Cree un modelo de aprendizaje automático de inmediato
con Amazon SageMaker Autopilot
Amazon SageMaker es un servicio completamente administrado que brinda a todos los científicos de datos y desarrolladores la capacidad de crear, entrenar e implementar modelos de aprendizaje automático de forma rápida.
En este tutorial, creará modelos de aprendizaje automático de inmediato sin escribir una línea de código. Utilice Amazon SageMaker Autopilot, una capacidad de AutoML que crea de inmediato los mejores modelos de aprendizaje automático para clasificación y regresión, al mismo tiempo que permite control y visibilidad completos.
En este tutorial, aprenderá a hacer lo siguiente:
- Crear una cuenta de AWS
- Configurar Amazon SageMaker Studio para acceder a Amazon SageMaker Autopilot.
- Descargar un conjunto de datos público con Amazon SageMaker Studio.
- Crear un experimento de entrenamiento con Amazon SageMaker Autopilot.
- Explorar las diferentes etapas del experimento de entrenamiento.
- Identificar e implementar el modelo con mejor rendimiento del experimento de entrenamiento.
- Hacer predicciones con el modelo implementado.
En este tutorial, asume el rol de desarrollador que trabaja en un banco. Se le solicita que desarrolle un modelo de aprendizaje automático para predecir si los clientes se inscribirán para un certificado de depósito. El modelo se entrenará con el conjunto de datos de marketing que contiene la información demográfica de los clientes, sus respuestas a los eventos de marketing y los factores externos.
| Acerca de este tutorial | |
|---|---|
| Duración | 10 minutos
|
| Costo | Menos de 10 USD |
| Caso de uso | Machine Learning |
| Productos | Amazon SageMaker |
| Público | Desarrollador |
| Nivel | Principiante |
| Última actualización | 12 de mayo de 2020 |
Paso 1. Cree una cuenta de AWS
El costo de este taller es menos de 10 USD. Para obtener más información, consulte los precios de Amazon SageMaker Studio.
¿Ya tiene una cuenta? Inicie sesión
Paso 2. Configure Amazon SageMaker Studio
Complete los siguientes pasos para incorporarse a Amazon SageMaker Studio y acceder a Amazon SageMaker Autopilot.
Nota: Para obtener más información, consulte Introducción a Amazon SageMaker Studio en la documentación de Amazon SageMaker.
a. Inicie sesión en la consola de Amazon SageMaker.
Nota: En la esquina superior derecha, asegúrese de seleccionar una región de AWS donde Amazon SageMaker Studio esté disponible. Para obtener una lista de regiones, consulte Incorporación a Amazon SageMaker Studio.


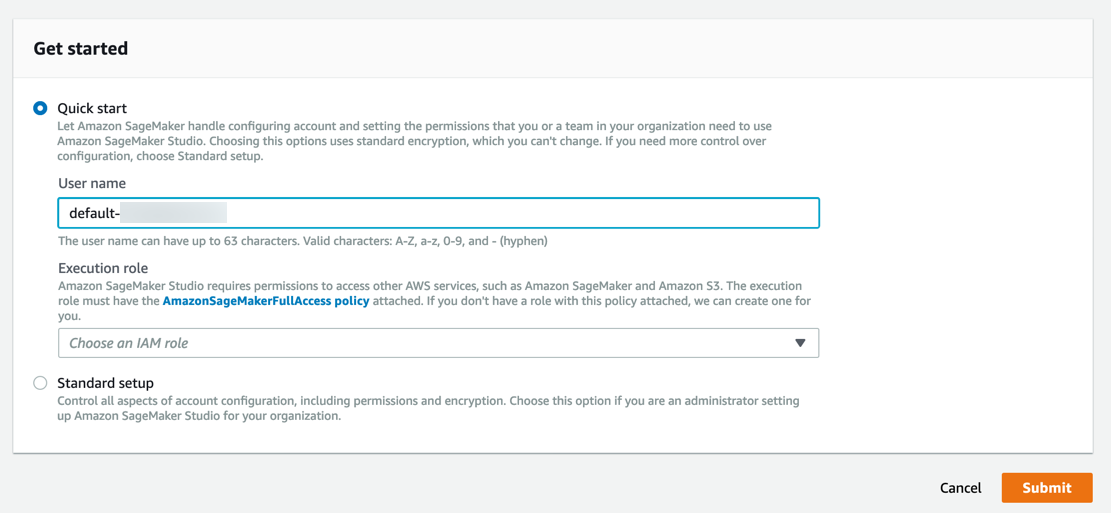
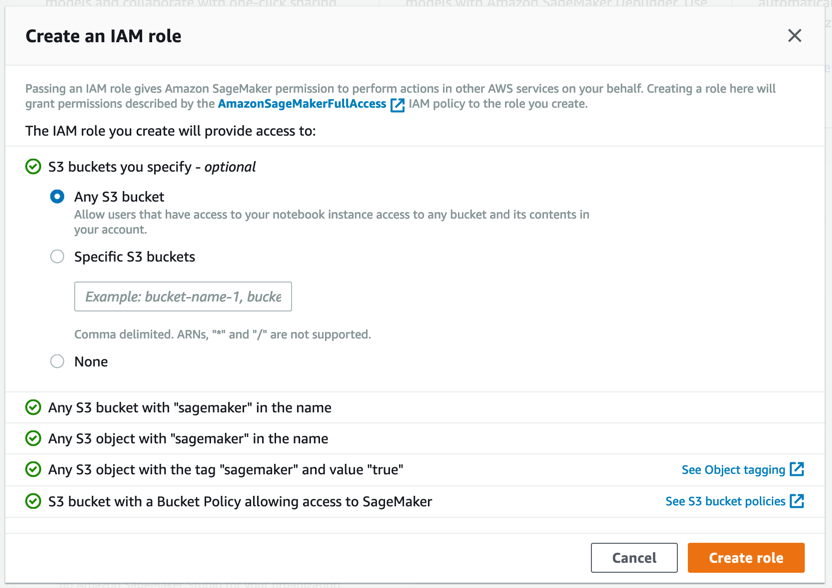
Amazon SageMaker crea un rol con los permisos necesarios y lo asigna a su instancia.
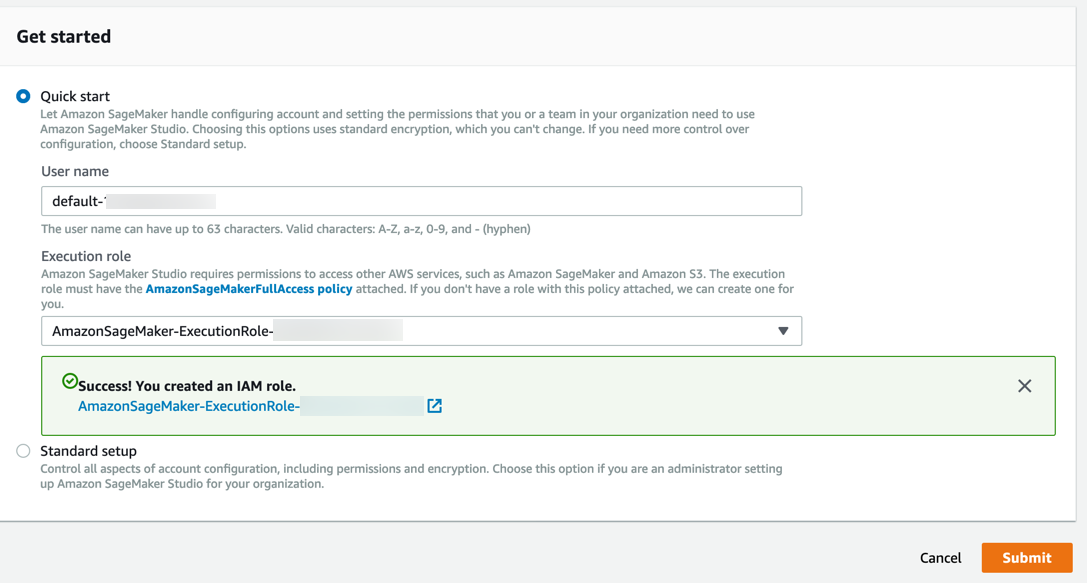
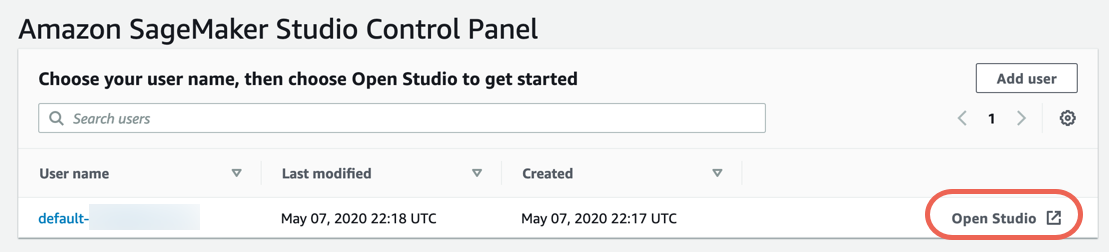
Paso 3. Descargue el conjunto de datos.
Complete los siguientes pasos para descargar y explorar el conjunto de datos.
Nota: Para obtener más información, consulte la sección Recorrido por Amazon SageMaker Studio en la documentación de Amazon SageMaker.
%%sh
apt-get install -y unzip
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
unzip -o bank-additional.zip
d. Copie y pegue el siguiente código en una nueva celda de código y elija Run (Ejecutar).
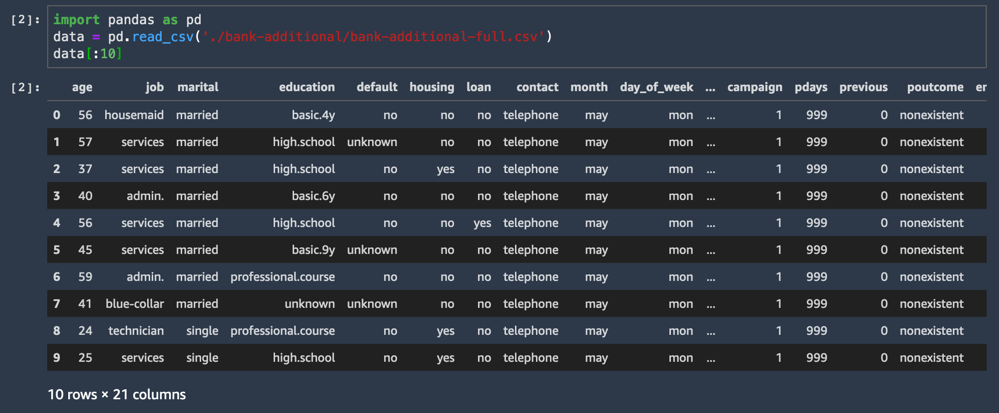
Se carga el conjunto de datos CSV y se muestran las primeras diez líneas.
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv')
data[:10]Una de las columnas del conjunto de datos se llama y representa la etiqueta de cada muestra: ¿este cliente aceptó la oferta o no?
En este paso, es donde los científicos de datos comenzarán a explorar los datos, crear nuevas características, etc. Con Amazon SageMaker Autopilot, no es necesario que realice ninguno de estos pasos adicionales. Simplemente tiene que cargar los datos tabulares en un archivo con valores separados por comas (por ejemplo, desde una hoja de cálculo o una base de datos) y elegir la columna de destino para predecir. A partir de allí, Autopilot crea un modelo predictivo para usted.
d. Copie y pegue el siguiente código en una nueva celda de código y elija Run (Ejecutar).
Este paso carga el conjunto de datos CSV en un bucket de Amazon S3. No es necesario crear un bucket de Amazon S3; Amazon SageMaker crea automáticamente un bucket predeterminado en su cuenta cuando carga los datos.
import sagemaker
prefix = 'sagemaker/tutorial-autopilot/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix)
print(uri)
¿Está preparado? La salida del código muestra el URI del bucket de S3 como en el siguiente ejemplo:
s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csvLleve un registro del URI de S3 impreso en su propio notebook. Lo necesitará en el siguiente paso.

Paso 4. Cree un experimento de SageMaker Autopilot.
Ahora que ha descargado y organizado en etapas el conjunto de datos en Amazon S3, puede crear un experimento de Amazon SageMaker Autopilot. Un experimento es una compilación de trabajos de procesamiento y entrenamiento relacionados con el mismo proyecto de aprendizaje automático.
Siga los pasos que se describen a continuación para crear un experimento.
Nota: Para obtener más información, consulte la sección Crear un experimento de Amazon SageMaker Autopilot en SageMaker Studio en la documentación de Amazon SageMaker.
a. En el panel de navegación de la izquierda de Amazon SageMaker Studio, elija Experiments (Experimentos), con un ícono simbolizado por un matraz, y elija Create Experiment (Crear experimento).
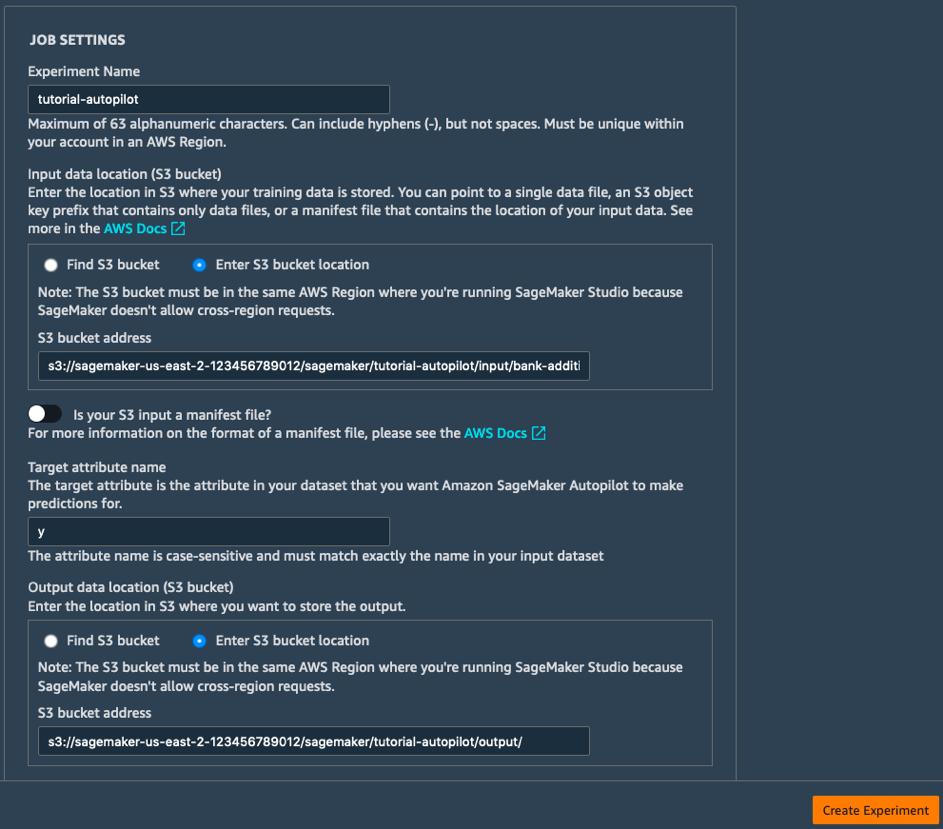
b. Complete los campos en Job Settings (Ajustes del trabajo) de la siguiente manera:
- Experiment Name (Nombre del experimento): tutorial-autopilot.
- S3 location of input data (Ubicación en S3 de datos de entrada): URI que imprimió anteriormente.
(p. ej.: s3://sagemaker-us-east-2-123456789012/sagemaker/tutorial-autopilot/input/bank-additional-full.csv) - Target attribute name (Nombre del atributo de destino): y.
- S3 location for output data (Ubicación en S3 de datos de salida): s3://sagemaker-us-east-2-[ACCOUNT-NUMBER]/sagemaker/tutorial-autopilot/output
(asegúrese de reemplazar [ACCOUNT-NUMBER] por su número de cuenta).
c. Deje todos los ajustes predeterminados y elija Create Experiment (Crear experimento).
¡Correcto! Así comienza el experimento de Amazon SageMaker Autopilot. El proceso generará un modelo y estadísticas que podrá ver en tiempo real mientras se ejecuta el experimento. Una vez completado el experimento, puede ver las pruebas, ordenar por métrica objetiva y hacer clic con el botón derecho para implementar el modelo para su uso en otros entornos.
Paso 5. Explore las etapas de un experimento de SageMaker Autopilot.
Mientras se ejecuta su experimento, puede conocer y explorar las diferentes etapas del experimento de SageMaker Autopilot.
Esta sección ofrece más detalles sobre las etapas del experimento de SageMaker Autopilot:
- Análisis de datos
- Diseño de características
- Adaptación de modelos
Nota: Para obtener más información, consulte el artículo Salida del notebook de SageMaker Autopilot.
Análisis de datos
La etapa de Análisis de datos identifica el tipo de problema a resolver (regresión lineal, clasificación binaria, clasificación multiclase). Luego, aparecen hasta diez canalizaciones candidatas. Una canalización combina el procesamiento previo de datos (manejo de valores faltantes, diseño de nuevas características, etc.) y el entrenamiento de modelo con un algoritmo de AA que coincide con el tipo de problema. Una vez que se completa este paso, el trabajo pasa al diseño de características.
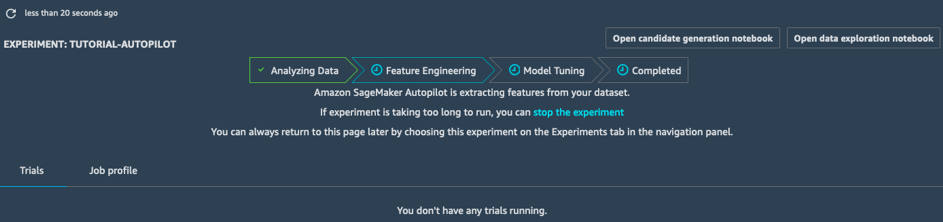
Diseño de características
En la etapa de Diseño de características, el experimento crea conjuntos de datos de entrenamiento y validación para cada canalización candidata, y almacena todos los artefactos en su bucket de S3. Durante esta etapa, puede abrir y ver dos notebooks generados automáticamente:
- Los notebooks de exploración de datos, que contienen información y estadísticas sobre el conjunto de datos.
- El notebook de generación de candidatos, que contiene la definición de las diez canalizaciones. De hecho, este es un notebook ejecutable: puede reproducir exactamente lo que hace el trabajo de AutoPilot, comprender cómo se crean los diferentes modelos e incluso seguir adaptándolos, si lo desea.
Con estos dos notebooks, puede comprender en detalle cómo se procesan previamente los datos y cómo se crean y optimizan los modelos. Esta transparencia es una característica importante de Amazon SageMaker Autopilot.
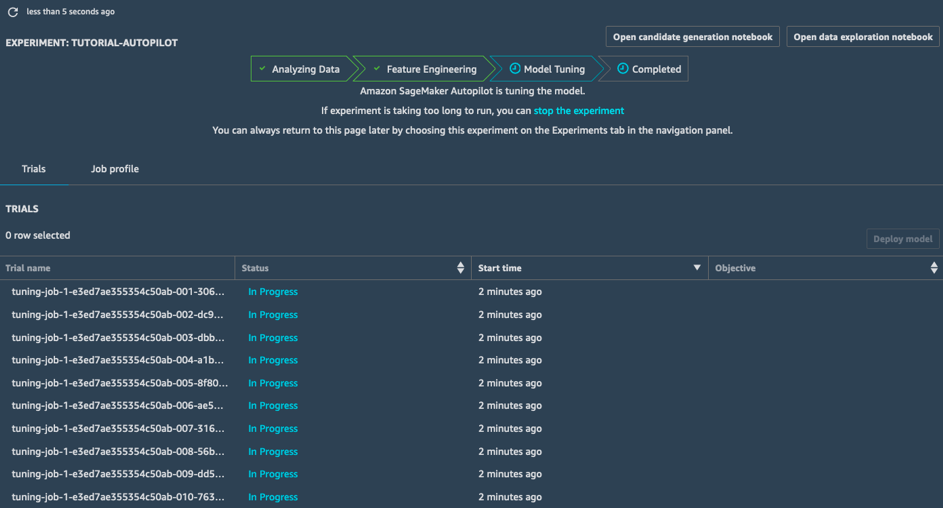
Adaptación de modelos
En la etapa de Adaptación de modelos, SageMaker Autopilot lanza un trabajo de optimización de hiperparámetros para cada canalización candidata y su conjunto de datos procesado previamente. Los trabajos de entrenamiento asociados exploran una amplia gama de valores de hiperparámetros y convergen rápidamente en modelos de alto rendimiento.
Una vez que se completa esta etapa, se completa el trabajo de SageMaker Autopilot. Puede ver y explorar todos los trabajos en SageMaker Studio.
Paso 6. Implemente el mejor modelo
Ahora que ha completado su experimento, puede elegir el mejor modelo adaptado e implementarlo en un punto de enlace administrado por Amazon SageMaker.
Siga estos pasos para elegir el mejor trabajo de adaptación e implementar el modelo.
Nota: Para obtener más información, consulte el artículo Choose and deploy the best model (Elija e implemente el mejor modelo).
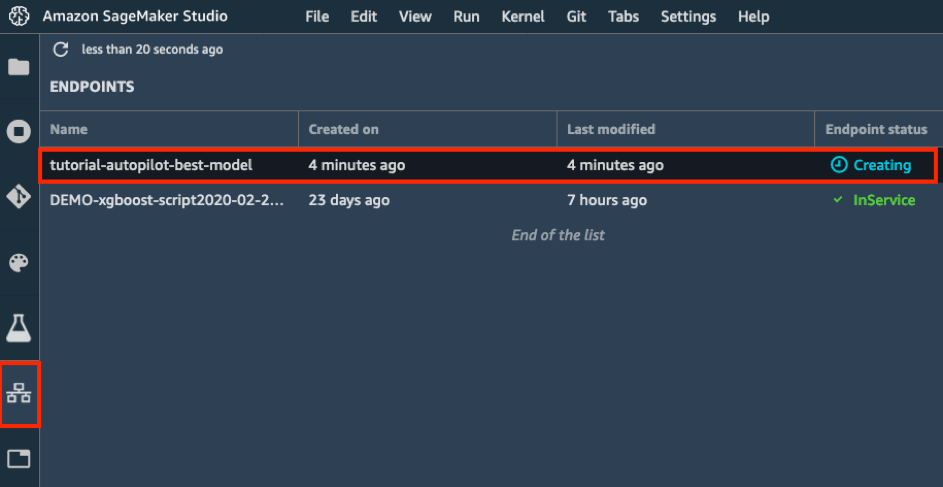
a. En la lista Trials (Pruebas) de su experimento, elija el icono junto a Objective (Objetivo) para ordenar los trabajos de adaptación en orden descendente. El mejor trabajo de adaptación se resalta con una estrella.
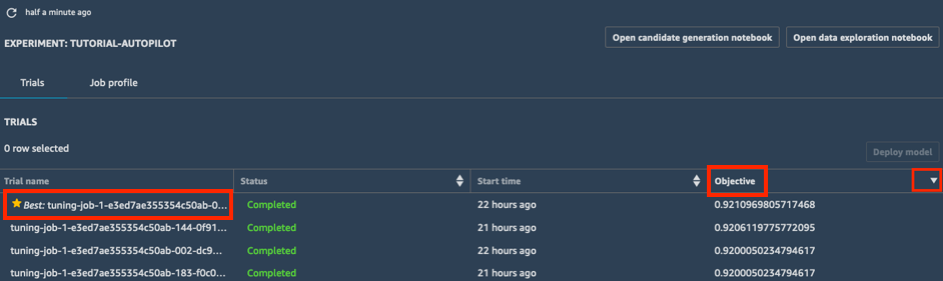
b. Seleccione el mejor trabajo de adaptación (indicado por una estrella) y elija Deploy model (Implementar modelo).
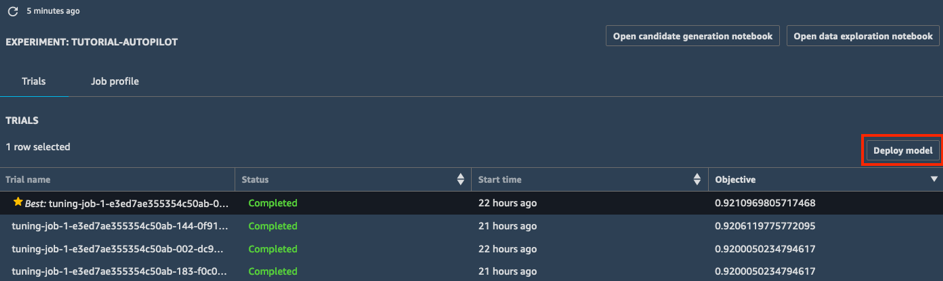
c. En la casilla Deploy model (Implementar modelo), dé un nombre a su punto de enlace (p. ej., tutorial-autopilot-best-model) y deje todos los ajustes predeterminados. Elija Deploy model (Implementar modelo).
Su modelo se implementa en un punto de enlace HTTPS administrado por Amazon SageMaker.
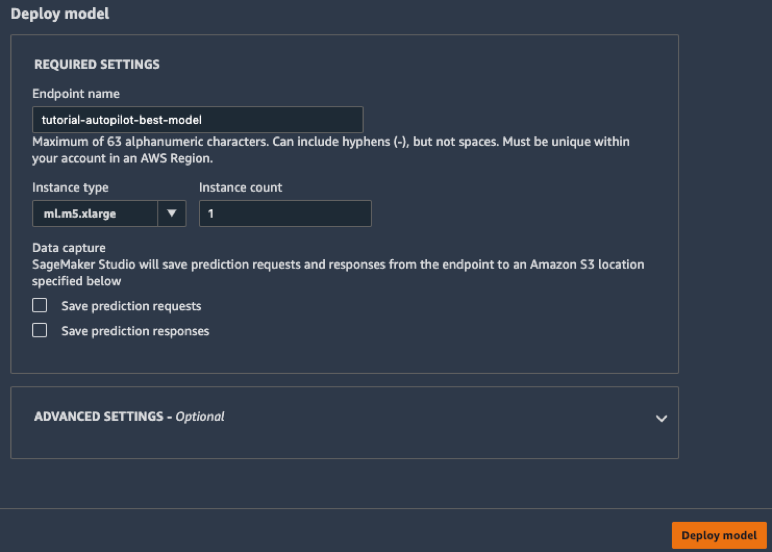
d. En la barra de herramientas izquierda, elija el ícono Endpoints (Puntos de enlace). Puede ver cómo se crea su modelo, lo que tomará unos minutos. Una vez que el estado del punto de enlace es InService (En servicio), puede enviar datos y recibir predicciones.
Paso 7. Haga predicciones con su modelo
Ahora que el modelo está implementado, puede predecir las primeras 2000 muestras del conjunto de datos. Para este propósito, utiliza la API invoke_endpoint en el SDK boto3. En el proceso, calcula métricas importantes de aprendizaje automático: accuracy (exactitud), precision (precisión), recall (exhaustividad) y F1 score (Valor-F).
Siga estos pasos para hacer predicciones con su modelo.
Nota: Para obtener más información, consulte la sección Administrar el aprendizaje automático con experimentos de Amazon SageMaker.
En su notebook de Jupyter, copie y pegue el siguiente código y elija Run (Ejecutar).
import boto3, sys
ep_name = 'tutorial-autopilot-best-model'
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print ("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if (count % 100 == 0):
sys.stdout.write(str(count)+' ')
print ("Done")
accuracy = (tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tn/(tn+fn)
f1 = (2*precision*recall)/(precision+recall)
print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
Debería ver el siguiente resultado,
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done
0.9830 0.6538 0.9873 0.7867
que es un indicador de progreso que permite ver la cantidad de muestras que se predijeron.
Paso 8. Elimine recursos
En este paso, finalizará los recursos que utilizó en este laboratorio.
Importante: Al finalizar los recursos que no se están utilizando de forma activa se reducen los costos. Es una práctica que recomendamos. Si no finaliza sus recursos, recibirá cargos en su cuenta.
Elimine su punto de enlace: en su notebook de Jupyter, copie y pegue el siguiente código y elija Run (Ejecutar).
sess.delete_endpoint(endpoint_name=ep_name)Si desea eliminar todos los artefactos de entrenamiento (modelos, conjuntos de datos procesados previamente, etc.), copie y pegue el siguiente código en la celda de código y elijaRun (Ejecutar).
Nota: Asegúrese de reemplazar ACCOUNT_NUMBER por su número de cuenta.
%%sh
aws s3 rm --recursive s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/Felicitaciones
Creó de inmediato un modelo de aprendizaje automático con la mejor precisión utilizando Amazon SageMaker Autopilot.
Pasos siguientes recomendados
Haga un recorrido por Amazon SageMaker Studio
Más información acerca de Amazon SageMaker Autopilot
Si quiere obtener más información, lea la publicación en el blog o vea la serie de videos sobre Autopilot.