Apa itu Pembelajaran Penguatan?
Apa itu pembelajaran penguatan?
Pembelajaran penguatan (RL) adalah teknik pembelajaran mesin (ML) yang melatih perangkat lunak untuk membuat keputusan untuk mencapai hasil yang paling optimal. Pembelajaran penguatan meniru proses pembelajaran coba-coba yang digunakan manusia untuk mencapai tujuannya. Tindakan perangkat lunak yang bekerja menuju tujuan Anda diperkuat, sementara tindakan yang mengurangi tujuan diabaikan.
Algoritma RL menggunakan paradigma hadiah dan hukuman saat memproses data. Mereka belajar dari umpan balik dari setiap tindakan dan menemukan sendiri jalur pemrosesan terbaik untuk mencapai hasil akhir. Algoritma juga mampu menunda kepuasan. Strategi terbaik secara keseluruhan mungkin memerlukan pengorbanan jangka pendek, sehingga pendekatan terbaik yang algortima temukan mungkin menyertakan beberapa hukuman atau runut balik di sepanjang perjalanan. RL adalah metode yang ampuh untuk membantu sistem kecerdasan buatan (AI) mencapai hasil optimal di lingkungan yang tidak terlihat.
Apa manfaat pembelajaran penguatan?
Ada banyak manfaat menggunakan pembelajaran penguatan (RL). Namun, ketiganya sering menonjol.
Unggul dalam lingkungan yang kompleks
Algoritma RL dapat digunakan dalam lingkungan yang kompleks dengan banyak aturan dan dependensi. Dalam lingkungan yang sama, manusia mungkin tidak mampu menentukan jalan terbaik yang harus diambil, bahkan dengan pengetahuan lingkungan yang unggul. Alih-alih, algoritma RL bebas model beradaptasi dengan cepat ke lingkungan yang terus berubah dan menemukan strategi baru untuk mengoptimalkan hasil.
Membutuhkan lebih sedikit interaksi manusia
Dalam algoritma ML tradisional, manusia harus memberi label pasangan data untuk mengarahkan algoritme. Bila Anda menggunakan algoritma RL, ini tidak perlu. Algoritma RL belajar dengan sendirinya. Pada saat yang sama, ia menawarkan mekanisme untuk mengintegrasikan umpan balik manusia, memungkinkan sistem yang beradaptasi dengan preferensi, keahlian, dan koreksi manusia.
Mengoptimalkan tujuan jangka panjang
RL secara inheren berfokus pada maksimalisasi hadiah jangka panjang, yang membuatnya tepat untuk skenario di mana tindakan memiliki konsekuensi yang berkepanjangan. Ini sangat cocok untuk situasi dunia nyata di mana umpan balik tidak segera tersedia untuk setiap langkah, karena dapat belajar dari hadiah yang tertunda.
Misalnya, keputusan tentang konsumsi atau penyimpanan energi mungkin memiliki konsekuensi jangka panjang. RL dapat digunakan untuk mengoptimalkan efisiensi dan biaya energi jangka panjang. Dengan arsitektur yang tepat, agen RL juga dapat menggeneralisasi strategi yang dipelajari di seluruh tugas yang serupa tetapi tidak identik.
Apa saja kasus penggunaan pembelajaran penguatan?
Pembelajaran penguatan (RL) dapat diterapkan pada berbagai kasus penggunaan dunia nyata. Berikut ini kami berikan beberapa contoh.
Personalisasi pemasaran
Dalam aplikasi seperti sistem rekomendasi, RL dapat menyesuaikan saran untuk pengguna individu berdasarkan interaksi mereka. Ini mengarah pada pengalaman yang lebih personal. Misalnya, aplikasi dapat menampilkan iklan kepada pengguna berdasarkan beberapa informasi demografis. Dengan setiap interaksi iklan, aplikasi mempelajari iklan mana yang akan ditampilkan kepada pengguna untuk mengoptimalkan penjualan produk.
Tantangan optimasi
Metode optimasi tradisional memecahkan masalah dengan mengevaluasi dan membandingkan solusi yang mungkin berdasarkan kriteria tertentu. Sebaliknya, RL memperkenalkan pembelajaran dari interaksi untuk menemukan solusi terbaik atau dekat dengan terbaik dari waktu ke waktu.
