Cosa si intende per MLOps?
Cosa si intende per MLOps?
Le operazioni di machine learning (MLOps) sono un insieme di pratiche che automatizzano e semplificano i flussi di lavoro e le implementazioni di machine learning (ML). Il machine learning e l'intelligenza artificiale (IA) sono funzionalità fondamentali che puoi implementare per risolvere problemi complessi del mondo reale e offrire valore ai tuoi clienti. Il MLOps è una cultura e una pratica di machine learning che unifica lo sviluppo (Dev) di applicazioni di ML con l'implementazione e le operazioni (Ops) del sistema di ML. L'organizzazione può utilizzare il MLOps per automatizzare e standardizzare i processi durante il ciclo di vita del ML. Questi processi includono lo sviluppo del modello, il test, l'integrazione, il rilascio e la gestione dell'infrastruttura.
Perché il MLOps è necessario?
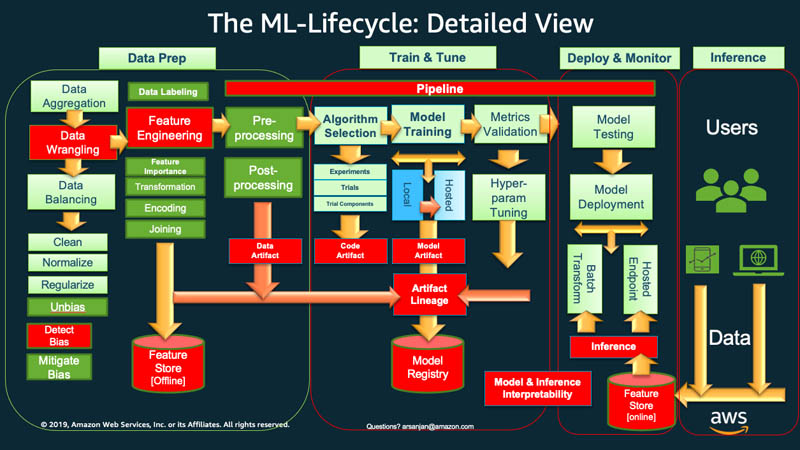
Ad alto livello, per intraprendere il ciclo di vita del machine learning, l'organizzazione deve in genere iniziare con la preparazione dei dati. Vengono recuperati dati di diversi tipi da varie origini e vengono eseguite attività come aggregazione, pulizia dei duplicati e ingegneria delle funzionalità.
Successivamente, i dati vengono utilizzati per addestrare e convalidare il modello di ML. È quindi possibile implementare il modello addestrato e convalidato come servizio di previsione al quale altre applicazioni possono accedere tramite API.
L'analisi esplorativa dei dati spesso richiede di sperimentare modelli differenti, fino a quando la versione migliore del modello non è pronta per l'implementazione. Porta a implementazioni delle versioni del modello e a rilasci di versioni dei dati frequenti. Il monitoraggio degli esperimenti e la gestione della pipeline di addestramento del ML sono fasi essenziali prima che le applicazioni possano integrare o utilizzare il modello nel loro codice.
Il MLOps è fondamentale per gestire in modo sistematico e simultaneo il rilascio di nuovi modelli di ML con modifiche al codice dell'applicazione e ai dati. Un'implementazione MLOps ottimale tratta le risorse di ML in modo simile ad altre risorse software dell'ambiente di integrazione e distribuzione continua (CI/CD). I modelli di ML vengono implementati insieme alle applicazioni e ai servizi che utilizzano e a quelli che se ne avvalgono come parte di un processo di rilascio unificato.
Quali sono i principi del MLOps?
Di seguito, affrontiamo quattro principi fondamentali del MLOps.
Controllo delle versioni
Questo processo prevede il monitoraggio delle modifiche nelle risorse di machine learning in modo da poter riprodurre i risultati e ripristinare le versioni precedenti, se necessario. Ogni specifica di modello o codice di addestramento di ML passa attraverso una fase di revisione del codice. Ciascuna è dotata di versioni per rendere riproducibile e verificabile l'addestramento dei modelli di ML.
La riproducibilità in un flusso di lavoro di ML è importante in ogni fase, dall'elaborazione dei dati all'implementazione del modello di ML. Significa che ogni fase dovrebbe produrre risultati identici a fronte dello stesso input.
Automazione
È possibile automatizzare varie fasi della pipeline di machine learning per garantire ripetibilità, coerenza e scalabilità. Ciò include le fasi dall'importazione dei dati, la pre-elaborazione, l'addestramento dei modelli e la convalida fino all'implementazione.
Questi sono alcuni dei fattori che possono innescare l'addestramento e l'implementazione automatizzati dei modelli:
- Messaggistica
- Monitoraggio degli eventi del calendario
- Modifiche ai dati
- Modifiche al codice di addestramento del modello
- Modifiche al codice dell'applicazione.
I test automatici consentono di individuare tempestivamente i problemi per correggere rapidamente gli errori e innescare l'apprendimento. L'automazione è più efficiente con l'infrastruttura come codice (IaC). È possibile utilizzare strumenti per definire e gestire l'infrastruttura. Questo contribuisce a garantire che sia riproducibile e possa essere implementato in modo coerente in vari ambienti.
Ottieni maggiori informazioni sul'IaC »
X continuo
Attraverso l'automazione, è possibile eseguire test e implementare codice in modo continuo nella pipeline di ML.
Nel MLOps, l'aggettivo continuo si riferisce a quattro attività che si verificano continuamente se viene apportata una modifica in qualsiasi parte del sistema:
- L'integrazione continua estende la convalida e il test del codice ai dati e ai modelli nella pipeline
- La distribuzione continua implementa automaticamente il modello o il servizio di previsione del modello appena addestrati
- L'addestramento continuo riaddestra automaticamente i modelli di ML per la reimplementazione
- Il monitoraggio continuo riguarda il monitoraggio dei dati e il monitoraggio dei modelli utilizzando metriche relative al business
Modello di governance
La governance implica la gestione di tutti gli aspetti dei sistemi di ML per garantirne l'efficienza. La governance richiede l'esecuzione di numerose attività:
- Promuovere una stretta collaborazione tra data scientist, ingegneri e stakeholder aziendali
- Utilizzare una documentazione chiara e canali di comunicazione efficaci per garantire che tutti siano allineati
- Stabilire meccanismi per raccogliere feedback sulle previsioni dei modelli e riaddestrare ulteriormente i modelli
- Garantire la protezione dei dati sensibili, l'accesso ai modelli e all'infrastruttura sicuro e il rispetto dei requisiti di conformità
Inoltre, è essenziale disporre di un processo strutturato per rivedere, convalidare e approvare i modelli prima che vengano pubblicati. Ciò può comportare la verifica dell'equità, dei pregiudizi e delle considerazioni etiche.
Quali sono i vantaggi del MLOps?
Il machine learning aiuta le organizzazioni ad analizzare i dati e ricavare informazioni per il processo decisionale. Tuttavia, è un campo innovativo e sperimentale che presenta una serie di sfide. La protezione dei dati sensibili, i budget limitati, la carenza di competenze e la tecnologia in continua evoluzione possono limitare il successo di un progetto. Senza controllo e guida, i costi rischiano di aumentare vertiginosamente e i team di data science potrebbero non raggiungere i risultati desiderati.
Il MLOps fornisce una mappa per indirizzare i progetti di ML verso il successo, indipendentemente dai vincoli. Ecco alcuni vantaggi principali del MLOps.
Riduzione del time-to-market
Il MLOps fornisce all'organizzazione un framework per raggiungere gli obiettivi di data science in modo più rapido ed efficiente. Gli sviluppatori e i manager possono gestire i modelli in modo più agile e strategico. Gli ingegneri ML possono fornire l'infrastruttura tramite file di configurazione dichiarativi che consentono di avviare i progetti in modo più fluido.
L'automazione della creazione e dell'implementazione dei modelli si traduce in tempi di immissione sul mercato più rapidi e in costi operativi inferiori. I data scientist possono esplorare rapidamente i dati di un'organizzazione per offrire un maggiore valore aziendale a tutti.
Produttività migliorata
Le pratiche MLOps aumentano la produttività e accelerano lo sviluppo di modelli di ML. Ad esempio, è possibile standardizzare l'ambiente di sviluppo o di sperimentazione. Dopodiché, gli ingegneri ML possono avviare nuovi progetti, passare da un progetto all'altro e riutilizzare i modelli di ML tra le applicazioni. Possono creare processi ripetibili per la sperimentazione rapida e l'addestramento dei modelli. I team di progettazione del software possono collaborare e coordinarsi durante il ciclo di vita di sviluppo del software ML per conseguire una maggiore efficienza.
Implementazione efficiente del modello
Il MLOps migliora la risoluzione dei problemi e la gestione dei modelli in produzione. Ad esempio, gli ingegneri del software possono monitorare le prestazioni del modello e riprodurne il comportamento per la risoluzione dei problemi. Possono tracciare e gestire centralmente le versioni dei modelli e scegliere quella giusta per i diversi casi d'uso aziendali.
Quando si integrano i flussi di lavoro dei modelli con le pipeline di integrazione continua e distribuzione continua (CI/CD), si limita il degrado delle prestazioni e si mantiene la qualità del modello. Questo resta valido anche dopo gli aggiornamenti e la messa a punto del modello.
Come implementare il MLOps nell'organizzazione
Esistono tre livelli di implementazione del MLOps, a seconda della maturità dell'automazione all'interno dell'organizzazione.
MLOps di livello 0
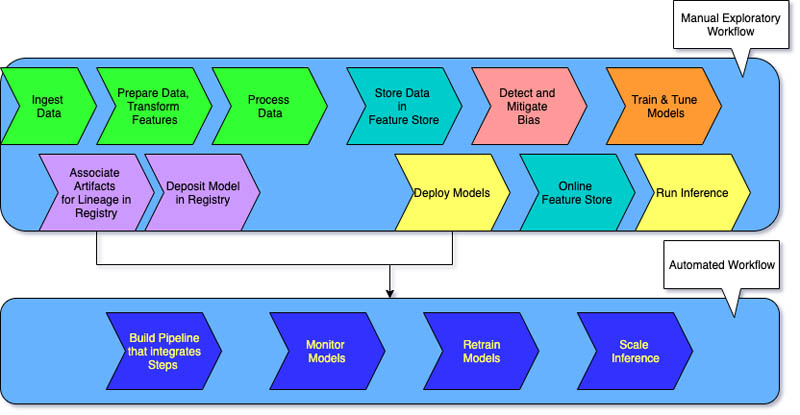
I flussi di lavoro di ML manuali e un processo guidato dai data scientist caratterizzano il livello 0 per le organizzazioni che stanno muovendo i primi passi con i sistemi di machine learning.
Ogni fase è manuale, inclusa la preparazione dei dati, l'addestramento del ML e le prestazioni e la convalida dei modelli. Richiede una transizione manuale tra i passaggi e ogni passaggio viene eseguito e gestito in modo interattivo. I data scientist in genere consegnano modelli addestrati sotto forma di artefatti che il team di ingegneri implementano sull'infrastruttura API.
Il processo separa i data scientist che creano il modello e gli ingegneri che lo implementano. A causa dei rilasci poco frequenti, i team di data science possono avere la possibilità di riaddestrare i modelli solo in poche occasioni durante l'anno. Non sussistono considerazioni del tipo CI/CD per i modelli di ML con il restante codice dell'applicazione. Allo stesso modo, il monitoraggio attivo delle prestazioni è inesistente.
MLOps di livello 1
Le organizzazioni che desiderano addestrare gli stessi modelli con nuovi dati spesso richiedono un'implementazione di maturità di livello 1. Il livello 1 del MLOps mira ad addestrare il modello in modo continuo automatizzando la pipeline di ML.
Nel livello 0, si implementa un modello addestrato in produzione. Al contrario, nel livello 1 si implementa una pipeline di addestramento che viene eseguita in modo ricorrente per fornire il modello addestrato alle altre applicazioni. Come minimo, si ottiene la fornitura continua del servizio di previsione del modello.
La maturità di livello 1 presenta le seguenti caratteristiche:
- Fasi rapide di sperimentazione del ML che comportano una notevole automazione
- Addestramento continuo del modello in produzione con nuovi dati come trigger della pipeline in tempo reale
- Implementazione della stessa pipeline in ambienti di sviluppo, pre-produzione e produzione
I team di progettazione collaborano con i data scientist per creare componenti di codice modulari riutilizzabili, componibili e potenzialmente condivisibili tra le pipeline di ML. Inoltre, è possibile creare un archivio funzionalità centralizzato che standardizza l'archiviazione, l'accesso e la definizione delle funzionalità per l'addestramento e l'erogazione del ML. Inoltre, è possibile gestire i metadati, come le informazioni su ciascuna esecuzione della pipeline e i dati di riproducibilità.
MLOps di livello 2
Il MLOps di livello 2 è pensato per le organizzazioni che vogliono sperimentare di più e creare spesso nuovi modelli che richiedono un addestramento continuo. È adatto alle aziende tecnologiche che aggiornano i propri modelli in pochi minuti, li riaddestrano a cadenza oraria o quotidiana e contemporaneamente li reimplementano su migliaia di server.
Poiché sono in gioco diverse pipeline di ML, una configurazione MLOps di livello 2 richiede tutte le configurazioni del MLOps di livello 1. Richiede inoltre quanto segue:
- Un orchestratore di pipeline di ML
- Un registro dei modelli per tracciare più modelli
Le tre fasi seguenti si ripetono su larga scala per diverse pipeline di ML per garantire la distribuzione continua del modello.
Creazione della pipeline
Vengono testate in modo iterativo nuove modellazioni e nuovi algoritmi di ML, e al contempo ci si assicura dell'orchestrazione delle fasi dell'esperimento. Questa fase produce il codice sorgente per le pipeline di ML. Il codice viene archiviato in un repository delle sorgenti.
Implementazione della pipeline
Successivamente, si crea il codice sorgente e si eseguono test per ottenere i componenti della pipeline ai fini dell'implementazione. L'output è una pipeline implementata con l'implementazione del nuovo modello.
Erogazione della pipeline
Infine, la pipeline viene erogata come servizio di previsione per le applicazioni. Le statistiche sul servizio di previsione del modello implementato vengono raccolte dai dati in tempo reale. L'output di questa fase è un trigger che innesca l'esecuzione della pipeline o un nuovo ciclo di esperimenti.
Qual è la differenza tra MLOps e DevOps?
MLOps e DevOps sono due pratiche che mirano a migliorare i processi di sviluppo, implementazione e monitoraggio delle applicazioni software.
Il DevOps mira a colmare il divario tra i team di sviluppo e operativi. Il DevOps aiuta a garantire che le modifiche al codice vengano automaticamente testate, integrate e implementate nella produzione in modo efficiente e affidabile. Promuove una cultura della collaborazione per ottenere cicli di rilascio più rapidi, una migliore qualità delle applicazioni e un uso più efficiente delle risorse.
Il MLOps, d'altra parte, è un insieme di best practice progettate specificamente per i progetti di machine learning. Mentre implementare e integrare il software tradizionale può essere relativamente semplice, i modelli di ML presentano sfide uniche. Questi contemplano la raccolta dei dati, l'addestramento dei modelli, la convalida, l'implementazione e il monitoraggio e il riaddestramento continui.
Il MLOps si concentra sull'automazione del ciclo di vita del ML. Aiuta a garantire che i modelli non vengano soltanto sviluppati, ma anche implementati, monitorati e riaddestrati in modo sistematico e ripetuto. Trasmette i principi del DevOps nel ML. Il MLOps si traduce in un'implementazione più rapida dei modelli di ML, in una migliore precisione nel tempo e in una maggiore garanzia che i modelli forniscano un valore aziendale reale.
In che modo AWS può supportare i requisiti MLOps?
Amazon SageMaker è un servizio completamente gestito che puoi utilizzare per preparare dati e creare, addestrare e distribuire modelli ML. È adatto a qualsiasi caso d'uso con infrastruttura, strumenti e flussi di lavoro completamente gestiti.
SageMaker fornisce strumenti progettati appositamente per il MLOps per automatizzare i processi durante tutto il ciclo di vita del ML. Utilizzando gli strumenti Sagemaker for MLOps, è possibile raggiungere rapidamente la maturità MLOps di livello 2 su larga scala.
Ecco le funzionalità principali di SageMaker che è possibile utilizzare:
- Esperimenti SageMaker può essere utilizzato per tenere traccia degli artefatti relativi ai processi di addestramento dei modelli, come parametri, metriche e set di dati.
- È possibile configurare le pipeline di SageMaker in modo che vengano eseguite automaticamente a intervalli regolari o quando si verificano determinati eventi.
- Registro dei modelli SageMaker permette di tenere traccia delle versioni dei modelli. Consente di tenere traccia anche dei relativi metadati, come il raggruppamento dei casi d'uso, e delle linee di base delle metriche prestazionali dei modelli in un repository centrale. Queste informazioni possono essere utilizzate per scegliere il modello migliore in base alle proprie esigenze aziendali.
Inizia a usare MLOps su Amazon Web Services (AWS) creando un account oggi stesso.
Fasi successive su AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages