- AWS Builder Center›
- builders.flash
Amazon Redshift を活用したゲームの行動ログ分析
2023-11-01 | Author : Sheng Hsia Leng, 森下 真孝
はじめ
ゲームなみなさんこんにちは、Game Solutions Architect の Leng (@msian.in.japan) と Game Solutions Architect の森下です。
この投稿ではモバイルゲームやオンラインゲームといった運営型のゲームにおいて、ユーザーの行動を分析するための手段として Amazon Redshift と Amazon Kinesis をご紹介します。
builders.flash メールメンバー登録
AWS for Games
今回の内容
この投稿は、ゲーム分析に関する builders.flash シリーズの第 2 弾になります。
前回の記事 では、リレーショナルデータベースにあるデータの分析として、Amazon Aurora MySQL と Amazon Redshift Serverless の Zero-ETL 統合についてご紹介しました。Amazon Redshift の Zero-ETL 統合を使うことで、Amazon Aurora MySQL にあるデータを、データパイプラインを構築せずに分析することができます。
しかし、リレーショナルデータベースにあるデータだけでは、 ゲーム分析のニーズに対処できない場合があります。
リレーショナルデータベースは、トランザクション処理による厳密性、頻繁なデータ行の更新、といった性質において優れています。一方で、プレイヤーの行動ログはデータ行の更新が発生せず、常に大量のデータが追加され続けるという性質があります。その場合はリレーショナルデータベースではなく、ストリーミングサービスやデータウェアハウスのソリューションを採用することで、性能やコストを最適化できる可能性があります。
