Cos'è una pipeline dei dati?
Cos'è una pipeline dei dati?
Una pipeline di dati è una serie di fasi di elaborazione per preparare i dati aziendali all'analisi. Le organizzazioni dispongono di un grande volume di dati provenienti da varie fonti come applicazioni, dispositivi Internet of Things (IoT) e altri canali digitali. Tuttavia, i dati grezzi sono inutili; devono essere spostati, ordinati, filtrati, riformattati e analizzati per la business intelligence. Una pipeline di dati comprende varie tecnologie per verificare, riassumere e trovare modelli nei dati per prendere decisioni aziendali informate. Pipeline dei dati ben organizzate supportano diversi progetti di big data, come visualizzazioni di dati, analisi esplorative di dati e attività di machine learning.
Quali sono i vantaggi di una pipeline di dati?
Le pipeline di dati consentono di integrare dati da diverse origini e di trasformarli per l'analisi. Rimuovono i silo di dati e rendono l'analisi dei dati più affidabile e precisa. Ecco alcuni vantaggi chiave di una pipeline di dati.
Migliore qualità dei dati
Le pipeline di dati puliscono e affinano i dati grezzi, migliorandone l'utilità per gli utenti finali. Standardizzano i formati dei campi come le date e i numeri di telefono e controllano gli errori di inserimento. Inoltre, eliminano la ridondanza e garantiscono una qualità dei dati coerente in tutta l'organizzazione.
Elaborazione efficiente dei dati
Gli ingegneri dei dati devono eseguire molte operazioni ripetitive durante la trasformazione e il caricamento dei dati. Le pipeline di dati consentono di automatizzare le attività di trasformazione dei dati e di concentrarsi invece sulla ricerca delle migliori informazioni dettagliate aziendali. Le pipeline di dati aiutano inoltre gli ingegneri dei dati a elaborare più rapidamente i dati grezzi che perdono valore nel tempo.
Integrazione completa dei dati
Una pipeline di dati astrae le funzioni di trasformazione dei dati per integrare i set di dati provenienti da origini diverse. È in grado di effettuare un controllo incrociato dei valori degli stessi dati provenienti da più origini e di risolvere le incongruenze. Ad esempio, immaginiamo che lo stesso cliente effettui un acquisto dalla tua piattaforma di e-commerce e dal tuo servizio digitale. Tuttavia, nel servizio digitale il suo nome viene scritto in modo errato. La pipeline può correggere questa incongruenza prima di inviare i dati per l'analisi.
Come funziona una pipeline di dati?
Proprio come una conduttura idrica sposta l'acqua dal bacino idrico ai rubinetti, una pipeline di dati sposta i dati dal punto di raccolta all'archiviazione. Una pipeline di dati estrae i dati da un'origine, apporta modifiche e li salva in una destinazione specifica. Di seguito illustriamo i componenti critici dell'architettura della pipeline di dati.
Origini dati
Un'origine dati può essere un'applicazione, un dispositivo o un altro database. Diverse origini possono inviare i dati nella pipeline. La pipeline può anche estrarre punti di dati tramite una chiamata API, un webhook o un processo di duplicazione dei dati. Puoi sincronizzare l'estrazione dei dati per l'elaborazione in tempo reale o raccogliere i dati a intervalli programmati dalle origini dati.
Trasformazioni
Man mano che i dati grezzi passano attraverso la pipeline, si modificano per diventare più utili per la business intelligence. Le trasformazioni sono operazioni, come l'ordinamento, la riformattazione, la deduplicazione, la verifica e la convalida, che modificano i dati. La pipeline può filtrare, riassumere o elaborare i dati per soddisfare i requisiti di analisi.
Dipendenze
Poiché le modifiche avvengono in sequenza, possono esistere dipendenze specifiche che riducono la velocità di trasferimento dei dati nella pipeline. Esistono due tipi principali di dipendenze: tecniche e aziendali. Ad esempio, se la pipeline deve attendere che una coda centrale si riempia prima di procedere, si tratta di una dipendenza tecnica. Al contrario, se la pipeline deve fermarsi in attesa della verifica incrociata dei dati da parte di un'altra unità aziendale, si tratta di una dipendenza aziendale.
Destinazioni
L'endpoint della pipeline di dati può essere un data warehouse, un data lake o un'altra applicazione di business intelligence o di analisi dei dati. A volte la destinazione è anche chiamata data sink.
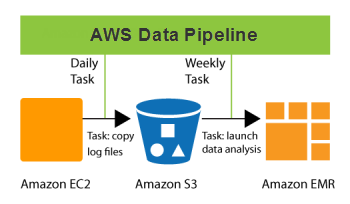
Quali sono le tipologie di pipeline di dati?
Esistono due tipi principali di pipeline di dati: pipeline per l'elaborazione di flussi e pipeline per l'elaborazione in batch.
Pipeline di elaborazione di flussi
Un flusso di dati è una sequenza continua e incrementale di pacchetti di dati di piccole dimensioni. In genere rappresenta una serie di eventi che si verificano in un determinato periodo. Ad esempio, un flusso di dati può mostrare dati dei sensori che contengono misurazioni dell'ultima ora. Una singola azione, come una transazione finanziaria, può anche essere chiamata evento. Le pipeline di streaming elaborano una serie di eventi per l'analisi in tempo reale.
I dati in streaming richiedono una bassa latenza e un'elevata tolleranza ai guasti. La tua pipeline di dati deve poter elaborare i dati anche se alcuni pacchetti di dati vengono persi o arrivano in un ordine diverso da quello previsto.
Pipeline di elaborazione in batch
Le pipeline di dati di elaborazione in batch elaborano e archiviano i dati in grandi volumi o batch. Sono adatte per attività occasionali ad alto volume, come la contabilità mensile.
La pipeline di dati contiene una serie di comandi in sequenza e ogni comando viene eseguito sull'intero batch di dati. La pipeline di dati fornisce l'output di un comando come input per il comando successivo. Una volta completate tutte le trasformazioni dei dati, la pipeline carica l'intero batch in un data warehouse nel cloud o in un altro datastore simile.
Ulteriori informazioni sull'elaborazione in batch »
Differenza tra pipeline di dati in batch e in streaming
Le pipeline di elaborazione in batch vengono eseguite di rado e in genere nelle ore non di punta. Richiedono un'elevata potenza di calcolo per un breve periodo di funzionamento. Al contrario, le pipeline di elaborazione di flussi funzionano in modo continuo, ma richiedono una bassa potenza di calcolo. Hanno invece bisogno di connessioni di rete affidabili e a bassa latenza.
Qual è la differenza tra le pipeline di dati e le pipeline ETL?
Una pipeline di estrazione, trasformazione e caricamento (ETL) è una speciale tipologia di pipeline. Gli strumenti ETL estraggono o copiano dati non elaborati provenienti da più origini e li archiviano in una posizione temporanea chiamata area di staging. Trasformano i dati nell'area di staging e li caricano nei data lake o warehouse.
Non tutte le pipeline di dati seguono la sequenza ETL. Alcuni possono estrarre i dati da un'origine e caricarli altrove senza alcuna trasformazione. Altre pipeline di dati seguono una sequenza di estrazione, caricamento e trasformazione (ETL) in cui estraggono e caricano i dati non strutturati direttamente in un data lake. Eseguono le modifiche dopo aver trasferito le informazioni su data warehouse su cloud.
In che modo AWS può supportare i tuoi requisiti di pipeline dei dati?
AWS Glue è un servizio di integrazione dei dati senza server che semplifica agli utenti di analisi la scoperta, la preparazione, lo spostamento e l'integrazione di dati provenienti da più fonti per l'analisi, l'apprendimento automatico e lo sviluppo di applicazioni.
- È possibile scoprire e connettersi a oltre 80 diversi datastore.
- Puoi gestire i tuoi dati in un catalogo dati centralizzato.
- Ingegneri dei dati, sviluppatori ETL, analisti di dati e utenti aziendali possono utilizzare AWS Glue Studio per creare, eseguire e monitorare le pipeline ETL per caricare i dati nei data lake.
- AWS Glue Studio offre interfacce Visual ETL, Notebook ed editor di codice, in modo che gli utenti dispongano di strumenti adeguati alle proprie competenze.
- Con Interactive Sessions, gli ingegneri dei dati possono esplorare i dati e creare e testare lavori utilizzando il loro IDE o notebook preferito.
- AWS Glue è serverless e scala automaticamente su richiesta, in modo che sia possibile concentrarsi sull'acquisizione di informazioni da dati su scala petabyte, senza gestire l'infrastruttura.
Inizia a usare AWS Glue creando un account AWS.
Fasi successive della pipeline dei dati
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages