Pekiştirmeli Öğrenme Nedir?
Pekiştirmeli öğrenme nedir?
Takviye öğrenme (RL), yazılımı en uygun sonuçları elde etmek için kararlar vermek için eğiten bir makine öğrenimi (ML) tekniğidir. İnsanların hedeflerine ulaşmak için kullandıkları deneme yanılma öğrenme sürecini taklit eder. Hedefiniz doğrultusunda çalışan yazılım eylemleri pekiştirilirken, hedeften uzaklaştıran eylemler göz ardı edilir.
RL algoritmaları, verileri işleyen bir ödül ve ceza paradigması kullanır. Her eylemin geri bildirimlerinden öğrenirler ve nihai sonuçlara ulaşmak için en iyi işleme yollarını kendi kendilerine keşfederler. Algoritmalar ayrıca ertelenmiş tatmin yeteneğine de sahiptir. En iyi genel strateji kısa vadeli fedakarlıklar gerektirebilir. Bu nedenle, keşfettikleri en iyi yaklaşım süreç içerisinde bazı cezaları veya geri adım atmayı içerebilir. RL, yapay zeka (AI) sistemlerinin görünmeyen ortamlarda en iyi sonuçları elde etmesine yardımcı olan güçlü bir yöntemdir.
Pekiştirmeli öğrenmenin avantajları nelerdir?
Pekiştirmeli öğrenmeyi (RL) kullanmanın birçok avantajı vardır. Ancak aşağıdaki üç alan genellikle öne çıkar.
Karmaşık ortamlarda üstünlük sağlar
RL algoritmaları, birçok kural ve bağımlılık içeren karmaşık ortamlarda kullanılabilir. Aynı ortamda bir insan, ortam hakkında üstün bilgiye sahip olsa bile izlenecek en iyi yolu belirleyemeyebilir. Bunun yerine, modelsiz RL algoritmaları sürekli değişen ortamlara hızla uyum sağlar ve sonuçları optimize etmek için yeni stratejiler bulur.
Daha az insan etkileşimi gerektirir
Geleneksel makine öğrenimi algoritmalarında, algoritmayı yönlendirmek için insanların veri çiftlerini etiketlemesi gerekir. Bir RL algoritması kullandığınızda bu durum gerekli değildir. Kendi kendine öğrenir. Aynı zamanda, insan geri bildirimini entegre etmek için mekanizmalar sunarak insan tercihlerine, uzmanlığına ve düzeltmelerine uyum sağlayan sistemlere izin verir.
Uzun vadeli hedefler için optimize eder
RL doğası gereği uzun vadeli ödül maksimizasyonuna odaklanır. Böylece eylemlerin uzun süreli sonuçlar getirdiği senaryolar için uygun hale gelir. Gecikmeli ödüllerden öğrenebildiğinden, her adımla ilgili geri bildirimlerin hemen mevcut olmadığı gerçek dünya durumları için özellikle uygundur.
Örneğin, enerji tüketimi veya depolanması ile ilgili kararların uzun vadeli sonuçları olabilir. RL, uzun vadeli enerji verimliliğini ve maliyetini optimize etmek için kullanılabilir. Uygun mimarilerle, RL temsilcileri öğrendikleri stratejileri benzer ancak aynı olmayan görevler arasında da genelleştirebilir.
Pekiştirmeli öğrenmenin kullanım durumları nelerdir?
Pekiştirmeli öğrenme (RL) çok çeşitli gerçek dünya kullanım durumlarına uygulanabilir. Aşağıda bazı örnekleri görebilirsiniz.
Pazarlama kişiselleştirme
Öneri sistemleri gibi uygulamalarda RL, etkileşimlerine dayalı olarak bireysel kullanıcılara önerileri özelleştirebilir. Böylece daha kişiselleştirilmiş deneyimlere ulaşılır. Örneğin, bir uygulama bazı demografik bilgilere dayanarak bir kullanıcıya reklam gösterebilir. Her reklam etkileşiminde uygulama, ürün satışlarını optimize etmek için kullanıcıya hangi reklamların gösterileceğini öğrenir.
Optimizasyon zorlukları
Geleneksel optimizasyon yöntemleri, olası çözümleri belirli kriterlere göre değerlendirerek ve karşılaştırarak sorunları çözer. Buna karşılık RL, zaman içinde en iyi veya en iyiye yakın çözümleri bulmak için etkileşimlerden öğrenmeyi gerektirir.
Örneğin, bir bulut harcama optimizasyon sistemi, dalgalanan kaynak ihtiyaçlarına uyum sağlamak ve optimum örnek türlerini, miktarlarını ve yapılandırmalarını seçmek için RL kullanır. Mevcut ve kullanılabilir bulut altyapısı, harcama ve kullanım gibi faktörlere dayalı kararlar alır.
Finansal tahminler
Finansal piyasaların dinamikleri karmaşıktır ve zaman içinde değişen istatistiksel özelliklere sahiptir. RL algoritmaları, işlem maliyetlerini dikkate alarak ve piyasa değişimlerine uyum sağlayarak uzun vadeli getirileri optimize edebilir.
Örneğin, bir algoritma eylemleri test etmeden ve ilgili ödülleri kaydetmeden önce borsanın kurallarını ve modellerini gözlemleyebilir. Dinamik olarak bir değer fonksiyonu oluşturur ve kârı en üst düzeye çıkarmak için bir strateji geliştirir.
Pekiştirmeli öğrenme nasıl çalışır?
Pekiştirmeli öğrenme (RL) algoritmalarının öğrenme süreci, davranış psikolojisi alanında hayvanlar ve insanlara yönelik pekiştirmeli öğrenmeye benzerdir. Örneğin bir çocuk, kardeşine yardım ettiğinde veya temizlik yaptığında ebeveyninden övgü aldığını ancak oyuncaklarını fırlattığında veya çığlık attığında olumsuz tepkiler aldığını keşfedebilir. Kısa sürede çocuk, hangi aktivite kombinasyonunun nihai ödülle sonuçlanacağını öğrenir.
RL algoritması benzer bir öğrenme sürecini taklit eder. Nihai ödül sonucunu elde etmek amacıyla ilgili negatif ve pozitif değerleri öğrenmek için farklı aktiviteler dener.
Temel kavramlar
Pekiştirmeli öğrenmede, bilmeniz gereken birkaç temel kavram vardır:
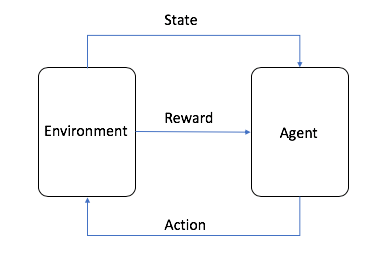
- Aracı, ML algoritmasıdır (veya otonom sistemdir)
- Ortam; değişkenler, sınır değerleri, kurallar ve geçerli eylemler gibi niteliklere sahip uyarlanabilir sorun alanıdır
- Eylem, RL aracısının ortamda gezinmek için attığı bir adımdır
- Durum, belirli bir zamandaki ortamdır
- Ödül, bir eylemde bulunmak için pozitif, negatif veya sıfır değerdir (başka bir deyişle ödül veya ceza)
- Kümülatif ödül, tüm ödüllerin toplamı veya nihai değerdir
Algoritma temelleri
Pekiştirmeli öğrenme, ayrık zaman adımlarını kullanan matematiksel bir karar verme modellemesi olan Markov karar sürecine dayanır. Temsilci, her adımda yeni bir ortam durumuyla sonuçlanan yeni bir eylem gerçekleştirir. Benzer şekilde, mevcut durum önceki eylemlerin sırasına atfedilir.
Aracı, ortamda hareket ederken deneme yanılma yoluyla bir dizi eğer-o halde kuralı veya politikası oluşturur. Politikalar, ideal kümülatif ödül için aracının daha sonra hangi eylemi yapacağına karar vermesine yardımcı olur. Aracı ayrıca yeni durum-eylem ödüllerini öğrenmek için daha fazla ortam araştırması yapmak veya belirli bir durumdan bilinen yüksek ödüllü eylemleri belirlemek arasında seçim yapmalıdır. Buna keşif-yararlanma değiş tokuşu denir.
Pekiştirmeli öğrenme algoritmalarının türleri nelerdir?
Pekiştirilmeli öğrenmede (RL) kullanılan çeşitli algoritmalar (ör. Q-öğrenme, politika gradyan yöntemleri, Monte Carlo yöntemleri ve zamansal fark öğrenmesi) vardır. Derin RL, derin sinir ağlarının pekiştirmeli öğrenmeye uygulanmasıdır. Derin RL algoritmasına örnek olarak Güven Bölgesi Politikası Optimizasyonu (TRPO) verilebilir.
Tüm bu algoritmalar iki geniş kategoride gruplandırılabilir.
Model tabanlı RL
Model tabanlı RL genel olarak ortamlar iyi tanımlanmış ve değişmez olduğunda ve gerçek dünya ortam testinin zor olduğu durumlarda kullanılır.
Temsilci ilk olarak ortamın dahili bir temsilini (modelini) oluşturur. Bu modeli oluşturmak için şu süreci kullanır:
- Ortam içinde eylemler gerçekleştirir ve yeni durum ile ödül değerini not eder.
- Eylem-durum geçişini ödül değeri ile ilişkilendirir.
Model tamamlandığında, temsilci optimum kümülatif ödüllerin olasılığına dayalı olarak eylem dizilerini simüle eder. Daha sonra eylem dizilerinin kendilerine de değer atar. Böylece temsilci, istenen nihai hedefe ulaşmak için ortam içinde farklı stratejiler geliştirir.
Örnek
Belirli bir odaya ulaşmak için yeni bir binada gezinmeyi öğrenen bir robot düşünün. Başlangıçta robot serbestçe keşif yapar ve binanın dahili bir modelini (veya haritasını) oluşturur. Örneğin, ana girişten 10 metre ilerledikten sonra bir asansörle karşılaştığını öğrenebilir. Haritayı oluşturduktan sonra, bina içinde sık sık ziyaret ettiği farklı konumlar arasında bir en kısa yol dizisi oluşturabilir.
Modelsiz RL
Ortam büyük, karmaşık ve kolayca tanımlanamadığında kullanılabilecek en iyi yöntem modelsiz RL'dir. Ayrıca ortamın bilinmediği ve değiştiği durumlarda da idealdir ve ortam temelli testlerin önemli dezavantajları yoktur.
Temsilci, ortamın ve dinamiklerinin dahili bir modelini oluşturmaz. Bunun yerine, ortam içinde bir deneme yanılma yaklaşımı kullanır. Bir politika geliştirmek için durum-eylem çiftlerini ve durum-eylem çiftleri dizilerini puanlar ve not eder.
Örnek
Şehir trafiğinde gezinmesi gereken sürücüsüz bir araç düşünün. Yollar, trafik modelleri, yaya davranışları ve sayısız diğer faktör ortamı oldukça dinamik ve karmaşık hale getirebilir. Yapay zeka ekipleri ilk aşamalarda aracı simüle edilmiş bir ortamda eğitir. Araç, mevcut durumuna göre eylemler gerçekleştirir ve ödüller veya cezalar alır.
Araç, zaman içinde farklı sanal senaryolarda milyonlarca mil sürüş yaparak tüm trafik dinamiklerini açıkça modellemeden her durum için hangi eylemlerin en iyi olduğunu öğrenir. Araç, gerçek dünyaya girdiğinde öğrenilen politikayı kullanır ancak yeni verilerle onu iyileştirmeye devam eder.
Pekiştirmeli, denetimli ve denetimsiz makine öğrenimi arasındaki fark nedir?
Denetimli öğrenme, denetimsiz öğrenme ve pekiştirmeli öğrenmenin (RL) tümü yapay zeka alanındaki makine öğrenimi algoritmaları olsa da üçü arasında ayrımlar vardır.
Denetimli ve denetimsiz öğrenme hakkında bilgi edinin »
Pekiştirmeli öğrenme ve denetimli öğrenme karşılaştırması
Denetimli öğrenmede hem girdiyi hem de beklenen ilişkili çıktıyı tanımlarsınız. Örneğin, köpek veya kedi olarak etiketlenmiş bir dizi görüntü sağlayabilirsiniz. Algoritmanın daha sonra yeni bir hayvan görüntüsünü köpek ya da kedi olarak tanımlaması beklenir.
Denetimli öğrenme algoritmaları girdi ve çıktı çiftleri arasındaki modelleri ve ilişkileri öğrenir. Ardından, yeni giriş verilerine dayanarak sonuçları tahmin ederler. Bir eğitim veri setindeki her bir veri kaydını bir çıktı ile etiketlemek için bir denetmen (genelde bir insan) gerektirir.
