O blog da AWS
Padrões Serverless de arquiteturas de IA generativos — Parte 1
Por Michael Hume, arquiteto de soluções sênio na Amazon Web Services e Parnab Basa, sênior product acelerator SA na Amazon Web Services.
Organizações de todos os tamanhos e tipos estão aproveitando grandes modelos de linguagem (LLMs) e modelos básicos (FMs) para criar aplicativos de IA generativos que oferecem novas experiências para clientes e funcionários. A computação Serverless oferece a solução perfeita, permitindo que as organizações se concentrem na inovação, flexibilidade e economia sem a complexidade do gerenciamento da infraestrutura. As organizações que fazem a transição de suas implementações experimentais para aplicativos prontos para produção podem implementar padrões de design de software comprovados, escaláveis e de fácil manutenção como a base de sua arquitetura.
Esta série de duas partes explora os diferentes padrões de arquiteturas, melhores práticas, implementações de código e considerações de design essenciais para integrar com sucesso soluções generativas de IA em aplicativos novos e existentes. Nesta publicação, focamos nos padrões aplicáveis à arquitetura de aplicativos de IA generativa em tempo real. A parte 2 aborda os padrões para criar implementações generativas de IA orientadas por lotes usando serviços Serverless.
Separação de preocupações
Um princípio fundamental na criação de aplicativos robustos de IA generativa é a separação de responsabilidades, que envolve dividir a pilha de aplicativos em três componentes distintos: frontend, middleware e camadas de serviço de backend. Essa abordagem de arquitetura (conforme mostrado no diagrama a seguir) oferece vários benefícios, incluindo complexidade reduzida, maior capacidade de manutenção e a capacidade de escalar componentes de forma independente. Ao implementar essa separação, você pode desenvolver soluções multiplataforma e, ao mesmo tempo, manter a flexibilidade de desenvolver cada componente de acordo com requisitos específicos.
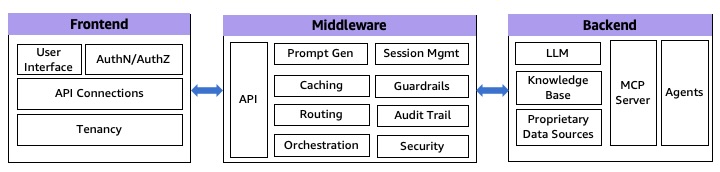
Figura 1: Arquitetura de IA generativa de 3 níveis
Embora essas camadas sejam meramente extensões da pilha de software tradicional, elas realizam algumas tarefas específicas em aplicativos generativos de IA.
Camada de frontend
A camada de frontend serve como a interface principal entre os usuários finais e o aplicativo generativo de IA. Para organizações que integram IA generativa em aplicativos existentes, essa camada pode já estar estabelecida. O frontend lida com responsabilidades críticas, incluindo autenticação de usuário, apresentação de UI/UX e comunicação de API. A AWS fornece um conjunto robusto de serviços Serverless para apoiar implementações de frontend, incluindo o AWS Amplify para desenvolvimento completo, o Amazon CloudFront combinado com o Amazon Simple Storage Service (Amazon S3) para entrega de conteúdo e serviços de containers como o Amazon Elastic Container Service (Amazon ECS) e o Amazon Elastic Kubernetes Service (Amazon EKS) para hospedagem de aplicativos. Serviços especializados, como o Amazon Lex, podem aprimorar a experiência do usuário por meio de interfaces conversacionais e recursos de pesquisa inteligente para criar chatbots interativos.
Camada de middleware
Isso representa a camada de integração, composta por três subcamadas essenciais que gerenciam diferentes aspectos da lógica do aplicativo e do fluxo de dados:
- Camada de API — Essa camada expõe serviços de backend por meio de vários protocolos, incluindo REST, GraphQL e WebSockets. Ele lida com funções essenciais, como validação de entrada, gerenciamento de tráfego e suporte ao CORS. A camada de API também implementa mecanismos de autorização e controle de acesso, gerencia o controle de versões da API e fornece recursos de monitoramento. Ele fornece comunicação segura e eficiente entre os componentes de frontend e backend, mantendo a escalabilidade e a confiabilidade. Os serviços gerenciados da AWS, como o Amazon API Gateway e o AWS AppSync, podem ajudar a criar um gateway de IA para simplificar o acesso e o gerenciamento de APIs.
- Camada de engenharia de prompt — Essa camada encapsula a lógica de negócios necessária para interagir com LLMs. Ele lida com geração dinâmica de solicitações, seleção de modelos, cache de solicitações, roteamento de modelos, grades de proteção e fiscalização de segurança. Essa camada implementa otimização de token e janela de contexto, filtragem de informações confidenciais, moderação do conteúdo de saída, tratamento de erros, lógica de repetição e trilhas de auditoria. Ao centralizar essas funções, você pode manter estratégias imediatas consistentes, reforçar a segurança e otimizar as interações do modelo entre os aplicativos. Você pode usar o Amazon DynamoDB para armazenar modelos e configurações de solicitações e usar o Amazon Bedrock Guardrails, o Amazon Bedrock Prompt Caching e o Amazon Bedrock Intelligent Prompt Routing para implementar proteções responsáveis de IA, reutilização de prefixos de solicitação e roteamento dinâmico, respectivamente.
- Camada de orquestração — Essa camada gerencia interações complexas entre vários componentes do sistema. Ele coordena chamadas externas de API e chamadas de agentes, gerencia consultas de bancos de dados vetoriais, armazena sessões de usuários e históricos de conversas e mantém o contexto da conversa em várias interações do LLM. Estruturas como LangChain e LlamaIndex são comumente usadas para simplificar essas operações e fornecer abordagens padronizadas para tarefas generativas comuns de IA. O AWS Step Functions tem integrações diretas com mais de 220 serviços da AWS, incluindo o Amazon Bedrock, permitindo que você construa fluxos de trabalho de IA generativos complexos sem precisar de recursos computacionais adicionais. Além disso, com o Amazon Bedrock Flows, você pode criar fluxos de trabalho complexos, flexíveis e com várias solicitações para avaliar, comparar e criar versões.
Serviços de backend, agentes e fontes de dados privadas
A camada de backend forma o núcleo da geração generativa de respostas de IA alimentada por LLMs. Ele consiste em hospedar e invocar o modelo LLM, agentes, bases de conhecimento ou um servidor Model Context Protocol (MCP). O Amazon Bedrock, o Amazon SageMaker JumpStart e o Amazon SageMaker oferecem uma variedade de FMs de alto desempenho das principais empresas de IA ou a opção de trazer as suas próprias. Você pode executar com segurança um servidor MCP usando uma arquitetura em containers, conforme descrito em Orientação para a implantação de servidores de protocolo de contexto modelo na AWS.
As fontes de dados privadas complementam os LLMs, fornecendo conhecimento proprietário autorizado fora de seus dados de treinamento. Para implementações de Retrieval Augmented Generation (RAG), o Amazon Kendra, o Amazon OpenSearch Serverless e a edição compatível com o Amazon Aurora PostgreSQL com a extensão pgVector oferecem opções de banco de dados vetoriais robustas e escaláveis. Para se aprofundar, leia O papel dos bancos de dados vetoriais em aplicativos generativos de IA nas opções de serviços da AWS disponíveis para armazenar incorporações em um banco de dados vetorial criado especificamente.
Os aplicativos em tempo real processam e fornecem respostas com latência mínima, aprimorando a experiência do usuário e facilitando a tomada de decisões mais rápida. Nas seções a seguir, exploraremos alguns padrões de arquitetura que podem ser usados para implementar aplicativos de IA generativa em tempo real.
Padrão 1: resposta de solicitação síncrona
Nesse padrão, as respostas são geradas e entregues imediatamente, enquanto o cliente bloqueia/espera pela resposta. Embora seja simples de implementar, tenha um fluxo previsível e ofereça forte consistência, ele sofre com operações de bloqueio, alta latência e possíveis tempos limite. Quando implementado para aplicativos generativos de IA, esse padrão é particularmente adequado para determinadas modalidades, como gerações de vídeo ou imagem. Para interações rápidas de LLM, ele pode lidar com várias solicitações simultâneas enquanto mantém um desempenho consistente sob cargas variadas. Esse modelo pode ser implementado por meio de várias abordagens arquitetônicas.
APIs REST
Você pode usar APIs RESTful para se comunicar com seu backend por meio de solicitações HTTP. Você pode usar APIs REST ou HTTP no API Gateway ou em um Application Load Balancer para roteamento baseado em caminhos para o middleware. O API Gateway oferece recursos adicionais, como autenticação baseada em tokens, autorizadores personalizados, permissões baseadas em recursos, mapeamento e transformação de solicitações/respostas, controle de versão e limitação de taxa. No entanto, com as APIs REST/HTTP no API Gateway, a resposta deve ser gerada em 29 segundos para atender ao tempo limite de integração padrão. Você pode estender esse limite padrão para 5 minutos para APIs REST com uma possível redução na cota de aceleração em nível de região da AWS para sua conta. Para ver um exemplo de implementação, consulte Interagir com modelos do Bedrock a partir de uma função Lambda com front-end de um API Gateway. O diagrama a seguir ilustra essa arquitetura.
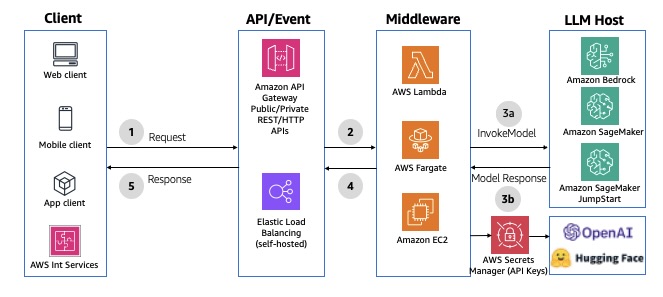
Figura 2: APIs REST/HTTP síncronas usando o Amazon API Gateway
APIs HTTP do GraphQL
Você pode usar o AWS AppSync como a camada de API para aproveitar os benefícios das APIs do GraphQL. As APIs do GraphQL oferecem busca de dados declarativa e eficiente usando uma definição de esquema digitado, armazenamento em cache de dados Serverless, sincronização de dados offline, segurança e controle de acesso refinado. Ele também fornece fontes de dados e resolvedores para escrever a lógica de negócios. Se você não precisar da camada de mutação, o AWS AppSync pode invocar diretamente um LLM no Amazon Bedrock. O tempo limite de integração do AWS AppSync é definido como 30 segundos por padrão e não pode ser estendido. Se você precisar realizar operações que possam levar mais tempo, considere implementar padrões assíncronos ou dividir a operação em partes menores. Para ver um exemplo de integração, consulte Invoke Amazon Bedrock models from AWS AppSync HTTP resolver. O diagrama a seguir ilustra a arquitetura da solução.
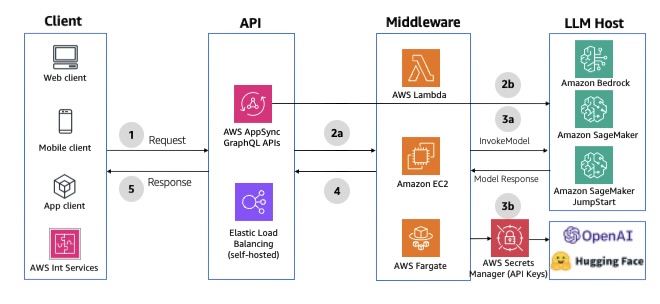
Figura 3: APIs HTTP síncronas do GraphQL usando o AWS AppSync
Interface conversacional de chatbot
O Amazon Lex é um serviço para criar interfaces conversacionais com voz e texto, oferecendo recursos de reconhecimento de fala e compreensão da linguagem. Ele simplifica o desenvolvimento multimodal e permite a publicação de chatbots em vários serviços de bate-papo e dispositivos móveis. Ele oferece integração nativa com o Lambda para agilizar o desenvolvimento de chatbots. Quando uma função Lambda é usada para atendimento, o tempo limite de resposta padrão é definido para 30 segundos. Para contornar, você pode usar as atualizações de cumprimento (fulfillment) para fornecer atualizações periódicas ao usuário, para que ele saiba que o chatbot ainda está atendendo à solicitação. Para ver um exemplo de implementação, consulte Aprimorar o Amazon Connect e o Lex com recursos generativos de IA. O diagrama a seguir ilustra a arquitetura da solução.
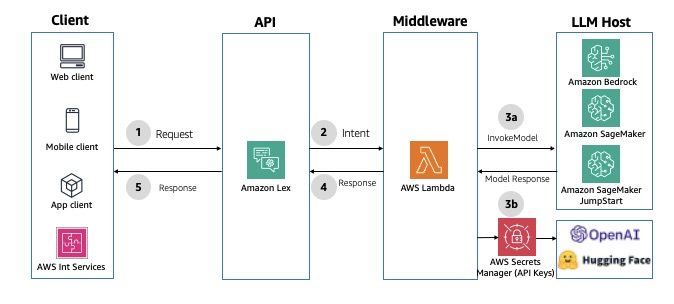
Figura 4: APIs conversacionais síncronas usando o Amazon Lex
Invocação de modelo usando orquestração
O AWS Step Functions permite a orquestração e a coordenação de várias tarefas, com integrações nativas nos serviços da AWS, como Amazon API Gateway, AWS Lambda e Amazon DynamoDB. O AWS Step Functions oferece recursos integrados, como orquestração de funções, ramificação, tratamento de erros, processamento paralelo e recursos humanos-in-the-loop. Ele também tem uma integração otimizada com o Amazon Bedrock, permitindo a invocação direta de FMs do Amazon Bedrock a partir dos fluxos de trabalho do AWS Step Functions. Com essa integração, você pode realizar o seguinte:
- Enriqueça o processamento de dados do Step Functions com recursos generativos de IA para tarefas como resumo de texto, geração de imagens ou personalização
- Recupere e injete dados atualizados (como preços de produtos ou perfis de usuário) nos prompts do LLM para maior precisão
- Organize LLM e chamadas de agentes em uma cadeia de processamento personalizada, usando os modelos mais adequados em cada estágio
- Implemente interações humanas-in-the-loop para moderar as respostas e lidar com as alucinações da FM
Para ver um exemplo de implementação usando o API Gateway, consulte Prompt chaining with Amazon API Gateway and AWS Step Functions. Para ver um exemplo de implementação usando o AWS AppSync, consulte Prompt chaining with AWS AppSync, AWS Step Functions and Amazon Bedrock. O diagrama a seguir ilustra um exemplo de arquitetura.
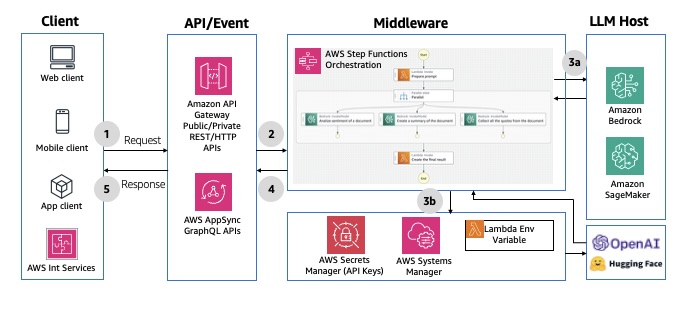
Figura 5: Invocações de modelo síncrono usando o AWS Step Functions
Padrão 2: resposta de solicitação assíncrona
Esse padrão fornece um canal de comunicação bidirecional full-duplex entre o cliente e o servidor sem que os clientes precisem esperar por atualizações. As maiores vantagens são sua natureza sem bloqueio, que pode lidar com operações de longa duração. No entanto, eles são mais complexos de implementar porque exigem gerenciamento de canais, mensagens e estados. Esse modelo pode ser implementado por meio de duas abordagens arquitetônicas.
APIs do WebSocket
O protocolo WebSocket permite a comunicação síncrona em tempo real entre o frontend e o middleware, permitindo mensagens bidirecionais e full-duplex por meio de uma conexão TCP persistente. Esse comportamento bidirecional aprimora as interações cliente/serviço, permitindo que os serviços enviem dados aos clientes sem exigir solicitações explícitas. Usando o API Gateway, você pode criar APIs do WebSocket como frontend com estado para um serviço da AWS (como Lambda ou DynamoDB) ou para um endpoint HTTP. A API WebSocket invoca seu backend com base no conteúdo das mensagens que recebe dos aplicativos clientes. Depois que a mensagem é gerada, o backend pode enviar mensagens de retorno de chamada para clientes conectados. Cada ciclo de solicitação-resposta deve ser concluído em 29 segundos, conforme definido pelo tempo limite de integração do API Gateway para WebSockets. A duração da conexão das APIs do API Gateway WebSocket pode ser de até 2 horas, com um tempo limite de conexão ociosa de 10 minutos. Elas não podem ser estendidas. Para ver um exemplo de implementação, consulte AI Chat with Amazon API Gateway (WebSockets), AWS Lambda and Amazon Bedrock. O diagrama a seguir ilustra um exemplo de arquitetura.
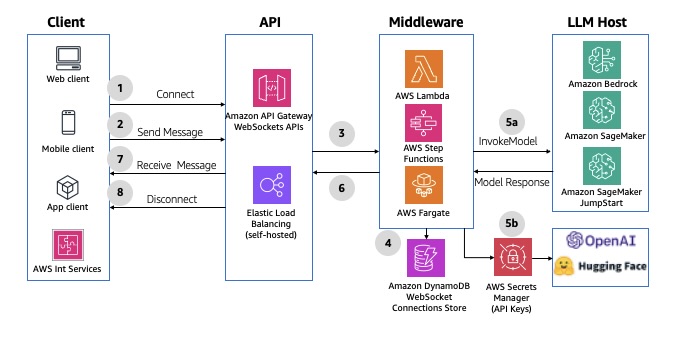
Figura 6: APIs assíncronas do WebSocket usando o Amazon API Gateway
APIs do GraphQL WebSocket
O AWS AppSync pode estabelecer e manter conexões seguras do WebSocket para operações de assinatura do GraphQL, permitindo que aplicativos de middleware distribuam dados em tempo real de fontes de dados para assinantes. Ele também oferece suporte a um modelo simples de publicação e assinatura, no qual os frontends do cliente podem ouvir canais ou tópicos específicos, com o AWS AppSync gerenciando vários canais pub/sub temporários e conexões WebSocket para fornecer e filtrar dados com base no nome do canal. Para ver um exemplo de implementação, consulte AI Chat with AWS AppSync (WebSockets), AWS Lambda, and Amazon Bedrock. O diagrama a seguir ilustra um exemplo de arquitetura.
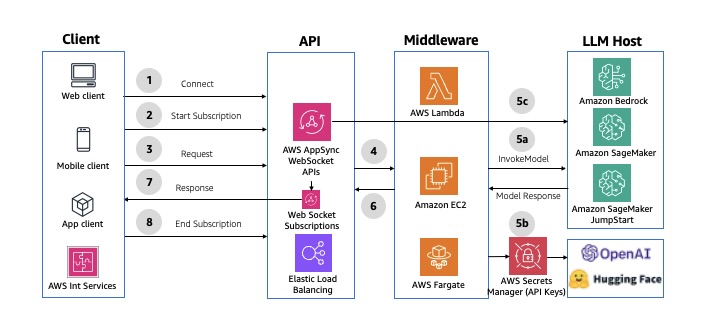
Figura 7: APIs assíncronas do GraphQL WebSocket usando a AWS
Padrão 3: resposta de streaming assíncrona
Esse padrão de streaming permite o fluxo de resposta em tempo real para os clientes em partes, aprimorando a experiência do usuário e minimizando a latência da primeira resposta. Esse padrão usa recursos de streaming integrados em serviços como Amazon Bedrock (APIs InvokeModelWithResponseStream ou ConverseStream) e inferência em tempo real do SageMaker, permitindo que os aplicativos exibam resultados de forma incremental em vez de esperar por respostas completas. Esse padrão é particularmente eficaz para aplicativos que implementam a modalidade de texto, como interfaces de bate-papo e ferramentas de geração de conteúdo baseadas em palavras.
A implementação é obtida por meio do WebSocket API do API Gateway ou APIs do AWS AppSync WebSocket ou assinaturas do GraphQL, considerando cuidadosamente o gerenciamento do tempo limite e o tratamento da conexão.
O diagrama a seguir ilustra a arquitetura do streaming assíncrono usando as APIs do API Gateway WebSocket.
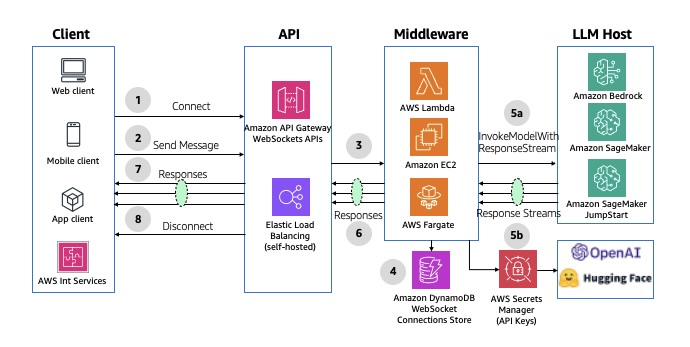
Figura 8: Resposta de streaming assíncrono usando as APIs do Amazon API Gateway WebSockets
O diagrama a seguir ilustra a arquitetura do streaming assíncrono usando as APIs do AWS AppSync WebSocket
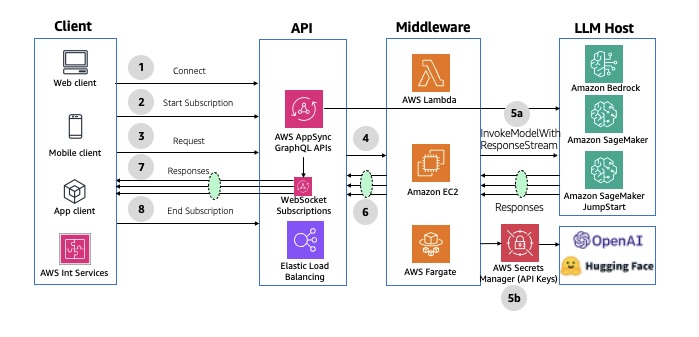
Figura 9: Resposta de streaming assíncrona usando as APIs do AWS AppSync WebSocket
Se você não precisa de uma camada de API, o streaming de resposta do Lambda permite que uma função do Lambda transmita progressivamente as cargas de resposta de volta aos clientes. Para obter mais detalhes, consulte Como usar o Amazon Bedrock com o AWS Lambda. O diagrama a seguir ilustra essa arquitetura.
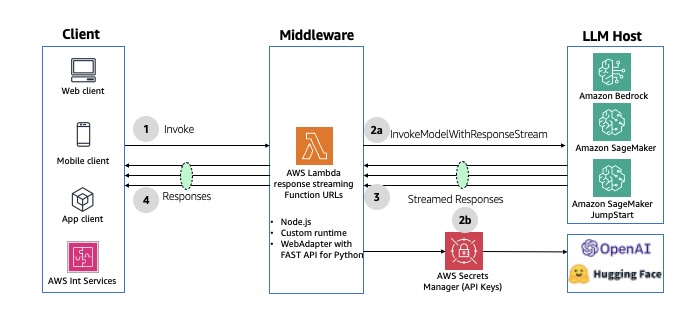
Figura 10: Resposta assíncrona usando streaming de respostas do AWS Lambda
Conclusão
Esta publicação apresentou três padrões de design aplicáveis a aplicativos de IA generativa em tempo real: resposta de solicitação síncrona, resposta de solicitação assíncrona e resposta de streaming assíncrona. Também destacamos como implementar esses padrões usando os serviços Serverless da AWS. Ao selecionar um padrão apropriado para sua implementação, é fundamental considerar a experiência prevista do usuário final, o conjunto técnico existente, as cotas de serviços da AWS e a latência das respostas do LLM. Na Parte 2, discutimos padrões para criar implementações de IA generativa orientada por lotes usando os serviços Serverless da AWS.
Este conteúdo foi traduzido da postagem original do blog, que pode ser encontrada aqui.
Autores
 |
Michael Hume é arquiteto de soluções sênio na Amazon Web Services |
 |
Parnab Basa é sênior product acelerator SA na Amazon Web Services |
Tradutor
 |
Daniel Abib é Arquiteto de Soluções Sênior e Especialista em Amazon Bedrock na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e especialização em Machine Learning. Ele trabalha apoiando Startups, ajudando-os em sua jornada para a nuvem. |
Revisor
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |