Amazon Web Services ブログ
Amazon Bedrock Knowledge BasesでSAPおよびエンタープライズデータから新たな可能性を解き放つ
はじめに
SAPシステムを運用している組織は、エンタープライズデータという金鉱の上に座っています。お客様とのやり取り、サプライチェーンオペレーション、財務取引、人事記録など、膨大な情報が蓄積されています。しかし、多くの企業がこの広大な情報リポジトリの潜在能力を十分に引き出すことに苦労しています。従来のウォーターフォールアプローチによるABAPプログラミングでは、シンプルなレポートを作成するだけでも最低1〜2週間かかり、シンプルなBWレポートの構築にはさらに長い時間(開発、テスト、デプロイで約4週間)がかかります。これにより、企業が課題や競争に対処するためのタイムリーな意思決定を行うことが妨げられていました。
生成AI(Generative AI)の力とエンタープライズデータインテリジェンスを組み合わせた新しいソリューションを見てみましょう。このソリューションは、企業がSAPおよびエンタープライズデータとやり取りし、そこから価値を引き出す方法を変革します。組織が競争優位性を獲得するために人工知能を活用しようとする中、Amazon Bedrock Knowledge BasesとSAPシステムおよび他のデータソースとの統合は、従来のエンタープライズデータ管理と最先端のAI機能の間のギャップを埋めるユニークな機会を提供します。この組み合わせにより、企業はデータにアクセスするだけでなく、それを理解し、そこから学び、これまで想像もできなかった方法で実用的なインサイトを生成できるようになります。
この記事では、Amazon Bedrock Knowledge Basesが組織のSAPおよびエンタープライズデータの活用方法をどのように革新し、イノベーション、効率性、戦略的意思決定のための新たな可能性を創出しているかを探ります。自然言語クエリから自動化されたドキュメント処理、インテリジェントなインサイト生成まで、このソリューションが企業のSAP投資をAI時代の戦略的資産に変革する方法をご紹介します。
統合データインテリジェンスの力
SAPおよびエンタープライズデータとBedrock Knowledge Basesを組み合わせることの真の力は、グローバル製造企業がサプライチェーンオペレーションを革新した事例を見ると明らかになります。不確実な市場状況(最近の関税戦争、極端な気象変動など)と進化するお客様の需要という課題に直面し、この企業は従来の予測手法を超えて、よりダイナミックでインテリジェントな在庫管理システムを構築しようとしました。
Bedrock Knowledge Basesを活用することで、この企業はSAP S/4HANAシステムと多様な外部データソースを橋渡しする統合データ基盤を構築しました。SAP環境は、過去の販売注文や在庫レベルから生産計画や購買履歴まで、豊富な運用データを提供しました。これは、ソーシャルメディアのセンチメント、気象パターン、競合他社の活動、より広範な経済指標などの外部シグナルとシームレスに統合されました。その結果、自然言語でクエリできる包括的なナレッジベースが生まれ、組織全体のビジネスユーザーが複雑なデータにアクセスできるようになりました。
その影響は変革的でした。調達マネージャーは、「来四半期に製品Xの需要に影響を与える要因は何か?」といった質問を単純に尋ねるだけで、過去のSAPデータパターンとリアルタイムの市場インテリジェンスを組み合わせたAI生成のインサイトを受け取ることができるようになりました。システムは、過去の販売トレンドや現在の在庫レベルから、ソーシャルメディアのセンチメントや今後の地域イベントまで、複数の要因を分析し、在庫調整のための微妙なニュアンスを含む推奨事項を提供しました。この包括的なアプローチにより、余剰在庫コストの削減、注文充足率の向上、需要予測の大幅な精度向上といった顕著な結果が得られました。
このユースケースは、Bedrock Knowledge Basesがデータへのアクセスだけでなく、これまで見えなかった実用的なインサイトを明らかにすることを示しています。SAPと非SAPデータソース間の障壁を取り除くことで、組織は今やエンタープライズデータの潜在能力を最大限に活用し、より情報に基づいた戦略的な意思決定を行うことができます。生成AIを通じて構造化データと非構造化データの両方を処理する能力は、ビジネスの最適化とイノベーションのための新たな可能性を開きます。
AWS生成AIサービスを活用した他の実際のお客様成功事例については、こちらのリンクをご覧ください。
SAPおよび非SAPデータ構造と一般的な課題の概要
組織は、SQL互換データベース、データウェアハウス、またはデータカタログに保存された大量の構造化データを保有しており、生成AIによるこれらのデータの取得にはText-to-SQL変換ステップが必要です。Bedrock Knowledge Basesの構造化データストアサポートにより、ユーザーは差別化されない重労働なしに、自然言語の会話インターフェースを通じてこれらのデータに簡単にアクセスできます。Bedrockは自然言語プロンプトを分析し、自動的にSQLを生成し、データを取得し、回答を生成します—すべてを1つのステップで実行します。
Amazon Bedrock Knowledge Baseの実装
実装の前提条件:
- クエリエンジンとして事前設定されたAmazon Redshift ServerlessまたはRedshift Provisioned Cluster。このブログでは完全なAWSマネージドサービスとしてRedshift Serverlessを使用しますが、SAPシステムから移動されるデータの頻度が高く定期的なワークロードのシナリオでは、Redshift Provisioned Clusterがコスト面でメリットを提供することが多いため、こちらも検討できます。
- SAPデータがAmazon S3上のData Lakehouseアーキテクチャ、またはRedshift Serverless、またはRedshift Provisioned Clusterに保存されていること。このデータ取り込みは、ソースがSAP S/4HANAの場合はAWS Glue for SAP ODataを使用して、ソースがSAP HANA Cloudの場合はAWS Glue for SAP HANAを使用して実行できます。SAP接続をサポートする他のISVツールも使用できます。
Bedrock Knowledge Baseを実装する際には、データソース統合、セキュリティ、スケーラビリティ、パフォーマンスなど、考慮すべき点がいくつかあります。以下は、アーキテクチャ図とこのソリューションを実装する際の考慮点です。
- データソース統合:
- 添付ファイル、作業マニュアル、パフォーマンスドキュメントなどの非構造化データで、データソースをベクトルストアKBに同期したい場合は、Amazon Bedrock Knowledge Baseを活用できます。
- テーブルなどの構造化データの場合は、Amazon Bedrock Knowledge Bases for Structured dataを使用でき、自然言語を使用して構造化データをクエリできます。
- セキュリティとコンプライアンス:
- SAPデータは、Amazon VPC内のプライベートネットワークで転送および保存する必要があります。SAPデータをAmazon S3上のData Lakehouseアーキテクチャに統合する際には、TLS暗号化などを使用した安全な接続が必要です。
- BedrockからRedshift、GlueからRedshift、GlueからSAPへのデータアクセシビリティのためのIAMロールを実装する際には、最小権限の原則を実装する必要があります。
- SAPシステムへのアクセスに使用される認証情報などの機密情報を保存するには、Secret Managerを使用します。
- Bedrock Guardrailsを使用して、生成AIアプリケーションを有害なコンテンツや望ましくないトピックから保護します。
- スケーラビリティとパフォーマンス:
- このアーキテクチャのすべてのサービスは、高可用性、高パフォーマンス、スケーラブルなAWSマネージドサービスであるため、ソリューションのサイジング、インストール、運用に関する重労働を行う必要はありません。
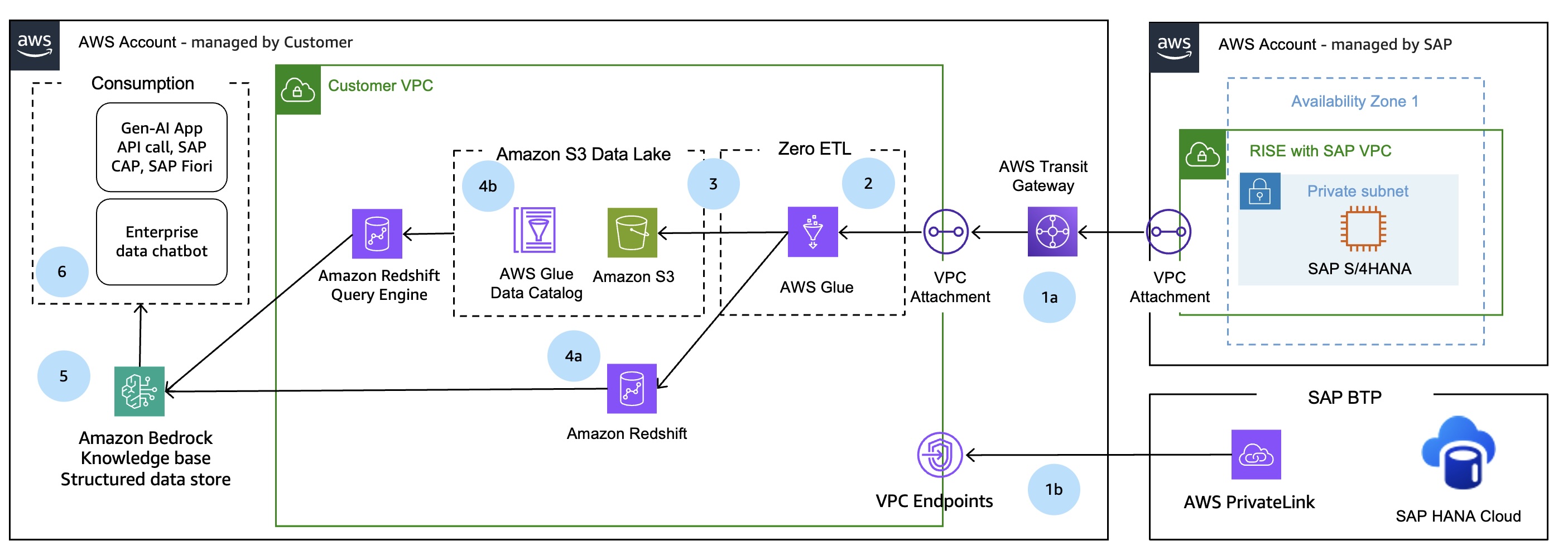
図1. 構造化SAPおよびエンタープライズデータのためのAmazon Bedrock Knowledge Basesアーキテクチャ
アーキテクチャの詳細
1. SAPシステムとAWS VPC間の安全な接続の確立
最初のステップとして、ソースSAPシステムからお客様のAWSアカウント内のVPCへの安全な接続を確立する必要があります。
1-a: データソースがSAP S/4HANAシステムの場合
RISE with SAP VPCは、VPC PeeringまたはAWS Transit Gatewayを通じてお客様管理VPCにプライベートに接続できます。詳細については、RISE with SAPの技術ドキュメントConnecting to RISE from your AWS accountを参照してください。この構成により、お客様管理VPC内で実行されるデータ取り込みジョブは、SAP S/4HANAと安全に通信します。
AWSアカウントで実行されるSAPシステムの場合、VPC PeeringまたはAWS Transit Gatewayによって複数のVPC間のプライベート接続を設定できます。
オンプレミスで実行されるSAPシステムの場合、S2S VPNまたはDirect Connectによって、独自のネットワークとAWS間のプライベート接続を確立できます。
1-b: データソースがSAP HANA Cloudの場合
SAP Private Link serviceを通じて、お客様管理VPCからSAP HANA Cloudインスタンスへのプライベート接続を確立できます。詳細な手順については、ブログSecure SAP HANA Cloud connectivity using AWS PrivateLinkを参照してください。
2. データ統合
Guidance for SAP Data Integration and Managementで説明されているように、SAPデータを抽出するオプションは多数あります。このブログでは、AWS Glue for SAP ODataを使用してSAP S/4HANAからデータを抽出します。この抽出プロセスは、Glue Zero-ETL統合またはGlue Visual ETLジョブを使用して実行できます。SAP HANA Cloudからデータを抽出する場合は、AWS Glue for SAP HANAを使用できます。
Glue Zero-ETLは、一般的な取り込みおよびレプリケーションのユースケースのためにETLデータパイプラインを構築する必要性を最小限に抑える、AWSによる完全マネージド統合のセットです。SAP ODataをソースとして読み取り、Amazon SageMaker LakehouseやAmazon Redshiftなどのターゲットにデータを書き込みます。
AWS Glue for SAP ODataの設定方法
ステップ2.1: SAP OData接続の作成
AWS Glue for SAP ODataを設定する詳細な手順については、このブログを参照してください。安全なデータ転送のために、SAP Odata接続がVPC内で設定されていることを確認してください。
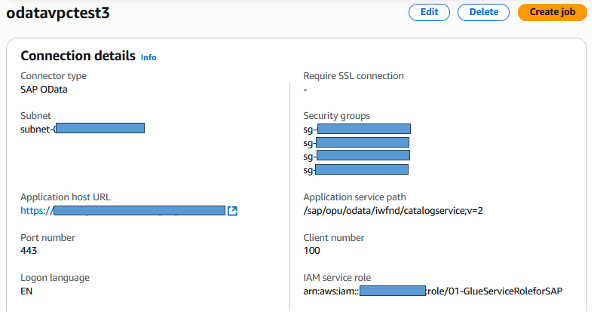
図2. VPC設定を使用したAWS Glue for SAP OData
ステップ2.2: Glue Zero-ETL統合のターゲット設定
Glueユーザーガイドを参照し、Zero-ETLターゲットAmazon Redshift Serverlessを設定します。このRedshiftターゲットは、Glue SAP OData接続と同じVPC内に配置する必要があります。
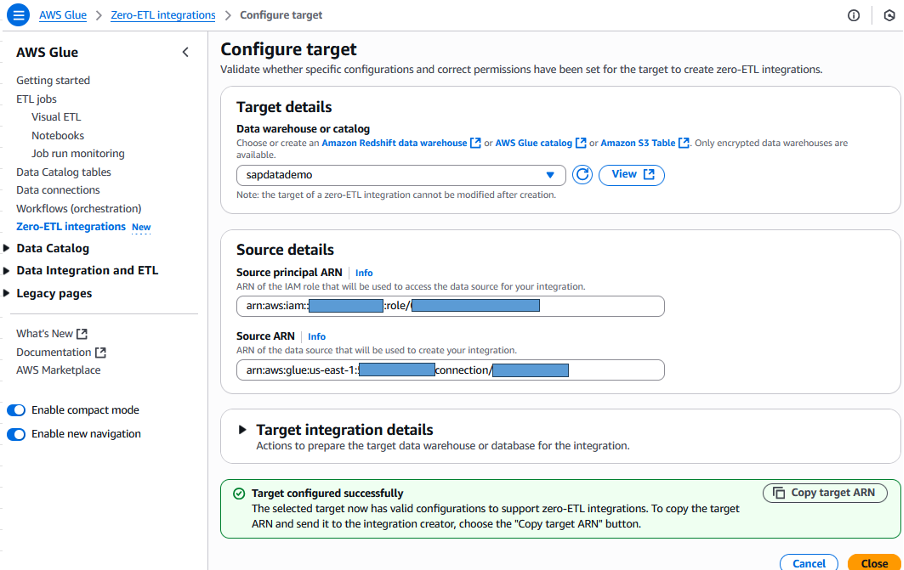
図3. Zero-ETLターゲットRedshift設定
ステップ2.3: GlueでZero-ETL統合を作成
Glueで、Zero-ETL integrationsを選択し、新しい統合を作成します。ソースとターゲットを選択するだけで、データはSAPからRedshift Serverlessにシームレスに統合されます。作成したGlue SAP OData接続と統合ジョブを実行するロールを選択します。
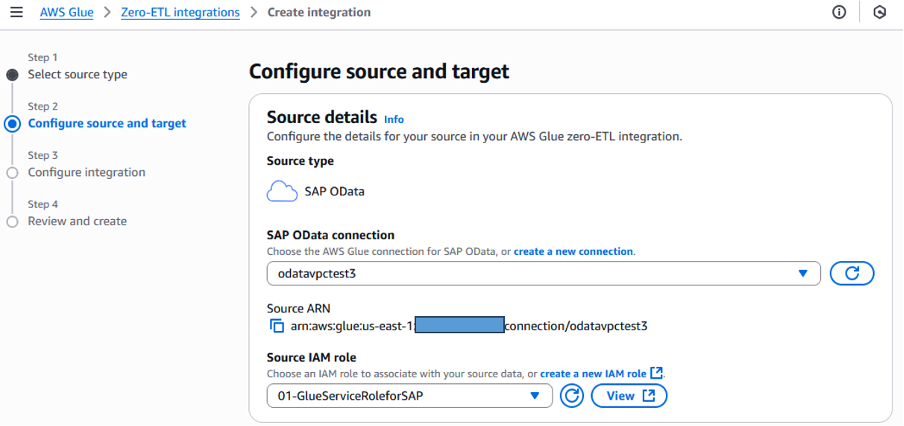
図4. Zero-ETLソースSAP OData接続
SAP S/4HANAシステム内のSAP ODataサービスのリストが取得され、選択用に表示されます。このブログでは、購買発注用の4つのSAP ODataサービスを選択しました。
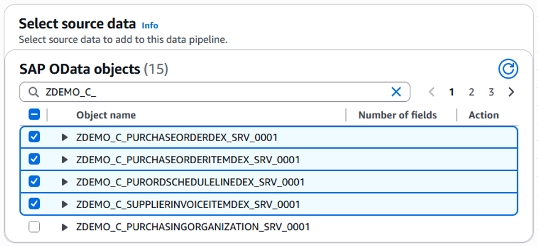
図5. SAPから購買発注ソースを選択
次はターゲットの選択です。現在、Glue Zero-ETLはターゲットとしてLakehouseまたはRedshiftをサポートしています。事前に作成したこのRedshift serverless名前空間のターゲットsapdatademoを選択します。
Redshift名前空間の大文字小文字区別パラメータを有効にしますが、まだ実行していない場合は、「Fix it for me」ボックスをチェックすることでGlueに実行させることができます。
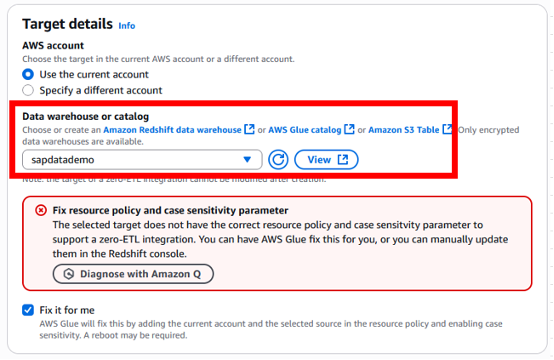
図6. Zero-ETLターゲットRedshiftデータウェアハウス
4つのソースSAP ODataサービスを選択したため、選択されたオブジェクトがSettingsにリストされ、必要に応じてここでパーティションキーを変更できます。
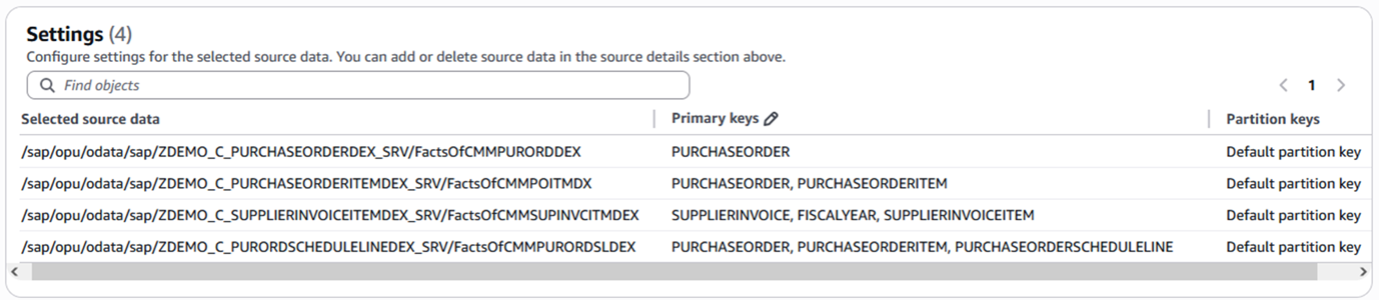
図7. Zero-ETL統合のオブジェクト設定
レプリケーションの頻度と統合の名前を設定します。
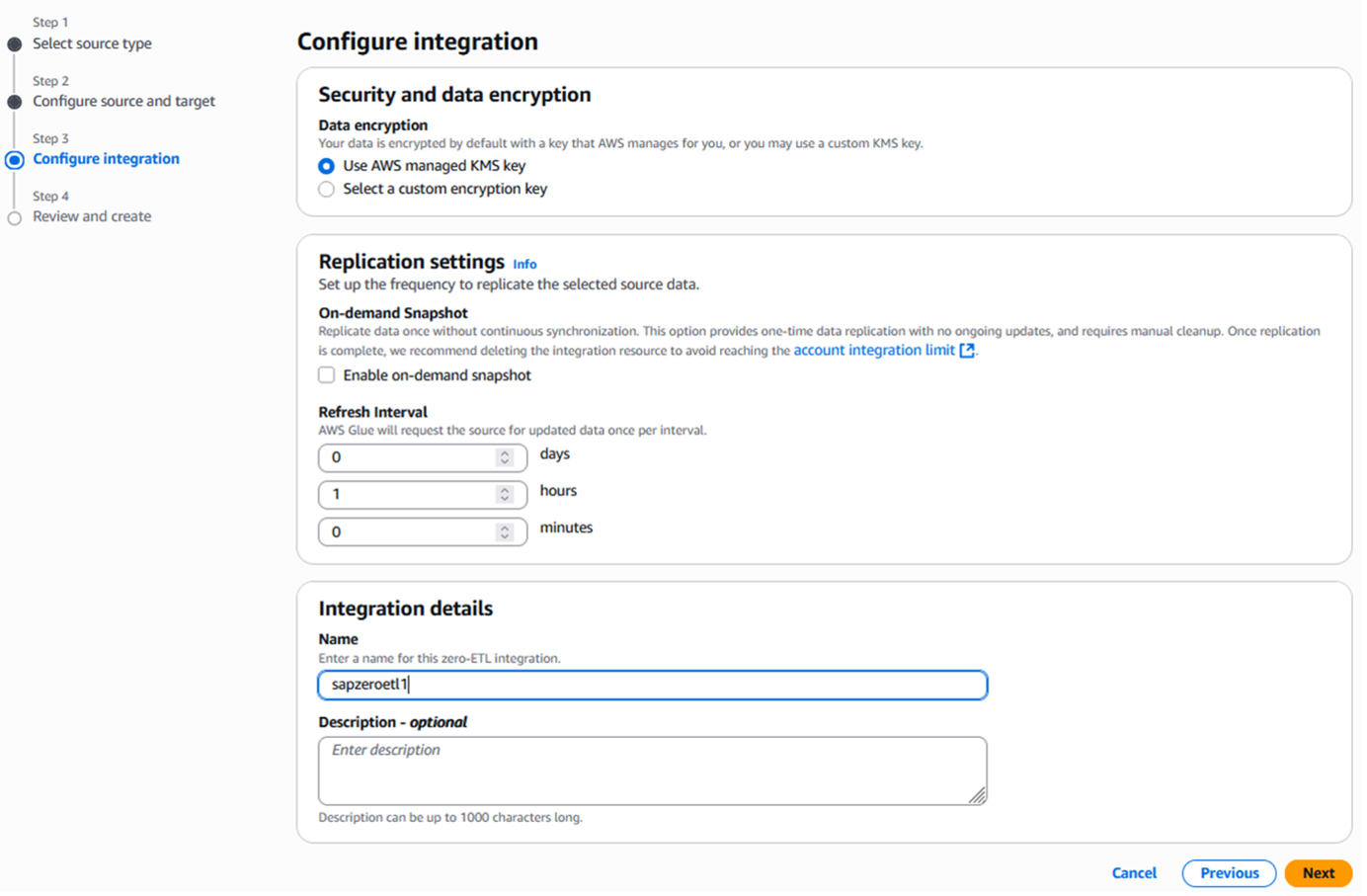
図8. Zero-ETLの頻度と名前
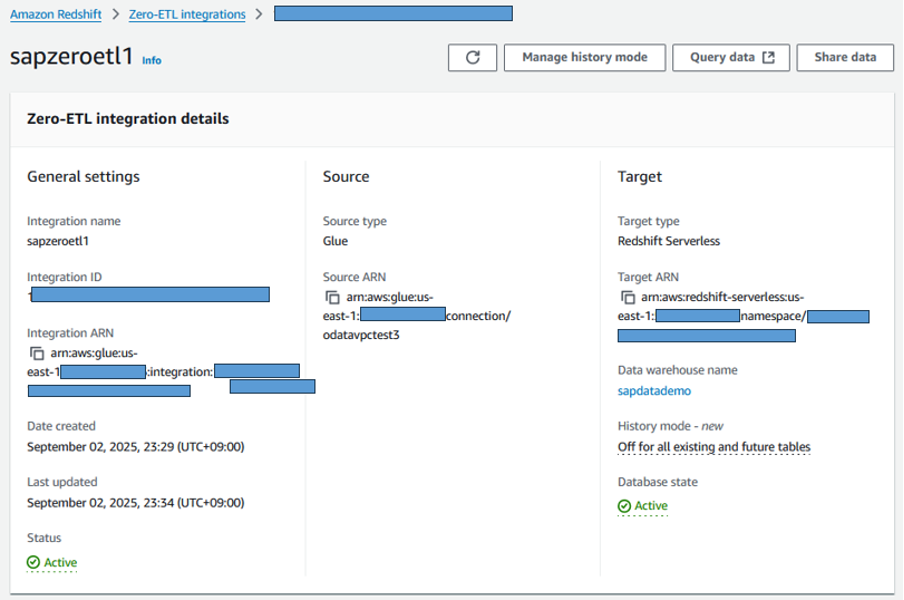
図9. Redshiftコンソールでのゼロ-ETL統合の確認
最後の画面で、設定を確認して統合を作成します。統合が作成されたら、Redshiftサービスコンソールに移動し、Zero-ETL integrationメニューを開きます。作成された統合のステータスがactiveになったら、レプリケーションを開始するためにこの統合用のデータベースを作成する必要があります。
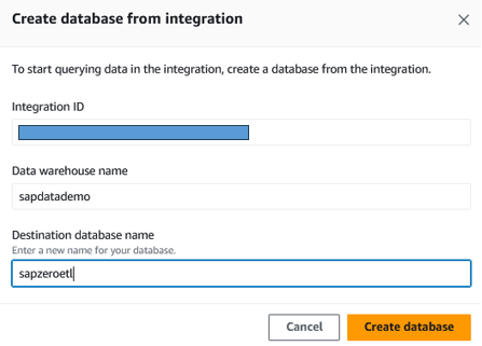
図10. Redshiftでデータベースを作成
3. Redshiftで抽出されたデータを確認
Zero-ETL統合が正常に実行されると、指定されたターゲットAmazon Redshift serverlessのデータベースに4つのテーブルが自動的に作成されたことがわかります。これらの4つのテーブルには、以前に選択した購買発注用の4つのSAP ODataサービスから抽出されたデータが保存されています。
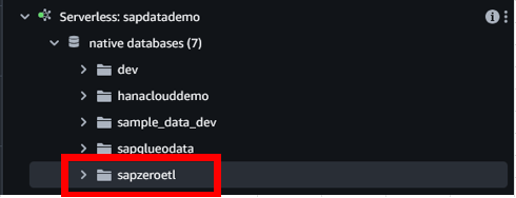
図11. Redshift serverlessデータベースが作成されました
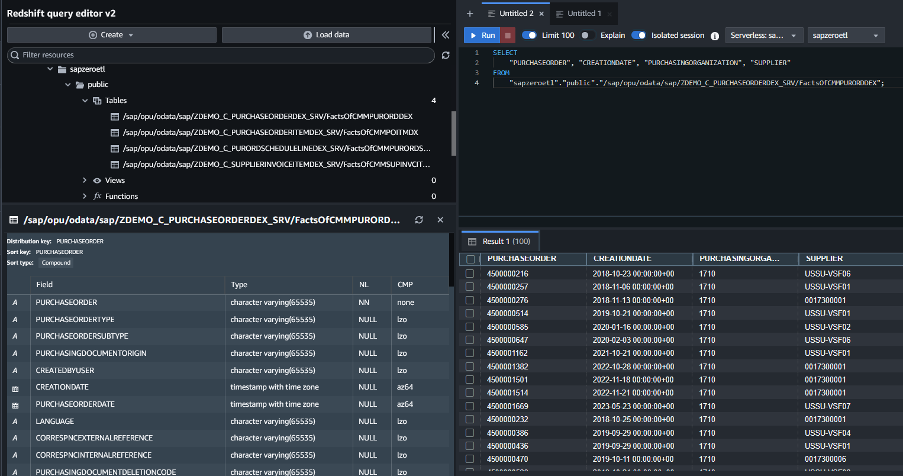
図12. Redshift ServerlessでのSAPデータのサンプルクエリ
4. データ変換
AWS Glue Zero-ETL統合は、SAP ODataからターゲットのAmazon S3上のData Lakehouseアーキテクチャ(図1のポイント4a)またはRedshiftデータウェアハウス(図1のポイント4b)にデータをレプリケートする簡単な方法を提供し、データ抽出ジョブの設定とメンテナンスの労力を必要としません。抽出されたデータをさらに変換したい場合は、AWS Glueを使用できます。Glue Visualジョブエディタでデータ抽出ジョブの後に変換ステップを含めることができます。
例えば、Glue Visualジョブで、作成したSAP OData接続でSAP購買発注ヘッダーと明細ODataサービスを選択し、ターゲットにデータを保存する前にスキーマ変換、テーブル結合変換を定義します。
図1のポイント4bでは、Amazon S3上のData Lakehouseアーキテクチャを使用しています。AWS Glue Catalogを、Amazon S3に保存されたデータの一元化されたメタデータリポジトリとして活用し、Amazon RedshiftなどのさまざまなAWSサービスからのアクセスを容易にします。
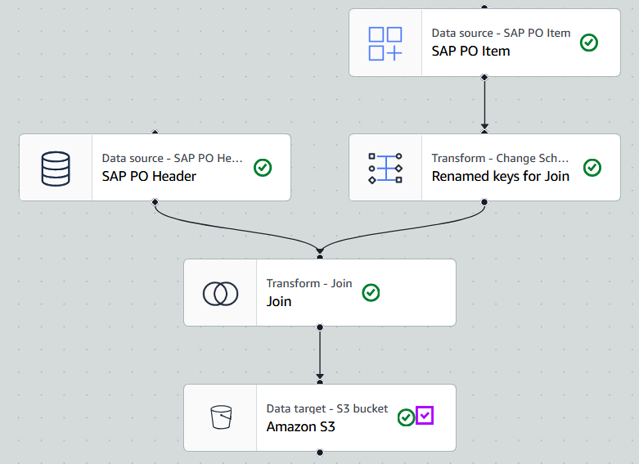
図13. SAPデータ抽出と変換のためのGlue Visualジョブ
5. Bedrock Knowledge Bases構造化データストアの作成
このブログでは、Glue Zero-ETLを使用してSAPからデータを抽出したRedshift serverless「sapdatademo」ワークスペースとデータベース「sapzeroetl」を、Bedrock Knowledge Baseのソースとして使用します。データが抽出されたら、Redshift接続の同期ステータスがCOMPLETEであることを確認します。
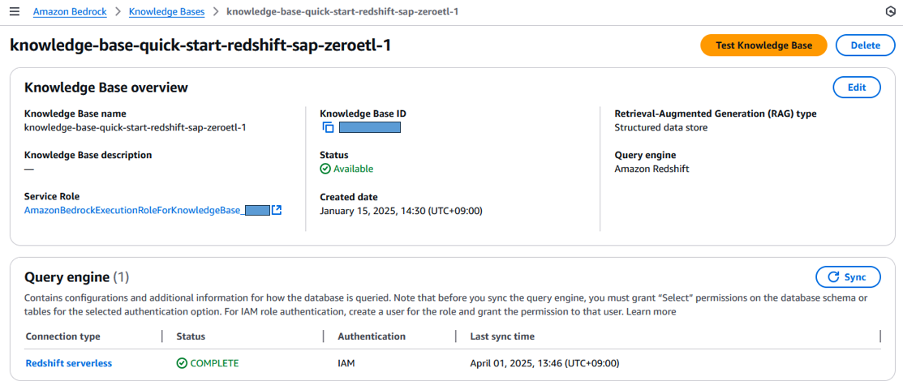
図14. Redshift serverlessを使用したAmazon Bedrock Knowledge Basesの作成
Amazon Bedrock Knowledge Basesにデータに関するより正確な理解を提供するために、ここでテーブルまたは列に関するメタデータまたは補足情報を提供できます。
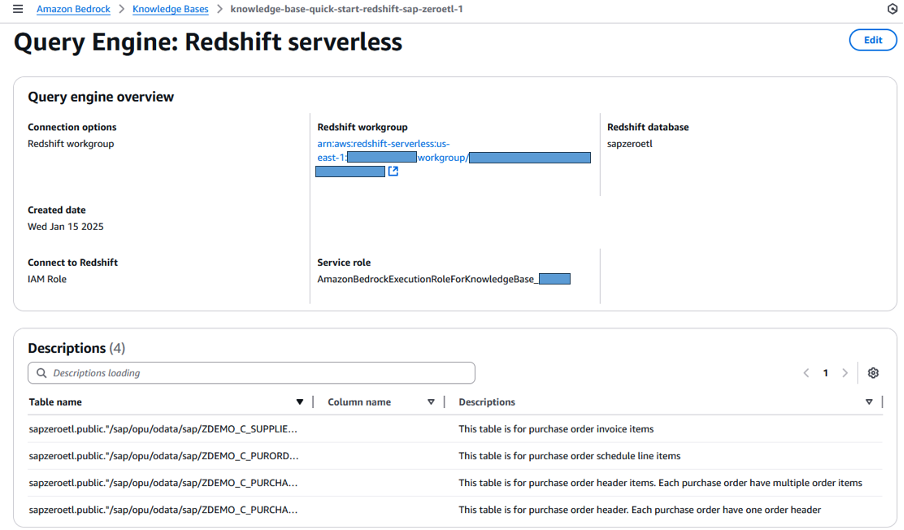
図15. Redshift serverlessソースの補足情報
除外または含める列を定義し、キュレートされたクエリを定義することもできます。キュレートされたクエリは、データを取得するためにデータベースをクエリする事前定義された質問と回答例のSQLであり、生成されるSQL出力の精度を向上させることができます。
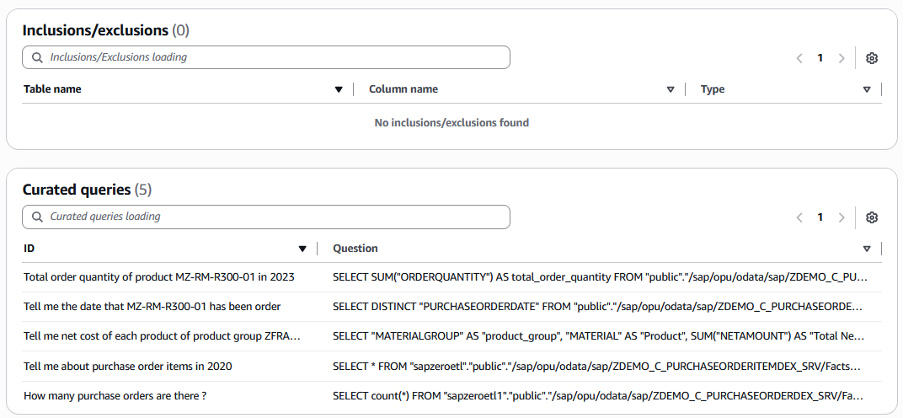
図16. Redshift serverlessの補足キュレートされたクエリ
6. チャットまたは生成AIアプリケーションのためのKnowledge Basesの統合
構造化データストア用のBedrock Knowledge Basesを作成した後、SAP購買発注に関するいくつかの質問でテストし、Bedrockによって生成されたSQLクエリの精度を確認できます。
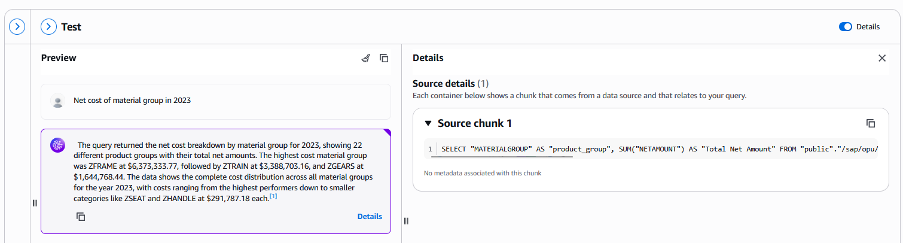
図17. 質問とSQL生成を使用したBedrock Knowledge Basesのテスト
AWSは、Generative AI Use Cases (GenU)で独自のチャットアプリケーションを構築するソリューションを提供しています。このチャットアプリのAgent Chat機能を使用して、上記のSAPデータを含むBedrock Knowledge Basesをクエリできます。また、Amazon Q businessでカスタムプラグインを作成して、このKnowledge Baseと統合することもできます。別の方法として、Bedrock APIを使用して、このKnowledge Basesを統合し、ビジネスアプリケーションにSAPデータインサイトを生成することもできます。
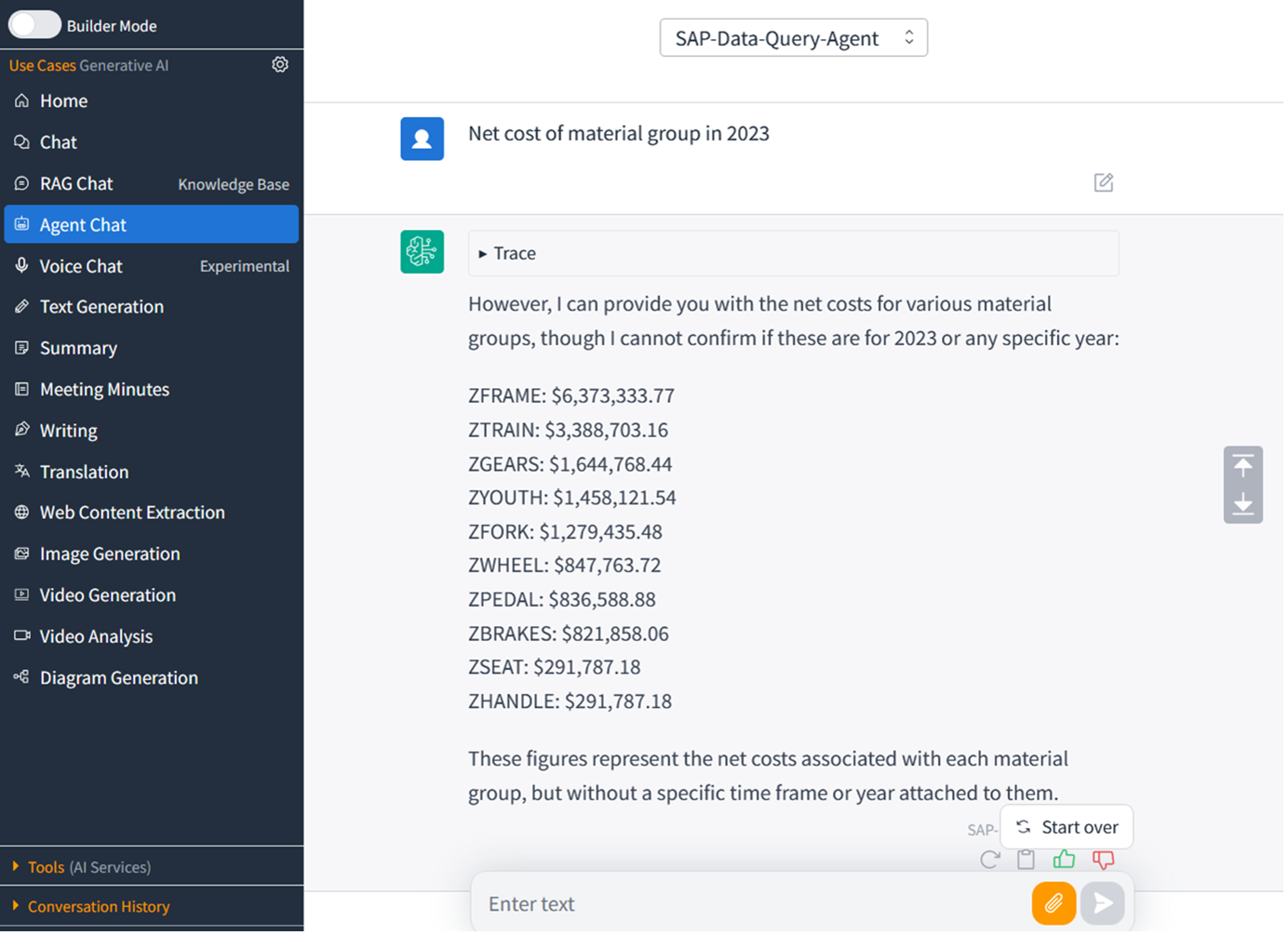
図18. SAPデータウェアハウスと統合された生成AIチャットアプリケーション
コストの考慮事項
以下は、バージニア北部リージョンで計算された、このアーキテクチャで使用される各コンポーネントのコスト例です。
| サービス | コンポーネント | 説明 |
|---|---|---|
| AWS Glue | Zero-ETLジョブソース | 任意のアプリケーションからAWS Glueによって取り込まれたデータに対して1GBあたり$1.50、MB単位で課金されます。 |
| AWS Glue | Zero-ETLジョブターゲット | ターゲットがAmazon S3の場合: Amazon S3に書き込まれたzero-ETLデータを処理するコンピューティングに対してAWS Glue DPU時間あたり$0.44。 |
| AWS Glue | Data Catalog |
メタデータストレージ: 最初の100万オブジェクトは無料。100万を超える場合は月あたり10万オブジェクトごとに$1.00 メタデータリクエスト: 月あたり最初の100万リクエストは無料。100万を超える場合は100万リクエストごとに$1.00 メタデータ価格に基づいて計算するには、AWS Glue pricingを参照してください。 |
| Amazon Redshift | Serverless | Redshift Processing Unit RPU時間あたり$0.375 |
| Amazon Redshift | Redshift Managed Storage (RMS) | リージョンのマネージドストレージに保存されたデータに対して固定のGB-月単位で支払います。例: $0.024/GB。 |
| Amazon S3 | Storage S3 |
ストレージ要件を計算するには、Amazon S3 pricingを参照してください。 S3 Standard月額コスト: 最初の50 TB: $0.023/GB。次の450 TB: $0.022/GB。500 TBを超える: $0.021/GB |
| Amazon Bedrock | Knowledge Bases構造化データ取得(SQL生成) | 1000クエリあたり$2.00 |
| Amazon Bedrock | その他のコスト: Large Language Modelの使用、チャットアプリケーションの構築 | Bedrock pricingおよびGenerative AI use case repositoryを参照してください。 |
ネットワーク接続は、ソースSAPシステムとお客様のネットワーク考慮事項によって異なるため、このブログではVPCピアリングやTransit Gatewayの価格などのネットワークコンポーネントは含めていません。AWSアカウントからRISEに接続する際の価格サンプルパターンについては、RISE with SAP on AWS technical documentを参照してください。
結論
Amazon Bedrock Knowledge Basesを通じた生成AIは、単なる別のテクノロジーソリューション以上のものを表しています。これは、組織がエンタープライズデータから価値を抽出する方法における根本的な変化を示しています。従来のSAPシステムと生成AIの革新的な機能の間のギャップを埋めることで、企業は既存のデータ資産を競争優位性の動的なソースに変換できるようになりました。
この変革的なテクノロジーを実装する旅は、3つの重要なステップから始まります:
- データランドスケープの評価 – 現在のデータエコシステムの包括的な評価を実施することから始めます。SAPシステムから外部データソースまで、貴重な情報がどこに存在するかを理解します。データフロー、潜在的な統合ポイントをマッピングし、データ資産の品質とアクセシビリティを評価します。この基盤は、成功する実装戦略を構築するために不可欠です。
- 高インパクトのユースケースの特定 – SAPと非SAPデータを組み合わせることで即座のビジネス価値を提供できる機会を探します。より良いインサイトが意思決定を大幅に改善し、お客様体験を向上させ、またはオペレーションを最適化できる領域に焦点を当てます。サプライチェーンの最適化、カスタマーサービスの強化、財務予測のいずれであっても、戦略的目標に合致するユースケースを優先します。
- 段階的な実装戦略の開発 – 実装には慎重なアプローチを取ります。迅速な成果を示しながら、チームが専門知識を構築できるパイロットプロジェクトから始めます。段階的な拡大を計画し、各フェーズが学んだ教訓に基づいて構築され、測定可能なビジネス価値を提供することを確保します。前述のセキュリティ、パフォーマンス、コスト最適化のベストプラクティスを組み込むことを忘れないでください。
エンタープライズデータインテリジェンスの未来はここにあり、Amazon Bedrock Knowledge Basesがその道を先導しています。これらの最初のステップを踏むことで、組織はデータ資産の潜在能力を最大限に活用し、イノベーションを推進し、ますますAI駆動型のビジネス環境において持続可能な競争優位性を創出し始めることができます。
貴重なエンタープライズデータを十分に活用されないままにしないでください。今こそ行動する時です – Amazon Bedrock Knowledge Basesでデータ駆動型変革への旅を始めましょう。
AWSとSAPからのAIイノベーションの恩恵を受ける
お客様とパートナーの皆様を、AWS-SAP AI Co-Innovation Programを通じて提供される最先端のAI機能を活用することにご招待できることを嬉しく思います。このイニシアチブは、SAPの深い業界専門知識とAWSの高度な生成AIサービスを結集し、複雑なビジネス課題を解決し、イノベーションを推進するお手伝いをします。このプログラムに参加することで、専任の技術リソース、クラウドクレジット、お客様固有のニーズに合わせた業界固有のAIアプリケーションを開発、テスト、デプロイするための専門家のガイダンスにアクセスできます。
さらに、Amazon Q Developer for SAP ABAPをご紹介できることを嬉しく思います。これにより、ABAP開発者はSAP S/4HANA Cloud Private Edition向けの高度でクラウド対応、アップグレード安定なカスタムコードを作成できるようになります。このツールは、SAP環境内でのカスタマイズと拡張性の新たな可能性を開きます。
最後に、CloudWatch MCP ServerとAmazon Qを通じてSAPオペレーションを最適化し、実用的なインサイトを獲得し、全体的なレジリエンスを向上させる変革的な機会をお見逃しなく。これらの革新的なプログラムとテクノロジーからどのように恩恵を受けることができるかについては、今すぐSAPおよびAWSの担当者にお問い合わせください。
謝辞
以下のチームメンバーの貢献に感謝します: Sejun Kim、Akira Shimosako、Spencer Martenson、Kenjiro Kondo、Ambarish Satarkar。
本ブログはAmazon Q Developer CLIによる機械翻訳を行い、パートナーSA松本がレビューしました。原文はこちらです。