Qu'est-ce que l'apprentissage par renforcement ?
Qu'est-ce que l'apprentissage à renforcement ?
L'apprentissage par renforcement (RL) est une technique d'apprentissage automatique (ML) qui entraîne les logiciels à prendre des décisions afin d'obtenir les résultats les plus optimaux. Elle imite le processus d'apprentissage par tâtonnements employé par les êtres humains pour atteindre leurs objectifs. Les actions logicielles qui contribuent à la réalisation de votre objectif sont renforcées, tandis que les actions qui nuisent à celle-ci sont ignorées.
Les algorithmes de RL utilisent un paradigme de récompense et de punition lorsqu'ils traitent les données. Ils apprennent du retour d'information de chaque action et découvrent par eux-mêmes les chemins de traitement optimaux pour atteindre les résultats finaux. Les algorithmes sont également capables de différer la gratification. La meilleure stratégie globale peut exiger des sacrifices à court terme ; ainsi, l'approche la plus efficace qu'ils découvrent peut inclure des punitions ou des retours en arrière. La RL est une méthode puissante qui aide les systèmes d'intelligence artificielle (IA) à obtenir des résultats optimaux dans des environnements invisibles.
Les avantages de l'apprentissage par renforcement
L'apprentissage par renforcement (RL) présente de nombreux avantages : en voici les trois principaux.
Excelle dans les environnements complexes
Les algorithmes de RL peuvent être utilisés dans des environnements complexes comportant de nombreuses règles et dépendances. Dans un même environnement, un être humain n'est pas toujours capable de déterminer le meilleur chemin à suivre, même s'il possède une connaissance supérieure de cet environnement. En revanche, les algorithmes de RL sans modèle s'adaptent rapidement aux environnements en constante évolution et trouvent de nouvelles stratégies pour optimiser les résultats.
Nécessite moins d'interactions humaines
Dans les algorithmes de ML classiques, un être humain doit étiqueter les paires de données pour guider l'algorithme ; ce processus n'est pas nécessaire avec un algorithme de RL, car il apprend seul. Dans le même temps, il propose des mécanismes permettant d'intégrer des commentaires humains qui aident à créer des systèmes s'adaptant aux préférences, à l'expertise et aux corrections humaines.
Optimiser les actions pour atteindre des objectifs à long terme
Le RL se concentre intrinsèquement sur la maximisation des récompenses à long terme, ce qui le rend idéal dans les scénarios où les actions ont des conséquences prolongées. Il est adapté aux situations réelles où chaque étape n'est pas immédiatement commentée, car l'algorithme peut apprendre des récompenses différées.
Par exemple, les décisions relatives à la consommation ou au stockage d'énergie peuvent avoir des conséquences à long terme : il est possible d'utiliser le RL pour optimiser l'efficacité énergétique et les coûts à long terme. Avec des architectures adéquates, les agents de RL peuvent aussi généraliser leurs stratégies apprises sur des tâches similaires mais non identiques.
Les cas d'utilisation de l'apprentissage par renforcement
L'apprentissage par renforcement (RL) peut être appliqué à une grande variété de cas d'utilisation concrets. Nous en donnons quelques exemples ensuite.
Personnalisation du marketing
Dans des applications comme les systèmes de recommandation, le RL est capable de personnaliser les suggestions transmises aux utilisateurs individuels en fonction de leurs interactions afin de créer des expériences plus personnelles. Par exemple, une application peut afficher des publicités destinées à un utilisateur en fonction de certaines informations démographiques. À chaque interaction avec une publicité, l'application apprend quelles publicités afficher sur l'appareil de l'utilisateur pour optimiser les ventes de produits.
Défis liés à l'optimisation
Les méthodes d'optimisation classiques résolvent les problèmes en évaluant et en comparant les solutions possibles en fonction de certains critères. Dans le cadre du RL, l'apprentissage se base en revanche sur les interactions afin de trouver les meilleures solutions ou des solutions s'en rapprochant le plus possible au fil du temps.
Par exemple, un système d'optimisation des dépenses dans le cloud a recours au RL pour suivre les variations des besoins en ressources et sélectionner les types d'instances, les quantités et les configurations optimaux. Il prend des décisions en fonction de facteurs tels que l'infrastructure cloud actuelle et disponible, les dépenses et l'utilisation.
Prédictions financières
La dynamique des marchés financiers est complexe, et comprend des propriétés statistiques qui changent au fil du temps. Les algorithmes de RL peuvent optimiser les rendements à long terme en tenant compte des coûts de transaction et en suivant les fluctuations du marché.
Par exemple, un algorithme peut observer les règles et les modèles du marché boursier avant de tester des actions et d'enregistrer les récompenses associées. Il crée dynamiquement une fonction de valeur et développe une stratégie pour maximiser les profits.
Comment fonctionne l'apprentissage par renforcement ?
Le processus d'apprentissage des algorithmes d'apprentissage par renforcement (RL) est similaire à l'apprentissage par renforcement animal et humain dans le domaine de la psychologie comportementale. Par exemple, un enfant peut découvrir qu'il reçoit des éloges de ses parents lorsqu'il aide un frère ou une sœur ou fait le ménage, mais qu'il reçoit des réactions négatives lorsqu'il jette des jouets ou crie. Rapidement, l'enfant apprend quelle combinaison d'activités aboutit à la récompense finale.
Un algorithme de RL imite un processus d'apprentissage similaire. Il essaie différentes activités pour apprendre les valeurs négatives et positives associées afin d'obtenir le résultat final.
Concepts clés
Dans l'apprentissage par renforcement, vous devez vous familiariser avec quelques concepts clés :
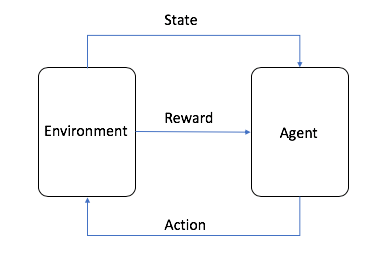
- L'agent est l'algorithme de ML (ou le système autonome)
- L'environnement est l'espace adaptatif du problème avec des attributs tels que des variables, des valeurs limites, des règles et des actions valides
- L'action est une étape que l'agent de RL effectue pour naviguer dans l'environnement
- L'état est l'environnement à un moment donné
- La récompense est la valeur positive, négative ou nulle pour avoir effectué une action, en d'autres termes, la récompense ou la punition
- La récompense cumulée est la somme de toutes les récompenses ou la valeur finale
Bases de l'algorithme
L'apprentissage par renforcement est basé sur le processus de décision de Markov, une modélisation mathématique de la prise de décision qui utilise des étapes temporelles discrètes. À chaque étape, l'agent effectue une nouvelle action qui entraîne un nouvel état de l'environnement. De même, l'état actuel est attribué à la séquence des actions précédentes.
Par des essais et des erreurs lors de ses déplacements dans l'environnement, l'agent élabore un ensemble de règles ou de politiques de type si-alors. Les politiques l'aident à décider de la prochaine action à entreprendre pour obtenir une récompense cumulée optimale. L'agent doit également choisir entre une exploration plus approfondie de l'environnement pour découvrir de nouvelles récompenses liées à un état ou sélectionner des actions connues à haut rendement dans un état donné. C'est ce qu'on appelle le compromis entre exploration et exploitation.
Les différents types d'algorithmes d'apprentissage par renforcement
Différents algorithmes sont utilisés dans le cadre de l'apprentissage par renforcement (RL), tels que le Q-learning, les méthodes de gradients de politique, les méthodes de Monte Carlo et l'apprentissage par différence temporelle. Le deep RL est l'application des réseaux neuronaux profonds à l'apprentissage par renforcement. Le TRPO (Trust Region Policy Optimization) est un exemple d'algorithme de deep RL.
Tous ces algorithmes peuvent être regroupés en deux grandes catégories.
RL axé sur un modèle
Le RL axé sur un modèle est généralement utilisé lorsque les environnements sont clairement définis et immuables, et lorsqu'il est difficile de réaliser des tests en environnement réel.
L'agent crée d'abord une représentation interne (un modèle) de l'environnement comme suit :
- Il prend des mesures au sein de l'environnement et consigne le nouvel état ainsi que la valeur de récompense.
- Il associe la transition de l'état vers l'action à la valeur de récompense.
Une fois le modèle terminé, l'agent simule des séquences d'actions en fonction de la probabilité de récompenses cumulées optimales. Il attribue ensuite des valeurs aux séquences d'actions elles-mêmes. L'agent développe ainsi différentes stratégies au sein de l'environnement pour atteindre l'objectif final souhaité.
Exemple
Prenons l'exemple d'un robot qui apprend à naviguer dans un nouveau bâtiment en vue d'atteindre une pièce spécifique. Dans un premier temps, il explore librement son environnement et en crée un modèle interne (une carte). Il peut ainsi notamment découvrir qu'il se trouve face à un ascenseur après avoir avancé de 10 mètres depuis l'entrée principale. Une fois la carte élaborée, le robot est en mesure de concevoir des séries de séquences de trajets les plus courts entre les différentes zones qu'il visite fréquemment dans le bâtiment.
RL sans modèle
Il est préférable d'utiliser le RL sans modèle lorsque l'environnement est vaste, complexe et difficile à décrire. Cette solution est également recommandée lorsque l'environnement est inconnu et changeant, et que les tests basés sur l'environnement ne présentent pas d'inconvénients importants.
L'agent ne crée pas de modèle interne de l'environnement et de sa dynamique, mais utilise une approche par tâtonnements au sein de l'environnement. Il note et consigne les paires état/action ainsi que les séquences de paires état/action pour concevoir une politique.
Exemple
Imaginez une voiture autonome qui doit rouler en ville. Les routes, la densité de la circulation, le comportement des piétons et d'innombrables autres facteurs peuvent rendre l'environnement très dynamique et complexe. Dans un premier temps, les équipes d'IA entraînent le véhicule dans un environnement simulé où le véhicule agit en fonction de son état actuel et reçoit des récompenses ou des pénalités.
En parcourant des millions de kilomètres dans différents scénarios virtuels, le véhicule finit par apprendre quelles sont les meilleures actions pour chaque état sans modéliser explicitement l'ensemble de la dynamique du trafic. Lorsqu'il passe au monde réel, le véhicule utilise la politique qu'il a apprise tout en continuant de l'affiner au moyen de nouvelles données.
La différence entre le machine learning renforcé, supervisé et non supervisé
Bien que l'apprentissage supervisé, l'apprentissage non supervisé et l'apprentissage par renforcement (RL) soient tous trois des algorithmes de machine learning dans le domaine de l'IA, ils présentent chacun des différences.
En savoir plus sur l'apprentissage supervisé et l'apprentissage non supervisé »
Apprentissage par renforcement ou apprentissage supervisé
L'apprentissage supervisé vous permet de définir à la fois l'entrée et la sortie associée attendue. Par exemple, vous pouvez fournir un ensemble d'images étiquetées « chiens ou chats », et l'algorithme devrait ensuite identifier une nouvelle image d'animal comme étant celle d'un chien ou un chat.
Les algorithmes d'apprentissage supervisé apprennent les modèles et les relations entre les paires d'entrée et de sortie pour ensuite prédire les résultats en fonction des nouvelles données d'entrée. Un superviseur, généralement un être humain, doit étiqueter chaque enregistrement de données appartenant à un ensemble de données d'entraînement avec une sortie.
Le RL a quant à lui un objectif final bien défini sous la forme d'un résultat souhaité, sans qu'aucun superviseur ne soit responsable d'étiqueter à l'avance les données associées. Pendant l'entraînement de l'algorithme, celui-ci ne tente pas de mapper les entrées avec les sorties connues mais de mapper les entrées avec les résultats possibles. En récompensant les comportements souhaités, vous privilégiez les meilleurs résultats.
Apprentissage par renforcement ou apprentissage non supervisé
Les algorithmes d'apprentissage non supervisé reçoivent des entrées sans sorties spécifiées pendant le processus d'entraînement, et découvrent des modèles et des relations cachés dans les données en utilisant des méthodes statistiques. Vous pouvez par exemple fournir un ensemble de documents que l'algorithme peut regrouper en catégories qu'il identifie en fonction des mots contenus dans le texte. Vous n'obtenez aucun résultat précis ; celui-ci se situera dans une fourchette.
À l'inverse, le RL vise un objectif final prédéterminé. Bien qu'il adopte une approche exploratoire, les explorations sont constamment validées et améliorées pour augmenter la probabilité d'atteindre l'objectif final. L'algorithme de RL est capable d'apprendre seul à atteindre des résultats très spécifiques.
Les défis de l'apprentissage par renforcement
Bien que les applications d'apprentissage par renforcement (RL) puissent potentiellement changer le monde, il n'est pas toujours facile de déployer de tels algorithmes.
Praticité
Expérimenter avec des systèmes de récompense et de sanction réels n'est pas toujours chose aisée : par exemple, tester un drone en situation réelle sans d'abord le manipuler dans un simulateur provoquerait des dégâts sur un nombre important d'appareils. Les environnements réels subissent des changements fréquents, considérables et soudains susceptibles de nuire à l'efficacité de l'algorithme en situation réelle.
Interprétabilité
Comme dans tout domaine scientifique, la science des données se penche aussi sur les résultats de recherches et les découvertes concluants pour établir des normes et des procédures. Les scientifiques des données préfèrent connaître la façon dont une conclusion spécifique a été atteinte pour la prouver et la reproduire,
mais avec des algorithmes de RL complexes, il peut être difficile de déterminer les raisons pour lesquelles une séquence particulière de mesures a été suivie. Quelles sont les actions de cette séquence qui ont permis d'obtenir le résultat final optimal ? Il est parfois difficile de déduire la réponse à cette question, ce qui peut en compliquer la mise en œuvre.
Ce qu'apporte AWS pour répondre à vos besoins en matière d'apprentissage par renforcement
Amazon Web Services (AWS) propose de nombreuses offres qui vous aident à développer, former et déployer des algorithmes d'apprentissage par renforcement (RL) à utiliser dans des applications concrètes.
Avec Amazon SageMaker, les développeurs et les data scientists peuvent développer rapidement et facilement des modèles RL évolutifs. Associez un cadre de deep learning (comme TensorFlow ou Apache MXNet) à une boîte à outils de RL (par exemple RL Coach ou RLlib) et à un environnement pour imiter un scénario réel. que vous utiliserez pour créer et tester votre modèle.
Avec AWS RoboMaker, les développeurs peuvent exécuter, dimensionner et automatiser la simulation avec des algorithmes RL pour la robotique sans aucune infrastructure requise.
Bénéficiez d'une expérience pratique avec AWS DeepRacer, la voiture de course entièrement autonome à l'échelle 1/18e. qui dispose d'un environnement cloud entièrement configuré servant à entraîner vos modèles de RL et vos configurations de réseaux neuronaux.
Commencez à utiliser l'apprentissage par renforcement sur AWS en créant un compte dès aujourd'hui.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages