Статическая стабильность с помощью зон доступности
АРХИТЕКТУРА | УРОВЕНЬ 300
Введение
Сервисы, которые мы создаем в Amazon, должны соответствовать самым высоким показателям высокой доступности. Это значит, что нам нужно внимательно анализировать зависимости наших систем. Мы проектируем системы так, чтобы они сохраняли устойчивость даже при нарушении работы зависимых компонентов. В этой статье мы опишем шаблон, который мы используем для достижения такого уровня устойчивости и который называется статическая стабильность. Мы покажем, как мы применяем эту концепцию к зонам доступности, важным инфраструктурным компонентам в AWS, которые являются ключевой зависимостью всех наших сервисов.
Система, спроектированная с использованием статической стабильности, продолжает работать, даже если зависимость вышла из строя. Возможно, система не получает обновленную информацию, например новые, удаленные или измененные элементы, которую должна была предоставлять зависимость. Однако все другие операции, которые выполнялись до отказа зависимости, продолжаются. Мы опишем, как мы обеспечили статическую стабильность Amazon Elastic Compute Cloud (EC2). Затем мы предоставим два примера статически стабильных архитектур, которые кажутся нам полезными для создания высокодоступных региональных систем на основе зон доступности.
Наконец, мы подробно опишем некоторые принципы проектирования сервиса Amazon EC2, в том числе его архитектуру, которая обеспечивает независимость зоны доступности на уровне программного обеспечение. Кроме того, мы обсудит некоторые компромиссы, на которые приходится идти при создании сервиса с такой архитектурой.
Роль зон доступности
Зоны доступности – это логически изолированные разделы региона AWS: у каждого региона AWS несколько зон доступности, которые спроектированы для независимой работы. Зоны доступности физически разделены значительным расстоянием для защиты от взаимосвязанного ущерба от потенциальных проблем, таких как удар молнии, торнадо и землетрясение. В них не используются общие источники питания или другая инфраструктура, но они подключены друг к другу с использованием быстрой зашифрованной частной оптоволоконной сети, чтобы приложения могли быстро переключаться на резервный ресурс без прерывания работы. Другими словами, зоны доступности создают абстрактный уровень над изолированной инфраструктурой. Сервисы, которым требуется зона доступности, позволяют оператору сообщить AWS, где необходимо физически инициализировать инфраструктуру в регионе, чтобы извлечь преимущества из этой независимости. В Amazon мы разработали региональные сервисы AWS, которые используют эту зональную независимость для достижения целевых показателей высокой доступности. В качестве примеров таких сервисов можно привести Amazon DynamoDB, Amazon Simple Queue Service (SQS), и Amazon Simple Storage Service (S3).
При взаимодействии с сервисом AWS, который инициализирует облачную инфраструктуру в облаке Amazon Virtual Private Cloud (VPC), для многих из таких сервисов требуется, чтобы оператор указал не только регион, но и зону доступности. Зона доступности часто указывается неявно в обязательном аргументе подсети, например при запуске инстанса EC2, инициализации базы данных Amazon Relational Database Service (RDS) или создании кластера Amazon ElastiCache. Хотя во многих случаях в зоне доступности есть несколько подсетей, одна подсеть полностью находится в одной зоне доступности, поэтому оператор, предоставляя аргумент подсети, также неявно указывает, какую зону доступности следует использовать.
Статическая стабильность
При создании систем на основе зон доступности мы сделали следующий вывод: необходимо подготовиться к сбоям, до того как они произойдут. Менее эффективный подход заключается в развертывании нескольких зон доступности и ожидании того, что в случае сбоя одной зоны доступности сервис масштабируется (возможно, используя AWS Auto Scaling) в других зонах доступности и может восстановить полную работоспособность. Этот подход менее эффективен, так как он подразумевает реагирование на сбои после их возникновения, а не их предотвращение. Другими словами, он лишен статической стабильности. Более эффективный статически стабильный сервис выделяет избыточные ресурсы инфраструктуры, чтобы продолжить работу без запуска новых инстансов EC2, даже если зона доступности выходит из строя.
Чтобы лучше проиллюстрировать статическую стабильность, рассмотрим сервис Amazon EC2, который спроектирован на основе этих принципов.
Сервис Amazon EC2 состоит из плоскости контроля и плоскости данных. Термины «Плоскость контроля» и «плоскость данных» используются сетевыми специалистами, но мы часто применяем их к AWS. Плоскость контроля – это оборудование, которое вносит изменения в систему, например добавляет, удаляет и изменяет ресурсы, и передает эти изменения туда, где их следует применить. И наоборот, плоскость данных – это повседневные операции этих ресурсов, которые необходимы для их использования.
В Amazon EC2 плоскость контроля – это все, что происходит, когда EC2 запускает новый инстанс. Логика плоскости контроля объединяет все необходимое для нового инстанса EC2, выполняя многочисленные задачи. Далее приведены некоторые примеры:
- Находит физический сервер для вычислительных ресурсов, учитывая требования к группе размещения и аренде VPC.
- Выделяет новый сетевой интерфейс в подсети VPC.
- Подготавливает том Amazon Elastic Block Store (EBS).
- Создает данные для доступа роли AWS Identity and Access Management (IAM).
- Устанавливает правила группы безопасности.
- Сохраняет результаты в хранилищах данных различных подчиненных сервисов.
- Передает необходимые конфигурации на сервер в VPC и на периферию сети по мере необходимости.
Плоскость данных Amazon EC2, наоборот, поддерживает работу инстансов EC2, выполняя следующие задачи:
- Перенаправляет пакеты в соответствии с таблицами маршрутизации VPC.
- Считывает и записывает данные на томах Amazon EBS.
- И т. д.
Плоскость данных Amazon EC2 намного проще плоскости контроля, что характерно для них. В результате такой относительной простоты целевые показатели доступности плоскости данных Amazon EC2 выше, чем у плоскости контроля Amazon EC2.
Важно, что плоскость данных Amazon EC2 спроектирована статически стабильной на фоне событий доступности плоскости контроля (таких как сбой запуска инстансов EC2). Например, чтобы предотвратить сбои сетевого подключения, плоскость данных Amazon EC2 спроектирована таким образом, что физический компьютер, на котором выполняется инстанс EC2, имеет локальный доступ ко всей информации, необходимой для маршрутизации пакетов внутри и за пределами VPC. Сбой плоскости контроля Amazon EC2 означает, что во время события физический сервер может не получать обновления, такие как добавление инстансов EC2 в VPC или создание нового правила группы безопасности. Однако трафик, который он мог отправлять и получать до события, будет по-прежнему доступен.
Концепции плоскости контроля, плоскости данных и статической стабильности широко применимы, даже за пределами Amazon EC2. Возможность разделить систему на плоскости контроля и данных может стать полезным инструментом проектирования высокодоступных сервисов по ряду причин:
- Как правило, доступность плоскости данных более критична для пользователей сервиса, чем доступность плоскости контроля. Например, непрерывная доступность и правильная работа инстанса EC2 после его запуска более важна для большинства клиентов AWS, чем возможность запуска новых инстансов EC2.
- Как правило, плоскость данных работает более вместительном томе, чем плоскость контроль (часто его размер на порядки больше). Поэтому лучше их разделить, чтобы каждый из них можно было масштабировать в соответствии с собственными потребностями.
- С годами мы обнаружили, что в плоскости контроля системы больше перемещаемых компонентов, чем в плоскости данных, поэтому статистически вероятность ее сбоя выше только из-за этого фактора.
Если объединить все эти соображения, мы рекомендуем разделять системы по границам плоскостей контроля и данных.
Для реализации такого разделения на практике мы применяем принципы статической стабильности. Обычно плоскость данных зависит от данных, поступающих от плоскости контроля. Однако для обеспечения более высоких целевых показателей доступности плоскость данных поддерживает существующее состояние и продолжает работать даже при сбое плоскости управления. Плоскость данных даже может не получать обновления во время сбоя, но все, что работало ранее, продолжает функционировать.
Ранее мы отметили, что схема, которая требует размещения инстанса EC2 в ответ на сбой зоны доступности, – это менее эффективный подход. Это не связано с тем, что мы не сможем запустить новый инстанс EC2. Это вызвано тем, что в ответ на сбой система должна немедленно создать зависимость от пути восстановления на плоскости контроля Amazon EC2, а также от всех связанных с приложением систем, необходимых для запуска нового инстанса. В зависимости приложения, могут потребоваться такие действия, как загрузка конфигурации среды выполнения, регистрация инстанса в сервисах обнаружения, получение данных для доступа и т. д. Системы плоскости контроля всегда более сложные, чем в плоскости данных, и вероятность их неправильной работы при общем сбое системы выше.
Шаблоны статической стабильности
В этом разделе мы опишем два шаблона, которые мы используем в AWS для проектирования высокодоступных систем на основе принципа статической стабильности. Каждая из них применяется в отдельных ситуациях, но все они используют преимущества абстрагирования зон доступности.
Пример зоны доступности типа «активный-активный»: сервис с балансировкой нагрузки
Несколько сервисов AWS состоит из группы горизонтально масштабируемых инстансов EC2 без состояния или контейнеров Amazon Elastic Container Service (ECS). Мы запускаем эти сервисы в группе Auto Scaling в трех или более зонах доступности. Кроме того, эти сервисы выделяют избыточные ресурсы, чтобы даже в случае сбоя всей зоны доступности, серверы в оставшихся зонах доступности смогли справиться с нагрузкой. Например, при использовании трех зон доступности коэффициент избыточности составляет 50 процентов. Другими словами, мы выделяем избыточные ресурсы так, чтобы каждая зона доступности работала на уровне нагрузки 66 процентов, для которого мы провели нагрузочное тестирование.
Самый распространенный пример – это сервис HTTPS с балансировкой нагрузки. На следующей схеме показ общедоступный балансировщик нагрузки Application Load Balancer, предоставляющий сервис HTTPS. Цель балансировщика нагрузки – это группа Auto Scaling, которая охватывает три зоны доступности в регионе eu-west-1. Это пример конфигурации высокой доступности типа «активный-активный» с использованием зон доступности.
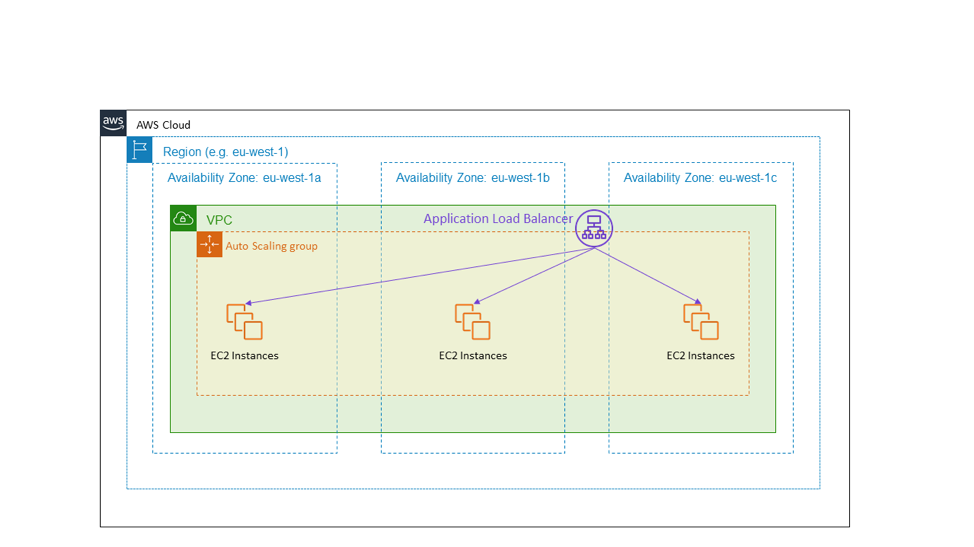
В случае сбоя зоны доступности архитектура, показанная на предыдущей схеме, не требует никаких действий. Инстансы EC2 в отказавшей зоне доступности перестанут проходить проверки работоспособности, и Application Load Balancer перестанет направлять на них трафик. В действительности, сервис Elastic Load Balancing создан на основе этого принципа. Он выделяет достаточно ресурсов для балансировку нагрузки, чтобы справиться со сбоем зоны доступности без необходимости в вертикальном масштабировании.
Мы также используем этот шаблон даже при отсутствии балансировщика нагрузки или сервиса HTTPS. Например, группа инстансов EC2, которые обрабатывают сообщения из очереди Amazon Simple Queue Service (SQS), также могут использовать этот шаблон. Инстансы развертываются в группе Auto Scaling в нескольких зонах доступности с соответствующей избыточностью. При сбое зоны доступности сервис ничего не предпринимает. Затронутые сервисы перестают работать, а их нагрузку подхватывают другие.
Пример зоны доступности типа «активный-резервный»: реляционная база данных
Некоторые из сервисов, которые мы создаем, фиксируют состояние, и для координации их работы требуется один основной или ведущий узел. Примером служит сервис, использующий реляционную базу данных, такую как Amazon RDS с ядром СУБД MySQL или Postgres. Типичная конфигурация высокой доступности такого типа реляционной базы данных содержит основной инстанс, на который поступают все запросы записи, и резервный кандидат. У нас также могут дополнительные реплики для чтения, которые не показаны на следующей схеме. При работе с подобной инфраструктурой с фиксацией состояния в другой зоне доступности есть «теплый» резервный узел, основанный на этом основном узле.
На следующей схеме показана база данных Amazon RDS. При инициализации базы данных с помощью Amazon RDS требуется указать группу подсетей. Группа подсетей – это набор подсетей, охватывающих несколько зон доступности, в которых будут инициализированы инстансы базы данных. Amazon RDS размещает резервного кандидата в другой зоне доступности из основного узла. Это пример конфигурации высокой доступности типа «активный-резервный» с использованием зон доступности.
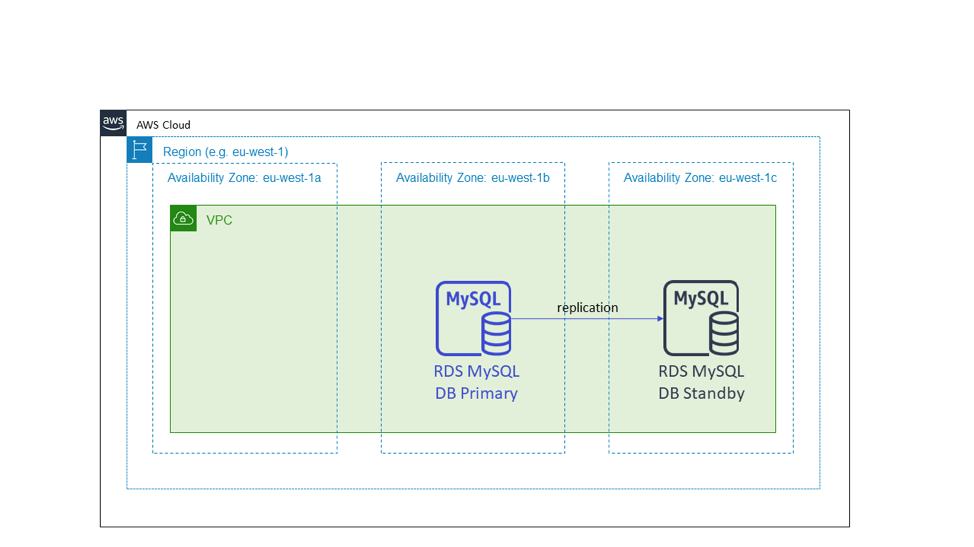
Как и в примере конфигурации типа «активный-активный» без фиксации состояния, при сбое зоны доступности с первичным узлом сервис с фиксацией состояния ничего не делает с инфраструктурой. Для сервисов, использующих Amazon RDS, сервис RDS управляет перебросом и меняет DNS-имя на новый основной узел в рабочей зоне доступности. Этот шаблон также применяется к другим конфигурациям типа «активный-резервный», даже если они не используют реляционную базу данных. В частности, мы применяем его в системах с архитектурой кластера, содержащей ведущий узел. Мы развертываем эти кластеры в зонах доступности и выбираем новый ведущий узел из резервных кандидатов, а не незамедлительно начинаем замену.
В обоих случаях эти шаблоны уже выделили ресурсы, необходимые на случай сбоя зоны доступности намного раньше любого возможного отказа. Ни в одном из случаев сервис не использует преднамеренно зависимости плоскости управления, например не инициализирует новую инфраструктуру и не вносит изменения, в ответ на сбой зоны доступности.
Устройство системы: статическая стабильность внутри Amazon EC2
В последнем разделе статьи мы немного углубимся в архитектуры устойчивой зоны доступности и рассмотрим некоторые способы, которые мы используем при применении принципа независимости зон доступности в Amazon EC2. Понимание этих концепций будет полезно при создании сервиса, который не только должен быть высокодоступным сам, но и должен предоставлять инфраструктуру, с помощью которой другие компоненты будут высокодоступными. Amazon EC2 как поставщик низкоуровневой инфраструктуры AWS предоставляет приложениям инфраструктуру, которая позволяет им обеспечить высокую доступность. Иногда эту стратегию может потребоваться применить в других системах.
При развертывании мы используем принцип независимости зон доступности в Amazon EC2. В Amazon EC2 программное обеспечение развертывается на физических серверах, на которых размещаются инстансы EC2, периферийные устройства, преобразователи имен DNS, компоненты плоскости контроля в пути запуска инстанса EC2 и многие другие компоненты, от которых зависят инстансы EC2. Эти развертывания соблюдают зональный календарь развертывания. Это значит, что две зоны доступности в одном регионе получат данное развертывание в разные дни. В AWS мы используем поэтапное развертывание. Например, мы соблюдаем следующую рекомендацию, независимо от типа сервиса, в котором выполняется развертывание: сначала развертывается универсальный почтовый ящик, затем 1/N серверов и т. д. Однако для таких сервисов, как Amazon EC2, развертывания преднамеренно согласуются с границами зон доступности. Таким образом, проблема с развертыванием влияет на одну зону доступности, откатывается и устраняется. Она не влияет на другие зоны доступности, которые продолжают работу в нормальном режиме.
Другой способ применения принципа независимости зон доступности при разработке в Amazon EC2 заключается в том, чтобы все потоки пакетов оставались в зоне доступности и не пересекали ее границы. Второй пункт (сохранение сетевого трафика в зоне доступности) стоит обсудить подробнее. Это интересная иллюстрация того, что мы мыслим по-разному при создании региональной высокодоступной системы, которая является потребителем независимых зон доступности (то есть использует гарантии независимости зон доступности как основу для создания высокодоступного сервиса) и при предоставлении инфраструктуры независимых зон доступности другим, чтобы позволить им обеспечить высокую доступность.
На следующей схеме оранжевым цветом выделен высокодоступный внешний сервис, который зависит от другого внутреннего сервиса, выделенного зеленым цветом. В несложной системе оба сервиса считаются потребителями независимых зон доступности EC2. Перед оранжевым и зеленым сервисами находится Application Load Balancer, и у каждого сервиса есть достаточная группа хостов, распределенных по трем зонам доступности. Один высокодоступный региональный сервис вызывает другой высокодоступный региональный сервис. Это простая архитектура, эффективная для многих наших сервисов.
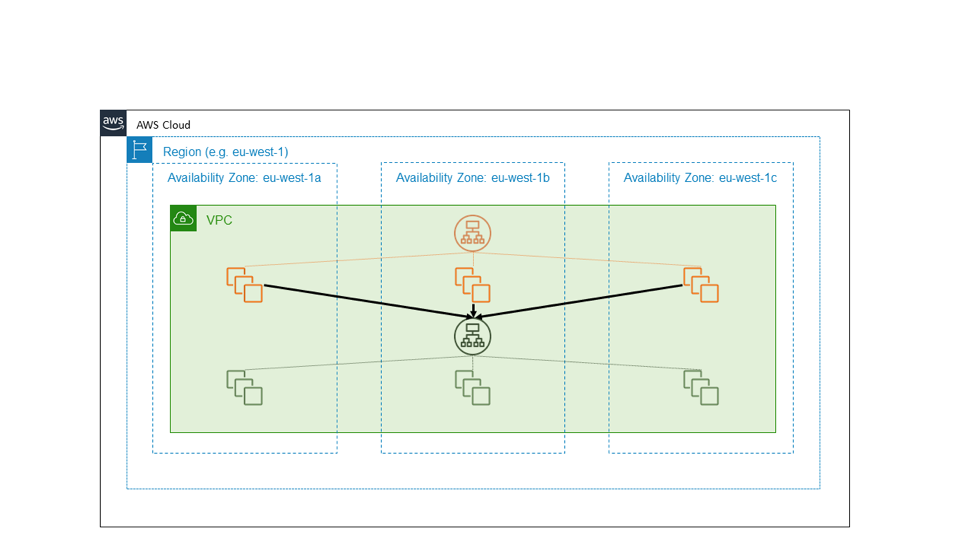
Однако предположим, что зеленый сервис – это базовая система. Допустим, что не только должен быть высокодоступным, но и должен служить структурным блоком для обеспечения независимости зон доступности. В этом случае мы можем спроектировать его как три инстанса в локальном для зоны сервисе, в котором мы применяем методы развертывания с учетом зон доступности. На следующей схеме показана система, в которой высокодоступный региональный сервис вызывает высокодоступный зональный сервис.
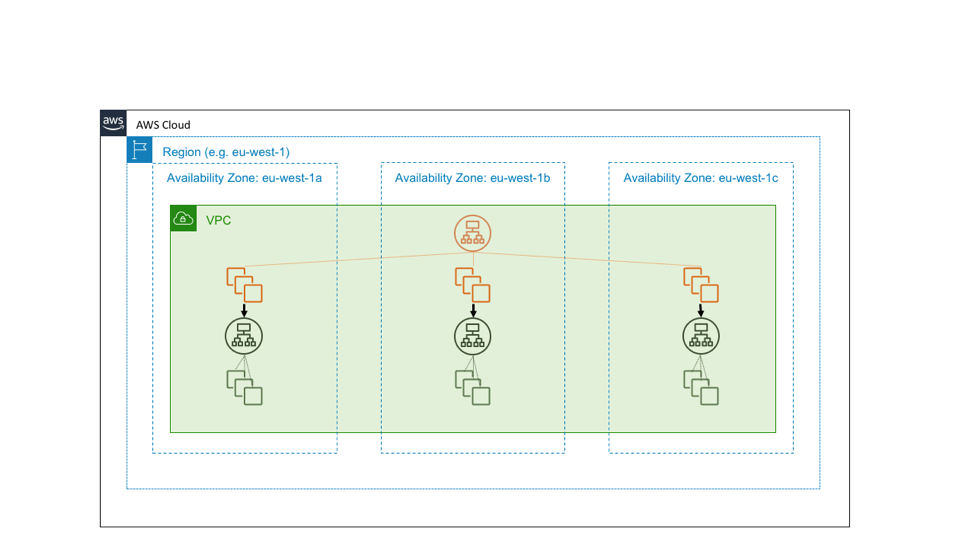
Причины, по которым мы проектируем базовые сервисы независимыми от зон доступности, просты. Допустим, произошел сбой зоны доступности. Для простых сбоев Application Load Balancer автоматически осуществляет переброс затронутых узлов. Однако не все сбои такие очевидные. Могут существовать ошибки в программном обеспечении, которые балансировщик нагрузки не увидит во время проверки работоспособности и не сможет устранить.
В предыдущем примере, в котором один высокодоступный региональный сервис вызывает другой такой же сервис, если запрос отправляется через систему, то с небольшими упрощениями вероятность того, что запрос избежит затронутую зону доступности составляет 2/3 * 2/3 = 4/9. Это значит, что шансы запроса на сохранение устойчивости меньше одного к одному. И наоборот, если мы сделаем зеленый сервис зональным, как в текущем примере, то хосты в оранжевом сервисе смогут вызвать зеленый адрес в той же зоне доступности. С такой архитектурой вероятность избежать затронутой зоны доступности составляет 2/3. Если в этом пути вызова N сервисов, вероятность возрастает до (2/3)^N для N региональных сервисов и остается равной 2/3 для N зональных сервисов.
Поэтому мы создали шлюз NAT Amazon EC2 как зональный сервис. Шлюз NAT — это функция Amazon EC2, которая разрешает исходящий интернет-трафик из частной подсети и отображается не как региональный шлюз для всего облака VPC, а как зональный ресурс, который клиенты инициализируют отдельно в каждой зоне доступности, как показано на следующей схеме. Шлюз NAT размещается на этом пути интернет-подключения для VPC и поэтому является частью плоскости данных любого инстанса EC2 в этом VPC. Если произойдет сбой одной из зон доступности, мы хотим, чтобы он был изолирован в этой зоне, а не распространился и на другие зоны. В конце концов, мы хотим, чтобы клиент, который создал архитектуру, аналогичную описанной ранее в этой статье (инициализировал группы инстансов в трех зонах доступности с достаточными ресурсами в любых из двух зон для обработки полной нагрузки), знал, что другие зоны доступности никак не будут затронуты тем, что происходит в отказавшей зоне доступности. Единственный способ достичь этого – убедиться, что все базовые компоненты, например шлюз NAT, действительно остаются в пределах зоны доступности.
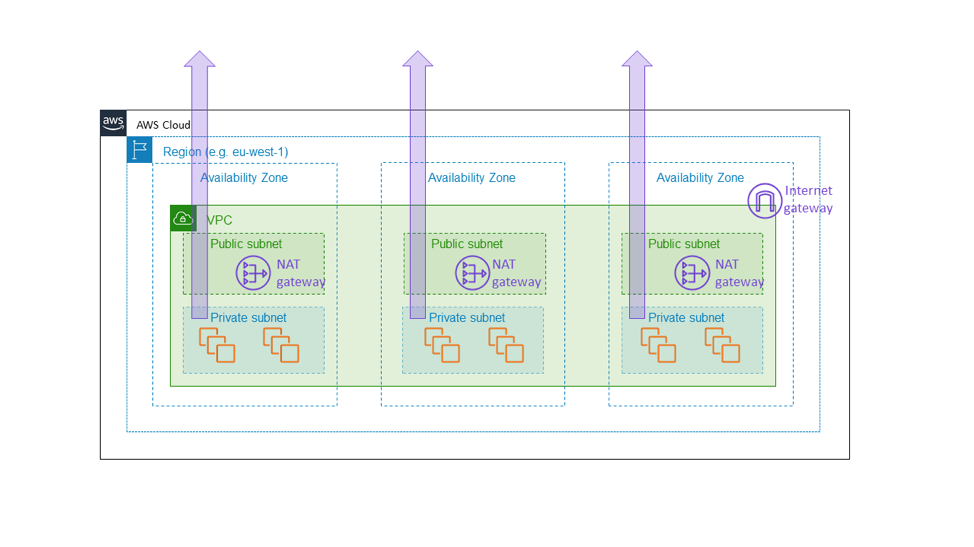
Это, в свою очередь, делает систему сложнее. Для нас в Amazon EC2 дополнительная сложность выражается в необходимости управления зональными, а не региональными средами сервисов. Для клиентов шлюза NAT она заключается в наличии нескольких шлюзов NAT и таблиц маршрутизации, которые используются в разных зонах доступности VPC. Эта сложность обоснована, так как шлюз NAT сам по себе является базовым сервисом, частью плоскости данных Amazon EC2, который должен предоставлять гарантии зональной доступности.
Существует еще одно предположение, которое мы делаем при создании сервисов, независимых от зон доступности, и это надежность данных. Хотя каждая из зональных архитектур, описанная выше, показывает, что весь стек содержится в одной зоне доступности, мы реплицируем любое жесткое состояние в несколько зон доступности для аварийного восстановления. Например, мы периодически сохраняем резервные копии базы данных в Amazon S3 и размещаем реплики для чтения наших хранилищ данных в границах зоны доступности. Эти реплики необязательны для работы основной зоны доступности. Вместо этого они помогают хранить важные для клиента или бизнеса данные в нескольких местоположениях.
При проектировании сервисноориентированной архитектуры, которая будет работать в AWS, мы поняли, что следует использовать один из следующих шаблонов или их сочетание.
- Более простой шаблон: региональный сервис вызывает региональный сервис. Часто это лучший вариант для сервисов, доступных внешним пользователям, который также подходит для большинства внутренних сервисов. Например, при создании сервисов приложений более высокого уровня в AWS, таких как Amazon API Gateway и бессерверные технологии AWS, мы используем этот шаблон для обеспечения высокой доступности даже в случае сбоя зоны доступности.
- Более сложный шаблон: региональный сервис вызывает зональный сервис или зональный сервис вызывает зональный сервис. При проектировании внутренних, а иногда и внешних компонентов плоскости данных в Amazon EC2 (например, сетевых устройств или другой инфраструктуры, которая расположена напрямую на критическом пути данных) мы используем шаблон независимости зон доступности и инстансы, которые изолированы в зонах доступности, чтобы сетевой трафик оставался в одной зоне доступности. Этот шаблон не только гарантирует изоляцию ошибок в зоне доступности, но и позволяет сократить расходы на сетевой трафик в AWS.
Заключение
В этой статье мы обсудили некоторые простые стратегии, которые мы использовали в AWS для успешного устранения зависимостей в зонах доступности. Мы поняли, что ключевой фактор для статической стабильности заключается в прогнозировании сбоев, прежде чем они произойдут. Если система работает в группе инстансов с горизонтальным масштабированием типа «активный-активный» или использует шаблон «активный-резервный» с фиксацией состояния, мы можем применять зоны доступности для обеспечения высоких показателей доступности. Мы развертываем системы так, чтобы все ресурсы, которые могут понадобиться в случае сбоя, уже были полностью выделены и доступны. Наконец, мы подробнее обсудили то, как сервис Amazon EC2 сам использует концепции статической стабильности для сохранения независимости зон доступности друг от друга.
Об авторах
Бекки Вайс
 Бекки Вайс – главный инженер в Amazon Web Services. Сейчас ее усилия направлены на работу с Identity and Access Management в AWS и, в целом, на то, чтобы предоставить клиентам гибкие, комплексные и заслуживающее доверия элементы управления безопасностью в облаке. В прошлом она работала над Amazon Virtual Private Cloud (т. е. над сетями) и AWS Lambda, а также с подразделением AWS Professional Services, помогая корпоративным клиентам успешно защитить свои среды в AWS. Кроме того, Бекки – большой поклонник AWS, и в свое свободное время создает всевозможные полезные и бесполезные решения в AWS. До прихода в AWS Бекки работала в Microsoft над Windows и Windows Phone.
Бекки Вайс – главный инженер в Amazon Web Services. Сейчас ее усилия направлены на работу с Identity and Access Management в AWS и, в целом, на то, чтобы предоставить клиентам гибкие, комплексные и заслуживающее доверия элементы управления безопасностью в облаке. В прошлом она работала над Amazon Virtual Private Cloud (т. е. над сетями) и AWS Lambda, а также с подразделением AWS Professional Services, помогая корпоративным клиентам успешно защитить свои среды в AWS. Кроме того, Бекки – большой поклонник AWS, и в свое свободное время создает всевозможные полезные и бесполезные решения в AWS. До прихода в AWS Бекки работала в Microsoft над Windows и Windows Phone.
Майк Ферр
 Майк Ферр – главный инженер в Amazon Web Services. Он стал работать в Amazon в 2009 году после получения степени доктора философии по информатике в Мэрилендском университете в Колледж-Парке. Во время работы в Amazon он занимался Virtual Private Cloud, Direct Connect, а также стеком технологий измерения и выставления счетов AWS. Теперь он работает над EC2, помогая с горизонтальным масштабированием облака.
Майк Ферр – главный инженер в Amazon Web Services. Он стал работать в Amazon в 2009 году после получения степени доктора философии по информатике в Мэрилендском университете в Колледж-Парке. Во время работы в Amazon он занимался Virtual Private Cloud, Direct Connect, а также стеком технологий измерения и выставления счетов AWS. Теперь он работает над EC2, помогая с горизонтальным масштабированием облака.
Связанный контент
Нашли то, что искали сегодня?
Скажите, как улучшить качество контента на наших страницах