Visão geral
Neste tutorial, aprenda a criar e automatizar fluxos de trabalho completos de machine learning (ML) usando o Amazon SageMaker Pipelines, o Amazon SageMaker Model Registry e o Amazon SageMaker Clarify.
Fácil de usar, o SageMaker Pipelines é o primeiro serviço de integração contínua e entrega contínua (CI/CD) com propósito específico para ML. Com o SageMaker Pipelines, é possível automatizar as diferentes etapas do fluxo de trabalho de ML, como carregamento de dados, transformação de dados, treinamento, ajuste, avaliação e implantação. O SageMaker Model Registry rastrear as versões do modelo, os metadados, como agrupamento de casos de uso, e referências das métricas de performance do modelo em um repositório central. Assim, é fácil escolher o modelo certo para implantação com base no que seus negócios necessitam. O Amazon SageMaker Clarify fornece maior visibilidade de seus dados e modelos de treinamento para poder identificar e limitar desvios, além de explicar as previsões.
Neste tutorial, você implementará um pipeline do SageMaker para desenvolver, treinar e implantar um modelo de classificação binária do XGBoost que prevê a probabilidade de uma solicitação de sinistro de seguro automotivo ser fraudulenta. Você usará um conjunto de dados de solicitações de sinistro automotivo que foi gerado sinteticamente. As entradas brutas são duas tabelas de dados de sinistros: uma tabela de solicitações e uma tabela de clientes. A tabela de solicitações contém uma coluna chamada fraud (fraude) para indicar se a solicitação foi fraudulenta ou não. Seu pipeline processará os dados brutos, criará conjuntos de dados de treinamento, validação e teste e desenvolverá e avaliará um modelo de classificação binária. Depois, usará o SageMaker Clarify para testar o desvio e a explicabilidade do modelo e, por fim, implantará o modelo para inferência.
O que você aprenderá
Neste guia, você vai:
- Criar e executar um pipeline do SageMaker para automatizar todo o ciclo de vida de ML
- Gerar previsões usando o modelo implantado
Pré-requisitos
Antes de iniciar este guia, você precisará de:
- Uma conta da AWS: caso ainda não tenha uma conta, siga o guia de conceitos básicos Setting Up Your AWS Environment (Configurar seu ambiente da AWS) para obter uma breve visão geral.
AWS Experience
Tempo para a conclusão
120 minutos
Custo para a conclusão
Consulte os preços do SageMaker para estimar o custo deste tutorial.
Requisitos
Você deve estar conectado a uma conta da AWS.
Serviços usados
Amazon SageMaker Studio, Amazon SageMaker Pipelines, Amazon SageMaker Clarify, Amazon SageMaker Model Registry
Data da última atualização
24 de junho de 2022
Implementação
Etapa 1: configurar o domínio do Amazon SageMaker Studio
Uma conta da AWS pode ter apenas um domínio do SageMaker Studio por região. Caso já tenha um domínio do SageMaker Studio na região Leste dos EUA (Norte da Virgínia), siga o guia de configuração do SageMaker Studio para fluxos de trabalho de ML para anexar as políticas do AWS IAM necessárias à conta do SageMaker Studio, ignore a Etapa 1 e vá diretamente para a Etapa 2.
Caso não tenha um domínio SageMaker Studio, continue com os passos da Etapa 1 para executar um modelo do AWS CloudFormation que cria um domínio do SageMaker Studio e adiciona as permissões necessárias para finalizar este tutorial.
Escolha o link da pilha do AWS CloudFormation. Esse link abre o console do AWS CloudFormation e cria seu domínio do SageMaker Studio e um usuário chamado studio-user. Também adiciona as permissões necessárias a sua conta do SageMaker Studio. No console do CloudFormation, confirme se US East (N. Virginia) (Leste dos EUA [Norte da Virgínia]) é a Region (Região) exibida no canto superior direito. O Stack name (Nome da pilha) deve ser CFN-SM-IM-Lambda-catalog e não poderá ser alterado. Essa pilha leva cerca de dez minutos para criar todos os recursos.
A pilha pressupõe que você já tenha uma VPC pública configurada na conta. Se você não tiver uma VPC pública, consulte VPC com uma única sub-rede pública para aprender a criar uma VPC pública.

Selecione I acknowledge that AWS CloudFormation might create IAM resources (Estou ciente de que o AWS CloudFormation pode criar recursos do IAM) e escolha Create stack (Criar pilha).

No painel do CloudFormation, escolha Stacks (Pilhas). A pilha leva cerca de dez minutos para ser criada. Quando a pilha é criada, o status da pilha é mudado de CREATE_IN_PROGRESS para CREATE_COMPLETE.

Etapa 2: configurar um bloco de anotações do SageMaker Studio e parametrizar o pipeline
Nesta etapa, você iniciará um novo bloco de anotações do SageMaker Studio e configura as variáveis do SageMaker necessárias para interagir com o Amazon Simple Storage Service (Amazon S3).
Insira SageMaker Studio na barra de pesquisa do Console da AWS e escolha SageMaker Studio. Escolha US East (N. Virginia) (Leste dos EUA [Norte da Virgínia]) na lista suspensa Region (Região) no canto superior direito do console.

Em Launch app (Iniciar aplicação), selecione Studio para abrir o SageMaker Studio usando o perfil studio-user.

Na barra de navegação do SageMaker Studio, escolha File (Arquivo), New (Novo), Notebook (Bloco de anotações).

Na caixa de diálogo Set up notebook environment (Configurar ambiente de bloco de anotações), em Image (Imagem), selecione Data Science (Ciência de dados). O kernel Python 3 é selecionado automaticamente. Escolha Select .

O kernel no canto superior direito do bloco de anotações agora deverá exibir Python 3 (Data Science) (Ciência de dados).

Para importar as bibliotecas necessárias, copie e cole o código a seguir em uma célula em seu bloco de anotações e execute a célula.
import pandas as pd
import json
import boto3
import pathlib
import io
import sagemaker
from sagemaker.deserializers import CSVDeserializer
from sagemaker.serializers import CSVSerializer
from sagemaker.xgboost.estimator import XGBoost
from sagemaker.sklearn.processing import SKLearnProcessor
from sagemaker.processing import (
ProcessingInput,
ProcessingOutput,
ScriptProcessor
)
from sagemaker.inputs import TrainingInput
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.steps import (
ProcessingStep,
TrainingStep,
CreateModelStep
)
from sagemaker.workflow.check_job_config import CheckJobConfig
from sagemaker.workflow.parameters import (
ParameterInteger,
ParameterFloat,
ParameterString,
ParameterBoolean
)
from sagemaker.workflow.clarify_check_step import (
ModelBiasCheckConfig,
ClarifyCheckStep,
ModelExplainabilityCheckConfig
)
from sagemaker.workflow.step_collections import RegisterModel
from sagemaker.workflow.conditions import ConditionGreaterThanOrEqualTo
from sagemaker.workflow.properties import PropertyFile
from sagemaker.workflow.condition_step import ConditionStep
from sagemaker.workflow.functions import JsonGet
from sagemaker.workflow.lambda_step import (
LambdaStep,
LambdaOutput,
LambdaOutputTypeEnum,
)
from sagemaker.lambda_helper import Lambda
from sagemaker.model_metrics import (
MetricsSource,
ModelMetrics,
FileSource
)
from sagemaker.drift_check_baselines import DriftCheckBaselines
from sagemaker.image_uris import retrieveCopie e cole o bloco de código a seguir em uma célula e execute para configurar o SageMaker e os objetos de cliente do S3 usando o SageMaker e os AWS SDKs. Esses objetos são necessários para permitir que o SageMaker execute várias ações, como implantar e invocar endpoints, e interagir com o Amazon S3 e o AWS Lambda. O código também configura a localização dos buckets do S3 onde os conjuntos de dados brutos e processados e os artefatos de modelo são armazenados. Os buckets de leitura e de gravação são separados. O bucket de leitura é o bucket público do S3 chamado sagemaker-sample-files, que contém os conjuntos de dados brutos. O bucket de gravação é o bucket do S3 padrão associado à sua conta chamado sagemaker-<your- Region>-<your-account-id> e será usado posteriormente neste tutorial para armazenar os conjuntos de dados processados e os artefatos.
# Instantiate AWS services session and client objects
sess = sagemaker.Session()
write_bucket = sess.default_bucket()
write_prefix = "fraud-detect-demo"
region = sess.boto_region_name
s3_client = boto3.client("s3", region_name=region)
sm_client = boto3.client("sagemaker", region_name=region)
sm_runtime_client = boto3.client("sagemaker-runtime")
# Fetch SageMaker execution role
sagemaker_role = sagemaker.get_execution_role()
# S3 locations used for parameterizing the notebook run
read_bucket = "sagemaker-sample-files"
read_prefix = "datasets/tabular/synthetic_automobile_claims"
# S3 location where raw data to be fetched from
raw_data_key = f"s3://{read_bucket}/{read_prefix}"
# S3 location where processed data to be uploaded
processed_data_key = f"{write_prefix}/processed"
# S3 location where train data to be uploaded
train_data_key = f"{write_prefix}/train"
# S3 location where validation data to be uploaded
validation_data_key = f"{write_prefix}/validation"
# S3 location where test data to be uploaded
test_data_key = f"{write_prefix}/test"
# Full S3 paths
claims_data_uri = f"{raw_data_key}/claims.csv"
customers_data_uri = f"{raw_data_key}/customers.csv"
output_data_uri = f"s3://{write_bucket}/{write_prefix}/"
scripts_uri = f"s3://{write_bucket}/{write_prefix}/scripts"
estimator_output_uri = f"s3://{write_bucket}/{write_prefix}/training_jobs"
processing_output_uri = f"s3://{write_bucket}/{write_prefix}/processing_jobs"
model_eval_output_uri = f"s3://{write_bucket}/{write_prefix}/model_eval"
clarify_bias_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/bias_config"
clarify_explainability_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/explainability_config"
bias_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/bias"
explainability_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/explainability"
# Retrieve training image
training_image = retrieve(framework="xgboost", region=region, version="1.3-1")Copie e cole o código a seguir para definir o nome dos vários componentes do pipeline do SageMaker, como o modelo e o endpoint, e especifique os tipos e contagens de instâncias de treinamento e inferência. Esses valores serão usados para parametrizar o pipeline.
# Set names of pipeline objects
pipeline_name = "FraudDetectXGBPipeline"
pipeline_model_name = "fraud-detect-xgb-pipeline"
model_package_group_name = "fraud-detect-xgb-model-group"
base_job_name_prefix = "fraud-detect"
endpoint_config_name = f"{pipeline_model_name}-endpoint-config"
endpoint_name = f"{pipeline_model_name}-endpoint"
# Set data parameters
target_col = "fraud"
# Set instance types and counts
process_instance_type = "ml.c5.xlarge"
train_instance_count = 1
train_instance_type = "ml.m4.xlarge"
predictor_instance_count = 1
predictor_instance_type = "ml.m4.xlarge"
clarify_instance_count = 1
clarify_instance_type = "ml.m4.xlarge"O SageMaker Pipelines oferece suporte à parametrização, o que permite especificar parâmetros de entrada no tempo de execução sem alterar o código do pipeline. Você pode usar os módulos disponíveis no módulo sagemaker.workflow.parameters, como ParameterInteger, ParameterFloat, ParameterString e ParameterBoolean, para especificar os parâmetros de pipeline de vários tipos de dados. Copie, cole e execute o código a seguir para configurar vários parâmetros de entrada, inclusive configurações do SageMaker Clarify.
# Set up pipeline input parameters
# Set processing instance type
process_instance_type_param = ParameterString(
name="ProcessingInstanceType",
default_value=process_instance_type,
)
# Set training instance type
train_instance_type_param = ParameterString(
name="TrainingInstanceType",
default_value=train_instance_type,
)
# Set training instance count
train_instance_count_param = ParameterInteger(
name="TrainingInstanceCount",
default_value=train_instance_count
)
# Set deployment instance type
deploy_instance_type_param = ParameterString(
name="DeployInstanceType",
default_value=predictor_instance_type,
)
# Set deployment instance count
deploy_instance_count_param = ParameterInteger(
name="DeployInstanceCount",
default_value=predictor_instance_count
)
# Set Clarify check instance type
clarify_instance_type_param = ParameterString(
name="ClarifyInstanceType",
default_value=clarify_instance_type,
)
# Set model bias check params
skip_check_model_bias_param = ParameterBoolean(
name="SkipModelBiasCheck",
default_value=False
)
register_new_baseline_model_bias_param = ParameterBoolean(
name="RegisterNewModelBiasBaseline",
default_value=False
)
supplied_baseline_constraints_model_bias_param = ParameterString(
name="ModelBiasSuppliedBaselineConstraints",
default_value=""
)
# Set model explainability check params
skip_check_model_explainability_param = ParameterBoolean(
name="SkipModelExplainabilityCheck",
default_value=False
)
register_new_baseline_model_explainability_param = ParameterBoolean(
name="RegisterNewModelExplainabilityBaseline",
default_value=False
)
supplied_baseline_constraints_model_explainability_param = ParameterString(
name="ModelExplainabilitySuppliedBaselineConstraints",
default_value=""
)
# Set model approval param
model_approval_status_param = ParameterString(
name="ModelApprovalStatus", default_value="Approved"
)Etapa 3: desenvolver componentes de pipeline
O pipeline é uma sequência de etapas que podem ser desenvolvidas individualmente e depois agrupadas para formar um fluxo de trabalho de ML. O diagrama a seguir mostra as etapas de alto nível de um pipeline.
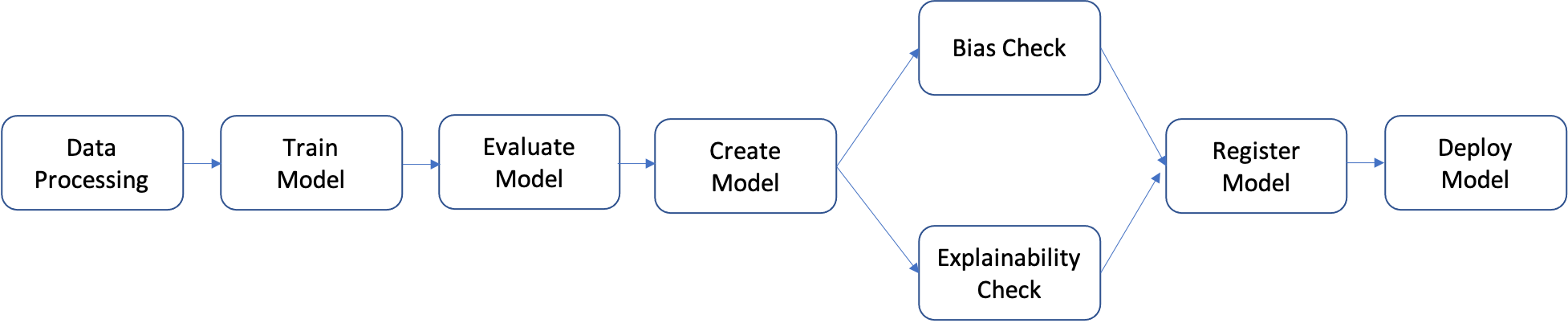
Neste tutorial, você criará um pipeline com estas etapas:
- Etapa de processamento de dados: executa um trabalho do SageMaker Processing usando os dados brutos de entrada no S3 e gera divisões de treinamento, validação e teste para o S3.
- Etapa de treinamento: treina um modelo do XGBoost usando trabalhos de treinamento do SageMaker com dados de treinamento e validação no S3 como entradas e armazena o artefato do modelo treinado no S3.
- Etapa de avaliação: avalia o modelo no conjunto de dados de teste executando um trabalho do SageMaker Processing usando os dados de teste e o artefato do modelo no S3 como entradas e armazena o relatório de avaliação de perfomance do modelo de saída no S3.
- Etapa condicional: compara a performance do modelo no conjunto de dados de teste com o limite. Executa uma etapa predefinida do SageMaker Pipelines usando o relatório de avaliação de performance do modelo no S3 como entrada e armazena a lista de saída das etapas do pipeline que serão executadas, caso a performance do modelo seja aceitável.
- Etapa de criação de modelo: executa uma etapa predefinida do SageMaker Pipelines usando o artefato de modelo no S3 como entrada e armazena o modelo de saída do SageMaker no S3.
- Etapa de verificação de desvio: verifica o desvio do modelo usando o SageMaker Clarify com os dados de treinamento e o artefato do modelo no S3 como entradas e armazena o relatório de desvio do modelo e as métricas de referência no S3.
- Etapa de explicabilidade do modelo: executa o desvio do modelo usando o SageMaker Clarify com os dados de treinamento e o artefato do modelo no S3 como entradas e armazena o relatório de explicabilidade do modelo e as métricas de referência no S3.
- Etapa de registro: executa uma etapa predefinida do SageMaker Pipelines usando as métricas de referência de modelo, desvio e explicabilidade como entradas para registrar o modelo no SageMaker Model Registry.
- Etapa de implantação: executa uma etapa predefinida do SageMaker Pipelines usando uma função de manipulador do AWS Lambda, o modelo e a configuração de endpoint como entradas para implantar o modelo em um endpoint do SageMaker Real-Time Inference.
O SageMaker Pipelines fornece muitos tipos de etapas predefinidas, como etapas para processamento de dados, treinamento de modelo, ajuste de modelo e transformação em lote. Para obter mais informações, consulte Pipeline Steps (Etapas de pipeline) no Guia do desenvolvedor do Amazon SageMaker. Nas etapas a seguir, você configurá e definirá cada etapa do pipeline individualmente. Depois, definirá o próprio pipeline combinando as etapas do pipeline com os parâmetros de entrada.
Etapa de processamento de dados: nesta etapa, você preparará um script Python para ingerir arquivos brutos; realizar processamentos como entrada de valores ausentes e engenharia de recursos; e selecionar as divisões de treinamento, validação e teste a serem usadas para desenvolver o modelo. Copie, cole e execute o código a seguir para criar seu script de processamento.
%%writefile preprocessing.py
import argparse
import pathlib
import boto3
import os
import pandas as pd
import logging
from sklearn.model_selection import train_test_split
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--train-ratio", type=float, default=0.8)
parser.add_argument("--validation-ratio", type=float, default=0.1)
parser.add_argument("--test-ratio", type=float, default=0.1)
args, _ = parser.parse_known_args()
logger.info("Received arguments {}".format(args))
# Set local path prefix in the processing container
local_dir = "/opt/ml/processing"
input_data_path_claims = os.path.join("/opt/ml/processing/claims", "claims.csv")
input_data_path_customers = os.path.join("/opt/ml/processing/customers", "customers.csv")
logger.info("Reading claims data from {}".format(input_data_path_claims))
df_claims = pd.read_csv(input_data_path_claims)
logger.info("Reading customers data from {}".format(input_data_path_customers))
df_customers = pd.read_csv(input_data_path_customers)
logger.debug("Formatting column names.")
# Format column names
df_claims = df_claims.rename({c : c.lower().strip().replace(' ', '_') for c in df_claims.columns}, axis = 1)
df_customers = df_customers.rename({c : c.lower().strip().replace(' ', '_') for c in df_customers.columns}, axis = 1)
logger.debug("Joining datasets.")
# Join datasets
df_data = df_claims.merge(df_customers, on = 'policy_id', how = 'left')
# Drop selected columns not required for model building
df_data = df_data.drop(['customer_zip'], axis = 1)
# Select Ordinal columns
ordinal_cols = ["police_report_available", "policy_liability", "customer_education"]
# Select categorical columns and filling with na
cat_cols_all = list(df_data.select_dtypes('object').columns)
cat_cols = [c for c in cat_cols_all if c not in ordinal_cols]
df_data[cat_cols] = df_data[cat_cols].fillna('na')
logger.debug("One-hot encoding categorical columns.")
# One-hot encoding categorical columns
df_data = pd.get_dummies(df_data, columns = cat_cols)
logger.debug("Encoding ordinal columns.")
# Ordinal encoding
mapping = {
"Yes": "1",
"No": "0"
}
df_data['police_report_available'] = df_data['police_report_available'].map(mapping)
df_data['police_report_available'] = df_data['police_report_available'].astype(float)
mapping = {
"15/30": "0",
"25/50": "1",
"30/60": "2",
"100/200": "3"
}
df_data['policy_liability'] = df_data['policy_liability'].map(mapping)
df_data['policy_liability'] = df_data['policy_liability'].astype(float)
mapping = {
"Below High School": "0",
"High School": "1",
"Associate": "2",
"Bachelor": "3",
"Advanced Degree": "4"
}
df_data['customer_education'] = df_data['customer_education'].map(mapping)
df_data['customer_education'] = df_data['customer_education'].astype(float)
df_processed = df_data.copy()
df_processed.columns = [c.lower() for c in df_data.columns]
df_processed = df_processed.drop(["policy_id", "customer_gender_unkown"], axis=1)
# Split into train, validation, and test sets
train_ratio = args.train_ratio
val_ratio = args.validation_ratio
test_ratio = args.test_ratio
logger.debug("Splitting data into train, validation, and test sets")
y = df_processed['fraud']
X = df_processed.drop(['fraud'], axis = 1)
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=test_ratio, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=val_ratio, random_state=42)
train_df = pd.concat([y_train, X_train], axis = 1)
val_df = pd.concat([y_val, X_val], axis = 1)
test_df = pd.concat([y_test, X_test], axis = 1)
dataset_df = pd.concat([y, X], axis = 1)
logger.info("Train data shape after preprocessing: {}".format(train_df.shape))
logger.info("Validation data shape after preprocessing: {}".format(val_df.shape))
logger.info("Test data shape after preprocessing: {}".format(test_df.shape))
# Save processed datasets to the local paths in the processing container.
# SageMaker will upload the contents of these paths to S3 bucket
logger.debug("Writing processed datasets to container local path.")
train_output_path = os.path.join(f"{local_dir}/train", "train.csv")
validation_output_path = os.path.join(f"{local_dir}/val", "validation.csv")
test_output_path = os.path.join(f"{local_dir}/test", "test.csv")
full_processed_output_path = os.path.join(f"{local_dir}/full", "dataset.csv")
logger.info("Saving train data to {}".format(train_output_path))
train_df.to_csv(train_output_path, index=False)
logger.info("Saving validation data to {}".format(validation_output_path))
val_df.to_csv(validation_output_path, index=False)
logger.info("Saving test data to {}".format(test_output_path))
test_df.to_csv(test_output_path, index=False)
logger.info("Saving full processed data to {}".format(full_processed_output_path))
dataset_df.to_csv(full_processed_output_path, index=False)
Em seguida, copie, cole e execute o bloco de código a seguir para criar uma instância do processador e a etapa SageMaker Pipelines para executar o script de processamento. Como o script de processamento é escrito em Pandas, utilize um SKLearnProcessor. A função ProcessingStep do SageMaker Pipelines recebe os seguintes argumentos: o processador, os locais de entrada do S3 para conjuntos de dados brutos e os locais de saída do S3 para salvar conjuntos de dados processados. Outros argumentos, como proporções de divisão de treinamento, validação e teste, são fornecidos pelo argumento job_arguments.
from sagemaker.workflow.pipeline_context import PipelineSession
# Upload processing script to S3
s3_client.upload_file(
Filename="preprocessing.py", Bucket=write_bucket, Key=f"{write_prefix}/scripts/preprocessing.py"
)
# Define the SKLearnProcessor configuration
sklearn_processor = SKLearnProcessor(
framework_version="0.23-1",
role=sagemaker_role,
instance_count=1,
instance_type=process_instance_type,
base_job_name=f"{base_job_name_prefix}-processing",
)
# Define pipeline processing step
process_step = ProcessingStep(
name="DataProcessing",
processor=sklearn_processor,
inputs=[
ProcessingInput(source=claims_data_uri, destination="/opt/ml/processing/claims"),
ProcessingInput(source=customers_data_uri, destination="/opt/ml/processing/customers")
],
outputs=[
ProcessingOutput(destination=f"{processing_output_uri}/train_data", output_name="train_data", source="/opt/ml/processing/train"),
ProcessingOutput(destination=f"{processing_output_uri}/validation_data", output_name="validation_data", source="/opt/ml/processing/val"),
ProcessingOutput(destination=f"{processing_output_uri}/test_data", output_name="test_data", source="/opt/ml/processing/test"),
ProcessingOutput(destination=f"{processing_output_uri}/processed_data", output_name="processed_data", source="/opt/ml/processing/full")
],
job_arguments=[
"--train-ratio", "0.8",
"--validation-ratio", "0.1",
"--test-ratio", "0.1"
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/preprocessing.py"
)Copie, cole e execute o bloco de código a seguir para preparar o script de treinamento. Esse script encapsula a lógica de treinamento para o classificador binário do XGBoost. Os hiperparâmetros usados no treinamento do modelo serão informados posteriormente no tutorial na definição da etapa de treinamento.
%%writefile xgboost_train.py
import argparse
import os
import joblib
import json
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Hyperparameters and algorithm parameters are described here
parser.add_argument("--num_round", type=int, default=100)
parser.add_argument("--max_depth", type=int, default=3)
parser.add_argument("--eta", type=float, default=0.2)
parser.add_argument("--subsample", type=float, default=0.9)
parser.add_argument("--colsample_bytree", type=float, default=0.8)
parser.add_argument("--objective", type=str, default="binary:logistic")
parser.add_argument("--eval_metric", type=str, default="auc")
parser.add_argument("--nfold", type=int, default=3)
parser.add_argument("--early_stopping_rounds", type=int, default=3)
# SageMaker specific arguments. Defaults are set in the environment variables
# Set location of input training data
parser.add_argument("--train_data_dir", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
# Set location of input validation data
parser.add_argument("--validation_data_dir", type=str, default=os.environ.get("SM_CHANNEL_VALIDATION"))
# Set location where trained model will be stored. Default set by SageMaker, /opt/ml/model
parser.add_argument("--model_dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
# Set location where model artifacts will be stored. Default set by SageMaker, /opt/ml/output/data
parser.add_argument("--output_data_dir", type=str, default=os.environ.get("SM_OUTPUT_DATA_DIR"))
args = parser.parse_args()
data_train = pd.read_csv(f"{args.train_data_dir}/train.csv")
train = data_train.drop("fraud", axis=1)
label_train = pd.DataFrame(data_train["fraud"])
dtrain = xgb.DMatrix(train, label=label_train)
data_validation = pd.read_csv(f"{args.validation_data_dir}/validation.csv")
validation = data_validation.drop("fraud", axis=1)
label_validation = pd.DataFrame(data_validation["fraud"])
dvalidation = xgb.DMatrix(validation, label=label_validation)
# Choose XGBoost model hyperparameters
params = {"max_depth": args.max_depth,
"eta": args.eta,
"objective": args.objective,
"subsample" : args.subsample,
"colsample_bytree":args.colsample_bytree
}
num_boost_round = args.num_round
nfold = args.nfold
early_stopping_rounds = args.early_stopping_rounds
# Cross-validate train XGBoost model
cv_results = xgb.cv(
params=params,
dtrain=dtrain,
num_boost_round=num_boost_round,
nfold=nfold,
early_stopping_rounds=early_stopping_rounds,
metrics=["auc"],
seed=42,
)
model = xgb.train(params=params, dtrain=dtrain, num_boost_round=len(cv_results))
train_pred = model.predict(dtrain)
validation_pred = model.predict(dvalidation)
train_auc = roc_auc_score(label_train, train_pred)
validation_auc = roc_auc_score(label_validation, validation_pred)
print(f"[0]#011train-auc:{train_auc:.2f}")
print(f"[0]#011validation-auc:{validation_auc:.2f}")
metrics_data = {"hyperparameters" : params,
"binary_classification_metrics": {"validation:auc": {"value": validation_auc},
"train:auc": {"value": train_auc}
}
}
# Save the evaluation metrics to the location specified by output_data_dir
metrics_location = args.output_data_dir + "/metrics.json"
# Save the trained model to the location specified by model_dir
model_location = args.model_dir + "/xgboost-model"
with open(metrics_location, "w") as f:
json.dump(metrics_data, f)
with open(model_location, "wb") as f:
joblib.dump(model, f)Configure o treinamento do modelo usando um estimador XGBoost do SageMaker e a função SageMaker Pipelines TrainingStep.
# Set XGBoost model hyperparameters
hyperparams = {
"eval_metric" : "auc",
"objective": "binary:logistic",
"num_round": "5",
"max_depth":"5",
"subsample":"0.75",
"colsample_bytree":"0.75",
"eta":"0.5"
}
# Set XGBoost estimator
xgb_estimator = XGBoost(
entry_point="xgboost_train.py",
output_path=estimator_output_uri,
code_location=estimator_output_uri,
hyperparameters=hyperparams,
role=sagemaker_role,
# Fetch instance type and count from pipeline parameters
instance_count=train_instance_count,
instance_type=train_instance_type,
framework_version="1.3-1"
)
# Access the location where the preceding processing step saved train and validation datasets
# Pipeline step properties can give access to outputs which can be used in succeeding steps
s3_input_train = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
s3_input_validation = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["validation_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
# Set pipeline training step
train_step = TrainingStep(
name="XGBModelTraining",
estimator=xgb_estimator,
inputs={
"train":s3_input_train, # Train channel
"validation": s3_input_validation # Validation channel
}
)Copie, cole e execute o bloco de código a seguir, que será usado para criar um modelo do SageMaker usando a função CreateModelStep do SageMaker Pipelines. Essa etapa utiliza a saída da etapa de treinamento para empacotar o modelo para implantação. O valor do argumento do tipo de instância é transmitido usando o parâmetro SageMaker Pipelines que você definiu anteriormente no tutorial.
# Create a SageMaker model
model = sagemaker.model.Model(
image_uri=training_image,
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
sagemaker_session=sess,
role=sagemaker_role
)
# Specify model deployment instance type
inputs = sagemaker.inputs.CreateModelInput(instance_type=deploy_instance_type_param)
create_model_step = CreateModelStep(name="FraudDetModel", model=model, inputs=inputs)Em um fluxo de trabalho de ML, é importante avaliar o modelo treinado para detectar desvios em potencial e entender como os vários recursos dos dados de entrada afetam a previsão do modelo. O SageMaker Pipelines fornece uma função ClarifyCheckStep que pode ser usada para realizar três tipos de verificações: verificação de desvio de dados (pré-treinamento), verificação de desvio de modelo (pós-treinamento) e verificação de explicabilidade do modelo. Para reduzir o tempo de execução, neste tutorial, você implementará apenas verificações de desvio e de explicabilidade. Copie, cole e execute bloco de código a seguir para configurar o SageMaker Clarify para verificação de desvio de modelo. Esta etapa coleta ativos, como os dados de treinamento e o modelo do SageMaker criado nas etapas anteriores, por meio do atributo properties. Quando o pipeline é executado, esta etapa só é iniciada depois que as etapas que fornecem as entradas terminam de ser executadas. Para obter mais detalhes, consulte Data Dependency Between Steps (Dependência de dados entre etapas) no Guia do desenvolvedor do Amazon SageMaker. Para gerenciar os custos e o tempo de execução do tutorial, a função ModelBiasCheckConfig é configurada para calcular apenas uma métrica de desvio: DPPL. Para obter mais informações sobre as métricas de desvio disponíveis no SageMaker Clarify, consulte Measure Posttraining Data and Model Bias (Medir dados de pós-treinamento e desvio de modelo) no Guia do desenvolvedor do Amazon SageMaker.
# Set up common configuration parameters to be used across multiple steps
check_job_config = CheckJobConfig(
role=sagemaker_role,
instance_count=1,
instance_type=clarify_instance_type,
volume_size_in_gb=30,
sagemaker_session=sess,
)
# Set up configuration of data to be used for model bias check
model_bias_data_config = sagemaker.clarify.DataConfig(
# Fetch S3 location where processing step saved train data
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=bias_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_bias_config_output_uri
)
# Set up details of the trained model to be checked for bias
model_config = sagemaker.clarify.ModelConfig(
# Pull model name from model creation step
model_name=create_model_step.properties.ModelName,
instance_count=train_instance_count,
instance_type=train_instance_type
)
# Set up column and categories that are to be checked for bias
model_bias_config = sagemaker.clarify.BiasConfig(
label_values_or_threshold=[0],
facet_name="customer_gender_female",
facet_values_or_threshold=[1]
)
# Set up model predictions configuration to get binary labels from probabilities
model_predictions_config = sagemaker.clarify.ModelPredictedLabelConfig(probability_threshold=0.5)
model_bias_check_config = ModelBiasCheckConfig(
data_config=model_bias_data_config,
data_bias_config=model_bias_config,
model_config=model_config,
model_predicted_label_config=model_predictions_config,
methods=["DPPL"]
)
# Set up pipeline model bias check step
model_bias_check_step = ClarifyCheckStep(
name="ModelBiasCheck",
clarify_check_config=model_bias_check_config,
check_job_config=check_job_config,
skip_check=skip_check_model_bias_param,
register_new_baseline=register_new_baseline_model_bias_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_bias_param
)Copie, cole e execute o bloco de código a seguir para configurar as verificações de explicabilidade do modelo. Esta etapa fornece insights como a importância do recurso (de que maneira os recursos de entrada afetam as previsões do modelo).
# Set configuration of data to be used for model explainability check
model_explainability_data_config = sagemaker.clarify.DataConfig(
# Fetch S3 location where processing step saved train data
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=explainability_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_explainability_config_output_uri
)
# Set SHAP configuration for Clarify to compute global and local SHAP values for feature importance
shap_config = sagemaker.clarify.SHAPConfig(
seed=42,
num_samples=100,
agg_method="mean_abs",
save_local_shap_values=True
)
model_explainability_config = ModelExplainabilityCheckConfig(
data_config=model_explainability_data_config,
model_config=model_config,
explainability_config=shap_config
)
# Set pipeline model explainability check step
model_explainability_step = ClarifyCheckStep(
name="ModelExplainabilityCheck",
clarify_check_config=model_explainability_config,
check_job_config=check_job_config,
skip_check=skip_check_model_explainability_param,
register_new_baseline=register_new_baseline_model_explainability_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_explainability_param
)Em sistemas de produção, nem todos os modelos treinados são implantados. Normalmente, implantam-se apenas os modelos com performance melhor do que o limite para uma métrica de avaliação escolhida. Nesta etapa, você criará um script do Python que pontua o modelo em um conjunto de teste usando a métrica área sob a curva da característica de operação do receptor (ROC-AUC). A performance do modelo em relação a essa métrica é usada em uma etapa posterior para determinar se o modelo deverá ser registrado e implantado. Copie, cole e execute o código a seguir para criar um script de avaliação que ingere um conjunto de dados de teste e gera a métrica AUC.
%%writefile evaluate.py
import json
import logging
import pathlib
import pickle
import tarfile
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
if __name__ == "__main__":
model_path = "/opt/ml/processing/model/model.tar.gz"
with tarfile.open(model_path) as tar:
tar.extractall(path=".")
logger.debug("Loading xgboost model.")
# The name of the file should match how the model was saved in the training script
model = pickle.load(open("xgboost-model", "rb"))
logger.debug("Reading test data.")
test_local_path = "/opt/ml/processing/test/test.csv"
df_test = pd.read_csv(test_local_path)
# Extract test set target column
y_test = df_test.iloc[:, 0].values
cols_when_train = model.feature_names
# Extract test set feature columns
X = df_test[cols_when_train].copy()
X_test = xgb.DMatrix(X)
logger.info("Generating predictions for test data.")
pred = model.predict(X_test)
# Calculate model evaluation score
logger.debug("Calculating ROC-AUC score.")
auc = roc_auc_score(y_test, pred)
metric_dict = {
"classification_metrics": {"roc_auc": {"value": auc}}
}
# Save model evaluation metrics
output_dir = "/opt/ml/processing/evaluation"
pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True)
logger.info("Writing evaluation report with ROC-AUC: %f", auc)
evaluation_path = f"{output_dir}/evaluation.json"
with open(evaluation_path, "w") as f:
f.write(json.dumps(metric_dict))Em seguida, copie, cole e execute o bloco de código a seguir para criar uma instância do processador e a etapa SageMaker Pipelines para executar o script de avaliação. Para processar o script personalizado, use ScriptProcessor. A função ProcessingStep do SageMaker Pipelines usa estes argumentos: o processador, o local de entrada do S3 para o conjunto de dados de teste, o artefato do modelo e o local de saída para armazenar os resultados da avaliação. Além disso, é fornecido um argumento property_files. Utilize arquivos de propriedades para armazenar informações da saída da etapa de processamento, que nesse caso é um arquivo json com a métrica de performance do modelo. Como mostraremos posteriormente no tutorial, isso serve principalmente para determinar quando uma etapa condicional deve ser executada.
# Upload model evaluation script to S3
s3_client.upload_file(
Filename="evaluate.py", Bucket=write_bucket, Key=f"{write_prefix}/scripts/evaluate.py"
)
eval_processor = ScriptProcessor(
image_uri=training_image,
command=["python3"],
instance_type=predictor_instance_type,
instance_count=predictor_instance_count,
base_job_name=f"{base_job_name_prefix}-model-eval",
sagemaker_session=sess,
role=sagemaker_role,
)
evaluation_report = PropertyFile(
name="FraudDetEvaluationReport",
output_name="evaluation",
path="evaluation.json",
)
# Set model evaluation step
evaluation_step = ProcessingStep(
name="XGBModelEvaluate",
processor=eval_processor,
inputs=[
ProcessingInput(
# Fetch S3 location where train step saved model artifacts
source=train_step.properties.ModelArtifacts.S3ModelArtifacts,
destination="/opt/ml/processing/model",
),
ProcessingInput(
# Fetch S3 location where processing step saved test data
source=process_step.properties.ProcessingOutputConfig.Outputs["test_data"].S3Output.S3Uri,
destination="/opt/ml/processing/test",
),
],
outputs=[
ProcessingOutput(destination=f"{model_eval_output_uri}", output_name="evaluation", source="/opt/ml/processing/evaluation"),
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/evaluate.py",
property_files=[evaluation_report],
)Com o SageMaker Model Registry, é possível catalogar modelos, gerenciar versões de modelos e implantar modelos seletivamente para produção. Copie, cole e execute o bloco de código a seguir para configurar a etapa de registro do modelo. Os dois parâmetros, model_metrics e drift_check_baselines, contêm as métricas de referência calculadas anteriormente no tutorial pela função ClarifyCheckStep. Você também pode fornecer suas próprias métricas de referência personalizadas. A intenção por trás desses parâmetros é fornecer um modo de configurar as referências associadas a um modelo para que possam ser usadas em verificações de desvio e trabalhos de monitoramento de modelo. Sempre que um pipeline é executado, você pode atualizar esses parâmetros com referências recém-calculadas.
# Fetch baseline constraints to record in model registry
model_metrics = ModelMetrics(
bias_post_training=MetricsSource(
s3_uri=model_bias_check_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
explainability=MetricsSource(
s3_uri=model_explainability_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
)
# Fetch baselines to record in model registry for drift check
drift_check_baselines = DriftCheckBaselines(
bias_post_training_constraints=MetricsSource(
s3_uri=model_bias_check_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_constraints=MetricsSource(
s3_uri=model_explainability_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_config_file=FileSource(
s3_uri=model_explainability_config.monitoring_analysis_config_uri,
content_type="application/json",
),
)
# Define register model step
register_step = RegisterModel(
name="XGBRegisterModel",
estimator=xgb_estimator,
# Fetching S3 location where train step saved model artifacts
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=[predictor_instance_type],
transform_instances=[predictor_instance_type],
model_package_group_name=model_package_group_name,
approval_status=model_approval_status_param,
# Registering baselines metrics that can be used for model monitoring
model_metrics=model_metrics,
drift_check_baselines=drift_check_baselines
)Com o Amazon SageMaker, é possível implantar um modelo registrado para inferência de várias formas. Nesta etapa, você implantará o modelo usando a função LambdaStep. Em geral, você deve usar o SageMaker Projects para implantações de modelos robustos que seguem as práticas recomendadas de CI/CD. Porém, em algumas circunstâncias, convém usar o LambdaStep para implantações de modelos leves para desenvolvimento, teste e endpoints internos que atendem a baixos volumes de tráfego. A função LambdaStep fornece uma integração nativa com o AWS Lambda, e assim você pode implementar lógica personalizada em seu pipeline sem provisionar ou gerenciar servidores. No contexto do SageMaker Pipelines, o LambdaStep permite adicionar uma função do AWS Lambda aos pipelines para dar suporte a operações de computação arbitrárias, sobretudo operações leves de curta duração. Lembre-se de que, em um LambdaStep do SageMaker Pipelines, a função Lambda é limitada a dez minutos de tempo de execução máximo, com um tempo limite padrão modificável de dois minutos.
Há dois modos de adicionar um LambdaStep aos pipelines. Primeiro, forneça o ARN de uma função Lambda existente que você criou com o AWS Cloud Development Kit (AWS CDK), o Console de Gerenciamento da AWS ou de outra forma. Segundo, o SDK do SageMaker Python de alto nível tem uma classe de conveniência auxiliar do Lambda que pode ser usada para criar uma nova função Lambda junto com o outro código que define seu pipeline. Neste tutorial, você usará o segundo método. Copie, cole e execute o código a seguir para definir a função do manipulador do Lambda. Este é o script do Python personalizado que recebe atributos de modelo, como nome do modelo, e os implementa em um endpoint em tempo real.
%%writefile lambda_deployer.py
"""
Lambda function creates an endpoint configuration and deploys a model to real-time endpoint.
Required parameters for deployment are retrieved from the event object
"""
import json
import boto3
def lambda_handler(event, context):
sm_client = boto3.client("sagemaker")
# Details of the model created in the Pipeline CreateModelStep
model_name = event["model_name"]
model_package_arn = event["model_package_arn"]
endpoint_config_name = event["endpoint_config_name"]
endpoint_name = event["endpoint_name"]
role = event["role"]
instance_type = event["instance_type"]
instance_count = event["instance_count"]
primary_container = {"ModelPackageName": model_package_arn}
# Create model
model = sm_client.create_model(
ModelName=model_name,
PrimaryContainer=primary_container,
ExecutionRoleArn=role
)
# Create endpoint configuration
create_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"VariantName": "Alltraffic",
"ModelName": model_name,
"InitialInstanceCount": instance_count,
"InstanceType": instance_type,
"InitialVariantWeight": 1
}
]
)
# Create endpoint
create_endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)Copie, cole e execute o bloco de código a seguir para criar o LambdaStep. Todos os parâmetros, como modelo, nome do endpoint e tipo e contagem de instância de implantação, são fornecidos usando o argumento inputs.
# The function name must contain sagemaker
function_name = "sagemaker-fraud-det-demo-lambda-step"
# Define Lambda helper class can be used to create the Lambda function required in the Lambda step
func = Lambda(
function_name=function_name,
execution_role_arn=sagemaker_role,
script="lambda_deployer.py",
handler="lambda_deployer.lambda_handler",
timeout=600,
memory_size=10240,
)
# The inputs used in the lambda handler are passed through the inputs argument in the
# LambdaStep and retrieved via the `event` object within the `lambda_handler` function
lambda_deploy_step = LambdaStep(
name="LambdaStepRealTimeDeploy",
lambda_func=func,
inputs={
"model_name": pipeline_model_name,
"endpoint_config_name": endpoint_config_name,
"endpoint_name": endpoint_name,
"model_package_arn": register_step.steps[0].properties.ModelPackageArn,
"role": sagemaker_role,
"instance_type": deploy_instance_type_param,
"instance_count": deploy_instance_count_param
}
)Nesta etapa, você usará o ConditionStep para comparar a performance do modelo atual com base na métrica área sob a curva (AUC). Apenas se a performance for maior ou igual a um limite da AUC (o escolhido aqui foi 0,7), o pipeline realizará verificações de desvio e explicabilidade, registrará o modelo e o implantará. Etapas condicionais como esta auxiliam na implantação seletiva dos melhores modelos para produção. Copie, cole e execute o código a seguir para definir a etapa condicional.
# Evaluate model performance on test set
cond_gte = ConditionGreaterThanOrEqualTo(
left=JsonGet(
step_name=evaluation_step.name,
property_file=evaluation_report,
json_path="classification_metrics.roc_auc.value",
),
right=0.7, # Threshold to compare model performance against
)
condition_step = ConditionStep(
name="CheckFraudDetXGBEvaluation",
conditions=[cond_gte],
if_steps=[create_model_step, model_bias_check_step, model_explainability_step, register_step, lambda_deploy_step],
else_steps=[]
)Etapa 4: criar e executar o pipeline
Após definir todas as etapas do componente, você pode montá-las em um objeto SageMaker Pipelines. Não é necessário especificar a ordem da execução, pois o SageMaker Pipelines infere automaticamente a sequência de execução com base nas dependências entre as etapas.
Copie, cole e execute o código a seguir para configurar o pipeline. A definição do pipeline utiliza todos os parâmetros definidos na Etapa 2 e a lista de etapas do componente. Etapas como criação de modelo, verificações de desvio e de explicabilidade, registro de modelo e implantação do Lambda não são listadas na definição do pipeline porque só serão executadas se a etapa condicional for avaliada como verdadeira. Se a etapa condicional for verdadeira, as etapas subsequentes serão executadas em ordem, com base nas entradas e saídas especificadas.
# Create the Pipeline with all component steps and parameters
pipeline = Pipeline(
name=pipeline_name,
parameters=[process_instance_type_param,
train_instance_type_param,
train_instance_count_param,
deploy_instance_type_param,
deploy_instance_count_param,
clarify_instance_type_param,
skip_check_model_bias_param,
register_new_baseline_model_bias_param,
supplied_baseline_constraints_model_bias_param,
skip_check_model_explainability_param,
register_new_baseline_model_explainability_param,
supplied_baseline_constraints_model_explainability_param,
model_approval_status_param],
steps=[
process_step,
train_step,
evaluation_step,
condition_step
],
sagemaker_session=sess
)Copie, cole e execute o código a seguir em uma célula de seu bloco de anotações. Se o pipeline já existir, o código atualizará o pipeline. Se o pipeline não existir, ele criará um novo. Ignore alertas do SDK do SageMaker, como “No finished training job found associated with this estimator. Please make sure this estimator is only used for building workflow config” [Não foram encontrados trabalhos de treinamento concluídos associados a este estimador. Verifique se o estimador é usado apenas para criar o fluxo de trabalho config].
# Create a new or update existing Pipeline
pipeline.upsert(role_arn=sagemaker_role)
# Full Pipeline description
pipeline_definition = json.loads(pipeline.describe()['PipelineDefinition'])
pipeline_definitionO SageMaker codifica o pipeline em um grafo acíclico orientado (DAG), onde cada nó representa uma etapa, e as conexões entre os nós representam dependências. Para inspecionar o pipeline do DAG pela interface do SageMaker Studio, selecione a guia SageMaker Resources no painel esquerdo, selecione Pipelines na lista suspensa e escolha FraudDetectXGBPipeline, Graph (Grafo). Você verá que as etapas do pipeline que criou são representadas por nós no grafo, e as conexões entre os nós foram inferidas pelo SageMaker com base nas entradas e saídas fornecidas nas definições da etapa.

Execute o pipeline executando a seguinte instrução de código. Os parâmetros de execução do pipeline são fornecidos como argumentos nesta etapa. Acesse a guia SageMaker Resources no painel esquerdo, selecione Pipelines na lista suspensa e escolha FraudDetectXGBPipeline, Executions (Execuções). Lista-se a execução atual do pipeline.
# Execute Pipeline
start_response = pipeline.start(parameters=dict(
SkipModelBiasCheck=True,
RegisterNewModelBiasBaseline=True,
SkipModelExplainabilityCheck=True,
RegisterNewModelExplainabilityBaseline=True)
)
Para revisar a execução do pipeline, escolha a guia Status. Quando todas as etapas são executadas corretamente, os nós no grafo ficam verdes.

Na interface do SageMaker Studio, selecione a guia SageMaker Resources (Recursos do SageMaker) no painel esquerdo e escolha Model registry (Registro do modelo) na lista suspensa. O modelo registrado é listado em Model group name (Nome do grupo de modelos) no painel esquerdo. Selecione o nome do grupo de modelos para mostrar a lista de versões de modelos. Sempre que você executa o pipeline, será adicionada uma nova versão do modelo ao registro, se a versão do modelo atender ao limite condicional para avaliação. Escolha uma versão do modelo para ver detalhes, como o endpoint do modelo e o relatório de explicabilidade do modelo.

Etapa 5: testar o pipeline invocando o endpoint
Neste tutorial, o modelo atinge uma pontuação superior ao limite escolhido da AUC de 0,7. Portanto, a etapa condicional registra e implanta o modelo em um endpoint de inferência em tempo real.
Na interface do SageMaker Studio, selecione a guia SageMaker Resources no painel esquerdo, escolha Endpoints e aguarde até que o status de fraud-detect-xgb-pipeline-endpoint seja alterado para InService.

Depois que Endpoint status (Status do endpoint) é alterado para InService, copie, cole e execute o código a seguir para invocar o endpoint e executar inferências de amostra. O código retornará as previsões do modelo das cinco primeiras amostras do conjunto de dados de teste.
# Fetch test data to run predictions with the endpoint
test_df = pd.read_csv(f"{processing_output_uri}/test_data/test.csv")
# Create SageMaker Predictor from the deployed endpoint
predictor = sagemaker.predictor.Predictor(endpoint_name,
sagemaker_session=sess,
serializer=CSVSerializer(),
deserializer=CSVDeserializer()
)
# Test endpoint with payload of 5 samples
payload = test_df.drop(["fraud"], axis=1).iloc[:5]
result = predictor.predict(payload.values)
prediction_df = pd.DataFrame()
prediction_df["Prediction"] = result
prediction_df["Label"] = test_df["fraud"].iloc[:5].values
prediction_dfEtapa 6: limpar os recursos
Para evitar cobranças não intencionais, é uma prática recomendada excluir recursos que você não está mais usando.
Copie e cole o bloco de código a seguir para excluir a função Lambda, o modelo, a configuração do endpoint, o endpoint e o pipeline que você criou neste tutorial.
# Delete the Lambda function
func.delete()
# Delete the endpoint
sm_client.delete_endpoint(EndpointName=endpoint_name)
# Delete the EndpointConfig
sm_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
# Delete the model
sm_client.delete_model(ModelName=pipeline_model_name)
# Delete the pipeline
sm_client.delete_pipeline(PipelineName=pipeline_name)Para excluir o bucket do S3, faça o seguinte:
- Abra o console do Amazon S3. Na barra de navegação, escolha Buckets, sagemaker-<your-Region>-<your-account-id>, e marque a caixa de seleção ao lado de fraud-detect-demo. Selecione Delete (Excluir).
- Na caixa de diálogo Delete objects (Excluir objetos), verifique se você selecionou o objeto correto para excluir e digite permanently delete (excluir permanentemente) na caixa de confirmação Permanently delete objects (Excluir objetos permanentemente).
- Quando esse passo for concluído e o bucket estiver vazio, você poderá excluir o bucket sagemaker-<your-Region>-<your-account-id> realizando o mesmo procedimento novamente.

O kernel Data Science usado para executar a imagem do bloco de anotações neste tutorial acumulará cobranças até você interromper o kernel ou executar as etapas a seguir para excluir as aplicações. Para obter mais informações, consulte Shut Down Resources (Desativar recursos) no Guia do desenvolvedor do Amazon SageMaker.
Para excluir as aplicações do SageMaker Studio, faça o seguinte: no console do SageMaker Studio, escolha studio-user e exclua todas as aplicações listadas em Apps (Aplicações) escolhendo Delete app (Excluir aplicação). Aguarde até o Status ser alterado para Deleted (Excluído).

Se você usou um domínio existente do SageMaker Studio na Etapa 1, ignore o restante da Etapa 6 e vá diretamente para a seção de conclusão.
Se você executou o modelo do CloudFormation na Etapa 1 para criar um novo domínio do SageMaker Studio, prossiga com as etapas a seguir para excluir o domínio, o usuário e os recursos criados pelo modelo do CloudFormation.
Para abrir o console do CloudFormation, insira CloudFormation na barra de pesquisa do Console da AWS e escolha CloudFormation nos resultados da pesquisa.

No painel do CloudFormation, escolha Stacks (Pilhas). Na lista suspensa de status, selecione Active (Ativo). Em Stack name (Nome da pilha), escolha CFN-SM-IM-Lambda-catalog para abrir a página de detalhes da pilha.

Na página de detalhes da pilha CFN-SM-IM-Lambda-catalog, escolha Delete (Excluir) para excluir a pilha junto com os recursos que ela criou na Etapa 1.

Conclusão
Parabéns! Você concluiu o tutorial Automatizar fluxos de trabalho de machine learning.
Você usou corretamente o Amazon SageMaker Pipelines para automatizar todo o fluxo de trabalho de ML, começando pelo processamento de dados, treinamento de modelo, avaliação de modelo, verificação de desvio e explicabilidade, registro de modelo condicional e implantação. Por fim, utilizou o SDK do SageMaker para implantar o modelo em um endpoint de inferência em tempo real e o testou com uma carga útil de exemplo.
Continue sua jornada de machine learning com o Amazon SageMaker seguindo a seção de próximas etapas abaixo.
Implantar um modelo de machine learning
Treinar um modelo de aprendizado profundo
Encontre mais tutoriais práticos