Buna karşılık, RL'nin istenen bir sonuç şeklinde iyi tanımlanmış bir nihai hedefi vardır ancak ilişkili verileri önceden etiketleyecek bir denetmen yoktur. Eğitim sırasında, girdileri bilinen çıktılarla eşleştirmeye çalışmak yerine, girdileri olası sonuçlarla eşleştirir. İstenen davranışları ödüllendirerek, en iyi sonuçlara ağırlık verirsiniz.
Pekiştirmeli öğrenme ve denetimsiz öğrenme karşılaştırması
Denetimsiz öğrenme algoritmaları, eğitim sürecinde belirli çıktıları olmayan girdiler alır. İstatistiksel araçlar kullanarak veriler içindeki gizli modelleri ve ilişkileri bulurlar. Örneğin, bir dizi belge sağlayabilirsiniz ve algoritma bunları metindeki kelimelere dayalı olarak tanımladığı kategorilere göre gruplayabilir. Belirli bir sonuç almazsınız; bunlar bir aralıkta yer alır.
Tersine, RL'nin önceden belirlenmiş bir nihai hedefi vardır. Keşifsel bir yaklaşım benimserken, nihai hedefe ulaşma olasılığını artırmak için keşifler sürekli olarak doğrulanır ve geliştirilir. Çok spesifik sonuçlara ulaşmayı kendi kendine öğretebilir.
Pekiştirmeli öğrenmenin zorlukları nelerdir?
Pekiştirmeli öğrenme (RL) uygulamaları potansiyel olarak dünyayı değiştirebilirken, bu algoritmaları uygulamak kolay olmayabilir.
Pratiklik
Gerçek dünyadaki ödül ve ceza sistemlerini denemek pratik olmayabilir. Örneğin, bir drone'u önce bir simülatörde test etmeden gerçek dünyada test etmek, önemli sayıda uçağın bozulmasına neden olur. Gerçek dünya ortamları sık sık, önemli ölçüde ve sınırlı uyarı ile değişir. Algoritmanın pratikte etkili olmasını zorlaştırabilirler.
Yorumlanabilirlik
Her bilim dalı gibi veri bilimi de standartlar ve prosedürler oluşturmak için kesin araştırmalara ve bulgulara bakar. Veri bilimciler, kanıtlanabilirlik ve tekrarlama açısından belirli bir sonuca nasıl ulaşıldığını öğrenmeyi tercih eder.
Karmaşık RL algoritmalarında, belirli bir adım dizisinin neden atıldığını tespit etmek zor olabilir. Bir dizideki hangi eylemler en iyi sonuca götüren eylemlerdi? Bunu anlamak zor olabilir. Bu durum da uygulama zorluklarına neden olur.
AWS, pekiştirmeli öğrenmeye nasıl yardımcı olabilir?
Amazon Web Services (AWS), gerçek dünyadaki uygulamalar için pekiştirmeli öğrenme (RL) algoritmaları geliştirmenize, eğitmenize ve dağıtmanıza yardımcı olan birçok teklife sahiptir.
Amazon SageMaker ile geliştiriciler ve veri bilimciler hızlı ve kolay bir şekilde ölçeklenebilir RL modelleri geliştirebilir. Gerçek dünya senaryosunu taklit etmek için bir derin öğrenme çerçevesini (TensorFlow veya Apache MXNet gibi), bir RL araç setini (RL Coach veya RLlib gibi) ve bir ortamı birleştirin. Modelinizi oluşturmak ve test etmek için bunu kullanabilirsiniz.
AWS RoboMaker ile geliştiriciler herhangi bir altyapı gereksinimi olmaksızın robotik için RL algoritmalarıyla simülasyonu çalıştırabilir, ölçeklendirebilir ve otomatikleştirebilir.
Tamamen otonom 1/18 ölçek li yarış arabası AWS DeepRacer ile uygulamalı deneyim kazanın. RL modellerinizi ve sinir ağı yapılandırmalarınızı eğitmek için kullanabileceğiniz tamamen yapılandırılmış bir bulut ortamı sunar.
Hemen bir hesap oluşturarak AWS'de pekiştirmeli öğrenmeye başlayın.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages