
Wählen Sie Datenablauf oben links, um zum Datenablaufdiagramm zurückzukehren. Wählen Sie das Symbol +, Analyse hinzufügen aus. Wählen Sie im Bereich Analyse erstellen unter Analysetyp die Option Verzerrungsbericht aus. Geben Sie für Analysename einen beliebigen Namen ein . Wählen Sie für Spalte auswählen, die Ihr Modell vorhersagt (Ziel) die Option Ziel aus. Lassen Sie das Kontrollkästchen Wert aktiviert. Geben Sie im Feld Vorhergesagte(r) Wert(e) 1 ein. Wählen Sie unter Spalte auswählen, die auf Verzerrung analysiert werden soll die Option sex. Behalten Sie für Verzerrungsmetriken auswählen die Standardeinstellungen bei. Wählen Sie Prüfen auf Verzerrung.
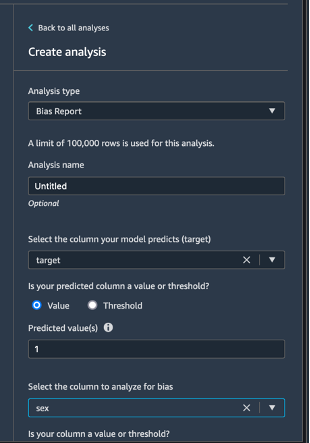
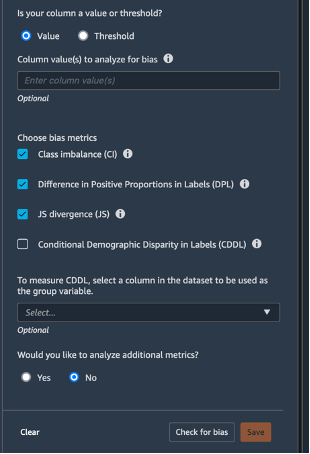
Nach einigen Sekunden generiert SageMaker Clarify einen Bericht, der zeigt, wie die Ziel- und Testspalten bei einer Reihe von verzerrungsbezogenen Metriken abschneiden, darunter Class Imbalance (CI) und Difference in Positive Proportions in Labels (DPL). In diesem Fall sind die Daten in Bezug auf sex leicht verzerrt (-0,38) und in Bezug auf labels nicht sehr verzerrt (0,075). Basierend auf diesem Bericht könnten Sie eine Methode zur Behebung von Verzerrungen in Betracht ziehen, z. B. die Verwendung der integrierten SMOTE-Transformation von SageMaker Data Wrangler. Überspringen Sie für die Zwecke dieses Tutorials den Schritt der Behebung. Wählen Sie Speichern, um den Bias-Bericht im Datenablauf zu sichern.

Schritt 7: Export Ihres Datenablaufs
Exportieren Sie Ihren Datenablauf in ein Jupyter Notebook, um die Schritte als SageMaker-Verarbeitungsaufträge auszuführen. Diese Schritte verarbeiten die Daten gemäß Ihrem definierten Datenablauf und speichern die Ausgaben in Amazon S3 oder Amazon SageMaker Feature Store.
Wählen Sie im Datenablaufdiagramm das Symbol +, Exportieren nach, Amazon S3 (über Jupyter Notebook). Dadurch wird ein Notebook in SageMaker Studio erstellt, in dem Sie die generierten SageMaker-Verarbeitungsaufträge ausführen können, um den transformierten Datensatz zu erstellen. Führen Sie dieses Notebook aus, um die Ergebnisse im standardmäßigen S3-Bucket zu speichern.



Schritt 8: Bereinigen der Ressourcen
Es ist eine bewährte Methode, Ressourcen zu löschen, die Sie nicht mehr verwenden, um unerwünschte Gebühren zu vermeiden.
Gehen Sie wie folgt vor, um den S3-Bucket zu löschen:
- Öffnen Sie die Amazon S3-Konsole. Wählen Sie auf der Navigationsleiste Buckets, sagemaker-<your-Region>-<your-account-id>, und aktivieren Sie dann das Kontrollkästchen neben data_wrangler_flows. Wählen Sie dann Löschen.
- Vergewissern Sie sich im Dialogfeld Objekte löschen, dass Sie das richtige Objekt zum Löschen ausgewählt haben, und geben Sie dauerhaft löschen im Bestätigungsfeld Objekte dauerhaft löschen ein.
- Sobald dies abgeschlossen und der Bucket leer ist, können Sie den Bucket sagemaker-<your-Region>-<your-account-id> löschen, indem Sie dasselbe Verfahren erneut ausführen.

Der Data-Science-Kernel, der zum Ausführen des Notebook-Images in diesem Tutorial verwendet wird, sammelt Gebühren an, bis Sie entweder den Kernel stoppen oder die folgenden Schritte ausführen, um die Anwendungen zu löschen. Weitere Informationen finden Sie unter Ressourcen herunterfahren im Entwicklerhandbuch zu Amazon SageMaker.
Gehen Sie wie folgt vor, um die SageMaker Studio-Apps zu löschen: Wählen Sie in der SageMaker Studio-Konsole studio-user aus und löschen Sie dann alle unter Apps aufgelisteten Apps, indem Sie App löschen auswählen. Warten Sie, bis sich der Status in Gelöscht ändert.

Wenn Sie in Schritt 1 eine vorhandene SageMaker-Studio-Domäne verwendet haben, überspringen Sie den Rest von Schritt 8 und fahren Sie direkt mit dem Abschlussabschnitt fort.
Wenn Sie die CloudFormation-Vorlage in Schritt 1 ausgeführt haben, um eine neue SageMaker-Studio-Domäne zu erstellen, fahren Sie mit den folgenden Schritten fort, um die Domäne, den Benutzer und die von der CloudFormation-Vorlage erstellten Ressourcen zu löschen.
Um die CloudFormation-Konsole zu öffnen, geben Sie CloudFormation in die Suchleiste der AWS-Konsole ein, und wählen Sie CloudFormation aus den Suchergebnissen aus.

Wählen Sie im Bereich CloudFormation die Option Stacks aus. Wählen Sie in der Status-Dropdown-Liste Aktiv aus. Wählen Sie unter Stack-Name CFN-SM-IM-Lambda-catalog aus, um die Stack-Detailseite zu öffnen.

Wählen Sie auf der Stack-Detailseite des CFN-SM-IM-Lambda-catalog Löschen aus, um den Stack zusammen mit den in Schritt 1 erstellten Ressourcen zu löschen.

Zusammenfassung
Sie haben Amazon SageMaker Data Wrangler erfolgreich verwendet, um Daten für das Training eines Machine-Learning-Modells vorzubereiten. SageMaker Data Wrangler bietet mehr als 300 vorkonfigurierte Datentransformationen, wie z. B. Spaltentyp konvertieren, One-Hot-Codierung, Fehlende Daten mit Mittelwert oder Median ersetzen, Spalten neu skalieren und Datums-/Zeiteinbettungen, sodass Sie Ihre Daten in geeignete Formate umwandeln können die effektiv für Modelle verwendet werden können, ohne eine einzige Codezeile zu schreiben.
Trainieren eines Deep-Learning-Modells
Automatisches Erstellen eines ML-Modells
Weitere praktische Tutorials finden