Сброс нагрузки во избежание перегрузок
Доставка программного обеспечения и операции | УРОВЕНЬ 400
Введение
В течение нескольких лет я работал в команде разработчиков сервисных платформ Amazon. Наша команда разрабатывала инструменты, которые помогали владельцам сервисов AWS, например Amazon Route 53 и Elastic Load Balancing, быстрее создавать сервисы, а клиентам – вызывать их. Другие команды Amazon предоставляли владельцам сервисов такие функциональные возможности, как измерение показателей, аутентификация и мониторинг, а также создание клиентских библиотек и документации. Чтобы администраторам сервисов не приходилось добавлять эти возможности вручную, команда разработчиков сервисных платформ выполнила интеграцию один раз, после чего они стали доступны каждому сервису через конфигурацию.
Однако возникали и трудности, например мы не могли определить, как предоставлять подходящие настройки по умолчанию, особенно для возможностей, связанных с производительностью или доступностью. Например, было сложно задать стандартное время ожидания со стороны клиента, так как нашей платформе неизвестны характеристики задержки вызова API. Владельцы и клиенты сервисов тоже столкнулись бы с подобными проблемами, поэтому мы продолжили разработки, сделав в процессе несколько полезных открытий.
Кроме того, трудности вызвало определение стандартного количества подключений, которые могут быть одновременно открыты для клиентов на сервере. Эта настройка помогает предотвратить перегрузки сервера. В частности, мы хотели настроить максимальное количество подключений для сервера пропорционально аналогичному показателю балансировщика нагрузки. Это было еще до появления Elastic Load Balancing, поэтому аппаратные балансировщики нагрузки широко применялись.
Мы решили помочь владельцам и клиентам сервисов Amazon определить идеальное значение максимального количества подключений для балансировщика нагрузки, а также соответствующее значение для предоставляемых нами платформ. Было решено, что если мы можем сделать выбор на основе собственных умозаключений, то можно написать программное обеспечение, имитирующее эти умозаключения.
Определение идеального значения оказалось очень сложной задачей. Если максимальное количество подключений слишком низкое, балансировщик нагрузки может отклонять избыточные запросы при увеличении их количества, даже если сервису хватает ресурсов. Если задать слишком большое значение, серверы могут замедляться и отказывать. Если задать максимальное количество подключений для определенной рабочей нагрузки в качестве оптимального, может измениться производительность зависимостей или сама рабочая нагрузка. В таком случае значения снова станут неправильными, приводя к отключениям и перегрузкам, которых можно было бы избежать.
В итоге мы обнаружили, что показатель максимального количества подключений слишком неточен, чтобы полностью решить задачу. В этой статье описываются другие подходы, которые принесли нам хорошие результаты, например сброс нагрузки.
Анатомия перегрузки
В системах компании Amazon используется прогнозное масштабирование, позволяющее предотвращать перегрузки. Однако защита систем должна быть многоуровневой. Она начинается с автоматического масштабирования, а также включает механизмы для безопасного сброса избыточной нагрузки и, что важнее всего, непрерывного тестирования.
Нагрузочное тестирование наших сервисов показало, что задержка сервера при низкой загрузке ниже, чем при высокой. Под большой нагрузкой острее проявляются такие проблемы, как конфликты потоков, изменение контекста, удаление ненужных данных и конфликты ввода-вывода. Со временем наступает переломный момент, после которого производительность сервиса начинает снижаться еще быстрее.
Теория, на которой основано это наблюдение, называется универсальным законом масштабируемости. Он является следствием закона Амдала. Эта теория гласит, что хотя пропускную способность сети можно повысить с помощью параллелизации, в конечном итоге она ограничена пропускной способностью точек сериализации (то есть задач, которые невозможно параллелизовать).
К сожалению, пропускная способность не только ограничена системными ресурсами, но и зачастую снижается при перегрузке системы. Когда нагрузка на систему превышает возможности ее ресурсов, работа замедляется. Компьютеры принимают задачи даже при перегрузке, но при этом тратят все больше времени на переключение контекста. Они становятся слишком медленными, чтобы приносить пользу.
В распределенной системе, где клиент взаимодействует с сервером, это обычно приводит к тому, что через некоторое время клиент теряет терпение и перестает ждать отклик сервера. Продолжительность этого периода называется временем ожидания. Когда перегрузка сервера достигает максимума и задержка превышает время ожидания клиента, запросы завершаются неудачей. На приведенном ниже графике показано, как время ответа сервера повышается по мере увеличения необходимой пропускной способности (в транзакциях за секунду) и со временем достигает переломного момента, когда производительность начинает стремительно снижаться.
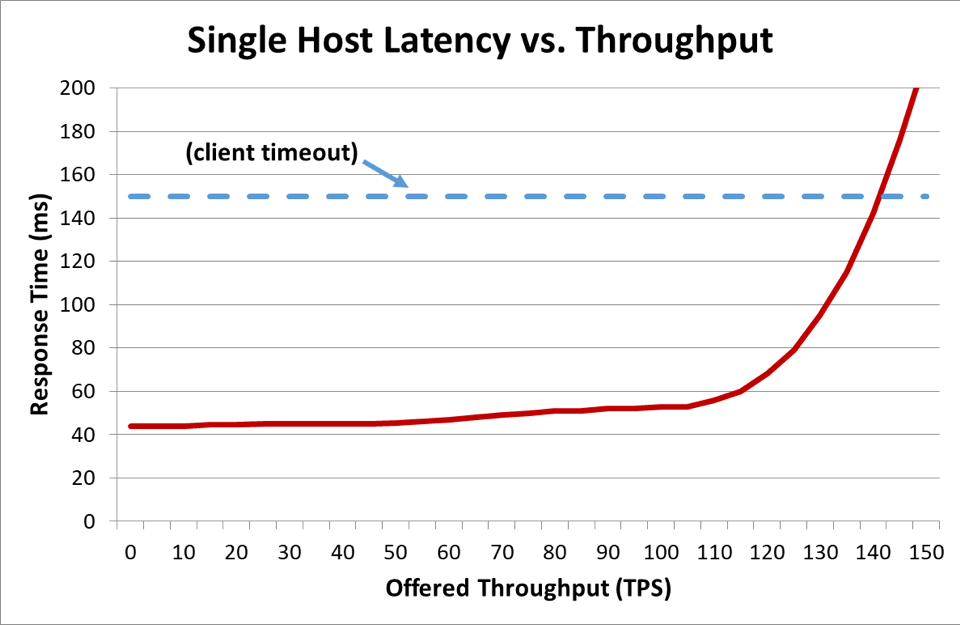
Когда время ответа превышает время ожидания клиента, понятно, что дела обстоят плохо, но на приведенном выше графике не видно, насколько. Чтобы проиллюстрировать это, можно составить график доступности с точки зрения клиента в зависимости от задержки. Вместо того чтобы использовать общий показатель времени ответа, мы можем руководствоваться средним временем ответа. Обратите внимание, что 50 процентов запросов были обработаны быстрее среднего времени задержки. Если средняя задержка сервиса равна времени ожидания клиента, то у половины запросов истекает срок действия, поэтому доступность составляет 50 процентов. В таком случае при повышении задержки возникает проблема с доступностью. Это показано на графике ниже.
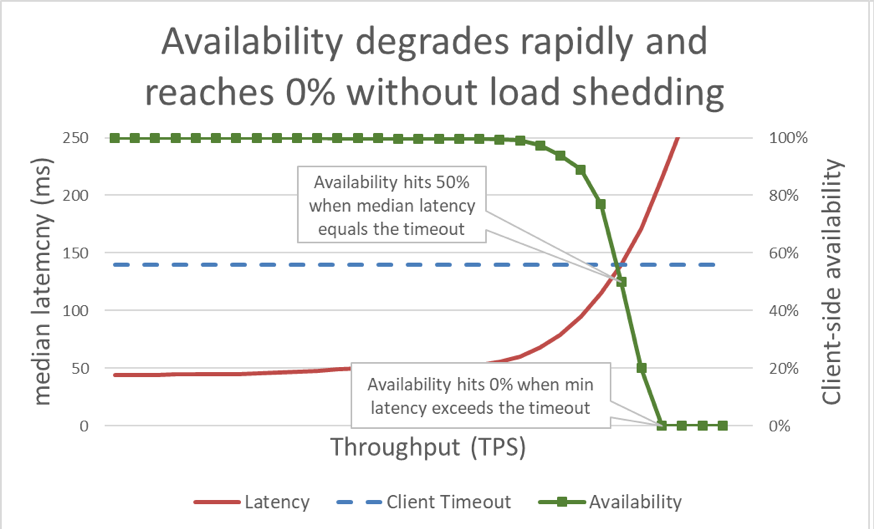
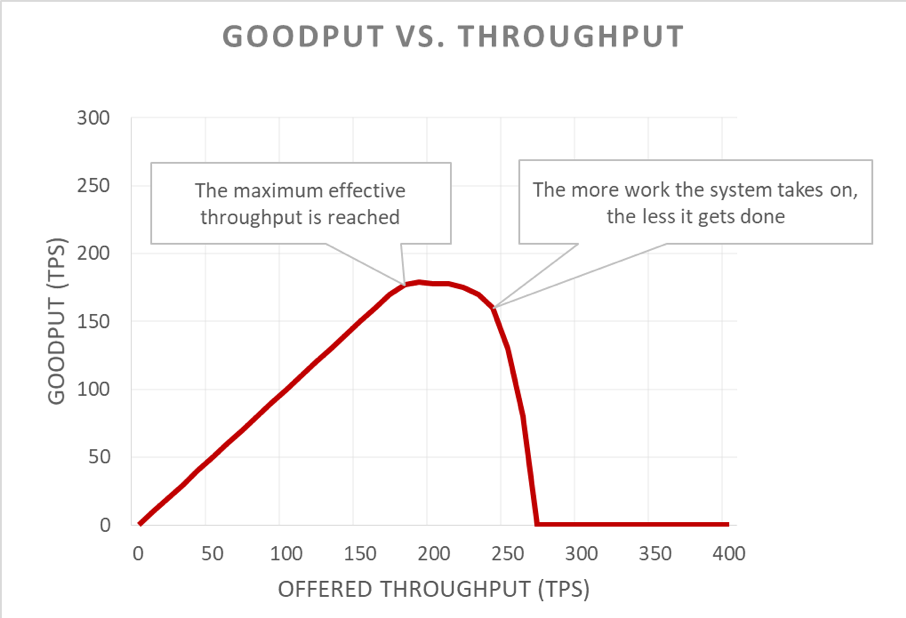
К сожалению, этот график трудно читать. Для простоты проблему доступности можно свести к определению полезной пропускной способности. Пропускная способность – это общее количество запросов, отправляемых на сервер за секунду. Полезная пропускная способность – это часть запросов, обработанная без ошибок и с достаточно низкой задержкой, чтобы клиент мог воспользовался откликом.
Циклы положительной обратной связи
Коварство перегрузок заключается в том, что они усиливают себя по принципу обратной связи. Если время ожидания клиента истекло, то возникшая ошибка будет не единственной нашей проблемой. Что еще хуже, вся работа, уже проделанная сервером по этому запросу, пропадет зря. А в случае перегрузки системы, когда ресурсы ограничены, она не может позволить себе работать впустую.
Более того, клиенты часто отправляют свои запросы повторно. Это умножает нагрузку на систему. Если граф вызовов в архитектуре, ориентированной на сервисы, является достаточно глубоким (то есть клиент вызывает сервис, который вызывает другие сервисы, а те вызывают другие сервисы), а на каждом уровне будет выполнено несколько повторных попыток, то перегрузка на нижнем уровне приведет к каскадному увеличению их количества и экспоненциальному увеличению нагрузки.
При сочетании этих факторов перегрузка образует собственный цикл обратной связи, который приводит к перегрузке в стабильном состоянии.
Предотвращение бесполезной работы
На первый взгляд, сброс нагрузки – это просто. Когда сервер приближается к перегрузке, он начинает отклонять избыточные запросы, чтобы сосредоточиться на уже принятых. Цель сброса нагрузки – поддерживать низкую задержку для тех запросов, которые сервер решит принять, чтобы сервис успевал отправить отклик, прежде чем истечет время ожидания клиента. При таком подходе сервер поддерживает высокую доступность для принимаемых запросов. Перегрузка влияет только на доступность избыточного трафика.
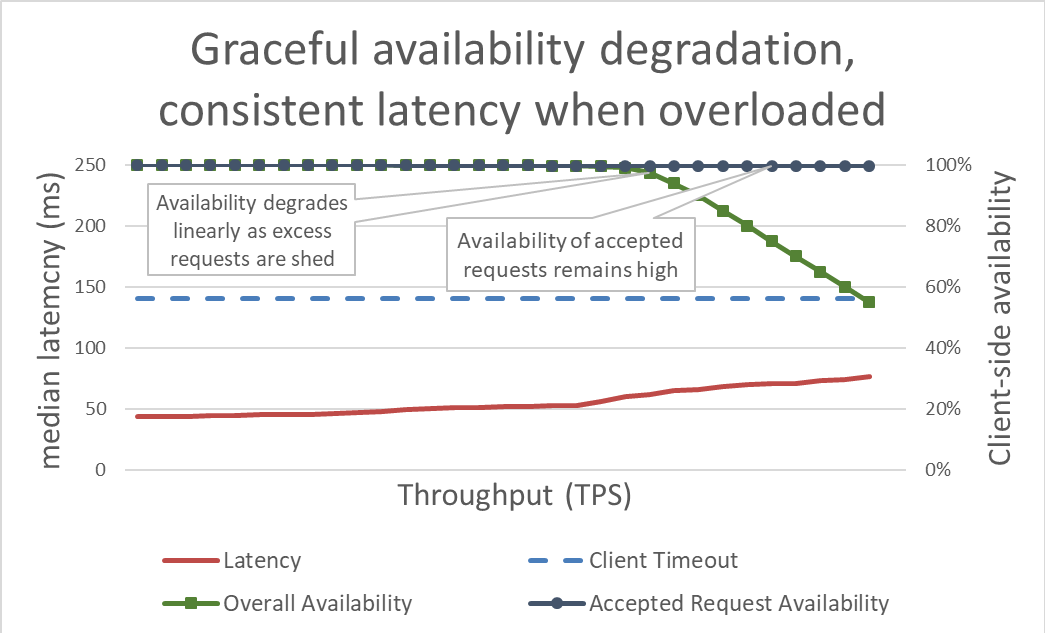
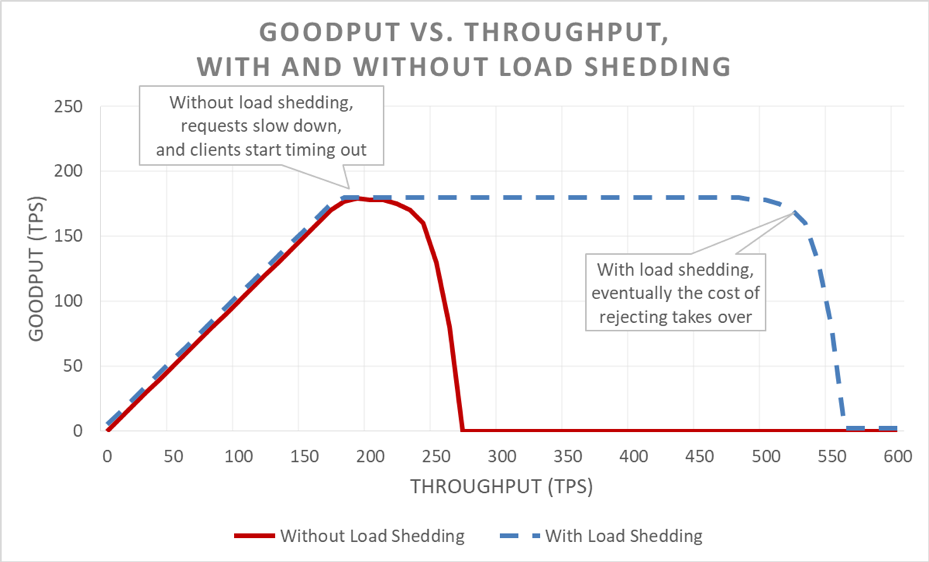
Контроль задержки путем сброса избыточной нагрузки делает систему более доступной. Однако преимущества этого подхода сложно представить на предыдущем графике. Линия общей доступности по-прежнему направляется вниз, что выглядит плохо. Разница в том, что запросы, принятые сервером, остаются доступными, так как они были быстро обработаны.
