





在本單元中,您將建立 Amazon Kinesis Data Analytics 應用程式,來即時彙總獨角獸群組的感應器資料。此應用程式將從 Amazon Kinesis 串流讀取資料、計算出行的總距離,以及目前在 Wild Ryde 上各獨角獸的最小和最大生命與魔法點數,並每分鐘將這些彙總的統計資料輸出至 Amazon Kinesis 串流。
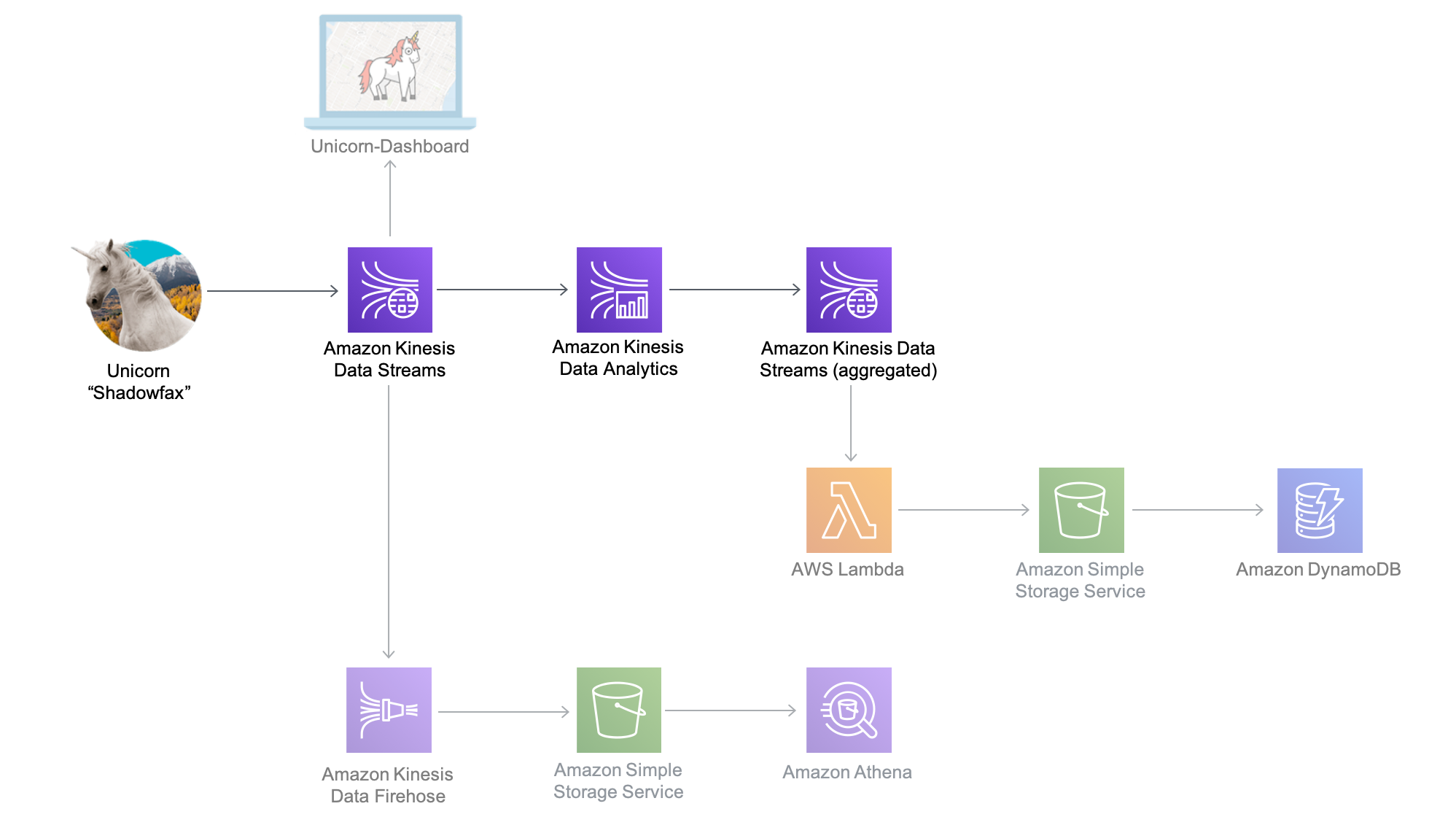
本單元的架構涉及 Amazon Kinesis Data Analytics 應用程式、來源與目標 Amazon Kinesis 串流,以及生產者和取用者命令列
Amazon Kinesis Data Analytics 應用程式會處理我們在上一個單元中建立之來源 Amazon Kinesis 串流的資料,並每分鐘彙總該資料。應用程式每分鐘都會發出資料,包括上一分鐘的出行總距離,以及我們獨角獸群組中各獨角獸的最小和最大生命,以及魔法點數讀數。這些資料點將傳送至目標 Amazon Kinesis 串流,以便系統中的其他元件處理。
完成單元的時間︰20 分鐘
使用的服務:
• Amazon Kinesis Data Streams
• Amazon Kinesis Data Analytics
-
步驟 1.建立 Amazon Kinesis 串流
使用 Amazon Kinesis Data Streams 主控台建立名為 wildrydes-summary 的新串流,其中包含 1 個碎片。
a.前往 AWS 管理主控台,按一下「服務」,然後選取「分析」下的「Kinesis」。
b.如果出現入門畫面,請選取「開始使用」。
c.選取「建立資料串流」。
d.在「Kinesis 串流名稱」中輸入「wildrydes-summary」,並在「碎片數量」中輸入「1」,然後選取「建立 Kinesis 串流」。
e.您的 Kinesis 串流將在 60 秒內變為「作用中」,並準備好儲存即時串流資料。
-
步驟 2.建立 Amazon Kinesis Data Analytics 應用程式
建立 Amazon Kinesis Data Analytics 應用程式,藉以從上一個單元建立的 wildrydes 串流讀取資料,並每分鐘發出包含下列屬性的 JSON 物件:
Name 獨角獸名稱 StatusTime 由 Amazon Kinesis Data Analytics 提供的 ROWTIME Distance 獨角獸出行距離的總和 MinMagicPoints MagicPoints 屬性的最小 資料點MaxMagicPoints MagicPooints 屬性的最大 資料點MinHealthPoints HealthPoints 屬性的最小資料點 MaxHealthPoints HealthPoints 屬性的 最大 資料點a.切換至您已開啟 Cloud9 環境的標籤。
b.執行生產者,以開始發出感應器資料至串流。
./producer
在我們建置應用程式時主動產生感應器資料,能讓 Amazon Kinesis Data Analytics 自動偵測我們的結構描述。
c.前往 AWS 管理主控台,按一下「服務」,然後選取「分析」下的「Kinesis」。
d.選取「建立分析應用程式」。
e.在「應用程式名稱」中輸入「wildrydes」,然後選取「建立應用程式」。
f.選取「連接串流資料」。
g.從「Kinesis 串流」中選取「wildrydes」。
h.向下捲動並按一下「探索結構描述」並稍後,隨後確保已正確自動探索該結構描述。
確保自動探索的結構描述包括:
欄 資料類型 Distance DOUBLE HealthPoints INTERGER Latitude DOUBLE Longitude DOUBLE MagicPoints INTEGER Name VARCHAR(16) StatusTime TIMESTAMP i.選取「儲存並繼續」。
j.選取「前往 SQL 編輯器」。這將開啟互動式查詢工作階段,除了即時 Amazon Kinesis 串流之外,我們將在其中建立查詢。
k.選取「是,啟動應用程式」。應用程式啟動需要 30 – 90 秒時間。
l.複製以下 SQL 查詢並貼入 SQL 編輯器:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( "Name" VARCHAR(16), "StatusTime" TIMESTAMP, "Distance" SMALLINT, "MinMagicPoints" SMALLINT, "MaxMagicPoints" SMALLINT, "MinHealthPoints" SMALLINT, "MaxHealthPoints" SMALLINT ); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM "Name", "ROWTIME", SUM("Distance"), MIN("MagicPoints"), MAX("MagicPoints"), MIN("HealthPoints"), MAX("HealthPoints") FROM "SOURCE_SQL_STREAM_001" GROUP BY FLOOR("SOURCE_SQL_STREAM_001"."ROWTIME" TO MINUTE), "Name";
(按一下以縮放)
m.選取「儲存並執行 SQL」。您每分鐘都會看到包含彙總資料的資料列送達。等候資料列送達。
n.按一下「目標」連結。
o.選取「連接至目標」。
p. 從「Kinesis 串流」中選取「wildrydes-summary」。
q.從「應用程式內串流名稱」中選取「DESTINATION_SQL_STREAM」。
r.選取「儲存並繼續」。

(按一下以縮放)
-
步驟 3.從串流讀取訊息
使用命令列取用者檢視來自 Kinesis 串流的訊息,從而查看每分鐘傳送的彙總資料。
a.切換至您已開啟 Cloud9 環境的標籤。
b.執行取用者,以便從串流讀取感應器資料。
./consumer -stream wildrydes-summary
取用者將會列印每分鐘由 Kinesis Data Analytics 應用程式傳送的訊息:
{ "Name": "Shadowfax", "StatusTime": "2018-03-18 03:20:00.000", "Distance": 362, "MinMagicPoints": 170, "MaxMagicPoints": 172, "MinHealthPoints": 146, "MaxHealthPoints": 149 } -
步驟 4.以生產者進行實驗
停止和啟動產生者,同時間觀看儀表板和取用者。啟動不同獨角獸名稱的多個產生者。
a.切換至您已開啟 Cloud9 環境的標籤。
b.按下 Control + C 停止生產者,並注意訊息是否停止。
c.再次啟動生產者,並注意訊息是否繼續。
d.按下 (+) 按鈕並按一下「新增終端機」,以開啟新增終端機標籤。
e.在新標籤中啟動生產者的另一個執行個體。提供特定的獨角獸名稱,並注意取用者輸出中
兩匹 獨角獸的資料點:./producer -name Bucephalus
f. 確認您看到輸出中出現多匹獨角獸:
{ "Name": "Shadowfax", "StatusTime": "2018-03-18 03:20:00.000", "Distance": 362, "MinMagicPoints": 170, "MaxMagicPoints": 172, "MinHealthPoints": 146, "MaxHealthPoints": 149 } { "Name": "Bucephalus", "StatusTime": "2018-03-18 03:20:00.000", "Distance": 1773, "MinMagicPoints": 140, "MaxMagicPoints": 148, "MinHealthPoints": 132, "MaxHealthPoints": 138 } -
回顧和秘訣
🔑 Amazon Kinesis Data Analytics 讓您能夠使用 SQL 查詢串流資料或建立整個串流應用程式,藉此取得可行的洞見及迅速回應業務和客戶需求。
🔧 在本單元中,您已建立 Kinesis Data Analytics 應用程式,藉以讀取來自獨角獸資料的 Kinesis 串流,並每分鐘發出摘要列。


在下一單元中,您將使用 AWS Lambda 處理稍早之前建立之