今回は、プレイヤーの行動に関する分析に焦点を当て、AWS のサービスを活用した実現方法について紹介します。
ログデータとトランザクションデータの比較
ここで、リレーショナルデータベースに格納されるトランザクションデータと、アプリケーションが生成するログデータの性質を比較していきます。
トランザクションデータは、既存行の更新、削除処理が発生します。例えばゲームであれば、プレイヤーのレベルや、リソースの量は単一行で表され、それをプレイ状況に応じて絶えず更新する必要があります。また、所持しているアイテムを消費したり、捨てたりした場合はデータ行の削除処理が必要になります。更新や削除を行う際、トランザクションデータは一連の処理が矛盾した結果で終了しないようにトランザクション処理されます。
一方、ログデータは既存行の更新、削除を原則として行わないという性質があります。例えばゲームにおけるプレイヤーの行動履歴は、行動のたびに新しいデータが生成、格納されます。そのため、一連の処理に矛盾が発生する余地がありません。また、トランザクションデータよりも大量のデータが絶えず生成されるため、ストリーミング処理で取り扱う方が適しています。
また、データのサイズの観点で比較すると、トランザクションデータは通常ギガバイト単位であるのに対し、ログデータはテラバイト、ペタバイト単位まで増大することがあります。
以上の比較を表にまとめると、次のようになります。
|
|
トランザクションデータ |
ログデータ |
|
データの追加処理 |
トランザクション |
ストリーミング |
|---|---|---|
|
データの更新、削除 |
あり |
なし |
|
データの量 |
ギガバイト |
テラバイト ~ ペタバイト |
|
ゲームにおけるユースケース |
ユーザーのプレイデータ
|
ユーザーの行動履歴 |
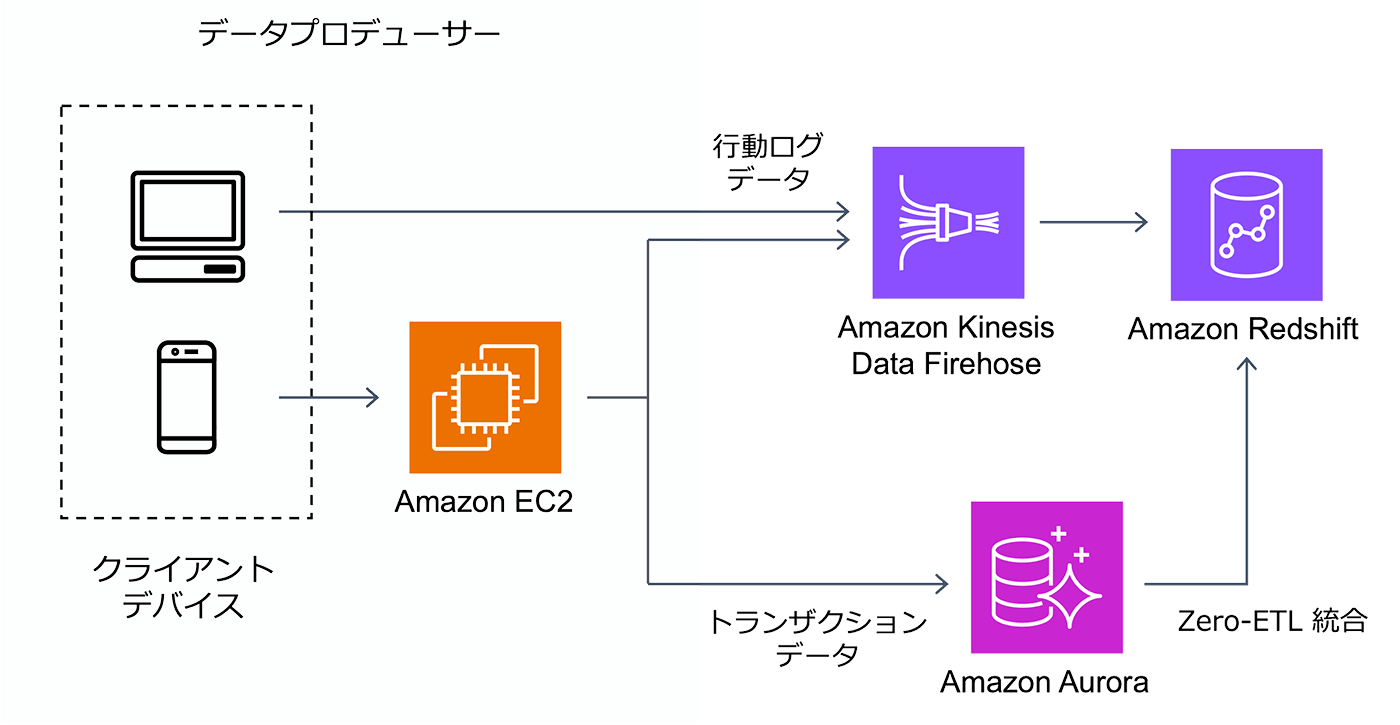
Amazon Redshift を活用した分析システムの構築例
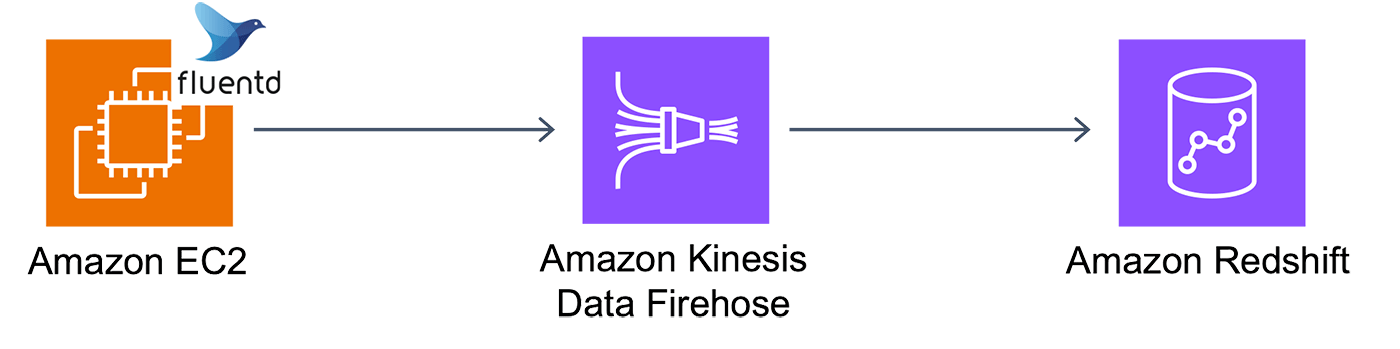
一番左が、行動ログを生成するデータプロデューサーになります。データプロデューサーには、モバイルや PC などのクライアントデバイス、Amazon EC2 などのバックエンドサービスが含まれます。
バックエンドサービスは API リクエストを受け付け、処理の内容に応じたトランザクションデータを Amazon Aurora などのリレーショナルデータベースに格納します。Amazon Aurora に格納されているトランザクションデータは、Amazon Redshift の Zero-ETL 統合機能を活用することで、すぐに分析を始めることができます。
一方、データプロデューサーから出力された行動ログデータは、Amazon Kinesis Firehose (以下、Amazon Kinesis Firehose)にストリーミングされます。Amazon Kinesis Data Firehose を活用すると、いくつかの項目を設定するだけで、簡単にストリーミングデータを Amazon Redshift に格納し分析を始めることができます。
ゲームにおける行動ログ分析のユースケース
では、実際にログデータをどのように活用できるのか、ゲームにおける行動ログ分析のユースケースについて考えてみたいと思います。
レベルデザイン、バランス調整
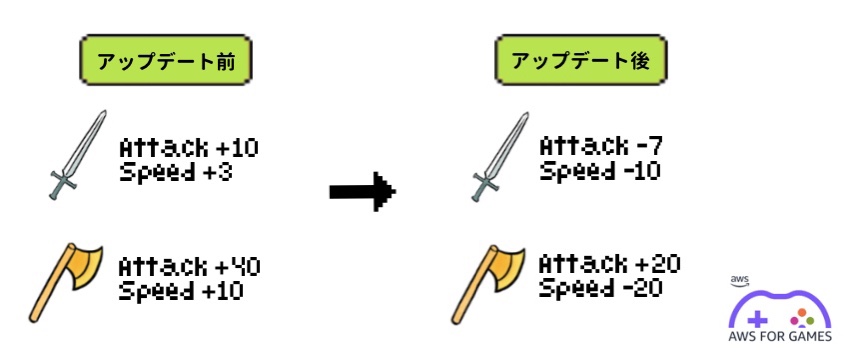
例えば、対戦シューティングゲームにおいて特定の武器やキャラクターによる勝率が高すぎると、多くのプレイヤーが同じ選択を行うようになり、結果としてゲームの遊びの幅が狭まってしまいます。こういった事態を防ぐため、昨今のゲームでは、リリース後にゲーム内のパラメータを変更することが珍しくなくなりました。
こういったレベルデザイン、バランス調整の際には、ある武器やキャラクターを選択した際の行動をログとして収集し、分析することで根拠となるデータが得られることが期待できます。
チート検出

プレイヤーに長くゲームをプレイしてもらうためには、継続的にゲーム環境の保守と改善に取り組むことが不可欠です。特にマルチプレイヤーゲームではチーターを排除することが重要です。チーターに負けてしまうと、プレイヤーは不快感を抱き、ゲームから離れてしまう可能性があります。
一般的なゲーム運営で取得した時系列ベースの行動ログを解析用のデータに加工し、機械学習を用いてプレイヤーのアイテム数の偽装や不正な行動を検出することができます。ゲームログの分析と機械学習の活用でチーターを検出し、アカウントを BAN するなどの処置を行うことにより、ゲームの公平性を維持し、すべてのプレイヤーが快適にゲームを楽しめる環境を実現できると考えられます。
マッチングルールの改善
プレイヤーの勝敗履歴、スキルやレベル、ゲーム内退場確率などを分析し、マッチングアルゴリズムを微調整することで、プレイヤー間の力量差が大きすぎるような不公平なマッチングを減らすことができます。マッチングルールの改善は、プレイヤーの不満やストレスを軽減することに繋がり、継続的なプレイとゲーム運営の改善効果が得られると考えられます。
LTV 最大化の施策考案
近年のゲーム開発およびマーケティングコストの高騰は、プレイヤーの生涯価値 (LTV) 最大化の重要性を押し上げています。
例えば、個々のプレイヤーのプレイスタイルと課金パターンを分析し、それぞれのニーズに合わせたプロモーションを実施することで、LTV の最大化を実現することができると考えられます。加えて、上述したチート検出とマッチングアルゴリズムの改善により、プレイヤーの満足度を高めて長くプレイしてもらうことで LTV 向上に役立つと考えられます。
想定シナリオ : 対戦シューティングゲームの試合データ
出力するログについて
出力するログは、対戦シューティングゲームの試合データを想定します。プレイヤーは任意の武器を試合に持ち込み、他のプレイヤーとデスマッチ形式で対戦します。このとき、あるプレイヤーが他のプレイヤーを撃破した際にログを出力することとします。出力するデータは、プレイヤー ID 、武器 ID 、撃破されたプレイヤーの ID 、撃破されたプレイヤーが所持していた武器 ID とします。開発者はこのデータを武器のバランス調整などに活用することができます。
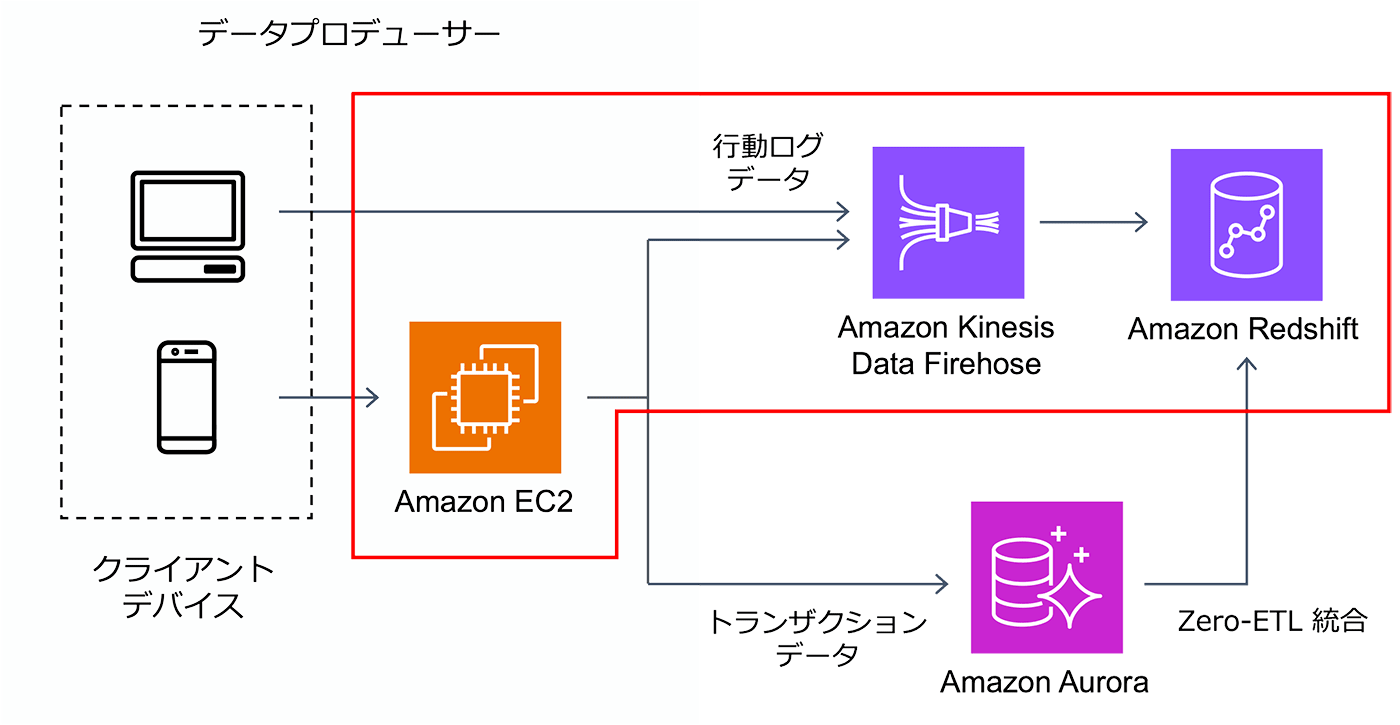
今回構築するアーキテクチャを次の図に示します。
Amazon EC2 をゲームサーバーに見立て、ダミーのログを生成する Python スクリプトを配置します。ログは、Amazon EC2 上に起動した fluentd へ http で出力されます。fluentd の Kinesis 統合機能を利用し、Kinesis Data Firehose へデータをストリーミング、最終的に Redshift にデータを格納します。
それでは、以下より手順を解説していきます。
1. Amazon Redshift Serverless の作成
1. Amazon Redshift Serverless の作成
Amazon Redshift Serverless の開始
Amazon Redshift のページを開き、左のメニューから Redshift サーバーレス を選択します。

すべてデフォルトの状態で「設定を保存」をクリックします。

Amazon Redshift サーバーレスの構成が完了するまで数分待ちます。作成が完了したら、ダッシュボードにデフォルトのワークグループが作成されています。

ゲーム分析用のワークグループを作成
今回は、ゲーム分析用に新しくワークグループを作成していきます。
右上の「ワークグループを作成」をクリックし、以下の構成でワークグループを作成します。
-
ワークグループ名 : game-log-workgroup
-
ベース RPU 容量 : 32
上記以外はデフォルトで「次へ」をクリックします。

名前空間は「game-log-namespace」とします。

「関連付けられた IAM ロール」では、「IAM ロールの管理」から「IAM ロールの作成」を選択し、デフォルトの IAM ロールを作成します。追加の Amazon S3 バケットは指定しません。


それ以外は全てデフォルトとして「次へ」「作成」とクリックしていきます。
セキュリティグループの設定
Amazon Kinesis Data Firehose から Amazon Redshift クラスターにアクセスするためには、ワークグループにセキュリティグループを設定する必要があります。
Amazon EC2 のページを開き、左のメニューから「セキュリティグループ」を選択、「セキュリティグループを作成」を選択します。

セキュリティグループ名と名前は「game-log-redshift-group」とします。
インバウンドルールに、以下の行を追加します。
-
タイプ : Redshift
-
ソース : 13.113.196.224/27
13.113.196.224/27 は東京リージョンにおける Amazon Kinesis Data Firehose のパブリック IP アドレスになります。東京リージョン以外の IP アドレスは こちらで確認できます。
それ以外はすべてデフォルトの状態のまま作成します。

次に、Redshift のページへ移動します。Amazon Redshift サーバーレスのダッシュボードから「game-log-workgroup」を選択し、「ネットワークとセキュリティ」の「編集」をクリックします。

「VPC セキュリティグループ」に「game-log-redshift-group」を選択します。「default VPC security group」が選択されている場合は解除します。
また「[パブリックにアクセス可能] をオンにする」も有効にします。
それ以外はデフォルトのまま「変更を保存」をクリックします。

以上で Amazon Redshift Serverless の構成が完了しました。
2. Amazon Kinesis Firehose の設定
ストリームの作成
Amazon Kinesis のページを開きます。
左のメニューから Data Firehose をクリックし、「配信ストリームを作成」をクリックします。

「ソースと送信先を選択」で、以下の構成を選択します。
-
ソース : Direct PUT
-
送信先 : Amazon Redshift

配信ストリーム名は「game-log-stream」とします。

送信先の設定は「Serverless ワークグループ」を選択し、Serverless ワークグループは先ほど作成した「game-log-workgroup」とします。

データベースの設定は以下の構成とします。
-
データベース : game
-
ユーザー名 : admin
-
パスワード : 任意の文字列
-
テーブル : log

「S3 の中間バケット」の項目を設定します。今回は「作成」をクリックして新しく作成します。

S3 の設定画面に移動します。S3 の「一般的な設定」を構成していきます。
バケット名は「{任意の文字列}-game-log-from-firehose」とします。それ以外は全てデフォルトの状態で「バケットを作成」をクリックします。

Amazon Kinesis Data Firehose の設定画面に戻ります。
「S3 の中間バケット」の「参照」をクリックし、先ほど作成した S3 バケットを選択します。

「COPY コマンドオプション」には以下のコマンドを入力します。
json 'auto ignorecase'
それ以外の設定はデフォルトのままとし、「配信ストリームを作成」をクリックします。
3. Amazon Redshift データベース・テーブル作成
データベースの作成
次に、ログ分析用のデータベースを作成します。
Amazon Redshift のページを開き、左のメニューから「クエリエディタ v2」をクリックします。

クエリエディタが立ち上がったら「Serverless: game-log-workgroup」を選択します。
Connect to game-log-workgroup というダイアログが開くので、Federated user のまま「Create Connection」を選択します。

上部の「Create」ブルダウンから「Database」を選択します。

データベースの作成画面が開かれるので、Database には「game」を入力、Users and groups には「admin」を選択し、「Create database」を選択します。

テーブルの作成
次に、game データベースにテーブルを作成します。
画面上部の「+」タブをクリックし、「Editor」を選択します。

workgroup と database として、今回作成したものを選択し、エディタに以下のクエリを入力します。
CREATE TABLE log (
player_id int,
weapon_id int,
defeated_player_id int,
defeated_weapon_id int,
created_at int
);
「Run」ボタンをクリックすると、log テーブルが作成されます。

Admin パスワードの設定
Admin ユーザーのパスワードを設定します。
サーバーレスダッシュボードから、game-log-namaspace 名前空間を選択し、管理者パスワードを変更をクリックします。

管理者ユーザー名は「admin」とし、パスワードは Amazon Kinesis Data Firehose の設定の際に入力したものとします。

4. Amazon EC2 (ダミーのゲームサーバー) の設定
IAM ロールの作成
ダミーのゲームサーバーとして EC2 を立ち上げる前に、EC2 から Amazon Kinesis Data Firehose にアクセスするための IAM ロールを作成しておきます。
IAM の画面を開き、左のメニューから「ロール」を選択、「ロールを作成」ボタンをクリックします。

「信頼されたエンティティを選択」で、以下の構成で次へをクリックします。
-
信頼されたエンティティタイプ : AWS のサービス
-
ユースケース : EC2

「許可ポリシー」の画面で、Firehose で検索し「AmazonKinesisFirehoseFullAccess」を選択して「次へ」をクリックします。

ロール名は「GameServerFirehoseAccessRole」として「ロールを作成」をクリックします。

以上で IAM ロールの作成は完了です。
EC2 の起動
次に、ゲームサーバーとなる EC2 を起動します。
EC2 のページに遷移し、「インスタンスを起動」を選択します。名前には「analytics」を入力します。

ページ下部の「高度な詳細」を開き、先ほど作った IAM ロールを指定します。

それ以外はすべてデフォルトの状態で「インスタンスを起動」を選択します。
キーペアを作成のダイアログが表示されたら「キーペアなしで続行」を選択します。

5. fluentd の起動と設定
EC2 への接続
EC2 が起動したら、 analytics インスタンスを選択して「接続」をクリックします。

インスタンスの接続方法として、「EC2 Instance Connect」を選択し、接続をクリックします。

このようなコマンドラインが表示されれば完了です。

fluentd のインストール
EC2 に fluentd をインストールします。
fluentd のドキュメントより、立ち上げた OS に合わせてインストールコマンドを実行します。
https://docs.fluentd.org/installation/install-by-rpm#amazon-linux
次に、fluentd の kinesis プラグインを、以下のコマンドでインストールします。
sudo /usr/sbin/fluent-gem install fluent-plugin-kinesisfluentd.conf の変更
fluentd の設定を変更し、http 経由で受け取ったログを Amazon Kinesis Data Firehose に流すようにします。
以下のコマンドを実行し、fluentd.conf の変更を行います。
sudo vi /etc/fluent/fluentd.confファイルの任意の箇所に、以下の設定を追記します。
<source>
@type http
port 8889
bind 0.0.0.0
tag game.log
</source>
<match game.**>
@type kinesis_firehose
region ap-northeast-1
delivery_stream_name game-log-stream
<buffer>
flush_interval 1
chunk_limit_size 1m
flush_thread_interval 0.1
flush_thread_burst_interval 0.01
flush_thread_count 15
total_limit_size 2GB
</buffer>
</match>ファイルの修正が完了したら、以下のコマンドで fluentd を再起動します。
sudo systemctl restart fluentd.serviceダミーゲームサーバースクリプトの作成
fluentd に http リクエストでログを送信するダミーゲームサーバースクリプトを作成します。
以下のコマンドを実行し、dummy_server.py を作成します。
vi dummy_server.py以下の Python スクリプトを貼り付けます。このスクリプトは、あらかじめ用意されたプレイヤー ID と武器 ID の対をランダムで選び、倒したプレイヤーと武器もランダムに選択してログを生成します。
import requests
import time
import random
RECORDS_NUM = 1000
PLAYER_ID_LIST = [
100000001,
100000002,
100000003,
100000004,
100000005,
100000006,
]
PLAYER_TO_WEAPON_ID_LIST = {
100000001: 200000001,
100000002: 200000002,
100000003: 200000001,
100000004: 200000003,
100000005: 200000001,
100000006: 200000002,
}
for i in range(RECORDS_NUM):
player_to_defeat_weight = {
100000001: 80,
100000002: 90,
100000003: 120,
100000004: 120,
100000005: 50,
100000006: 110,
}
player_id = random.choices(PLAYER_ID_LIST, [120, 110, 80, 80, 150, 90]).pop()
player_to_defeat_weight.pop(player_id)
defeat_player_id = random.choices(list(player_to_defeat_weight.keys()), list(player_to_defeat_weight.values())).pop()
current_timestamp = int(time.time())
body = {
"player_id": player_id,
"weapon_id": PLAYER_TO_WEAPON_ID_LIST[player_id],
"defeated_player_id": defeat_player_id,
"defeated_weapon_id": PLAYER_TO_WEAPON_ID_LIST[defeat_player_id],
"created_at": current_timestamp
}
r = requests.post('http://localhost:8889/game.log', json=body);
print(body)
time.sleep(random.uniform(0.1, 1.5))ダミーゲームサーバーの起動
以下のコマンドを実行してダミーサーバーを起動します。
python3 dummy_server.pyこのスクリプトを実行している限り、fluentd にログが送信され続けます。念のため 1,000 行出力した時点で停止するようにしていますが、数百行程度出力したら Ctrl + C などで停止していただいて問題ありません。
6. データの分析
Amazon Redshift Serverless にデータが入っていることを確認
以上の作業により、Amazon Redshift の log テーブルにデータが格納されます。クエリエディターでデータを確認してみましょう。
数分ほど待ってから、再び Amazon Redshift のクエリエディターを開きます。
画面上部の「+」タブをクリックし、「Editor」を選択して SQL 文を貼り付けます。
SELECT * FROM log;
上部の「Run」をクリックすることで、テーブルに格納されたデータを確認することができます。

分析クエリの実行
Amazon Redshift Serverless に格納されたデータに対して、実際の運用を想定したクエリを実行します。
次のクエリを実行すると、武器 ID ごとに撃破した回数を出力することができます。
SELECT weapon_id, COUNT(*) FROM log GROUP BY weapon_id;
Result ペインの右上にある「Chart」をクリックするとグラフ化することもできます。

7. リソースの削除
最後にリソースの削除を行います。
EC2 の削除
EC2 のページを開き、analytics インスタンスを選択し、「インスタンスの状態」から「インスタンスを終了」をクリックします。

Amazon Kinesis Data Firehose ストリームの削除
Amazon Kinesis Data Firehose のページを開き、「game-log-stream」を選択して「削除」をクリックします。

Amazon Redshift Serverless のワークグループの削除
Amazon Redshift Serverless のページを開き、game-log-workgroup のワークグループと名前空間を削除します。
まとめ
Amazon Kinesis Data Firehose を活用して、行動ログを Amazon Redshift Serverless に配信する方法について確認しました。
行動ログを活用してより良いゲーム開発を目指す開発者の方々に、この記事がご参考になれば幸いです。
筆者プロフィール
Sheng Hsia Leng
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
ゲーム業界に特化したソリューションアーキテクトとしてお客様を支援しております。
RPG とドット絵ゲームが好きです。オフモードの時はインスタでバイリンガル漫画を投稿しています。

森下 真孝
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
国内のモバイルゲーム開発会社でサーバーサイドからクライアントサイドまでを担当。
ゲーム業界向けのソリューションアーキテクトとしてゲーム開発に携わるお客様をご支援しております。