Aşırı yüklenmeyi engellemek için yük atma yöntemini kullanma
Yazılım Teslimi ve Operasyonlar | 400. DÜZEY
Giriş
Birkaç yıl boyunca Amazon'da Service Frameworks ekibinde görev yaptım. Amazon Route 53 ve Elastic Load Balancing gibi AWS hizmeti sahiplerinin hizmetlerini daha hızlı oluşturmalarına ve hizmet istemcilerinin bu hizmetleri daha kolay çağırmalarına yardımcı olan araçları ekibimiz yazmıştır. Diğer Amazon ekipleri hizmet sahiplerine ölçüm, kimlik doğrulama, izleme, istemci kitaplığı oluşturma ve belge oluşturma gibi işlevler sunmuştur. Her hizmet ekibi bu özellikleri hizmetlerine manuel olarak entegre etmek zorunda kalmak yerine, Service Frameworks ekibi bu entegrasyonu bir kereliğine sağlamış ve yapılandırma aracılığı ile bu işlevselliği her hizmete uygulamıştır.
Özellikle performans veya erişilebilirlik ile ilgili olan özelliklere yönelik hassas varsayılan ayarları sağlamak karşılaştığımız zorluklardan biri oldu. Örneğin, varsayılan istemci tarafı süre aşımı ayarını kolayca yapamadık çünkü çerçevemizin API gecikme süresi niteliklerinin ne olabileceği hakkında bir tahmini yoktu. Bu durum, hizmet sahipleri ya da istemcilerin çözümleyeceği basit bir durum olmayacaktı bu nedenle biz denemeye devam ettik ve bu yolda faydalı bilgiler edindik.
Aynı zamanda istemcilerin erişimine açık olacak hizmet sunucusu varsayılan bağlantı sayısının belirlenmesi bizi zorlayan sorulardan biri olmuştur. Bu ayar, bir sunucunun çok fazla çalışarak aşırı yük almasını engellemek amacıyla tasarlanmıştır. Özellikle sunucunun maksimum bağlantı ayarlarını, yük dengeleyici için maksimum bağlantılarla orantılı olarak yapılandırmak istedik. Bu durum Elastic Load Balancing işleminden önce olduğu için donanım yük dengeleyicileri yaygın olarak kullanılmaktaydı.
Amazon hizmet sahiplerine ve istemcilerine, yük dengeleyicisine ayarlanan maksimum bağlantılar için ideal değeri ve sunduğumuz çerçevelerinde ilgili değeri bulmaları konusunda destek olmak için yola çıktık. Seçim yapma konusunda insanların yargılarını nasıl kullanabileceğimizi bulabilirsek bu yargılara öykünmek için bir yazılım hazırlayabileceğimize karar verdik.
İdeal değeri belirlemek çok zorlu bir süreç oldu. Maksimum bağlantılar çok düşük ayarlansaydı yük dengeleyici, hizmetin yeterli kapasitesi olsa bile istek sayısında artışı kesebilirdi. Maksimum bağlantılar çok yüksek ayarlansaydı sunucular yavaşlayıp tepkisiz bir hale gelirdi. Maksimum bağlantılar iş yüküne doğru şekilde ayarlansaydı iş yükü değişecek veya bağımlılık performansı değişecekti. Sonra da değerler yanlış olup gereksiz kesintiler veya aşırı yüklenmeler meydana gelecekti.
Nihayetinde maksimum bağlantının sorunun tam cevabını veremeyecek kadar belirsiz olduğunu anladık. Bu çalışmada iyi çalıştığını bulduğumuz yük atma gibi diğer yaklaşımları ele alacağız.
Aşırı yük anatomisi
Amazon’da aşırı yüklenme durumlarıyla karşılaşmadan önce sistemlerimizi proaktif olarak ölçekleme yapmak üzere tasarlayarak aşırı yüklenmenin önüne geçeriz. Ancak sistemlerin korunması katman korunmasını da kapsar. Bu da otomatik ölçeklendirme ile başlar ancak aşırı yükü hassas bir şekilde atmak için mekanizma, bu mekanizmaları izleme imkanı ve en önemlisi sürekli test etmeyi de kapsar.
Hizmetlerimize yük testi yaptığımızda düşük kullanımdaki sunucunun gecikmesinin yüksek kullanımdaki gecikmeden daha düşük olduğunu buluruz. Ağır yük altında iş parçacığı çekişmesi, bağlam değişimi, çöp toplama ve G/Ç çekişmesi daha belirgin hale gelir. Sonuç olarak hizmet, performansı çok daha hızlı şekilde düşmeye başladığı bükülme noktasına varır.
Bu gözlemin dayandığı teori, Amdahl kanununun bir türevi olan Evrensel Ölçeklenebilirlik Kanunu olarak bilinir. Bu teoriye göre bir sistemin verimi paralelleştirme kullanılarak artırılabilirken bu verim serileştirme (paralelleştirilemeyen görevler) noktaları ile sınırlıdır.
Ne yazık ki verim yalnızca sistemin kaynakları tarafından sınırlandırılmamakta, aynı zamanda sistem aşırı yüklendiğinde de genellikle düşer. Sisteme kaynak desteğinden daha fazla iş yüklendiğinde sistem yavaşlar. Bilgisayarlar aşırı yüklendiği zaman bile çalışmaya devam eder ancak bağlam değiştirme süresi fazla uzar ve kullanışlı olabilmek için çok yavaşlar.
Bir istemcinin bir sunucuyla konuştuğu dağıtımlı bir sistemde istemci, sabırsızlanır ve belli bir süre sonra sunucunun yanıt vermesini beklemekten vazgeçer. Bu süre zaman aşımı olarak bilinir. Bir sunucu, gecikme istemcinin zaman aşımını geçecek kadar aşırı yüklendiği zaman istekler sekteye uğramaya başlar. Aşağıdaki grafik, sunulan aktarım hızı (işlemlerde saniye başına) arttıkça sunucu yanıt süresinin nasıl arttığını ve nihayetinde her şeyin hızlıca bozulduğu bükülme noktasına ulaştığını göstermektedir.
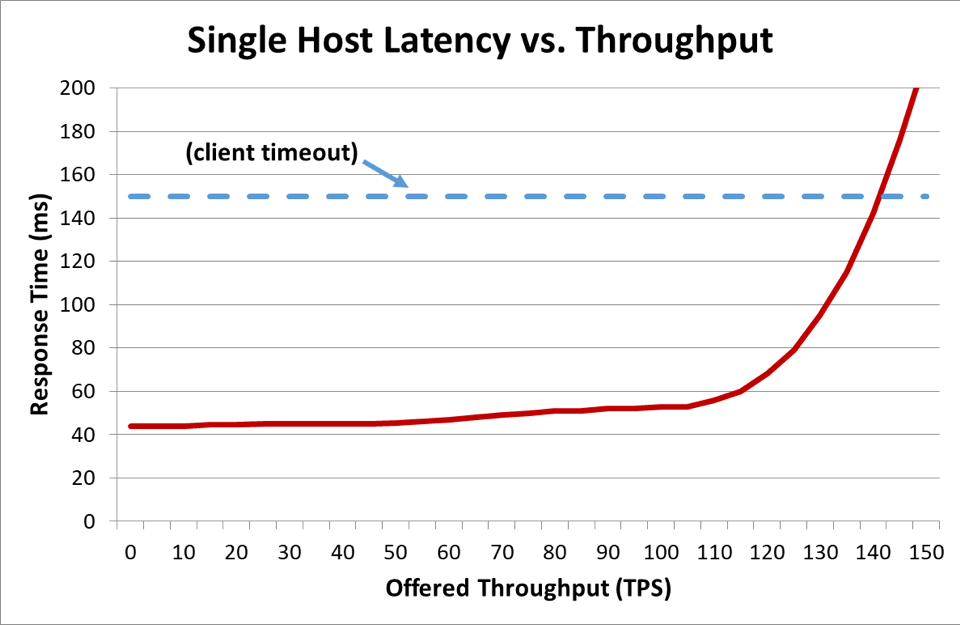
Önceki grafik, yanıt süresinin istemci zaman aşımını geçtiği zaman her şeyin kötü gittiğini gösterirken bunun derecesini göstermemektedir. Bunu açmak gerekirse gecikmenin yanında istemci tarafından algılanan erişilebilirliği belirleyebiliriz. Genel bir yanıt süresi ölçümü kullanmak yerine medyan yanıt süresini kullanabiliriz. Medyan yanıt süresi, isteklerin yarısının medyan değerinden daha hızlı olduğunu gösterir. Bir hizmetin medyan gecikme süresi istemcinin zaman aşımına denk ise isteklerin yarısı zaman aşımına uğrar, böylelikle erişilebilirlik yüzde ellidir. Bu da gecikmedeki artışın gecikme sorununun erişilebilirlik sorununa dönüşmesine neden olur. Aşağıdaki grafik bunun nasıl olduğunu göstermektedir:
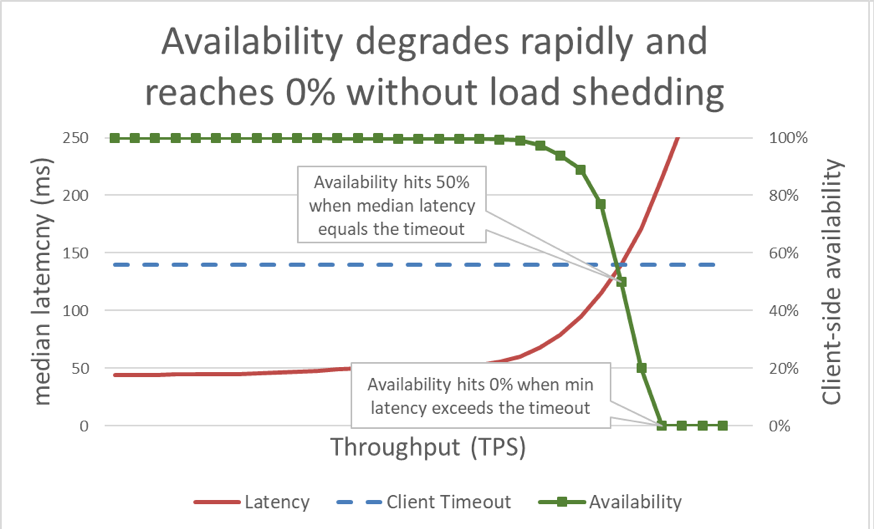
Ne yazık ki bu grafiğin okunması zordur. Erişilebilirlik sorununu tanımlamanın kolay bir yolu kullanılabilir veri miktarını verimden ayırmaktır. Verim, sunucuya saniye başına iletilen toplam istek sayısıdır. Kullanılabilir veri miktarıysa hata olmaksızın işleyen ve istemcinin yanıtı kullanabileceği kadar düşük gecikme süresi olan aktarım hızının alt kümesidir.
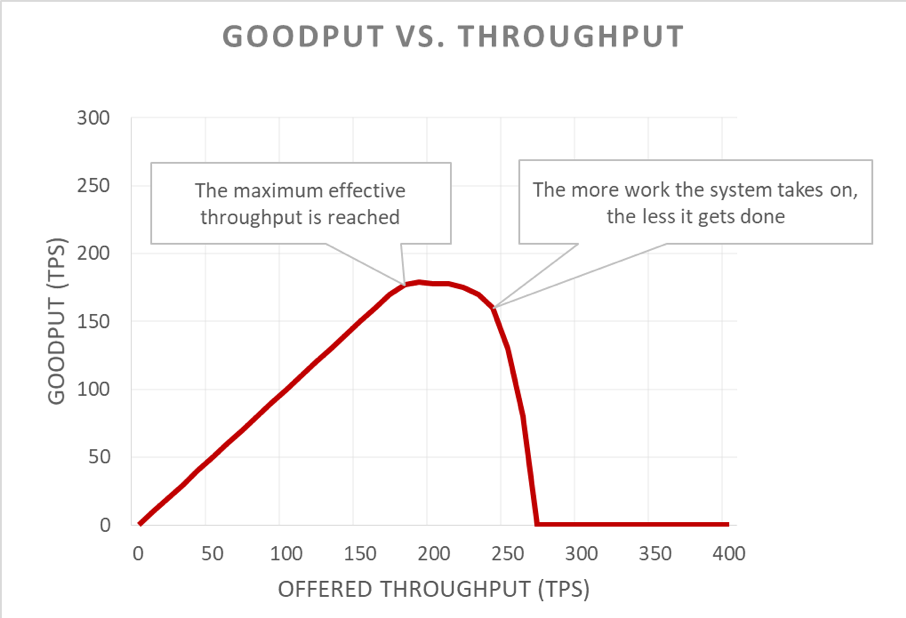
Pozitif geri bildirim döngüleri
Aşırı yüklenme durumunun gizli tarafı geri bildirim döngüsünde nasıl ilerlediğidir. İstemci zaman aşımına uğradığı zaman hatanın oluşması oldukça kötü bir durumdur. Bundan daha da kötüsü sunucunun o ana kadar o istekle ilgili sağladığı tüm ilerlemeler boşa gidecektir. Sistemin, kapasitenin sınırlandığı aşırı yüklenme durumunda yapması gereken en son şey ise yapılan işin heba olmasıdır.
Sorunları daha da kötü hale getiren şey de istemcilerin isteklerini sıklıkla yeniden denemeleridir. Bu da sistemde sunulan yükü arttırır. Ayrıca hizmet odaklı bir mimaride yeterince derin bir çağrı çizgesi varsa (istemci bir hizmeti, hizmet diğer hizmetleri, diğer hizmetler başka hizmetleri arar) ve her bir katman birkaç deneme yaparsa alt katmandaki aşırı yük, sunulan yükü katlayarak arttıran art arda yeniden denemelere yol açar.
Bu faktörler bir araya geldiğinde aşırı yük, istikrarlı bir durum olarak aşırı yüklenmeye neden olan kendi geri bildirim döngüsünü oluşturur.
İşin heba olmasını engelleme
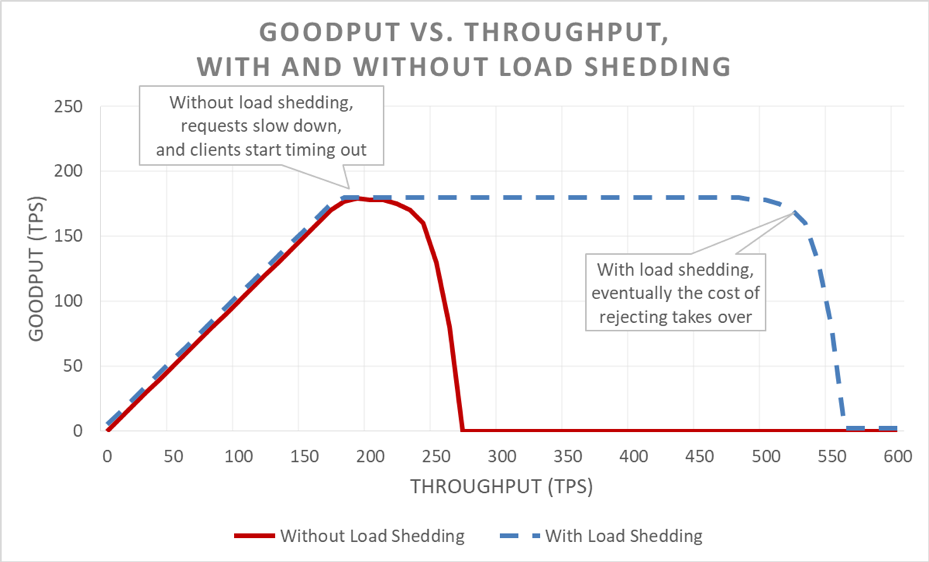
Yüzeyde yük atma durumu kolaydır. Bir sunucu aşırı yüklenmeye giderse erişime izin vereceği isteklere odaklanabilmesi için aşırı istekleri reddetmeye başlamalıdır. Yük atmanın amacı, istemci zaman aşımına uğramadan önce sunucunun yanıt vermeyi kabul ettiği isteklerin gecikme süresini kısa tutmaktır. Bu yaklaşımla sunucu, kabul ettiği istekler için yüksek düzeyde erişilebilirlik sağlar ve yalnızca fazla olan trafiğin erişilebilirliği bu olumsuzluktan etkilenir.
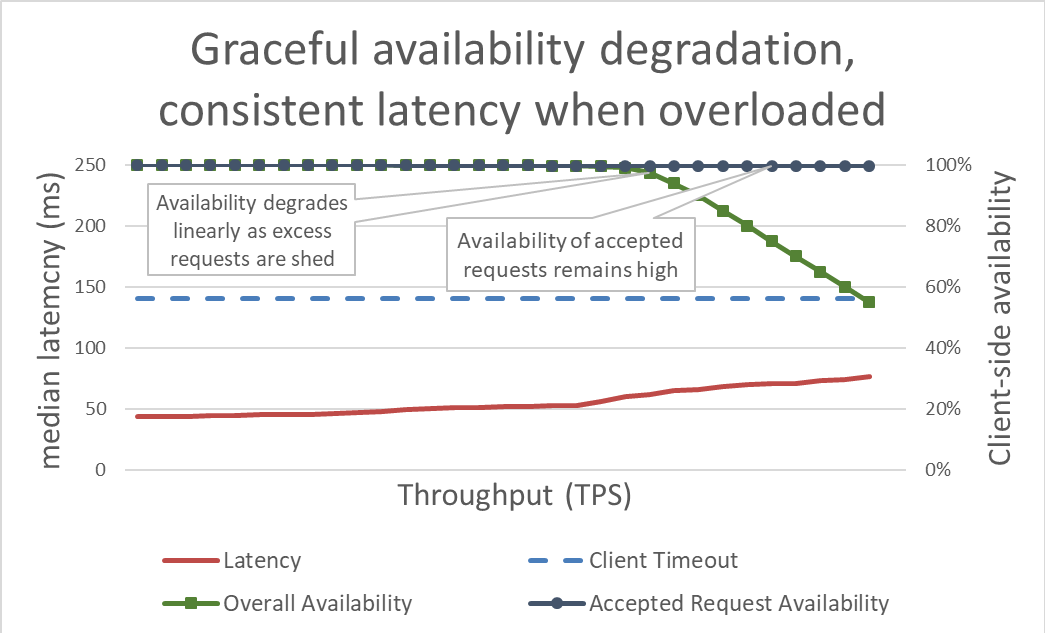
Gecikme süresinin fazla yük atılarak kontrol edilmesi sistemi daha erişilebilir hale getirecektir. Ancak bu yaklaşımın faydalarının önceki grafikten görülmesi zordur. Genel erişilebilirlik çizgisi hala aşağıya ilerlemekte, bu da durumun kötü olduğunu gösteriyor. Burada önemli olan husus sunucunun kabul etmeye karar verdiği isteklerin hızlı bir şekilde sunuldukları için kullanılabilir halde olmasıdır.
Yük atma, sunucunun kullanılabilir veri miktarını sürdürmesine ve teklif edilen verim arttığında bile olabildiğince çok isteği yerine getirmesine olanak sağlar. Ancak yük atma durumu serbest değildir ve nihayetinde sunucu, Amdahl kanununa ve kullanılabilir veri miktarına yenik düşer.
Test
Diğer mühendislerle yük atma ile ilgili konuştuğumda hizmetlerini, kesildiği noktaya ve bu noktanın çok daha ötesine kadar yük testinden geçirmemişlerse hizmetin mümkün olduğunca az oranda hatalı olacağını varsaymaları gerektiğini belirtmek isterim. Amazon’da hizmetlerimizin yük testi için bir hayli zaman harcamaktayız. Bu makalede daha önce geçen grafikleri oluşturmak bize aşırı yük performansının ana hattını çizmemizi ve zaman içerisinde hizmetlerimizde değişiklik yaptıkça bunların takibini yapmamızı sağlar.
Yük testinin pek çok türü vardır. Bazı yük testleri, diğerleri sabit bir filo boyu kullanırken yük arttıkça filonun otomatik olarak ölçeklendirme yapmasını sağlar. Aşırı bir yük testinde verim arttıkça hizmet erişilebilirliği sıfıra doğru hızlıca düşmesi hizmetin ilave yük atma mekanizmalarına gereksinim duyduğu anlamına gelen iyi bir işarettir. İdeal yük testi sonucu, hizmet tam olarak kullanılmaya yakın ise kullanılabilir veri miktarının yatay seyirde ilerlemesi olup daha fazla verim uygulandığında ise düz kalmasıdır.
Chaos Monkey gibi araçlar hizmetlerde kaos mühendisliği testlerini yürütmeye yardımcı olur. Örneğin, CPU üzerinde aşırı bir yüklenme oluşturur ya da aşırı yüklenme sırasında oluşan durumları simüle etmek üzere paket kayıplarını bildirir. Kullandığımız bir başka test tekniği ise kanarya veya mevcut yük oluşturma testi uygulamak, sürekli yükü (artan yükün yerine) test ortamına doğru sürerken sunucuları bu ortamdan kaldırmaya başlamaktır. Bu da örnek başına sunulan verimi artırır, böylelikle örnek verimini test edebilir. Filo boyutlarını azaltarak yapay şekilde artan yükün bu tekniği, bir hizmeti tek başına test etmek için yararlıdır ancak tam yük testlerinin yerine geçmemektedir. Tam, uçtan uca bir yük testi performans sorunlarını ortaya çıkaracak bu hizmetin bağımlılıklarına olan yükü de arttıracaktır.
Testlerin yapıldığı esnada istemci tarafından algılanan erişilebilirlik ve gecikme ile beraber sunucu tarafı erişilebilirliği ve gecikme süresi ölçümünü yapmaktayız. İstemci tarafı erişilebilirliği azalmaya başladığında yükü bu noktadan çok uzağa itiyoruz. Yük atma çalışır durumda ise kullanılabilir veri miktarı, hizmetin ölçeklendirilmiş yeterliliklerinin ötesinde sunulan verim arttığında bile istikrarlı kalacaktır.
Aşırı yük testi, aşırı yüklenmeyi önlemek için mekanizmaların araştırılmasından daha önemlidir. Her mekanizmada karmaşıklık mevcuttur. Örneğin, makalenin başında bahsettiğim hizmet çerçevelerindeki tüm yapılandırma seçeneklerini ve varsayılanların hiç hata yapmamasının ne kadar zor olduğunu göz önünde bulundurun. Aşırı yüklerden kaçınmak için her mekanizma farklı korumalar ilave etmekle birlikte sınırlı bir etkililiğe sahiptir. Test yoluyla ekip, sistemdeki performans sorunlarını tespit edebilir, aşırı yüke müdahale etmek için gerekli olan korumaları belirleyebilir.
Görünürlük
Amazon’da hizmetlerimizi aşırı yüklerden korumak için hangi teknikleri kullandığımıza bakmaksızın bu önlemler etkili olduğunda ihtiyaç duyduğumuz ölçümler ve görünürlük hakkında dikkatlice düşünürüz.
Karartma koruması bir isteği reddettiği zaman bu ret hizmetin erişilebilirliğini düşürür. Kapasitesi olduğu halde hizmet tersini anladığında ve bir isteği reddettiğinde (ör. maksimum bağlantı sayısı çok yavaş ayarlandığında) yanlış olan bir pozitif üretir. Biz verdiğimiz hizmette yanlış pozitifi sıfırda tutmaya çalışıyoruz. Bir ekip hizmetlerindeki yanlış pozitif oranının düzenli bir şekilde sıfır olmadığını tespit ederse hizmet ya çok hassas bir şekilde ayarlanmıştır ya da bireysel sistemler sabit şekilde ve yasal olarak aşırı yüklenmiş durumdadır; ve ölçeklendirme ya da yük dengeleme sorunu olabilir. Bu tür durumlarda uygulama performans ayarları yapabilir ya da yük dengesizliklerini daha incelikle ele alabilecekleri daha büyük bulut sunucusu tiplerine geçiş yapabiliriz.
Görünürlük bakımından yük atma, istekleri reddettiğinde istemcinin kim olduğunu belirleyecek araçlarımız olduğundan, hangi işlemleri yapmaya çalıştığını ve koruyucu önlemleri almamızı sağlayan diğer bilgileri edindiğimizden emin oluruz. Ayrıca önlemlerin önemli düzeyde trafik hacmini reddedip reddetmediğini tespit eden alarmlar kullanıyoruz. Karartma mevcut olduğunda önceliğimiz kapasiteyi arttırıp mevcut performans sorununu gidermektir.
Yük atmada görünürlükle ilgili ince ayrıntılı ancak önemli bir husus daha vardır. Hizmetlerimizin gecikme metriklerini hatalı istek gecikmeleri ile kirletmemenin önemli olduğunu keşfettik. Her şeyden önce bir yük atma isteğinin gecikmesi diğer isteklere kıyasla çok daha az olmalıdır. Örneğin, bir hizmet trafiği yükünün yüzde 60’ını atıyorsa hatasız istek gecikmesi korkunç düzeyde olsa da hizmetin medyan gecikmesi oldukça şaşırtıcı görünebilir çünkü hızlı hatalı isteklerin bir sonucu olarak daha az rapor edilmektedir.
Yük atmanın otomatik ölçeklendirme ve Erişilebilirlik Alanı hatası üzerinde etkileri
Yanlış yapılandırıldığı zaman yük atma reaktif otomatik ölçeklendirmeyi devre dışı bırakabilir. Aşağıdaki örneği inceleyin: bir hizmet CPU tabanlı reaktif ölçekleme için yapılandırılmıştır ve benzer bir CPU hedefindeki istekleri reddetmek üzere yapılandırılmış yük atma özelliğine de sahiptir. Bu durumda yük atma sistemi, CPU yükünü düşük tutmak için istek sayısını azaltacak ve reaktif ölçeklendirme, yeni örnekleri başlatmak için kesinlikle gecikmeli bir sinyal almayacaktır.
Erişilebilirlik Alanı arızalarını gidermek için otomatik ölçeklendirme limitleri belirlediğimizde ayrıca yük atma mantığını da göz önünde bulunduruyoruz. Gecikme hedeflerimizi korurken hizmetler, Erişilebilirlik Alanı kapasite değerinin kullanılamayacağı bir noktaya ölçeklendirilir. Amazon ekipleri genellikle bir hizmetin kapasite sınırına ne kadar yakın olduğunu belirlemek için CPU gibi sistem ölçümlerini takip eder. Ancak yük atma ile filo, isteklerin reddedileceği noktaya sistem ölçümlerinin gösterdiğinden çok daha yakın olabilir ve Erişilebilirlik Alanı hatasını gidermek için gerekli ek kapasiteye sahip olmayabilir. Yük atma ile filomuzun kapasitesini ve boşluk payını her zaman anlayabilmemiz için hizmetlerimizi kırılmaya karşı test etmemiz gerektiğinden çok emin olmalıyız.
Aslında yoğun ve kritik olmayan trafiğe şekil vererek maliyetleri azaltmak için yük atma özelliğini kullanabiliriz. Örneğin bir filo, amazon.com web sayfasını ele alırsa web trafiğinin tam Erişilebilirlik Alanı fazlalığı için ölçeklendirilmesinin masrafına değmeyeceğine karar verebilir. Ancak bu yaklaşıma karşı dikkatli davranıyoruz. Tüm isteklerin maliyeti aynı değildir ve bir hizmetin insan trafiği ve fazla trafiğin yükünü aynı anda atmak için Erişilebilirlik Alanı yedeğini sağlamak dikkatli bir tasarım, sürekli test ve işletme desteği gerektirir. Ayrıca bir hizmetin istemcileri hizmetin bu şekilde yapılandırıldığını bilmezse Erişilebilirlik Alanı hatası sırasındaki davranışı, kritik olmayan yük atma yerine çok büyük kritik erişilebilirlik düşüşü gibi görünebilir. Bu nedenle yığın boyunca global önceliklendirme kararları vermeye çalışmak yerine hizmet odaklı bir mimaride bu tür yapılandırmaları olabildiğince çabuk elemeye çalışıyoruz (istemciden ilk isteği alan hizmette olduğu gibi).
Yük atma mekanizmaları
Yük atma ve öngörülemeyen senaryolar tartışıldığında karartmaya yol açan tahmin edilebilir pek çok koşul üzerine odaklanmak da önemlidir. Amazon’da hizmetler, daha fazla kapasite eklemesi yapmaksızın Erişilebilirlik Alanı hatasını gidermek için yeterli ek kapasiteyi sürdürür. İstemciler arasında adaleti sağlamak için kısıtlamayı kullanırlar.
Ancak tüm bu önlemlere ve operasyonel uygulamalara rağmen bir hizmet, herhangi bir zamanda belirli bir kapasiteye sahiptir ve birçok sebepten ötürü aşırı yüklenebilir. Bu nedenler arasında trafikte beklenmeyen artışlar, filonun ani kapasite kaybı (kötü dağıtım veya başka nedenler), ucuz isteklerden (önbelleğe alınan okumalar gibi) pahalı isteklere (önbellek kaçışları veya yazmaları) eğilim gösteren istemciler bulunur. Hizmet aşırı yüklendiğinde yüklendiği istekleri tamamlamalıdır, yani hizmetler kendilerini karartmalardan kurtarmalıdır. Bu bölümün geri kalanında aşırı yükü yıllar içinde nasıl yürüttüğümüzü gösteren teknik ve yaklaşımları ele alacağız.
Sonlandırma isteklerinin maliyetlerini anlama
Hizmetlerimizi kullanılabilir veri miktarının durağan hale geldiği noktanın ötesinde yük testine tabi tutuyoruz. Bunun ana sebeplerinden biri de yük atma esnasında istekleri azalttığımızda istekleri azaltma maliyetini olabildiğince düşük tutmaktır. İstek azaltma maliyetini olması gerekenden çok daha yüksek hale getirebilen rastlantısal günlük dökümü veya soket ayarını kaçırmanın kolay olduğunu gördük.
Nadir durumlarda bir isteği hızlı şekilde azaltmak, isteği yerine getirmekten daha pahalı olabilmektedir. Bu tür durumlarda, başarılı yanıtların gecikmesini eşleştirmek (minimum düzeyde) için reddedilen istekleri yavaşlatıyoruz. Ancak isteği yerine getirmenin maliyeti olabildiğince düşük olduğunda bunu yapmak önemlidir; örneğin, uygulama iş parçacığının bağlanmadığı zamanlar.
İsteklere öncelik verilmesi
Bir sunucu aşırı yüklendiğinde gelen isteklerin içinden hangisini kabul edip hangisini reddedeceğini belirlemek amacıyla öncelik sırasına koyma olanağına sahiptir. Sunucunun yük dengeleyiciden alabileceği en önemli istek ping isteğidir. Sunucu, ping isteğine zamanında cevap vermezse yük dengeleyici, bu sunucuya belli bir süre yeni istekleri göndermeyi bırakacak ve sunucu boşta duracaktır. Karartma durumu söz konusu olduğunda da en son yapmak isteyeceğimiz şey filomuzun boyutunu düşürmek olur. Ping isteklerinin ötesinde istek önceliği, verilen hizmete göre değişiklik göstermektedir.
Amazon.com sitesini çalıştırmak için veri sağlayan bir web hizmeti düşünün. Arama indeksi ağı için web sayfası oluşturma desteği veren hizmet çağrısının insan kaynaklı bir istekten daha önemli olması daha az olası bir durumdur. Web isteklerini yerine getirmek önemlidir ancak tercih olarak yoğun olmayan bir zamana kaydırılabilir. Bununla birlikte pek çok hizmetin yürütüldüğü amazon.com gibi komplike ortamlarda hizmetler, karmaşık öncelik verme keşiflerini kullanırsa sistemin genelinde erişilebilirlik etkilenebilir ve iş heba olabilir.
Öncelik verme ve kısıtlama, hizmetin aşırı yükten korunduğu üst düzey kısıtlamalarından kaçınmak için birlikte kullanılabilir. Amazon’da yapılandırılmış kısıtlama sınırlarının üzerinde artış için istemcilerimize izin verdiğimiz durumlarda bu istemcilerden gelen aşırı isteklere, diğer istemcilerden gelen kota içi isteklerden daha az öncelik sağlanır. Artan kapasitesinin kullanılamaması olasılığını en aza indirgemek için yerleştirme algoritmalarına odaklanmaya çok zaman harcıyoruz ancak değişimler düşünüldüğünde öngörülebilir iş yükünü tahmin edilemeyen iş yüküne tercih ediyoruz.
Süreye dikkat edilmesi
Bir hizmet yarıya gelmişse ve istemcinin zaman aşımına uğradığını anlarsa işin geri kalanını atlar ve o noktada isteği yerine getirmez. Aksi durumda hizmet sunucusu, istek üzerinde çalışmaya devam eder ve geç gelen cevabı bir ağacın ormanda düşmesine benzer. Sunucunun bakış açısıyla başarılı bir yanıt vermiş olur. Ancak zaman aşımına uğrayan istemci bakış açısına göre bu bir hatadır.
Bu heba olan işin önüne geçmenin bir yolu istemciler, her istekte sunucuya ne kadar beklemek istediklerini belirten zaman aşımı ile ilgili ipuçları barındırmasıdır. Sunucu bu ipuçlarını hesap eder ve mecburi istekleri az bir maliyetle düşürür.
Bu zaman aşımı ipuçları, mutlak bir süre veya süreç olarak ifade edilebilir. Ne yazık ki sunucular, dağıtılmış sistemde şu anki saatin ne olduğu hakkında fikir birliği sunmamaktadır. Amazon Zaman Eşitleme Hizmeti sahip olduğunuz Amazon Elastic Compute Cloud (Amazon EC2) bulut sunucu saatlerini her AWS Bölgesinde yedekli uydu kontrollü ve atomik saatler filosu ile senkronize ederek denge sağlamaktadır. İyi senkronize edilmiş saatler, günlüğe kaydetme amaçlı olarak da Amazon’da önemlidir. Senkronize olmayan saatleri olan sunuculardaki iki günlük dosyasının karşılaştırılması sorun gidermeyi başlangıçta olduğundan daha zor hale getirir.
“Saati saymanın” diğer yolu da tek bir makinedeki süreyi ölçmektir. Sunucular tüketilen zamanı ölçmede iyidir çünkü diğer sunucularla fikir birliği sağlamaları gerekmemektedir. Ne yazık ki zaman aşımlarını süreç bakımından ifade etmek de sorunludur. Özellikle kullandığınız zamanlayıcı monoton olmalı ve sunucu Ağ Zaman Protokolü (NTP) ile senkronize olduğunda geriye doğru gitmemelidir. Bundan daha da zor olanı, sürecin hesaplanması için sunucunun süreölçeri ne zaman başlatması gerektiğini bilmesidir. Bazı aşırı yük durumlarında yüksek hacimdeki istekler, İletim Denetimi Protokolü (TCP) geçici belleğinde sıraya girer, böylelikle sunucu, istekleri geçici bellekten okuyana kadar istemci zaman aşımına uğramış olur.
Amazon’daki sistemler, istemci zaman aşımı ipuçlarını her ifade ettiğinde bunları geçici olarak uygulamaya çalışırız. Hizmet odaklı mimarinin çok sayıda durak içerdiği yerlerde duraklar arasında “kalan süre” son tarihini yayıyoruz. Böylece çağrı zincirinin sonunda aşağı akış hizmeti, yanıtının ne kadar faydalı olduğunun farkında olabilir.
Sunucu, istemcinin son tarihini bildikten sonra sıra hizmet uygulamasında son tarihin nerede uygulanacağı sorusuna gelir. Hizmette istek sırası varsa bunu, her birini sıradan çıkardıktan sonra zaman aşımını değerlendirerek kullanıyoruz. Ancak bu halen karmaşık bir uygulamadır çünkü isteğin ne kadar süreceği konusunda bilgimiz olmuyor. Bazı sistemler, API isteklerinin ne kadar süreceği konusunda tahmin yapmakta ve istemcinin tahmini son gecikme tarihini aşması durumunda istekleri düşürmektedir. Ancak işler bu kadar basit değildir. Örneğin, önbellek isabetleri isabetsiz önbelleklerden daha hızlıdır, değerlendirici de bunun isabet mi isabetsizlik mi olduğunu bilmemektedir. Hizmetin arka uç kaynakları kısımlara ayrılmış olabilir ve yalnızca bazı kısımlar yavaş olabilir. Beceriklilikte pek çok fırsat vardır ancak bunun tahmin edilemeyen bir durumda geri tepmesi de olasıdır.
Kendi deneyimlerimize dayanarak karmaşıklıklara ve değişimlere rağmen sunucudaki istemci zaman aşımlarını zorlamak hâlâ diğer alternatiflerden daha iyi bir seçenektir. Yığılan isteklerin ve kimse için bir önemi kalmayan isteklerin üzerinde çalışan sunucunun yerine “istek üzerine yaşam süresi”nin uygulanmasının ve mecburi isteklerin çıkarılmasının yararlı olduğunu gördük.
Başlanan işin bitirilmesi
Yararlı olan hiçbir işin özellikle de aşırı yüklenmede heba olmasını istemeyiz. Çalışmanın çıkarılması, istemciler genellikle zamanında yanıt alamadıklarında isteklerini yeniledikleri için aşırı yükü artıran pozitif bir geri bildirim döngüsü oluşturur. Bu olduğu zaman kaynağı tüketen bir istek, hizmet üzerindeki yükü katlayarak çoklu kaynak tüketen bir isteğe dönüşür. İstemciler zaman aşımına uğrayıp tekrar denediklerinde farklı bir bağlantıda yeni bir istek gerçekleştirirken genellikle ilk bağlantılarında beklemekten vazgeçer. Sunucu ilk isteği bitirip yanıt verse de istemci, dikkatini vermemiş olabilir çünkü yinelenen isteğinn bir yanıt bekliyordur.
Bu boşa giden çalışma sorunu sınırlı iş yürütmek üzere hizmetleri tasarlama nedenimizdir. Büyük bir veri kümesi (veya herhangi bir liste olmaksızın) döndürebilecek bir API’yi gösterdiğimiz yerlerde bunu sayfalandırmayı destekleyen bir API olarak göstermekteyiz. Bu API'ler, kısmi sonuç ve istemcinin daha fazla veri istemek için kullanabileceği bir belirteç sunar. Sunucu; bellek, CPU ve ağ bant genişliği miktarı için üst sınırı olan bir isteği işlediğinde hizmet üzerindeki ek yükü tahmin etmenin daha kolay olduğunu keşfettik. Bir isteği işlemenin ne kadar süreceğine dair sunucunun herhangi bir fikri olmadığında giriş kontrolünü gerçekleştirmek çok zordur.
İsteklere öncelik sağlamada daha ustaca çözüm istemcilerin, bir hizmetin API'lerini nasıl kullandığıdır. Örneğin, bir hizmete ait iki API olduğunu varsayalım: başlangıç() ve bitiş(). Bu işi tamamlamak için istemcilerin her iki API’yi arayabilmesi gerekmektedir. Bu durumda hizmet, bitiş() isteklerini başlangıç() isteklerine karşı ön planda tutmalıdır. Şayet başlangıç() önceliği verilirse istemci, karartma ile sonuçlanan işi tamamlama şansı elde edemeyecektir.
Sayfalandırma heba edilen iş için bir başka izleme yeridir. Bir istemcinin bir hizmetten elde edilen sonuçları sayfalandırmak için sıralı birkaç istekte bulunması gerekiyorsa ve N-1 sayfasından sonra hata görüyor ve sonuçları çıkarıyorsa N-2 hizmet aramalarını ve uyguladığı tüm denemeleri boşa harcıyor demektir. Bu da bize bitiş() istekleri gibi ilk sayfa isteklerine, sonraki sayfalandırma isteklerinden sonra öncelik verilmesi gerektiğini gösteriyor. Ayrıca senkronize işlem sırasında çağırdıkları bir hizmet aracılığıyla neden sınırlı işler yapmak için hizmet tasarladığımızın ancak sınırsız olarak sayfalandırma yapılmadığının altını çiziyor.
Kuyruklara dikkat edilmesi
İç sıralar yönetilirken istek süresine bakmakta fayda vardır. Pek çok modern hizmet mimarisi, çeşitli iş aşamaları sırasında istekleri işlemek amacıyla iş parçacığı havuzlarını bağlamak için bellek içi sıraları kullanır. Uygulayıcısı olan bir web hizmet çerçevesinin önünde yapılandırılmış bir sıraya sahip olması olasıdır. İşletim sistemi, herhangi bir TCP tabanlı hizmetle her soket için bir ara bellek tutar, bu ara bellekler de çok sayıda bastırılmış istek içerebilir.
İşleri sıradan çıkardığımızda sırada ne kadar işin kaldığını inceleme fırsatını elde ederiz. En azından kendi ölçümlerimizde bu süreyi kaydetmeye çalışırız. Sıraların boyutunu sınırlamanın yanı sıra gelen isteklerin sıraya girmesine ilişkin süre miktarı için üst sınır belirlemenin ve süresi çok geçmişse atmanın ne kadar önemli olduğunu gördük. Bu da, başarı şansı çok daha yüksek olan yeni istekler üzerinde çalışmak için sunucu üzerinde boş alan yaratır. Bu yaklaşımın en uç noktası olarak, protokol destekliyorsa bunun yerine son giren ilk çıkar (LIFO) kuyruğu kullanmanın yöntemlerini ararız. (HTTP/1.1 belirli bir TCP bağlantısındaki istek sıralaması LIFO sırasını desteklemezken HTTP/2 genellikle destekler.)
Yük dengeleyici de, dalgalanma sıraları adı verilen bir özellik kullanarak hizmetler aşırı yüklendiği zaman gelen istek veya bağlantıları sıraya sokabilir. Bu sıralar, karartmaya yol açabilir çünkü bir sunucu nihayetinde istek aldığı zaman isteğin sırada ne kadar beklediğini bilmez. Genel anlamda güvenilir bir varsayım, hemen hata veren aşırı istekleri sıraya koymak yerine yayılma yöntemini kullanır. Amazon’da bu bilgi, Elastic Load Balancing (ELB) hizmetinin gelecek nesli için hazırlanmıştır. Classic Load Balancer dalgalanma sırası kullanırken Application Load Balancer aşırı trafiği reddeder. Yapılandırmaya bakılmaksızın Amazon’da ekipler, verdikleri hizmette dalgalanma sırasının derinliği veya yayılma sayısında olduğu gibi ilgili yük dengeleyici ölçümlerini izler.
Kendi deneyimlerimize dayanarak sıraya dikkat etmenin önemi göz ardı edilemez. Genellikle güvendiğim sistemlerde ve kütüphanelerde sezgisel olarak aramayı düşünmediğim bellek içi sıralar bulduğumda şaşırırım. Sistemlere girdiğimde henüz bilmediğim yerlerde bir sıra olduğunu varsaymanın faydalı olduğunu biliyorum. Elbette aşırı yük testi, doğru ve gerçek testlerle çözüm bulduğum sürece kodların içine girmekten daha faydalı bilgiler sağlar.
Alt katmanlarda aşırı yükten korunma
Hizmetler çeşitli katmanlardan oluşur, bunlar; yük dengeleyicileri, netfilter ve iptables kapasiteleri işletim sistemleri, hizmet çerçevesi ve kod olup her katman hizmeti korumaya yönelik belirli kapasiteyi sağlar.
NGINX gibi HTTP proxy’ler, arka uç sunucusuna ilettiği etkin istek veya bağlantı sayısını sınırlamak için maksimum bağlantı özelliğini (max_conns) genel olarak destekler. Her ne kadar yararlı bir mekanizma olsa da bunu varsayılan koruma seçeneği yerine son çare olarak kullanmayı öğrendik. Proxy’lerle önemli trafiğe öncelik sağlamak zordur ve işlenmemiş boşluktaki istek sayımı takibi hizmetin gerçekten aşırı yüklü olup olmadığına ilişkin bazen yanlış bilgiler verebilir.
Bu makalenin başında Service Framework ekibinde yer aldığım zamanlarda yaşadığım bir zorluğu anlatmıştım. Amazon ekibine, maksimum bağlantıları kendi yük dengeleyicilerinide yapılandırmaları için tavsiye edilen varsayılan ayarları sağlamaya çalışıyorduk. Sonunda yük dengeleyicilerine maksimum bağlantıları ve yüksek proxy oluşturmalarını önerdik ve sunucunun yerel bilgilerle daha keskin yük atma algoritmaları uygulamasına izin verdik. Bununla birlikte maksimum bağlantı değerlerinin dinleyici iş parçacıklarını, dinleyici işlemlerini veya sunucu üzerindeki dosya belirteçlerini geçmemesi de önemli idi. Bu nedenle sunucu, yük dengeleyiciden kritik sağlık kontrolü isteklerini yerine getirecek kaynaklara sahipti.
Sunucu kaynağı kullanımını sınırlandırmak üzere işletim sistemi özellikleri güçlü olup acil durumlarda kullanılabilir. Aşırı yükün olabileceğini bildiğimiz için işletim kitabını kullanılmaya hazır belirli komutlarla kullanarak hazırlıklı oluyoruz. İptables hizmet programı, sunucunun kabul edeceği maksimum bağlantı sayısı için üst sınır belirleyebilir ve diğer herhangi bir sunucudan çok daha ucuz bağlantılara erişimi reddedebilir. Ayrıca sınırlı ölçüde yeni bağlantılara izin vererek veya kaynak IP adresi başına sınırlı bir bağlantı oranına veya sayıma izin vererek çok daha gelişmiş kontrollerle yapılandırılabilir. Kaynak IP filtreleri güçlüdür ancak geleneksel yük dengeleyicileri için geçerli değildir. Bununla beraber ELB Network Load Balancer, kaynak IP filtreleri gibi iptables kurallarının beklendiği gibi çalışmasını sağlayarak arayan kişinin IP kaynağını ağ sanallaştırma yoluyla işletim sistemi katmanında bile korur.
Katmanlarda koruma
Bazı durumlarda sunucu, yavaşlama olmaksızın istekleri reddetmek için bile kaynaklarını tüketir. Bu bilgiyle, nasıl işbirliği yaptıklarını görmek ve aşırı yükün atılmasını sağlamak için sunucu ile istemci arasındaki durakları inceliyoruz. Örneğin, bazı AWS hizmetleri varsayılan olarak yük atma seçenekleri içerir. Amazon API Gateway ile bir hizmet sunduğumuzda herhangi bir API’nin kabul edeceği maksimum istek oranını yapılandırabiliyoruz. Hizmetlerimiz API Gateway, Application Load Balancer veya Amazon CloudFront tarafından karşılandığında birçok boyutta fazla trafik çekmek amacıyla AWS WAF yapılandırmasını gerçekleştirebiliyoruz.
Görünürlük zor bir gerilim oluşturur. Erken reddetmek önemlidir çünkü fazla trafiği atmanın en ucuz yoludur ancak yine de görünürlük bakımından maliyeti vardır. Sunucunun yapabileceğinden daha fazla iş kaldırmasını, fazlalıkları atmasını ve trafikte ne atıldığını görmek için yeterli bilgiyi kaydetmesini sağlamak için katmanlarda koruma sağlıyoruz. Bir sunucu yalnızca çok fazla trafik olduğunda düştüğü için aşırı yük veya trafikten korumak amacıyla önündeki katmana güveniyoruz.
Aşırı yük hakkında farklı düşünme
Bu makalede, kaynak limitleri ve çekişmeler gibi sistemlerin eş zamanlı olarak iş yaptığında yavaşladığı gerçeğine dayanarak yükün atılma gereğini ele aldık. Aşırı yük geri bildirim döngüsü, nihayetinde boşa giden iş, oran arttırma isteği ve daha fazla yükle sonuçlanan gecikme ile meydana gelir. Bu güç, Evrensel Ölçeklenebilirlik Kanunu ve Amdahl kanunundan gelir ve aşırı yükü atarak ve aşırı yük karşısında öngörülebilir ve istikrarlı performansı sağlayarak bundan kaçınmak önemlidir. Öngörülebilir ve istikrarlı performansa odaklanmak Amazon hizmetlerinin dayandığı temel prensiptir.
Örneğin, Amazon DynamoDB ölçekte öngörülebilir performans ve erişilebilirlik sunan bir veri tabanı hizmetidir. Oluşan iş yükü hızlı bir şekilde meydana gelirse ve mevcut kaynakları aşsa bile DynamoDB, bu iş yükü için öngörülebilen kullanılabilir veri miktarını korur. DynamoDB otomatik ölçeklendirme, uyarlanabilir kapasite ve isteğe bağlı faktörler, iş yükündeki artışa uymak için kullanılabilir veri miktarını arttırmak için hızlıca tepki verir. O sırada kullanılabilir veri miktarı sabit kalır, hizmeti DynamoDB üzerinde katmanlarda öngörülebilir performansta tutar ve tüm sistemin istikrarını korur.
AWS Lambda tahmin edilebilir performansa odaklanmanın daha kapsamlı bir örneğini sunar. Bir hizmet uygulayacağımız zaman Lambda kullandığımızda her bir API araması, kendi yürütme ortamında kendisine ayrılmış miktarda tutarlı hesaplama kaynağı ile çalışır ve bu yürütme ortamı tek seferde yalnızca bir istek üzerinde çalışır. Bu çalışma şekli, belli bir sunucunun birden fazla API üzerinde çalıştığı sunucu tabanlı paradigmadan farklıdır.
Her bir API aramasını kendi bağımsız kaynaklarında tutmak (hesaplama, hafıza, disk, ağ) Amdahl kanununu bir şekilde bozacaktır çünkü bir API aramasının kaynakları başka bir API aramasının kaynakları ile rekabet etmeyecektir. Bu nedenle verim, kullanılabilir veri miktarını geçerse kullanılabilir veri miktarı, daha geleneksel sunucu tabanlı ortamlarda olduğu gibi düşmek yerine düz kalacaktır. Bu, bağımlılıklar yavaşlayabildiği ve eş zamanlılığın artmasına neden olabildiği için her derde deva değildir. Ancak bu senaryoda, en azından bu makalede ele aldığımız ana bilgisayardaki kaynak çekişmesi türleri için geçerli olmayacaktır.
Bu kaynak izolasyonu, zor ancak AWS Fargate, Amazon Elastic Container Service (Amazon ECS) ve AWS Lambda gibi modern ve sunucusuz hesaplama ortamlarında önemlidir. Amazon’da iş parçacığı havuzlarını ayarlamadan maksimum yük dengeleyici bağlantıları için mükemmel yapılandırmayı seçmeye kadar yük atmayı uygulamak için yapılması gereken çok fazla iş olduğunu öğrendik. Bu tür yapılandırmalar için uygun varsayılan ayarları bulmak zor ya da imkansızdır çünkü bunlar, her sistemin eşsiz işletimsel özelliklerine bağlıdırlar. Bu yeni ve sunucusuz hesaplama ortamları, aşırı yük karşısında korunmak için kısıtlama ve eş zamanlılık denetimleri gibi daha düşük düzeyde kaynak izolasyonu sağlar ve daha fazla denetime tabidir. Bir bakıma mükemmel varsayılan yapılandırma değerini kovalamak yerine hep beraber bu yapılandırmadan kaçınabilir ve yapılandırma olmaksızın aşırı yük kategorilerinden koruyabiliriz.
Daha fazla kaynak
- Evrensel Ölçeklenebilirlik Kanunu
- Amdahl kanunu
- Kademeli olay odaklı mimari (SEDA)
- Little kanunu (bir sistemin içindeki eş zamanlılığı ve dağıtılmış sistemlerde kapasitenin nasıl belirleneceğini açıklar)
- Telling Stories About Little's Law, Marc's Blog
- Elastic Load Balancing Deep Dive and Best Practices, sunumu: re:Invent 2016 (aşırı istekleri sıraya sokmayı durdurmak üzere Esnek Yük Dengeleme gelişimini tanımlar)
- Burgess, Thinking in Promises: Designing Systems for Cooperation, O'Reilly Media, 2015
Yazar hakkında
David Yanacek, AWS Lambda üzerinde çalışan bir Kıdemli Baş Mühendistir. David, 2006'dan bu yana Amazon'da çalışan bir yazılım geliştiricisidir. Daha önce Amazon DynamoDB ve AWS IoT'de, dâhili web hizmeti çerçevelerinde ve filo operasyonları otomasyon sistemlerinde çalışmıştır. David'in iş yerinde en sevdiği aktivitelerden birisi, sistemlerin zaman içinde daha hatasız çalışması için operasyonel ölçümler yoluyla günlük analizi ve elemeler yapmaktır.

Bugün aradığınızı buldunuz mu?
Sayfalarımızdaki içeriğin kalitesini artırabilmemiz için bize görüşlerinizi bildirin