Сброс нагрузки позволяет серверу поддерживать полезную пропускную способность и выполнять как можно больше запросов даже при увеличении нагрузки. Однако процедура сброса нагрузки также связана с затратами, поэтому со временем сервер попадает под действие закона Амдала, и полезная пропускная способность снижается.
Тестирование
Обсуждая сброс нагрузки с другими инженерами, я часто говорю: если сервис не прошел нагрузочные испытания до точки отказа и дальше, следует готовиться к тому, что он даст сбой самым неподходящим образом. В компании Amazon мы уделяем много времени нагрузочному тестированию своих сервисов. Составление графиков, подобных представленным выше в этой статье, помогает нам оценить базовую производительность при перегрузке и отслеживать изменения по мере модифицирования сервисов.
Есть множество типов нагрузочных испытаний. Некоторые нагрузочные испытания обеспечивают автоматическое масштабирование парка по мере повышения нагрузки, а некоторые поддерживают фиксированный размер парка. Если при тестировании на перегрузку доступность сервиса стремительно снижается до нуля по мере повышения пропускной способности, это признак того, что сервис нуждается в дополнительных механизмах сброса нагрузки. В идеале при нагрузочном тестировании полезная пропускная способность должна стабилизироваться по мере приближения к полному использованию сервиса и оставаться без изменений даже при дальнейшем повышении нагрузки.
Такие инструменты, как Chaos Monkey, помогают тестировать сервисы с использованием хаотического инжиниринга. Например, они могут перегружать ЦП или вызывать потерю пакетов, чтобы имитировать условия перегрузки. Еще одна методика тестирования, которую мы применяем, – взять имеющийся тест с генерированием нагрузки или пробную систему, применить постоянную нагрузку (вместо возрастающей) к тестовой среде и начать исключать из нее серверы. Это повышает нагрузку на каждый инстанс, позволяя тестировать его пропускную способность. Такая методика с искусственным повышением нагрузки за счет уменьшения размера парка удобна для изолированного тестирования сервиса, но не является заменой полноценным нагрузочным испытаниям. Полноценное, комплексное нагрузочное тестирование также повысит нагрузку на зависимости сервиса, помогая выявить другие узкие места.
Во время испытаний мы измеряем не только доступность и задержку на стороне сервера, но и доступность с точки зрения клиента. Когда эта доступность начинает снижаться, мы еще больше увеличиваем нагрузку. Если сброс нагрузки работает, пропускная способность останется стабильной, даже если нагрузка сильно превысит номинальные возможности сервиса.
Крайне важно провести тестирование с перегрузкой, прежде чем изучать механизмы ее предотвращения. Каждый из этих механизмов имеет свои сложности. Например, вспомните все параметры конфигурации на сервисных платформах, упомянутые в начале статьи, и как сложно было подобрать для них правильные значения. Каждый механизм предотвращения перегрузки добавляет определенные средства защиты и имеет ограниченную эффективность. В ходе тестирования команда может обнаружить узкие места системы и подобрать сочетание мер защиты, необходимое для устранения перегрузки.
Наглядность
В компании Amazon, независимо от используемых методик для защиты от перегрузки, мы серьезно обдумываем, какие метрики и какой уровень наглядности потребуются нам при вступлении в силу мер защиты от перегрузки.
Когда защита от сбоев отклоняет запрос, этот отказ снижает доступность сервиса. Когда сервис совершает ошибку и отклоняет запрос, несмотря на наличие ресурсов (например, если задано слишком низкое максимальное количество подключений), регистрируется ложное срабатывание. Мы стремимся свести количество ложных срабатываний к нулю. Если команда регулярно обнаруживает, что частота ложных срабатываний больше нуля, то либо для сервиса задана слишком высокая чувствительность, либо отдельные узлы подвергаются постоянной и реальной перегрузке. Это может указывать на проблему с масштабированием или балансировкой нагрузки. В таких случаях может потребоваться настройка работы приложения или переход на более крупные типы инстансов, которые лучше справляются с перепадами нагрузки.
С точки зрения наглядности, когда в результате сброса нагрузки отклоняются запросы, следует обеспечить наличие контрольно-измерительных средств, чтобы знать, кем был клиент, какую операцию он вызывал, а также другую информацию, которая поможет нам настроить меры защиты. Мы также используем оповещения, чтобы определить, отклоняют ли средства защиты какой-либо значительный объем трафика. При частичном отказе системы приоритетными задачами являются добавление ресурсов и устранение текущего узкого места.
Есть еще один неочевидный, но важный фактор, связанный с наглядностью при сбросе нагрузки. Мы поняли, как важно не сбивать метрики задержки в наших сервисах неудачными запросами. Все-таки задержка при сбросе запроса должна быть крайне низкой по сравнению с другими запросами. Например, если сервис сбрасывает 60 процентов трафика, то его средняя задержка может казаться отличной, несмотря на ужасную задержку удачных запросов, так как последняя недостаточно представлена из-за быстрого отклонения запросов.
Влияние сброса нагрузки на автоматическое масштабирование и зоны доступности
Неправильная настройка сброса нагрузки может привести к отключению реактивного автоматического масштабирования. Рассмотрим такой пример: для сервиса настроено реактивное масштабирование с учетом использования ЦП, а также сброс нагрузки для отклонения запросов при примерно такой же загрузке ЦП. В этом примере система сброса нагрузки сокращает количество запросов, чтобы поддерживать загрузку ЦП на низком уровне, а функция реактивного масштабирования получает сигналы о необходимости запуска новых инстансов с задержкой или вообще не получает их.
Мы также учитываем логику сброса нагрузки при настройке пределов автоматического масштабирования для реагирования на сбои зон доступности. Поддерживая задержку на нужном уровне, сервисы масштабируются до такой степени, что становятся недоступны объемы ресурсов, сопоставимые с несколькими зонами доступности. Команды компании Amazon часто используют такие метрики системы, как загрузка ЦП, чтобы примерно определить, насколько сервис близок к предельному использованию ресурсов. Однако при использовании сброса нагрузки парк может подходить намного ближе к тому моменту, когда потребуется отклонять запросы, чем показывают системные метрики, и не располагать достаточным объемом резервных ресурсов, чтобы устранить сбой зоны доступности. При использовании сброса нагрузки необходимо тщательно тестировать сервисы на отказ, чтобы иметь представление о ресурсах и запасе возможностей парка оборудования в тот или иной момент времени.
В действительности благодаря сбросу нагрузки можно сократить расходы, контролируя некритический трафик во внепиковые периоды. Например, если парк оборудования обрабатывает трафик веб-сайта amazon.com, он может решить, что трафик обходчика поисковой системы не стоит затрат ресурсов на его масштабирование до полной избыточности зоны доступности. Однако мы применяем этот подход очень осторожно. Не все запросы одинаково затратны, а чтобы доказать, что сервис должен обеспечивать избыточность зоны доступности для пользовательского трафика и при этом сбрасывать избыточный трафик обходчика, требуются тщательное проектирование, постоянное тестирование и поддержка руководства компании. А если клиентам сервиса неизвестно, что он настроен таким образом, его поведение во время сбоя зоны доступности может больше напоминать огромное критическое падение доступности, чем обычный сброс нагрузки. По этой причине в архитектуре, ориентированной на сервисы, мы стараемся выполнять такую обработку как можно раньше (например, в сервисе, который получает первоначальный запрос от клиента), а не пытаемся принимать глобальные решения о расстановке приоритетов в масштабе стека.
Механизмы сброса нагрузки
Что касается сброса нагрузки и непредсказуемых сценариев, также важно обращать внимание на множество предсказуемых условий, которые приводят к частичному отказу. В компании Amazon сервисы обладают достаточной избыточной мощностью, чтобы реагировать на сбои зон доступности, не задействуя дополнительные ресурсы. Они используют регулирование, чтобы обеспечить честные условия для клиентов.
Однако несмотря на эти средства защиты и методики эксплуатации, в любой момент сервис располагает определенными ресурсами, следовательно может быть перегружен по различным причинам. В их число входят неожиданные скачки трафика, внезапная потеря ресурсов парка (из-за некорректного развертывания или по другим причинам), а также переход клиентов с простых запросов (например, чтения из кэша) на сложные (например, промахи или запись в кэш). При перегрузке сервису необходимо выполнить принятые запросы. Таким образом, сервисам необходимо защищаться от частичного отказа. Далее в этом разделе мы рассмотрим некоторые особенности и методики, которые мы использовали за эти годы для контроля перегрузки.
Определение затрат на отклонение запросов
Мы обязательно проводим нагрузочные испытания своих сервисов, продолжая повышать нагрузку даже после того, как полезная пропускная способность стабилизируется. Одна из основных целей использования этого подхода – обеспечить как можно более низкие затраты на отклонение запросов во время сброса нагрузки. Мы увидели, как легко пропустить случайный оператор регистрации или настройку сокета, которые еще больше увеличат затраты на обработку запроса.
В редких случаях быстро отклонить запрос может быть дороже, чем удерживать его. В таких ситуациях мы замедляем отклоненные запросы в соответствии с (как минимум) задержкой успешных откликов. Однако это важно сделать, если затраты на удержание запросов максимально низки (например, если они не задерживают поток приложения).
Приоритеты запросов
При перегрузке сервер может анализировать входящие запросы и выбирать, какие из них принять, а какие отклонить. Самый важный запрос, который получит сервер, – это ping-запрос от балансировщика нагрузки. Если сервер не отвечает на ping-запросы вовремя, балансировщик нагрузки перестанет отправлять новые запросы на этот сервер в течение некоторого времени, а сервер будет простаивать. А в случае частичного отключения мы точно не захотим уменьшать размеры парков ресурсов. Что касается других запросов, параметры расстановки их приоритетов будут уникальными для каждого сервиса.
Рассмотрим веб-сервис, который предоставляет данные для рендеринга сайта amazon.com. Вызов сервиса, помогающий отрисовывать веб-страницы для обходчика поискового индекса, наверняка будет не так важен, как запрос, инициированный человеком. Обслуживание запросов обходчика важно, но в идеальной ситуации его можно перенести на внепиковое время. Однако в такой сложной среде, как amazon.com, где совместно работает большое количество сервисов, если эти сервисы используют конфликтующие эвристические алгоритмы расстановки приоритетов, то это может повлиять на доступность всей системы и привести к простоям в работе.
Расстановку приоритетов и регулирование можно использовать совместно, чтобы избежать строгих ограничений при регулировании, в то же время защищая сервис от перегрузки. В компании Amazon, когда мы разрешаем клиентам превышать заданные ограничения, избыточным запросам от этих клиентов можно назначать более низкие приоритеты, чем запросам от других клиентов, укладывающимся в квоту. Мы проводим много времени за изучением алгоритмов размещения, которые сводят к минимуму вероятность того, что дополнительные ресурсы будут недоступны. Однако с учетом компромиссов мы отдаем предпочтение предсказуемой подготовленной рабочей нагрузке.
Наблюдение за временем
Если сервис частично обработал запрос и заметил, что время ожидания клиента истекло, он может пропустить остальные задачи и отклонить запрос. В противном случае сервер продолжает обрабатывать запрос, а его поздний отклик останется незамеченным. С точки зрения сервера он вернул отклик об успешном выполнении. Однако с точки зрения клиента, время ожидания которого истекло, произошла ошибка.
Чтобы избежать лишнего расхода ресурсов, клиенты могут включать в каждый запрос подсказки о времени ожидания, которые сообщают серверу, сколько они готовы ждать. Сервер может оценивать эти подсказки и отклонять «обреченные» запросы с небольшими затратами.
Подсказка о времени ожидания может быть выражена как абсолютное время или продолжительность. К сожалению, серверы в распределенных системах пользуются печальной славой из-за проблем с согласованием времени. Сервис синхронизации времени Amazon компенсирует отклонения, синхронизируя часы инстансов Amazon Elastic Compute Cloud (Amazon EC2) с парком резервных спутниковых и атомных часов в каждом регионе AWS. Синхронизация часов также важна для компании Amazon при ведении журналов. Сравнение двух файлов журналов на серверах с рассинхронизированными часами делает устранение неполадок еще сложнее.
Еще один способ следить за временем – измерять продолжительность выполнения запросов на отдельных компьютерах. Серверам хорошо удается измерять прошедшее время в локальной среде, так как им не приходится согласовывать его с другими серверами. К сожалению, выражение времени ожидания в виде продолжительности тоже имеет свои недостатки. Например, используемый таймер должен быть монотонным и не возвращаться назад, когда сервер синхронизируется с протоколом сетевого времени (NTP). Намного более сложная проблема заключается в том, что для измерения продолжительности сервер должен знать, когда запускать секундомер. При особо сильной перегрузке в буферах протокола TCP может накапливаться большое количество запросов. К тому времени, когда сервер прочитает запросы из своих буферов, время ожидания клиента уже истечет.
Когда системы компании Amazon отправляют подсказки о времени ожидания, мы стараемся применять их транзитивно. В тех местах, где ориентированная на сервисы архитектура содержит несколько прыжков, мы распространяем показатель оставшегося времени на каждый из них, чтобы подчиненные сервисы в конце цепочки вызовов знали, сколько времени осталось для отправки полезного ответа.
Когда сервер узнает срок ожидания клиента, возникает вопрос, в каких случаях ограничивать срок в реализации сервиса. Если у сервиса есть очередь запросов, мы пользуемся этой возможностью оценить время ожидания после удаления каждого запроса из очереди. Но это все равно довольно сложно, ведь мы не знаем, сколько времени займет обработка запроса. Некоторые системы приблизительно оценивают время обработки запросов API и отклоняют запросы заранее, если указанное клиентом время ожидания меньше приблизительной задержки. Однако зачастую все не так просто. Например, попадания в кэш обрабатываются быстрее, чем промахи, а при прогнозировании неизвестно, что из этого произойдет. Серверные ресурсы сервиса могут быть разбиты на разделы, некоторые из которых могут работать медленно. Имеется множество возможностей для оригинальных решений, но такая изобретательность также может дать обратный эффект в непредсказуемой ситуации.
Наш опыт показывает, что принудительное применение сроков ожидания клиентов на сервере все равно лучше альтернативы, несмотря на сложности и компромиссы. Вместо того чтобы накапливать запросы (из-за чего сервер может обрабатывать запросы, которые уже никого не интересуют), мы применяем показатель времени жизни запроса и сбрасываем запросы, которые невозможно выполнить.
Завершение начатого
Мы не хотим, чтобы полезная работа пропадала зря, особенно при перегрузке. Выполнение работы впустую создает положительный цикл обратной связи, который повышает перегрузку, так как клиенты часто повторяют запрос, если сервис не отвечает вовремя. В таком случае один требовательный к ресурсам запрос превращается в несколько, умножая нагрузку на сервис. Когда время ожидания клиентов истекает и выполняется повторная попытка, они часто перестают ждать ответа при первом подключении, пока составляют новый запрос на отдельном подключении. Если сервер выполнит первый запрос и отправит отклик, клиент может не заметить его, так как теперь он ожидает ответа на повторный запрос.
Именно по этой причине мы стараемся проектировать сервисы с расчетом на ограниченную работу. Там, где доступен API, способный вернуть крупный набор данных (или вообще какой-либо список), мы предоставляем его с поддержкой разбиения на страницы. Такие API-интерфейсы возвращают часть результатов и токен, с помощью которого клиент может запросить дополнительные данные. Мы обнаружили, что спрогнозировать дополнительную нагрузку на сервис становится проще, если сервер обрабатывает запрос с верхним ограничением на использование памяти, ЦП и пропускной способности сети. Контролировать доступность ресурсов очень сложно, если серверу неизвестно, сколько времени займет обработка запроса.
Менее очевидная возможность для расстановки приоритетов запросов связана с тем, как клиенты используют API-интерфейсы сервиса. Допустим, у сервиса есть два API: start() и end(). Чтобы выполнять свою работу, клиентам необходима возможность вызывать оба API. В этом случае сервис должен отдавать запросам end() приоритет над запросами start(). Если бы предпочтение отдавалось запросам start(), клиенты не могли бы завершать начатую работу, что приводит к частичным отказам.
Еще одна причина выполнения лишней работы – разбиение на страницы. Если клиенту необходимо отправить несколько последовательных запросов для постраничного просмотра результатов из сервиса, но он обнаруживает сбой после страницы N-1 и удаляет результаты, то запросы к сервису на получение страницы N-2 и соответствующие повторные попытки выполняются впустую. Это подразумевает, что, как и запросы end(), запросы первой страницы должны иметь более высокий приоритет, чем запросы последующих страниц. А еще это демонстрирует, почему мы проектируем сервисы с расчетом на ограниченную работу без бесконечного перелистывания страниц из сервиса, вызываемого в ходе синхронной операции.
Наблюдение за очередями
При управлении внутренними очередями также полезно учитывать продолжительность выполнения запросов. Во многих современных архитектурах сервисов используются очереди в памяти, чтобы соединять пулы потоков для обработки запросов на различных этапах работы. Платформа веб-сервисов с исполнителем наверняка включает очередь, настроенную на переднем плане. Для каждого сервиса на основе протокола TCP операционная система поддерживает буфер для каждого сокета, а эти буферы могут содержать огромные объемы накопленных запросов.
Извлекая задачи из очередей, мы можем определять, насколько долго они ожидали выполнения. Как минимум, мы пытаемся записать эту длительность в показатели сервиса. Мы обнаружили, что важно ограничить не только размер очередей, но и время, в течение которого входящий запрос хранится в очереди. Просроченные запросы сбрасываются. Это освобождает ресурсы сервера для обработки более новых запросов, имеющих большую вероятность успешного выполнения. В качестве крайнего случая применения этого подхода мы рассмотрим способы применения очереди на основе модели «последним пришел, первым вышел» (LIFO), если протокол поддерживает ее. (Конвейеры запросов HTTP/1.1 для того или иного TCP-подключения не поддерживают очереди LIFO, но HTTP/2 в целом поддерживает их.)
Балансировщики нагрузки также могут добавлять в очередь входящие запросы или подключения при перегрузке сервисов, используя так называемые пиковые очереди. Использование таких очередей может привести к частичному отказу, так как даже получив запрос, сервер не знает, сколько времени этот запрос находился в очереди. В общем случае безопасным решением является использование конфигурации переполнения, которая быстро отклоняет избыточные запросы, а не ставит их в очередь. Компания Amazon встроила это решение в сервис Elastic Load Balancing (ELB) следующего поколения. Сервис Classic Load Balancer использовал пиковую очередь, но Application Load Balancer отклоняет избыточный трафик. Независимо от конфигурации, команды сотрудников Amazon отслеживают соответствующие метрики балансировщика нагрузки (например, глубину пиковой очереди или количество переполнений) для своих сервисов.
Наш опыт показывает, что невозможно переоценить важность отслеживания очередей. К своему удивлению, я часто нахожу очереди в памяти там, где мне и в голову не приходит искать их, – в системах и библиотеках, от которых зависят мои сервисы. Анализируя системы, полезно предполагать, что где-то есть очереди, о которых мы еще не знаем. Конечно, испытание на перегрузку дает больше полезной информации, чем разбор кода, при условии что удастся придумать подходящие и реалистичные сценарии тестирования.
Защита от перегрузки на нижних уровнях
Сервисы состоят из нескольких уровней – от балансировщиков нагрузки до операционных систем с возможностями netfilter и iptables, сервисных платформ и кода. Каждый уровень предоставляет определенные возможности по защите сервиса.
Многие прокси-серверы HTTP (например, NGINX) поддерживают настройку максимального количества подключений (max_conns) для ограничения количества активных запросов или подключений, передаваемых на фоновый сервер. Этот механизм может быть полезен, но мы предпочитаем использовать его в качестве крайней меры, а не стандартного варианта защиты. При использовании прокси-серверов сложно отдавать предпочтение важному трафику, а предварительный счетчик передаваемых запросов иногда предоставляет неточную информацию о том, перегружен ли сервис на самом деле.
В начале этой статьи я описывал задачу со времен моей работы в команде разработчиков сервисных платформ. Мы пытались определить рекомендуемое стандартное ограничение количества подключений, чтобы команды сотрудников Amazon могли задать его в своих балансировщиках нагрузки. В итоге мы порекомендовали сотрудникам задать высокие пределы количества подключений для балансировщиков нагрузки и прокси-сервера, поручив серверу реализацию более точных алгоритмов сброса нагрузки с учетом локальной информации. Однако важно следить, чтобы значение максимального количества подключений не превышало число потоков и процессов прослушивания, а также дескрипторов файлов на сервере. Это необходимо, чтобы сервер располагал достаточными ресурсами для обработки критически важных запросов на проверку работоспособности от балансировщика нагрузки.
Предусмотренные в операционной системе функции для ограничения использования ресурсов предоставляют широкие возможности и могут быть полезны в чрезвычайных ситуациях. А так как нам известно о возможности перегрузок, мы принимаем меры защиты, используя подходящие руководства и подготавливая конкретные команды. Утилита iptables может задавать верхнюю границу количества подключений, принимаемых сервером, и отклонять избыточные подключения намного экономичнее, чем какой-либо серверный процесс. Этот параметр также можно настраивать более изощренными средствами, например разрешив установку новых подключений с ограниченной скоростью или даже разрешить ограниченную скорость либо число подключений на исходный IP-адрес. Фильтры исходных IP-адресов эффективны, но неприменимы к традиционным балансировщикам нагрузки. Однако ELB Network Load Balancer сохраняет исходный IP-адрес отправителя даже на уровне операционной системы благодаря виртуализации сети, обеспечивая корректную работу правил iptables, например фильтров исходного IP-адреса.
Многоуровневая защита
В некоторых случаях ресурсов сервера не хватает даже для того, чтобы отклонять запросы без замедления работы. Учитывая этот факт, мы рассматриваем все прыжки между сервером и его клиентами, чтобы понять, как они могут взаимодействовать и помогать сбрасывать избыточную нагрузку. Например, некоторые сервисы AWS по умолчанию включают настройки сброса нагрузки. Предоставляя сервис через Amazon API Gateway, можно настроить максимальную скорость запросов для любого API. Предоставляя сервисы через API Gateway, Application Load Balancer или Amazon CloudFront, можно настроить в AWS WAF сброс избыточного трафика, задав ряд параметров.
Наглядность создает сложное противоречие. Раннее отклонение запросов важно, так как на этом этапе сброс избыточного трафика обходится дешевле всего, но при этом страдает наглядность. Именно поэтому наша защита делится на несколько уровней: сервер получает больше работы, чем он может выполнить, сбрасывает избыточный трафик и заносит в журнал достаточно информации, чтобы можно было выявить потери трафика. Так как сервер может сбросить ограниченное количество трафика, мы рассчитываем, что его передний уровень обеспечит защиту от предельных объемов трафика.
Новый взгляд на перегрузку
В этой статье упоминалось, что необходимость сбрасывать нагрузку вызвана замедлением работы систем при получении большого количества одновременных задач, когда становятся важны такие факторы, как ограничения ресурсов и конфликты. Цикл обратной связи при перегрузке образуется из-за задержки, которая в конечном итоге приводит к бесполезной работе, повышению частоты запросов и еще большей перегрузке. Важно избежать этого эффекта, обусловленного универсальным законом масштабируемости и законом Амдала, сбрасывая избыточную нагрузку и поддерживая предсказуемую, стабильную производительность даже при перегрузке. Ориентирование на предсказуемую и стабильную производительность – ключевой принцип проектирования сервисов Amazon.
Например, Amazon DynamoDB – это сервис баз данных, обеспечивающий предсказуемые производительность и доступность в нужных масштабах. Даже если рабочая нагрузка резко усиливается и превышает выделенный объем ресурсов, DynamoDB поддерживает для нее предсказуемую задержку полезной пропускной способности. Такие факторы, как автомасштабирование DynamoDB, адаптивное выделение ресурсов и работа по требованию, быстро реагируют, чтобы повышать полезную пропускную способность, адаптируясь к повышению рабочей нагрузки. В это время полезная пропускная способность остается стабильной, также поддерживая предсказуемую производительность сервиса на уровнях выше DynamoDB и повышая стабильность системы в целом.
AWS Lambda – еще более универсальный пример сервиса, ориентированного на предсказуемую производительность. При реализации сервиса с помощью Lambda каждый вызов API выполняется в отдельной среде, для которой выделяется стабильное количество вычислительных ресурсов. Эта среда выполнения всегда работает только с одним запросом. Этот подход отличается от серверной парадигмы, согласно которой каждый сервер работает с несколькими API-интерфейсами.
Изолируя каждый вызов API в независимых ресурсах (в вычислительных системах, в памяти, на диске или в сети), можно обойти закон Амдала в некоторых аспектах, так как ресурсы одного вызова API не будут конфликтовать с ресурсами другого. Следовательно, если нагрузка превысит полезную пропускную способность, последняя останется стабильной, вместо того чтобы падать, как в более традиционной серверной среде. Это не панацея, ведь зависимости могут замедляться, повышая количество одновременных операций. Однако в этом случае, по крайней мере, не будут возникать конфликты ресурсов узла, которые мы рассматривали в этой статье.
Такая изоляция ресурсов – относительно малозаметное, но важное преимущество современных бессерверных вычислительных сред, таких как AWS Fargate, Amazon Elastic Container Service (Amazon ECS) и AWS Lambda. В компании Amazon мы обнаружили, что реализация сброса нагрузки требует больших усилий: от настройки пулов потоков до выбора идеальной конфигурации максимального количества подключений к балансировщику нагрузки. Подобрать разумные стандартные значения для таких конфигураций очень трудно или невозможно, так как они зависят от уникальных эксплуатационных характеристик каждой системы. Эти новые бессерверные вычислительные среды обеспечивают изоляцию ресурсов нижнего уровня и предоставляют высокоуровневые регуляторы (например, средства управления ограничением и количеством одновременных операций) для защиты от перегрузки. В некотором смысле, вместо того чтобы гнаться за идеальным стандартным значением, мы можем полностью избежать этой настройки и обеспечить защиту от перегрузок различных типов без какой-либо конфигурации.
Дополнительные сведения
- Универсальный закон масштабируемости
- Закон Амдала
- Промежуточная архитектура на основе событий (SEDA)
- Закон Литтла (описывает параллельную обработку в системе и определение мощности распределенных систем)
- Истории о законе Литтла, блог Марка
- Углубленное знакомство с Elastic Load Balancing и рекомендации, презентация с конференции re:Invent 2016 (содержит описание эволюции Elastic Load Balancing с целью остановить добавление избыточных запросов в очередь)
- Бёрджесс, Thinking in Promises: Designing Systems for Cooperation, O’Reilly Media, 2015 г.
Об авторе
Дэвид Янацек работает старшим главным инженером в AWS Lambda. Дэвид разрабатывает программное обеспечение в Amazon с 2006 года, раньше работал над Amazon DynamoDB и AWS IoT, а также внутренними платформами веб-сервисов и системами автоматизации операций парка. Одно из любимых занятий Дэвида – анализ журналов и тщательная проверка операционных показателей. Таким образом он ищет способы сделать работу систем беспроблемной.

Нашли то, что искали сегодня?
Скажите, как улучшить качество контента на наших страницах