Misalnya, sistem pengoptimalan belanja cloud menggunakan RL untuk menyesuaikan dengan kebutuhan sumber daya yang berfluktuasi dan memilih jenis instans, jumlah, dan konfigurasi yang optimal. Itu membuat keputusan berdasarkan faktor-faktor seperti infrastruktur cloud saat ini dan yang tersedia, pengeluaran, dan pemanfaatan.
Prediksi keuangan
Dinamika pasar keuangan sangat kompleks, dengan sifat statistik yang berubah seiring waktu. Algoritma RL dapat mengoptimalkan pengembalian jangka panjang dengan mempertimbangkan biaya transaksi dan beradaptasi dengan perubahan pasar.
Misalnya, algoritma dapat mengamati aturan dan pola pasar saham sebelum menguji tindakan dan mencatat imbalan terkait. Ini secara dinamis menciptakan fungsi nilai dan mengembangkan strategi untuk memaksimalkan keuntungan.
Bagaimana cara kerja pembelajaran penguatan?
Proses pembelajaran algoritma pembelajaran penguatan (RL) mirip dengan pembelajaran penguatan hewan dan manusia dalam bidang psikologi perilaku. Misalnya, seorang anak mungkin paham bahwa ia akan menerima pujian dari orang tua ketika membantu kakaknya atau membersihkan rumah, tetapi ia akan menerima reaksi negatif ketika melempar mainan atau berteriak. Anak tersebut akan segera mempelajari kombinasi aktivitas apa yang menghasilkan hadiah akhir.
Algoritma RL meniru proses pembelajaran serupa. Algoritma ini mencoba berbagai aktivitas untuk mempelajari nilai-nilai negatif dan positif terkait untuk mencapai hasil hadiah akhir.
Konsep inti
Dalam pembelajaran penguatan, terdapat beberapa konsep kunci yang perlu Anda kenal:
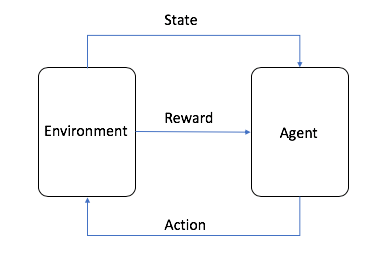
- Agen adalah algoritma ML (atau sistem otonom)
- Lingkungan adalah ruang masalah adaptif dengan atribut seperti variabel, nilai batas, aturan, dan tindakan yang valid
- Tindakan adalah langkah yang diambil agen RL untuk menavigasi lingkungan
- Keadaanadalah lingkungan pada titik waktu tertentu
- Hadiah adalah nilai positif, negatif, atau nol—dengan kata lain, hadiah atau hukuman—karena melakukan suatu tindakan
- Hadiah kumulatif adalah jumlah dari semua hadiah atau nilai akhir
Dasar-dasar algoritma
Pembelajaran penguatan didasarkan pada proses keputusan Markov, sebuah pemodelan matematika untuk pengambilan keputusan yang menggunakan langkah waktu diskret. Pada setiap langkah, agen melakukan tindakan baru yang menghasilkan keadaan lingkungan baru. Demikian pula, keadaan saat ini dikaitkan dengan urutan tindakan sebelumnya.
Melalui percobaan dan kegagalan saat bergerak di sekitar lingkungan, agen membangun seperangkat aturan atau kebijakan jika-maka. Kebijakan tersebut membantunya memutuskan tindakan yang perlu dilakukan selanjutnya untuk mendapatkan hadiah kumulatif yang optimal. Agen juga harus memilih antara eksplorasi lingkungan lebih lanjut untuk mengetahui hadiah dari tindakan-keadaan baru atau memilih tindakan dengan hadiah tinggi dari keadaan tertentu yang sudah diketahui. Hal ini disebut dengan tarik ulur eksplorasi-eksploitasi.
Apa saja jenis algoritma pembelajaran penguatan?
Ada berbagai algoritma yang digunakan dalam pembelajaran penguatan (RL)—seperti Q-learning, metode gradien kebijakan, metode Monte Carlo, dan pembelajaran perbedaan temporal. Deep RL adalah aplikasi jaringan neural dalam untuk pembelajaran penguatan. Salah satu contoh algoritma RL mendalam adalah Trust Region Policy Optimization (TRPO).
Semua algoritma ini dapat dikelompokkan menjadi dua kategori besar.
RL berbasis model
RL berbasis model biasanya digunakan ketika lingkungan didefinisikan dengan baik dan tidak berubah dan di mana pengujian lingkungan dunia nyata sulit dilakukan.
Agen pertama-tama membangun representasi internal (model) lingkungan. Ini menggunakan proses ini untuk membangun model ini:
- Dibutuhkan tindakan dalam lingkungan dan mencatat status baru dan nilai hadiah
- Ini mengaitkan transisi tindakan-tindakan dengan nilai hadiah.
Setelah model selesai, agen menyimulasikan urutan tindakan berdasarkan probabilitas imbalan kumulatif yang optimal. Kemudian selanjutnya memberikan nilai pada urutan tindakan itu sendiri. Agen dengan demikian mengembangkan strategi yang berbeda dalam lingkungan untuk mencapai tujuan akhir yang diinginkan.
Contoh
Pertimbangkan robot yang belajar menavigasi gedung baru untuk mencapai ruangan tertentu. Awalnya, robot mengeksplorasi dengan bebas dan membangun model internal (atau peta) bangunan. Misalnya, ia mungkin belajar bahwa ia menemukan lift setelah bergerak maju 10 meter dari pintu masuk utama. Setelah membangun peta, ia dapat membangun serangkaian urutan jalur terpendek antara berbagai lokasi yang sering dikunjungi di gedung.
RL bebas model
RL bebas model paling baik digunakan ketika lingkungannya besar, kompleks, dan tidak mudah dijelaskan. Ini juga ideal ketika lingkungan tidak diketahui dan berubah, dan pengujian berbasis lingkungan tidak datang dengan kerugian yang signifikan.
Agen tidak membangun model internal lingkungan dan dinamikanya. Sebaliknya, ia menggunakan pendekatan coba-coba dalam lingkungan. Ini menilai dan mencatat pasangan tindakan-negara—dan urutan pasangan tindakan negara—untuk mengembangkan kebijakan.
Contoh
Pertimbangkan mobil otonom yang perlu menavigasi lalu lintas kota. Jalan, pola lalu lintas, perilaku pejalan kaki, dan faktor lain yang tak terhitung jumlahnya dapat membuat lingkungan menjadi sangat dinamis dan kompleks. Tim AI melatih kendaraan di lingkungan simulasi pada tahap awal. Kendaraan mengambil tindakan berdasarkan keadaannya saat ini dan menerima hadiah atau penalti.
Seiring waktu, dengan mengemudi jutaan mil dalam skenario virtual yang berbeda, kendaraan mempelajari tindakan mana yang terbaik untuk setiap negara bagian tanpa secara eksplisit memodelkan seluruh dinamika lalu lintas. Ketika diperkenalkan di dunia nyata, kendaraan menggunakan kebijakan yang dipelajari tetapi terus menyempurnakannya dengan data baru.
Apa perbedaan antara machine learning yang dikuatkan yang diawasi dan tanpa pengawasan?
Sementara pembelajaran yang diawasi, pembelajaran tanpa pengawasan, dan pembelajaran penguatan (RL) adalah semua algoritma ML di bidang AI, ada perbedaan di antara ketiganya.
Baca tentang pembelajaran tanpa pengawasan dan yang diawasi »
Pembelajaran penguatan vs. pembelajaran yang diawasi
Dalam pembelajaran yang diawasi, Anda menentukan input dan output terkait yang diharapkan. Misalnya, Anda dapat memberikan satu set gambar berlabel kucing atau kucing, dan algoritma tersebut kemudian diharapkan untuk mengidentifikasi gambar hewan baru sebagai kucing atau kucing.
Algoritma pembelajaran yang diawasi mempelajari pola dan hubungan antara pasangan input dan output. Kemudian, Algoritma tersebut memprediksi hasil berdasarkan data input baru. Ini membutuhkan supervisor, biasanya manusia, untuk memberi label setiap catatan data dalam kumpulan data pelatihan dengan output.
Sebaliknya, RL memiliki tujuan akhir yang terdefinisi dengan baik dalam bentuk hasil yang diinginkan tetapi tidak ada pengawas untuk memberi label data terkait terlebih dahulu. Selama pelatihan, alih-alih mencoba memetakan input dengan output yang diketahui, ia memetakan input dengan hasil yang mungkin. Dengan menghargai perilaku yang diinginkan, Anda memberi bobot pada hasil terbaik.
Pembelajaran penguatan vs. pembelajaran tanpa pengawasan
Algoritma pembelajaran tanpa pengawasan menerima input tanpa output yang ditentukan selama proses pelatihan. Mereka menemukan pola dan hubungan tersembunyi dalam data menggunakan sarana statistik. Misalnya, Anda dapat menyediakan satu set dokumen, dan algoritma dapat mengelompokkannya ke dalam kategori yang diidentifikasi berdasarkan kata-kata dalam teks. Anda tidak mendapatkan hasil tertentu; hasil keluar dalam kisaran.
Sebaliknya, RL memiliki tujuan akhir yang telah ditentukan. Meskipun dibutuhkan pendekatan eksplorasi, eksplorasi terus divalidasi dan ditingkatkan untuk meningkatkan kemungkinan mencapai tujuan akhir. Ia dapat mengajar dirinya sendiri untuk mencapai hasil yang sangat spesifik.
Apa tantangan dengan pembelajaran penguatan?
Sementara aplikasi pembelajaran penguatan (RL) berpotensi mengubah dunia, mungkin tidak mudah untuk menerapkan algoritma ini.
Kepraktisan
Bereksperimen dengan sistem penghargaan dan hukuman dunia nyata mungkin tidak praktis. Misalnya, menguji drone di dunia nyata tanpa pengujian di simulator terlebih dahulu akan menyebabkan sejumlah besar pesawat rusak. Lingkungan dunia nyata sering berubah, secara signifikan, dan dengan peringatan terbatas. Hal ini dapat membuat lebih sulit bagi algoritma untuk menjadi efektif dalam praktik.
Interpretabilitas
Seperti bidang sains lainnya, ilmu data juga melihat penelitian dan temuan konklusif untuk menetapkan standar dan prosedur. Ilmuwan data lebih suka mengetahui bagaimana kesimpulan spesifik dicapai untuk provabilitas dan replikasi.
Dengan algoritma RL yang kompleks, alasan mengapa urutan langkah tertentu diambil mungkin sulit untuk dipastikan. Tindakan apa dalam urutan yang mengarah pada hasil akhir yang optimal? Ini bisa sulit untuk disimpulkan, yang menyebabkan tantangan implementasi.
Bagaimana AWS dapat membantu pembelajaran penguatan?
Amazon Web Services (AWS) memiliki banyak penawaran yang membantu Anda mengembangkan, melatih, dan menerapkan algoritma pembelajaran penguatan (RL) untuk aplikasi dunia nyata.
Dengan Amazon SageMaker, pengembang dan ilmuwan data dapat dengan cepat dan mudah mengembangkan model RL yang dapat diskalakan. Gabungkan kerangka kerja deep learning (seperti TensorFlow atau Apache MXNet), kit alat RL (seperti RL Coach atau RLlib), dan lingkungan untuk menyerupai skenario dunia nyata. Anda dapat menggunakannya untuk membuat dan menguji model Anda.
Dengan AWS RoboMaker, pengembang dapat menjalankan, menskalakan, dan mengotomatiskan simulasi dengan algoritma RL untuk robotika tanpa persyaratan infrastruktur apa pun.
Dapatkan pengalaman langsung dengan AWS DeepRacer, mobil balap skala 1/18 yang sepenuhnya otonom. Ini menawarkan lingkungan cloud yang sepenuhnya dikonfigurasi yang dapat Anda gunakan untuk melatih model RL dan konfigurasi jaringan neural Anda.
Mulailah pembelajaran penguatan di AWS dengan membuat akun hari ini.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages